Nie raz już pisałem tu o architekturze (Architektura systemu) tym razem kilka słów o tym. Często jestem pytany o kryterium podziału dużego systemu na komponenty. Jednym z nich jest praktyka dążenia do minimalizacji złożoności interfejsów między komponentami jako konsekwencja dziedzinowego kryterium podziału . Złą praktyką jest natomiast dążenie do usuwania redundancji.
Stosuje takie – komponentowe dziedzinowe – podejście, w różnej formie, z powodzeniem od lat. Można je spotkać w różnych formach w literaturze, pierwszy raz spotkałem się z nim w 1999 roku.
Obecnie mamy już dość dobrze wypracowane wzorce projektowe ale nadal jest problem ze zrozumieniem “kiedy i jak”. Ładnie to opisał swego czasu [[E.Evans przy okazji wzorca DDD]], Tu poprzestanę jedynie na pojęciu [[bounded context]] czyli “granica kontekstu”. Granica ta ma podwójne znaczenie: kontekst nadaje (zmienia) znaczenia w modelu pojęciowym (bałwan w kontekście zimy to co innego niż bałwan w kontekście członków zespołu projektowego) oraz kontekst (bardzo często) wyznacza zakres projektu (inne aspekty wzorca DDD tu pominę). Pierwsza uwaga: kontekst dziedzinowy (pojęciowy) jest ważniejszy (powinien być nadrzędny) wobec zakresu projektu, ten drugi jest ustalany, drugi wynika z systemu pojęciowego (bałwan z okazji zimy będzie trwalszym pojęciem w projekcie niż bałwan z okazji członków doraźnego spotkania zespołu).
Ładnie opisał to M.Fowler:
Bounded Context is a central pattern in Domain-Driven Design. It is the focus of DDD’s strategic design section which is all about dealing with large models and teams. DDD deals with large models by dividing them into different Bounded Contexts and being explicit about their interrelationships.
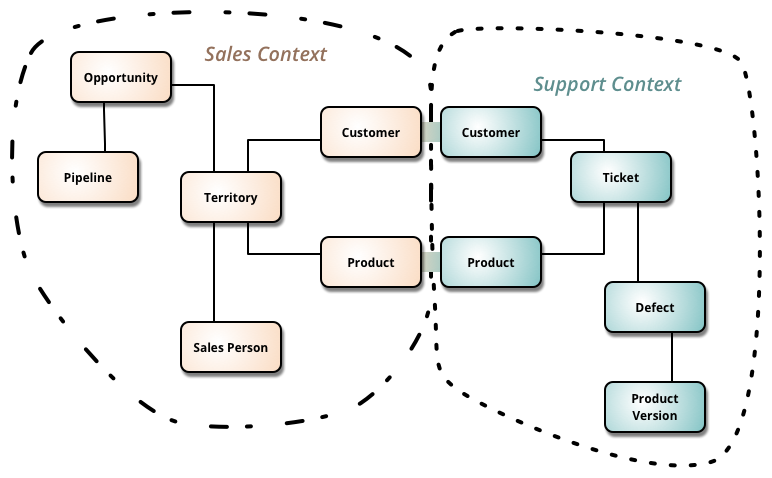
Jak widać mamy dwa konteksty i redundancje (pojęcia Customer i Produkt po obu stronach). Powyższe powinno być podstawą do podziału projektu na dwa komponenty (dwie aplikacje każda ma swoje klasy Customer i Produkt i nie współdzielą ich w bazie danych) i powinno odwieść od pomysłu tworzenia jednej znormalizowanej bazy danych dla całości. Powód pierwszy to inne związki pojęciowe i inne definicje pojęć. Produkt w kontekście sprzedaży ma nazwę, cenę, dostępność itp. Produkt w kontekście uszkodzeń ma numer seryjny, wersję, użytkownika itp. Inne będą reguły biznesowe w każdym komponencie. Drugi powód to łatwa dostępność na rynku produktów typu CRM i TicketXXX, szukanie jednego “pakietu zintegrowanego” będzie bardzo trudne, bo kontekstów sprzedaży a potem obsługi uszkodzeń czy reklamacji, jako pary, będzie tysiące wariantów. Kupno osobno i integracja dwóch odpowiednio dobranych produktów (aplikacji) będzie znacznie łatwiejsze, i raczej obejdzie bez kastomizacji, której wymaga większość (wszystkie??) pakietów zintegrowanych (one zawsze są jakimś zgniłym kompromisem).
Idąc w stronę komponentów i dużych złożonych systemów warto skorzystać z podejścia polegającego na tworzeniu (kupowaniu) tak zwanych mikroserwisów, czyli wąsko specjalizowanych dziedzinowych aplikacji (wręcz pojedynczych grup przypadków użycia). Paradoksalnie to bardzo ułatwia projektowanie, implementację a przede wszystkim obniża koszty utrzymania całego systemu. Brak złożonych połączeń między komponentami (współdzielona baza danych, złożone interfejsy) pozwala na to, by cykle ich życia były także niezależne (wprowadzane zmiany także). Tu opis (znowu M.Fowler):
One reasonable argument we’ve heard is that you shouldn’t start with a microservices architecture. Instead begin with a monolith, keep it modular, and split it into microservices once the monolith becomes a problem.
(M.Fowler Microservices).
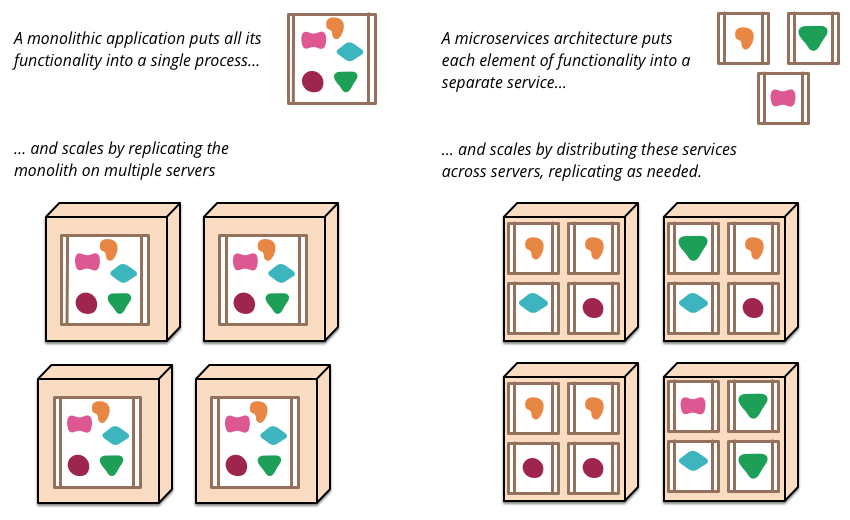
Bardzo ładnie pokazał to Marin Fowler na jednej ze swoich prezentacji Testing strategies in a Microserices Architecture.
Polecam także:
distributed objects was although you can encapsulate many things behind object boundaries, you can’t encapsulate the remote/in-process distinction. An in-process function call is fast and always succeeds (in that any exceptions are due to the application, not due to the mere fact of making the call). Remote calls, however, are orders of magnitude slower, and there’s always a chance that the call will fail due to a failure in the remote process or the connection. (źr. Microservices and the First Law of Distributed Objects).
oraz:
Concluding with the famous Conway?s law: “organizations which design systems ? are constrained to produce designs which are copies of the communication structures of these organizations”. In other words, the communication between two different software modules is proportional to the communication between the designers and developers of these modules. Conway?s law exposes the vulnerability in monoliths as they grow in size. Micro-services may not be the best, but better than monoliths for the contemporary web based applications. (Źródło: Micro-Services: A comparison with Monoliths ? My Blog)
A co dalej z ERP
Trzy lata temu robiłem pewne podsumowanie w jednym z artykułów na ten temat w kontekście systemów ERP, w zasadzie mogę je przepisać (a cały artykuł polecam ;):
Rynek stale się rozwija i dojrzewa. Praktycznie każda większa firma doświadczyła w jakiejś formie wdrożenia gotowego, dostosowywanego do potrzeb, oprogramowania ERP. Warto jednak podkreślić, że idea jednego ?super systemu? ERP II, odchodzi powoli do lamusa. Moim zdaniem to kwestia roku, dwóch. Pierwsze symptomy to zalecenia producentów dużych systemów: wdrażać gotowe oprogramowanie w postaci ?gotowej? tylko tam gdzie pasuje, obszary specyficzne dla firmy opisać i zaprojektować dla nich dedykowane rozwiązanie i zintegrować. Dobry system ERP to środowisko programistyczne (tak zwany framework, szkielet). Systemy, nazwę je ?zapóźnione?, nadal wymagają ingerencji w ich kod by cokolwiek osiągnąć. Kompromisem jest sytuacja, w której system ERP ma bogaty interfejs (tak zwane API, Application Programming Interface) pozwalający na integrację dedykowanych podsystemów lub właśnie zewnętrznych komponentów czyli korzystania z możliwości jakie daje Cloud Computing. Przyszłość to komponenty?
(źr. Biznes wychodzi z objęć systemu ? monolitycznego ERP | Jarosław Żeliński IT-Consulting).



Bardzo ciekawa prezentacja na temat mikro-serwisów, polecam:
https://youtu.be/d_RwASXkPqE
Kolejny ciekawy artykuł z tego obszaru