Regularnie spotykam się z monstrualnymi specyfikacjami: najpierw “wymagań” a potem “przypadków użycia”: dziesiątki, setki (o ich ilości napisałem tu). Na ich podstawie powstają wyceny – nie mniej kosmiczne. Jednak jeżeli zestawić to z badaniami projektów i oceną, że jedną z kluczowych przyczyn porażek jest nadmierna złożoność i niejednoznaczność specyfikacji wymagań, a potem samego projektu i jego zakresu oraz utrata panowania nad tym zakresem, to może warto się nad tym pochylić?
Kluczem jest definicja wymagania i często są nimi właśnie przypadki użycia. Pojęcie przypadku użycia (UML) i usługi (SoaML):
Przypadek użycia (UML, Superstructure v.2.4.1.): A use case is the specification of a set of actions performed by a system, which yields an observable result that is, typically, of value for one or more actors or other stakeholders of the system.
Usługa (SoaML, v.1.0.1.): Service is defined as the delivery of value to another party, enabled by one or more capabilities. Here, the access to the service is provided using a prescribed contract and is exercised consistent with constraints and policies as specified by the service contract.
Tak więc przypadek użycia jako efekt daje określony, wartościowy rezultat. Warto teraz w tym miejscu podkreślić, że SOA (patrz specyfikacja) zakłada, że usługa jako efekt (produkt) daje “Real World Effect defined as service operation post condition” co jest o tyle istotne, że analogicznie kończy się przypadek użycia (przypomnę, że “post condition” to stabilny stan systemu po wykonaniu operacji).
Popatrzmy teraz na pojęcie czynności w BPMN:
Aktywność a czynność: (BPMN, v.2.0) An Activity is work that is performed within a Business Process. An Activity can be atomic or non-atomic (compound). The types of Activities that are a part of a Process are: Task, Sub-Process, and Call Activity, which allows the inclusion of re-usable Tasks and Processes in the diagram. However, a Process is not a specific graphical object. Instead, it is a set of graphical objects. The following sections will focus on the graphical objects Sub-Process and Task. […] A Task is an atomic Activity within a Process flow. A Task is used when the work in the Process cannot be broken down to a finer level of detail.
Tu zaczyna się pragmatyka biznesowa, czyli definicja pojęcia proces biznesowy, która zakłada, że proces biznesowy (także elementarny, atomowy) to czynność lub łańcuch logicznie powiązanych czynności (aktywność), tworzy produkt mający wartość dla odbiorcy tego produktu (produkt musi się nadawać do biznesowego wykorzystania). Ta definicja jest niemalże kopia definicji przypadku użycia. Procesem biznesowym jest KAŻDA aktywność wraz z jej samodzielnie przydatnym biznesowo produktem (para aktywność i jej produkt, dlatego w BPMN nie ma jednej ikony na “proces biznesowy”). Jak widać, te trzy pojęcia: przypadek użycia aplikacji, usługa aplikacji oraz elementarny proces biznesowy (podkreślam, że projekty IT dla biznesu mają biznesowy kontekst co nadaje ściślejsze znaczenia tym trzem pojęciom), mają niemalże tożsame definicje (zresztą OMG dąży w tym właśnie kierunku). Popatrzmy tu:
The majority of today’s SOA design techniques 1,2,3 are centered around definition of services. They use 1service-oriented decomposition, based on the business processes, enterprise business/functional model, required long term architectural goals and reuse of the existing enterprise functionality. (Incorporating Enterprise Data into SOA).
Kluczem jest sugestia (uznanie), że elementarnym pojęciem do dekompozycji funkcjonalnej jest pojęcie elementarnej (atomowej) usługi (i nie jest nią jedna linia programu!) będącej także elementarnym procesem biznesowym. Popatrzmy na diagram obrazujący architekturę SOA (pochodzący z tego samego artykułu):
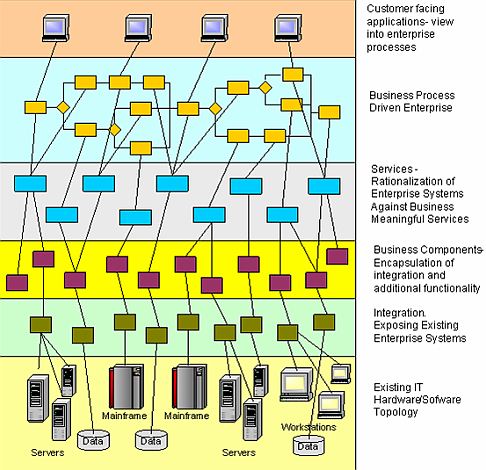
Mamy tu, między innymi, trzy ważne warstwy (tu drugą, trzecią i czwartą od góry), są to odpowiednio: procesy biznesowe, usługi aplikacyjne (ta warstwa to abstrakcja) oraz aplikacje świadczące te usługi. Mamy więc mapowanie elementarnych atomowych procesów (pojedynczych czynności) na elementarne usługi aplikacyjne. Usługi te, to nic innego jak przypadki użycia aplikacji, czyli każdą aplikację (jej użyteczność) można opisać z pomocą jej “przypadków użycia”, a te jak już wiemy, w UML służą – jak widać słusznie – do specyfikowania wymagań funkcjonalnych. Tu uwaga, nie należy tego mylić ze spotykanymi w literaturze “biznesowymi przypadkami użycia” (nie ma taki w UML).
Konwencja biznesowych przypadków użycia to relikt metody RUP z lat 90’tych, kiedy to nie było np. notacji BPMN, i tak zwany “biznesowy diagram przypadków użycia” opisywał firmę, jej usługi i klientów (aktorów), a nie aplikację (do dzisiaj jest to przyczyną wielu nieporozumień i powstawania niskiej jakości niejednoznacznych dokumentacji).
Tak więc, jak widać, można uznać (przyjąć), że przypadek użycia to usługa aplikacji, a ich gradację określa produkt jako użyteczność efektu. Co ciekawe, niektóre narzędzia CASE wspierają (ułatwiają) tworzenie (mapowanie) czynności (elementarnych procesów biznesowych) w procesach (notacja BPMN) na przypadki użycia (notacja UML).
Taksonomia wymagań, w tym biznesowe i przypadki użycia oraz usługi aplikacyjne (Produkty w procesie analizy wymagań):
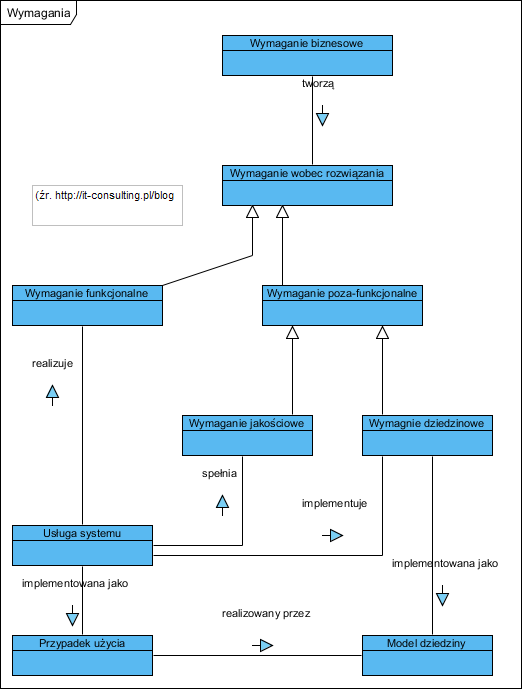
Warto tu teraz zwrócić uwagę, że wymagania funkcjonalne i poza-funkcjonalne, jakościowe i dziedzinowe oraz usługi systemu to elementy abstrakcyjne.
Tak na prawdę rzeczywiste są jedynie wymagania biznesowe jako oczekiwania zamawiającego wyrażone w jego języku, oraz przypadki użycia i model dziedziny, bo opisują rzeczywisty byt jakim jest (przyszły) produkt (aplikacja).
CRUD, czym jest?
CRUD to skrót od ang. Create, Retrieve, Update, Delete (Utwórz, Przywołaj, Zaktualizuj, Usuń). Są to cztery podstawowe operacje na tak zwanych kartotekach, obiektach służących do zapamiętywania informacji czyli pojedynczych “encji” (nie mylić z encjami w bazach relacyjnych) lub ich agregatach. Obiektami odpowiedzialnym za ich przechowywanie są repozytoria (Repository). Kluczowe cztery operacje udostępniane przez repozytorium to właśnie CRUD. Pytanie brzmi: czym jest kartoteka? Jest zbiorem kart (dokumentów) o jednakowej (lub podobnej) strukturze. Tak więc usługą jest “zarządzanie kartami”, czy też odrębnymi usługami są tworzenie karty, czytanie, uzupełnienie, usunięcie? Popatrzmy na to z perspektywy usługi dla użytkownika: ma sens posiadanie wygodnej szuflady z kartami w bibliotece ale czy ma sens samodzielna, wyjęta z kontekstu usługa “tworzenie nowych kart”? Można polemizować, ale jeżeli chcieć utrzymać spójność pojęciową i możliwość kontroli spójności i kompletności projektu i jego zakresu, lepiej uznać, że usługą aplikacyjną jest “zarządzanie kartami”. Po pierwsze taka usługa jest samowystarczalna, zaś samo tworzenie karty bez możliwości jej przywołania nie ma sensu, więc te cztery proste czynności są niejako nierozerwalnie związane, stanowiąc jedną usługę. Po drugie tworzenie nowego zapisu, modyfikowanie czy usuwanie, to kontekst użytkownika, w zasadzie każdą z czterech operacji CRUD można sprowadzić do scenariusza:
- pokaż kartę (pusta to tworzenie nowego zapisu)
- zrób z tym coś (wpisz nowe, zmień, usuń) i potwierdź (zachowaj skutek)
Dlatego są podstawy by uznać, że “zarządzanie kartami katalogowymi” to jednak jeden przypadek użycia, a poszczególne operacje, to kontekstowe warianty scenariusza wynikające z procesu czyli chwilowego celu użytkownika (aktora). To podobnie jak młotek (usługa dostępna ze skrzynki narzędziowej), to człowiek używa młotka w kontekście wbijanie gwoździa, zbijania szyby, rozbijania kamieni. Młotek w rękach człowieka po prostu służy do uderzania, więc przypadkiem użycia jest uderzanie a nie czynność w procesie zbijania budy dla psa jaką jest wbijanie gwoździ w deski. Podejście takie wcale nie jest nowe, w ciekawy sposób opisał to autor tego artykułu:
If you have ever been writing use cases for a data-oriented system (i.e. CMS), you have probably noticed that there is a problem with the large number of use cases like “Add an article”, “Remove an article” etc. If you have all CRUD operations available for all objects in the system, you can finish with up to 4 x number-of-objects of use cases. You can reduce this number by introducing the CRUD pattern, which I would like to present you in this blog entry. (CRUD Pattern in Use Cases ? PUT Software Engineering Team).
Można takie podejście (wynikające niejako wprost z definicji przytoczonych pojęć), jak widać, nazwać wzorcem projektowym :). Bardzo ładnie przekłada się to na architekturę (model oparty o wzorzec BCE), operującą pojęciami boundary (granica), controll ( sterowanie) i entity (nośnik informacji):

Na powyższym diagramie mamy dwa przypadki użycia: górny to typowy CRUD, dolny do usługa, np. obliczeniowa. Przypadek pierwszy (górny) dodatkowo korzysta z logiki “Samodzielna logika” tego drugiego PU (integracja dwóch aplikacji/komponentów).
Poniżej dwa ciekawe artykuły, rozwijające powyższe. Pierwszy to tak zwane mikro serwisy, wzorzec traktujący każdą usługę aplikacyjną 9a tym samym przypadek użycia) jako odrębną aplikację, drugi pokazuje jak projektować interfejsy w takich przypadkach.
“Microservices” – yet another new term on the crowded streets of software architecture. Although our natural inclination is to pass such things by with a contemptuous glance, this bit of terminology describes a style of software systems that we are finding more and more appealing. We’ve seen many projects use this style in the last few years, and results so far have been positive, so much so that for many of our colleagues this is becoming the default style for building enterprise applications. Sadly, however, there’s not much information that outlines what the microservice style is and how to do it. (Microservices).
Tell-Don’t-Ask is a principle that helps people remember that object-orientation is about bundling data with the functions that operate on that data. It reminds us that rather than asking an object for data and acting on that data, we should instead tell an object what to do. This encourages to move behavior into an object to go with the data. (TellDontAsk).
Na zakończenie
Analizy biznesowe wymagają oderwania się od technokracji, nie ma czegoś takiego jak dziesiątki przypadków użycia dla jednej faktury, nie ma systemowych przypadków użycia (nawet w specyfikacji UML ich nie znajdziecie), są kompletne (dające jako efekt przydatne produkty) usługi aplikacyjne i korzystający z tych usług aktorzy, w tym inne aplikacje lub komponenty. Dokumentacje zawierające setki przypadków użycia to nieporozumienie, technokratyczni zabójcy projektów. Warto się zastanowić zanim powierzycie analizę i projekt logiki systemu technokratycznemu developerowi… Zapraszam do lektury kolejnego artykułu o zarządzaniu szczegółowością analizy..



Odniosę się do fragmentu mówiącego, że przypadki użycia to wymagania. Czy to jest dobre porównanie? Bo w takim razie jak rozumieć podział w VisualParadigm na Przypadki użycia i Wymagania. One są tam oddzielnymi bytami, powiązanymi jakoś ze sobą, ale istnieją samodzielnie.
To jak to jest w trakcie zbierania wymagań? Zbieramy PU czy wymagania? Słownikowo nie jest to to samo, ale też granice są określone jak w średniowieczu między sąsiednimi krajami – potrafią się zazębiać.
W VP notujemy zarówno PU jak i Wymagania. Jeśli założymy, że wymaganiem jest PU, to po grzyba osobny byt Wymagania w VP? Zajmujemy się nim w takim razie, czy pomijamy?
Wymagania w VP to wymagania z notacji SysML, ta wymaga i tak taksonomii (z reguły są to wymagania: biznesowe, funkcjonalne, itp…), notacje to narzędzia i pojęcia notacyjne, kontekst wynika z rodzaju projektu i przyjętej “polityki” a przede wszystkim, należy mieć dla całego projektu spójny system pojęć, bez czego dokumentacja jest po prostu niespójna. taką spójność daje nam np. uznanie, że szkieletem jest SOA/Architektura korporacyjna, wobec tego mając pojęcie “usługa aplikacyjna” kojarzymy je z pojęciem “proces biznesowy” i uznajemy, że abstrakcją takiej usługi jest “przypadek użycia aplikacji”. To dopiero daje nam pełną kontrolę nad zakresem projektu i szkielet architektury oraz spójność całej analizy i projektu od ogółu do szczegółu. W przeciwnym przypadku możemy dostać listę “wymagań funkcjonalnych i poza-funkcjonalnych”, która nijak się ma do przypadków użycia, procesów biznesowych itp. Zarządzanie taka listą graniczy z cudem.
dodałem do treści artykułu taksonomię wymagań by pokazać związek (śladowanie) pomiędzy wymaganiami biznesowymi, usługami systemu a jego przypadkami użycia i architekturą (model dziedziny) systemu.
W jaki sposób w dokumentacj przypadku użycia CRUD zdefiniować warunki końcowe? Można po prostu napisać, np: dokument utoworzony / zmieniony / usunięty?
W zasadzie stan końcowy dla CRUD to poprawnie (należy to opisać) zapisany obiekt, pewną abstrakcją będzie tu obiekt “poprawnie usunięty” ;). Innymi słowy każda operacja C i U na fakturze zakończy się zapisaniem poprawnej faktury, pewnym specyficznym przypadkiem jest jej usunięcie :). To dlatego, często można się spotkać z wyłączaniem operacji usuwanie z tego “zestawu”. Co to R (retrieve czyli samo bierne czytanie) to przerwany scenariusz U. Warto nie zapominać, że dotarcie do treści dokumentu to nieukończone polecenie modyfikacji (nieukończone z powodu zaniechania lub braku praw do modyfikacji).
Bardzo fajnie ujęty temat. Obecnie w projekcie mam tonę przypadków użycia na n formularzy bo ktoś uznał, że da to możliwość kontroli wykonania implementacji i testów (rozliczalność). Przy takim rozdrobnieniu padliśmy w projekcie ofiarą tego, że zaczęto rozdzielać jeszcze na przypadki te same funkcjonalności dostępne przez UI a osobno na dostępne przez wystawione na API mikroserwisy. Zarządzanie zakresem już dawno padło. Można by napisać podręcznik jak nie należy prowadzić projektów. Piszę projektów bo błąd nie tyle co był po stronie analizy po stronie Wykonawcy a raczej zarządzania przez Zamawiającego projektem, co skutkowało lawiną błędów.
Przypadki użycia są potężnie nadużywane, można o tym faktycznie książkę napisać. Dlatego zawsze polecam by autor dokumentacji opartej na przypadkach użycia podał na początku definicję przypadku użycia z jakiej skorzystał… 😉