Jestem orędownikiem metod naukowych i modelowania więc znowu o tym. Na początek jednak cytat z prasy:
Im więcej zasobów organizacja przechowuje w swoich zasobach, tym większe problemy napotyka. Podstawowym problemem, który dotyczy typowych serwerów plików, są ograniczenia związane z możliwościami systemu plików stosowanego w danym serwerze. […]
Oprócz wymagań związanych z szybkością przetwarzania strumienia informacji przedsiębiorstwa potrzebują narzędzi, które umożliwią analizę bardzo dużych zbiorów danych. Potrzeby biznesowe związane z analizowaniem różnych wariantów wymagają szybkiej odpowiedzi systemu. Gdy ilość zgromadzonych danych liczy się w terabajtach, tradycyjny model hurtowni korzystający z wielowymiarowych modeli OLAP działa zbyt wolno, a niekiedy w ogóle nie nadaje się do analizy podobnej wielkości danych. (za Ujarzmić firmowe dane – Computerworld.pl).
 Im więcej zasobów organizacja przechowuje w swoich zasobach, tym większe problemy napotyka. Podstawowym problemem, który dotyczy typowych serwerów plików, są ograniczenia związane z możliwościami systemu plików stosowanego w danym serwerze. […]
Im więcej zasobów organizacja przechowuje w swoich zasobach, tym większe problemy napotyka. Podstawowym problemem, który dotyczy typowych serwerów plików, są ograniczenia związane z możliwościami systemu plików stosowanego w danym serwerze. […]Analiza danych i wyciąganie wniosków z zasady jest wnioskowaniem indukcyjnym, jest to wyciąganie wniosków na bazie posiadanych informacji, jednak problem polega na tym, że bazujemy na wiedzy już posiadanej. Innymi słowy metodami indukcyjnymi, jeżeli można próbować dowodzić rzeczy poznanych, tak nie odkryjemy rzeczy nowych… po drugie:
Głównym problemem filozoficznym związanym z rozumowaniami indukcyjnymi jest to, czy stanowią one rozumowania uzasadniające: skoro konkluzja wnioskowania indukcyjnego nie jest w pełni uzasadniona przez jej przesłanki, pojawia się problem, w jaki sposób, w jakim stopniu i czy w ogóle wnioskowania indukcyjne prowadzą do prawdziwych wniosków. Ci, którzy uznają wnioskowania indukcyjne za wnioskowania uzasadniające (zwolennicy indukcjonizmu) tłumaczą zazwyczaj stopień uzasadnienia konkluzji wnioskowania indukcyjnego za pomocą pojęcia prawdopodobieństwa logicznego. Krytyka indukcjonizmu dokonana przez dedukcjonizm (antyindukcjonizm) opiera się przede wszystkim na fakcie, że nie skonstruowano dotychczas zadowalającej odpowiedzi na pytanie, jak mierzyć to prawdopodobieństwo. (za Rozumowanie indukcyjne ? Wikipedia, wolna encyklopedia).
W opozycji do tej metody jest
Hipotetyzm – sposób uzasadniania twierdzeń w naukach empirycznych. Z hipotez wyprowadza się ich konsekwencje logiczne. Mając pewien zbiór konsekwencji bada się, czy nie ma w nim tautologii (ew. sprzeczności). Jeżeli twierdzenie wyprowadzone w ten sposób wnosi coś nowego do teorii, poddaje się je testowi empirycznemu (twierdzenie traktuje się jako przewidujące fakty doświadczalne). (za Hipotetyzm ? Wikipedia, wolna encyklopedia).
Ma on swoje źródło w:
Falsyfikacjonizm jest to zbiór procedur metodologicznych, które, w opinii autorów tego stanowiska, chcący się przyczynić do rozwoju wiedzy naukowej badacz musi stosować. Osią tego ujęcia jest przekonanie, że dla teorii naukowych nie należy szukać potwierdzenia (weryfikacji), lecz kontrprzypadków, mogących badanej teorii zaprzeczyć. Należy zatem dążyć do sfalsyfikowania teorii (wykazania jej niezgodności z doświadczeniem), a jeśli próba się nie powiedzie uznać, tymczasowo, teorię, aż do następnej próby falsyfikacji, która dla teorii skończyć się może obaleniem. (za Krytyczny racjonalizm ? Wikipedia, wolna encyklopedia).
 Tyle wprowadzenia. I co z tego wynika? Że odkrywanie “nowych rzeczy” nie jest w stanie się dokonać na bazie analizy historii, bo skoro szukamy rzeczy nowych to historia ich nie zawiera. Falsyfikacjonim, nazywany często “naukowym badaniem”, polega na stawianiu hipotez i podejmowaniu prób ich sfalsyfikowania (wykazania ich nieprawdziwości). Dobra hipoteza – teoria – to hipoteza w postaci modelu zjawiska, które opisuje (hipoteza mówi: tak właśnie jest) oraz przykład (test) zdarzenia, które – gdyby zaistniało – obali tę hipotezę (warunek falsyfikacji).
Tyle wprowadzenia. I co z tego wynika? Że odkrywanie “nowych rzeczy” nie jest w stanie się dokonać na bazie analizy historii, bo skoro szukamy rzeczy nowych to historia ich nie zawiera. Falsyfikacjonim, nazywany często “naukowym badaniem”, polega na stawianiu hipotez i podejmowaniu prób ich sfalsyfikowania (wykazania ich nieprawdziwości). Dobra hipoteza – teoria – to hipoteza w postaci modelu zjawiska, które opisuje (hipoteza mówi: tak właśnie jest) oraz przykład (test) zdarzenia, które – gdyby zaistniało – obali tę hipotezę (warunek falsyfikacji).
Czyli hipotezy nie dowodzimy, musimy ją obalić by wykazać jej fałszywość ale autor hipotezy musi wskazać co potencjalnie obala jego hipotezę (twórcą tej teorii w filozofii nauki jest [[Karl Popper]]). Innymi słowy: hipoteza może mi przyjść do głowy nawet podczas wizji religijnej, nie ma to znaczenia. Ważne jest, dla jej prawdziwości, by ją opisać i wskazać warunek falsyfikacji. Hipoteza taka, jeżeli jest potwierdzana przez obserwowane zjawiska, jest prawdziwa tak długo jak długo nie zostanie sfalsyfikowana (wskazane zostanie zjawisko wyłamujące się modelowi). Najbardziej znanym i znamiennym przykładem tego podejścia jest [[słynne twierdzenie Fermata]].
A teraz po ludzku
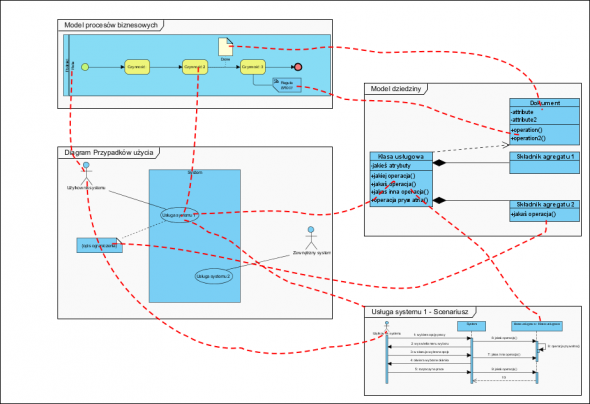
Modelowanie, jako narzędzie analizy, to nic innego jak właśnie tworzenie hipotez. Np. tworzę model procesów biznesowych (z reguły na bazie małej partii dokumentów rzeczywistych). Dowodem falsyfikującym ten model jest wskazanie takiego rzeczywistego dokumentu w analizowanej firmie, który nie jest obsługiwany stworzonym modelem procesu. Wskazanie takiego dokumentu lub zdarzenia obala hipotezę (model) i wymaga modyfikacji modelu procesu lub uznanie, że model jest zły (i stworzenie nowego :)). To samo dotyczy każdego innego modelowania.
Tak więc modele rynkowe zachowań klientów, prognozy i wiele innych można budować analizując terabajty danych opisujących historię. Problem w tym, że: nie znamy prawdopodobieństwa jakie rządzi tymi zdarzeniami, tak więc nie odkryjemy tak niczego poza tym co się wydarzyło i nadal nie wiemy z jakim prawdopodobieństwem wykryte zdarzenie z historii się powtórzy (wierzymy, że się powtórzy) w (prognozowanej) przyszłości (kto nie wierzy niech sprawdzi skuteczność takich prognoz (analiza techniczna) na giełdach. Jest praktycznie zerowa, co nie przeszkadza w jej powszechnym stosowaniu :).
Moim, i nie tylko, zdaniem hurtownie danych i wszelkiego typu systemy BI mogą być skuteczne jako wykrywanie “czegoś” w historii, na pewno sprawdzają się jako złożone systemy raportowania, ale nie sądzę by jakakolwiek hurtownia danych plus system BI odkryła cokolwiek nowego lub skutecznie prognozowała. Pamiętajmy, że tak zwany “model statystyczny” nie jest modelem zjawiska w rozumieniu teorii naukowej, to wyłącznie statystyka bez wiedzy i zrozumienia zjawiska opisywanego ta statystyką.
Firmy parające się statystyką, polegają (korzystają z) na tak zwanej [[próbie reprezentatywnej]]. Analizowana jest “dobrana” mała partia danych, a nie wszystkie, wiec nie wiem skąd ten pęd do analizy wszystkich posiadanych danych, których stale przybywa.
Budowanie modeli na bazie małych partii danych jest po pierwsze wiarygodniejsze (paradoksalnie) niż proste wnioskowanie statystyczne, po drugie daje szanse odkrycia czegoś nowego. W czym problem? To drugie jest nie możliwe z pomocą deterministycznej maszyny jaką jest komputer. To wymaga człowieka, ten jednak nie daje się produkować masowo… ;), korporacja na nim nie zarobi.
Hm… czy przypadkiem promowanie systemów hurtowni danych, BI, pracy z terabajtami danych itp.. to nie tworzenie sobie rynku przez dostawców tych technologii?
 Warto więc za każdym razem, zanim zainwestujemy w rozwiązania operujące na terabajtach danych, przemyśleć co chcemy osiągnąć. W zasadzie nie ma uzasadnienia dla trzymania wszystkich danych, ważne jest określenie jaki problem chcemy rozwiązać. Jeżeli są to problemy związane z analizą danych historycznych, badania statystyczne mogą być skuteczne, do tego poddają się automatyzacji. Jeżeli jednak problem tkwi w planowaniu zmian, prognozowaniu, odkrywaniu, polecam raczej człowieka i budowanie hipotez.
Warto więc za każdym razem, zanim zainwestujemy w rozwiązania operujące na terabajtach danych, przemyśleć co chcemy osiągnąć. W zasadzie nie ma uzasadnienia dla trzymania wszystkich danych, ważne jest określenie jaki problem chcemy rozwiązać. Jeżeli są to problemy związane z analizą danych historycznych, badania statystyczne mogą być skuteczne, do tego poddają się automatyzacji. Jeżeli jednak problem tkwi w planowaniu zmian, prognozowaniu, odkrywaniu, polecam raczej człowieka i budowanie hipotez.
A inne analizy?
Opisany powyżej mechanizm dotyczy każdego rodzaju analizy, której celem jest zrozumienie “jak coś działa”. Analiza ogromnych ilości zebranych danych, których źródłem są tylko obserwacje i fakty to paradoksalnie najgorsza metoda badawcza. Jako system raportowania (przetwarzanie danych) sprawdza się bardzo dobrze ale tylko do tego.
 Wystarczy (nomen omen) spojrzeć wstecz historii. Opis wszechświata bazujący wyłącznie na obserwacji to znany z czasów przedkopernikańskich układ geocentryczny. Jest efektem zapisów wyników obserwacji. W zasadzie rosnąca liczba tych obserwacji potwierdzała jedynie znany z tamtych czasów fałszywy model (patrz po lewej). Jest zawiły, niedający sie opisać prostymi zależnościami. Odkrycie nowej planety wymagałoby kolejnych setek obserwacji by opisać jej tor na tym rysunku.
Wystarczy (nomen omen) spojrzeć wstecz historii. Opis wszechświata bazujący wyłącznie na obserwacji to znany z czasów przedkopernikańskich układ geocentryczny. Jest efektem zapisów wyników obserwacji. W zasadzie rosnąca liczba tych obserwacji potwierdzała jedynie znany z tamtych czasów fałszywy model (patrz po lewej). Jest zawiły, niedający sie opisać prostymi zależnościami. Odkrycie nowej planety wymagałoby kolejnych setek obserwacji by opisać jej tor na tym rysunku.
Sytuacja zmienia się diametralnie po tym, jak Kopernik “poszedł w stronę” myślenia hipotezami. Nie zapisywał i nie porządkował pieczołowicie kolejnych bzdurnych pomiarów a szukał wytłumaczenia otrzymanych już (których zresztą mogło by być znacznie mniej). Jak wiemy Kopernik znalazł odpowiedź napytanie: jak wygląda wszechświat (teraz wiemy, że nasz to tylko jeden z wielu układów we wszechświecie). Zbudował prosty i łatwy do matematycznego (w porównaniu z tym po lewej) opisu model heliocentryczny i za jednym zamachem nie tylko wyjaśnił dotychczasowe obserwacje ale przewidział wszystkie następne.
Podobną metodę można zastosować do modelowania zjawisk gospodarczych, procesów biznesowych czy oprogramowania. Analiza przedsiębiorstwa nie musi polegać na dziesiątkach wywiadów, porządkowaniu ich treści i setkach diagramów, z których nic nie wynika. Analiza może polegać na analizie partii dokumentów, zbudowaniu modelu procesu i sprawdzeniu czy wyjaśnia inne zdarzenia w firmie. Taka analiza jest mniej kosztowna, produkuje znacznie mniej papieru, jest pozbawiona nieścisłości i nadmiaru nieprzydatnych danych. Niestety ile razy mówię o tym np. na konferencjach natychmiast większość firm doradczych wysłała by mnie na stos…
Ktoś mógłby zapytać: czy ma sens do każdego projektu angażować “naukowca”? Do każdego zapewne nie ale skoro wiemy z badań, że w projektach związanych z zarządzaniem lub dostarczaniem oprogramowania ponad 60% kosztów idzie w błoto z powodu złych analiz i projektów to sami sobie Państwo odpowiedzcie na to pytanie… bo praktyka pokazuje, że to w zasadzie zawsze jest tańsze :), niestety widać to dopiero po zakończeniu projektu… a co z analizą danych historycznych? Podobno, jak twierdzi Hegel, [[historia uczy ludzi, że historia niczego ludzi nie nauczyła]]…



“Hm… czy przypadkiem promowanie systemów hurtowni danych, BI, pracy z terabajtami danych itp.. to nie tworzenie sobie rynku przez dostawców tych technologii?”
Zawsze tak było i będzie, że dostawca będzie szukał zbytu na to co ma w ofercie.
Natomiast nie spotkałem się z innym zastosowaniem narzędzi BI niż “złożone systemy raportowania”
Co do tego: “nie sądzę by jakakolwiek hurtownia danych plus system BI odkryła cokolwiek nowego lub skutecznie prognozowała.”
Prognoza to tylko prognoza, wychodzi lepiej lub gorzej, ale na podstawie czegoś trzeba planować sprzedaż, produkcję, itp.
“Prognoza to tylko prognoza, wychodzi lepiej lub gorzej, ale na podstawie czegoś trzeba planować sprzedaż, produkcję, itp.”
Ale modele systemowe są znacznie skuteczniejsze niż statystyka, która raczej działa jak znana anegdota o indyku…