Wprowadzenie

Regularnie na moich szkoleniach oraz w toku projektów, dostaje pytania o “walidacje”. Z reguły spotykam specyfikacje wymagań (albo oczekiwania na takie), zawierające zestawienia dokumentów (i formatek ekranowych), dla każdego zestawienie pól, dla każdego pola “walidacje”. Problem w tym, że:
- mieszają się tu tak zwane typy proste danych (znakowe, liczbowe, itp.), tak zwane “maski” (data, email, itp.), oraz reguły biznesowe (np. właściwy rabat),
- z uwagi na to, że dokumentów jest wiele, a pola mogą się na nich powtarzać, powstaje duża liczba powtórzonych zapisów “walidacji”, niejednokrotnie niespójnych a bywa, że sprzecznych.
- typy proste oraz reguły biznesowe (logika biznesowa) to dwa zupełnie inne obszary systemu.
Jak definiować wymagania na “walidacje”
Tu warto na początek wrócić do klasyfikacji wymagań. W artykule Inżynieria wymagań opisałem trzy ich rodzaje:
- funkcjonalne czyli usługi aplikacji (przypadki użycia tej aplikacji),
- poza-funkcjonalne czyli cechy jakościowe,
- dziedzinowe czyli logika biznesowa.
I teraz bardzo ważna rzecz: które elementy architektury oprogramowania, za realizację których wymagań odpowiadają? W artykule Gdzie się realizują wymagania opisałem ogólnie wzorzec projektowy MVC. Pomijając sam wzorzec, istotne jest to, że tak zwane “walidacje” są dokonywane w dwóch różnych elementach architektury. Tak zwane typy proste danych (np. pole znakowe Nazwisko) są (mogą być) sprawdzone w momencie ich wprowadzania (np. formatka ekranowa nie przyjmuje cyfr w polu nazwisko). Cała logika biznesowa jest wykonywana wewnątrz aplikacji (informacje o ewentualnych błędach pojawią się po zatwierdzeniu formularza), np. upust może być sprawdzony (albo naliczony) dopiero po skompletowaniu danych wymaganych do jego wyliczenia, czyli będzie to kilka różnych pól (najmniej dwa :)). Bywa, że do wyliczenia czegoś potrzebne będą dane nie wprowadzane do danej formatki faktury, np. saldo klienta.
Jedną z najgorszych praktyk programistów jakie spotykam, jest umieszczanie logiki biznesowej (a są nią np. metody naliczania upustów) w formularzach ekranowych. Po pierwsze prowadzi to dużego obciążania kodu tych formatek, po drugie przy dużej ilości dokumentów (formatek ekranowych) logika biznesowa jest powielana, co prowadzi do dużych problemów z utrzymaniem spójności sprawdzanych reguł biznesowych w aplikacji. Po trzecie próby pisania interfejsów (API) do tych aplikacji (np. przyjmowanie dokumentów wystawionych poza aplikacją) jest niemożliwe bez kolejnego powielenia logiki biznesowej w API (jeżeli chcemy “walidować” przyjmowane tą drogą dane a z raczej chcemy). Jednym słowem masakra.
Sprawdzoną metodą skutecznego (spójność, kompletność, niesprzeczność) zapisywania wymagań dziedzinowych (w tym “walidacje”) jest wydzielenie w dokumentacji:
- słownika pojęć
- słownika reguł biznesowych
- specyfikacji tablic decyzyjnych jako uzupełnienia reguł biznesowych.
Słownik pojęć powinien obejmować wszystko to co stwarza ryzyko niejednoznaczności. Reguły biznesowe, wraz z tablicami decyzyjnymi (jeżeli są wymagane) zebrane w jednym miejscu (specyfikacja reguł), są niczym innym jak wymaganiami dziedzinowymi. Tak opracowana dokumentacja analityczna pozwala developerowi na łatwe poruszanie się po dokumencie, mamy możliwość weryfikacji wymagań, ich spójności i kompletności. Załączając specyfikacje wzorów dokumentów (mock-up’y ekranów czyli formatki ekranowe) każdy obszar takiego wzoru albo jest oczywisty, albo jest zdefiniowany (jako nazwa) w słowniku pojęć. Cała nietrywialna logika działania jest opisana regułami biznesowymi. Ogólne zasady tworzenia takiej dokumentacji:
- W toku analizy opracowujemy modele procesów biznesowych zawierające wyłącznie aktywności i ich produkty (czyli procesy biznesowe) i nic ponad to (dodatkowe szczegóły to albo procedury albo scenariusze przypadków użycia, to inne dokumenty).
- Na modelach procesów zaznaczamy wszystkie aktywności związane ze stosowaniem reguł biznesowych (konwencja dokumentowania reguł na modelach zależy od użytego narzędzia CASE). Reguły biznesowe uzupełniamy o ewentualne kryteria decyzyjne (np. w postaci tablic decyzyjnych).
- Równolegle prowadzimy słownik pojęć dla dokumentacji.
- Nie definiujemy (jako biznes, a nawet analityk biznesowy, zgłaszający wymagania) typów prostych, one są albo oczywiste, albo wynikają z definicji pojęć (w razie wątpliwości piszemy czym jest nazwisko w słowniku).
Ważna rzecz. Decyzje o tym jakimi typami danych operuje aplikacja, to decyzje developera (programisty). Moim zdaniem programista żądający w wymaganiach podania mu typów danych, jest nieukiem albo leniwym sabotażystą (użycie – wybór typów danych, w tym typów złożonych, to decyzje i kompetencje developera!).
Poniżej opisane elementy umieszczone na jednym schemacie blokowym:
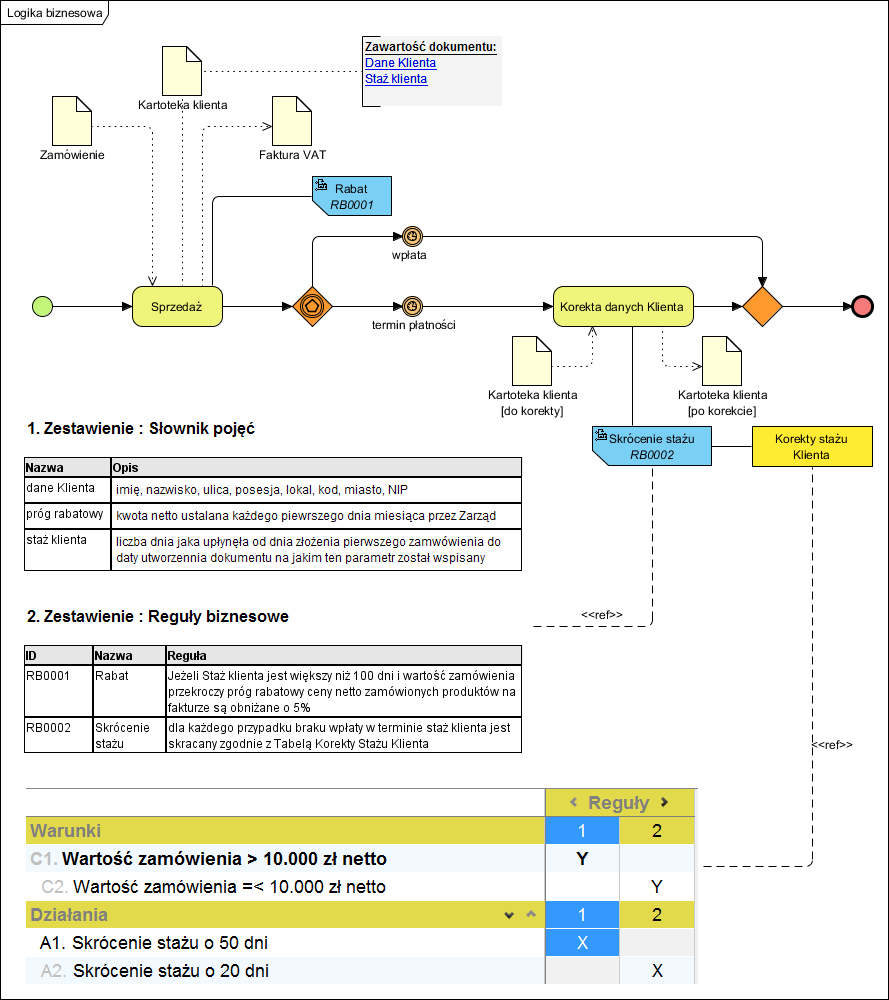
Tak więc, warto rozważyć stosowanie reguł biznesowych i słowników pojęć (Semantics Of Business Vocabulary And Rules), gdyż jest to sprawdzona i bardzo przydatna technika analizy i dokumentowania logiki biznesowej. Polecam także stronę The Business Rules Group i zamieszczony tam Manifest Reguł Biznesowych. Tworzenie monstrualnych dokumentów wymagań, zawierających dziesiątki razy powielane “walidacje” prowadzi do wielu kłopotów z utrzymaniem spójności i kompletności takich specyfikacji. Pomijam już ich uciążliwą objętość. Jako materiał dla programisty są one wtedy trudne w użyciu, do tego skłaniają do najgorszych praktyk, jakimi jest między innymi umieszczanie logiki biznesowej w kodzie formatek ekranowych.
Na koniec polecam książkę Building Business Solutions poświęcona temu zagadnieniu.



Na tym diagramie nie mamy informacji jak działa ‘Sprzedaż’, albo na czym polega ‘Korekta danych klienta’. Rozumiem, że tego nie opisujemy już diagramem BPMN? Nie rozwijamy (jak zaleca B.Silver w swojej książce ‘BPMN method and style…’) na pod procesy – gdzie ‘Sprzedaż’ i ‘Korekta..’ byłyby rodzicami, a opis działania procesów byłby przeniesiony na poziom niżej – bardziej szczegółowy.
W takim razie czym modelujemy szczegóły działania tych dwóch aktywności?
P.
BPMN to notacja opisująca procesy biznesowe a nie logikę oprogramowania. Szczegóły biznesowe każdego elementarnego procesu (aktywności) opisują albo procedury albo wymagania wobec wykonawcy (aktor wie jak to zrobić bo był na szkoleniu). Sprzedaż to wystawienie faktury VAT sprzedaży na podstawie danych z Zamówienia. Korekta danych klienta to nic innego jak ingerencja w treść wyświetlonej Kartoteki Klienta. Z perspektywy “aktora” systemu nie ma żadnych dodatkowych szczegółów, bo jakie? W wersji “prostej” stan początkowy to wyświetlona formatka ekranowa do wypełnienia, stan końcowy to formatka zatwierdzona. Taka aktywność (elementarny proces) mapowany jest jeden do jednego na przypadek użycia (usługę aplikacji, czyli zgodnie z SOA lub architekturą korporacyjną). Szczegóły przypadku użycia czyli dialog aktor-system, to scenariusz przypadku użycia (opis a lepiej diagram sekwencji UML).
Szczegóły to nie żadne podprocesy, a informacja i to jak ona powstaje lub jest modyfikowana. Odpowiedź na pytanie “Na czym polega ‘Korekta danych klienta'” polega na pokazaniu formularza Dane Klienta i stwierdzeniu, że mozna je modyfikować wg. określonych reguł (patrz reguły biznesowe).
https://it-consulting.pl/autoinstalator/wordpress/2021/03/28/struktury-formularzy-jako-forma-wyrazania-wymagan/