Wprowadzenie
Przypadki użycia już opisywałem, między innymi w artykule Paradygmat obiektowy i przypadki użycia, jednak dotyczył on błędów popełnianych przy tworzeniu tych diagramów. Tak więc teraz jak najbardziej sensowne jest odpowiedzieć na kolejne pytanie: skoro nie na diagramie przypadków użycia, to gdzie mają być szczegóły? No i dostałem takiego maila (z oczywistych powodów został zanonimizowany i uproszczony):
Witam, Będę wdzięczny za podpowiedź. Jeśli modelujemy diagram przypadków użycia systemu, gdzie aktorem jest użytkownik back office i jednym z przypadków użycia jest modyfikacja danych klienta. To w jaki sposób najlepiej wyrazić, że w ramach tej modyfikacji można:
1. Zaktualizować imię i nazwisko.
2. Adres.
3. Zgodę na przetwarzanie danych.
Itd.
A) Czy najlepiej stworzyć dedykowany diagram uszczegóławiający poszczególne opcje modyfikacji?
B) Czy na głównym diagramie przypadek użycia z modyfikacja powinien zostać rozszerzony przez extend’y i kolejne przypadki użycia – będzie wtedy dość gęsto bo są też inne przypadki użycia.
C) Możliwe opcje do modyfikacji powinny zostać opisane w formie treści do przypadku użycia związanego z modyfikacją?
Która opcja będzie najbardziej odpowiednia? I znowu odpowiem przykładem.
Biblioteka
W ww. poprzednim swoim artykule przywoływałem już treść specyfikacji UML traktującej o przypadkach użycia. Tu więc od razu przykładowy diagram.
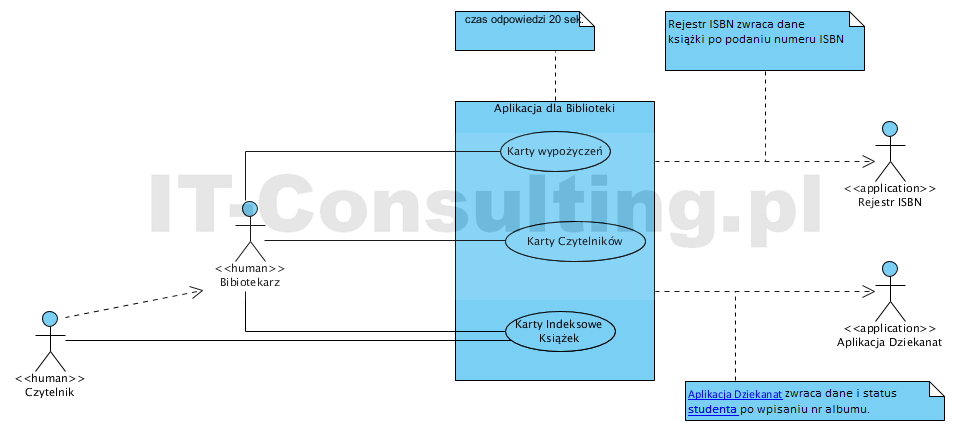
Na diagramie widać, że od aplikacji oczekujemy: Kart wypożyczeń, Kart czytelników i Kart indeksowych książek.
Nazwy przypadków użycia to kwestia przyjętej konwencji. Dość często spotykana konwencja to cele aktora (np. zarządzanie wypożyczeniami), jednak jak już swego czasu pisałem, konteksty aktora (często user story) nie są dobre jako nazwa usługi aplikacji, bo bardzo często prowadzą do nieuzasadnionego komplikowania tego diagramu. Osobiście stosuję konwencję opartą na nazwach zestawów informacji (dokument, mock-up ekranu) jakimi aplikacja zarządza (pamiętajmy, że system “nie wie” w jakim celu jest używany, to wie jedynie aktor). Dlatego tu mamy Karty wypożyczeń, a nie osobne: Wypożyczenia i Zwroty, bo zwrot książki polega na wpisaniu daty zwrotu na Karcie wypożyczenia, nie jest to osobny przypadek użycia (!), a kolejny kontekst użycia usługi Karty wypożyczeń. Tak więc aplikacja świadczy usługę (przypadek użycia) Karty wypożyczeń a nie dwie: wypożyczenia książek i zwroty książek, bo to są konteksty aktora (może ich być więcej o czym za chwilę). Pozostałe dwa przypadki użycia analogicznie.
No i teraz pytanie: jak pokazać, że możliwe jest zaktualizowanie określonych danych? Np. wskazane powyżej dodanie daty zwrotu? Musimy mieć makietę Karty wypożyczenia:
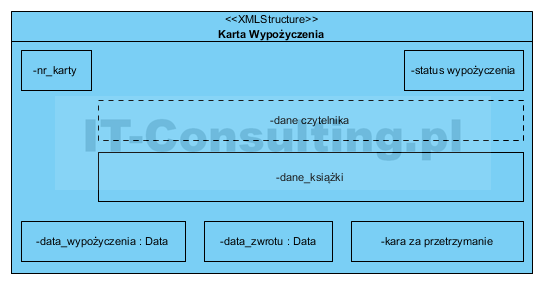
Jak widać to tu właśnie jest miejsce na zapis faktu, że czynność (aktywność w procesie biznesowym) zwrot książki polega na wprowadzeniu daty oddania książki w pole data_zwrotu. Najgorszym pomysłem było by dodanie kolejnego przypadku użycia na diagramie przypadków użycia.
A co np. z wymaganiem: “system powinien pozwalać na naliczanie kar za przetrzymanie książki”. I znowu: najgorszy pomysł to kolejny nowy przypadek użycia: naliczanie kar. Naliczenie kary to wykonanie operacji na polach data wypożyczenia i data zwrotu, oraz zapisanie wyniku w polu kara za przetrzymanie. Realizacja tego wymagania to modyfikacja (uzupełnienie) makiety Karty wypożyczenia, a nie powiększanie diagramu przypadków użycia.Makieta formularza służy właśnie do zapisywania takich szczegółów. Wzór na naliczenie kary zapisujemy osobno jako regułę biznesową, np: “Jeżeli książka nie zostanie zwrócona w czasie określonym przez Regulamin biblioteki, należy naliczyć karę w wysokości określonej przez ten regulamin”. To znaczy, że albo aktor sam nalicza i wpisuje wysokość pobranej kary, albo potrzebny będzie kolejny przypadek użycia (nie ma go na powyższym diagramie), np. Ustawienie parametrów systemu, udokumentowany kolejną makietą, zawierającą między innymi maksymalną liczbę dni wypożyczenia i karę za każdy dzień przetrzymania. To pozwoliło by naliczać kary automatycznie.
Na powyższym diagramie przypadków użycia pokazałem także realizację wymagania “system powinien podpowiadać dane książki po wpisaniu numeru ISBN (detale tego jak sie to odbywa dokumentuje sie w scenariuszu – diagram sekwencji – Dodaj książkę, przypadku użycia Karty Indeksowe Książek, przypominam, że przypadek może mieć więcej niż jeden scenariusz). Kolejne wymaganie: “system powinien kontrolować to, czy czytelnik nie został skreślony z listy studentów” zostało zrealizowane z pomocą integracji z aplikacją Dziekanat w sposób analogiczny jak opis dla ISBN.
A.Cocburn pisze w Hexagonal architecture :
Przypadki użycia i granica aplikacji
https://alistair.cockburn.us/hexagonal-architecture/
Przydatne jest użycie sześciokątnego wzorca architektury, aby wzmocnić preferowany sposób pisania przypadków użycia. Częstym błędem jest pisanie przypadków użycia, które zawierają intymną wiedzę na temat technologii znajdującej się poza każdym portem. Te przypadki użycia zyskały słusznie złą sławę w branży, ponieważ są długie, trudne do odczytania, nudne, kruche i kosztowne w utrzymaniu.Rozumiejąc architekturę portów i adapterów, widzimy, że przypadki użycia powinny być generalnie pisane na granicy aplikacji (wewnętrzny sześciokąt), aby określić funkcje i zdarzenia obsługiwane przez aplikację, niezależnie od technologii zewnętrznej. Te przypadki użycia są krótsze, łatwiejsze do odczytania, tańsze w utrzymaniu i bardziej stabilne w czasie.
Na zakończenie
Tworzenie diagramów np. jak ten:

mija się z celem. Jest to diagram, który nie pomoże developerowi, nie zawiera żadnych istotnych danych, a użycie go do dokonania wyceny np. metodą punktów funkcyjnych czy COSMIC , da w efekcie wysoce zawyżone, nieadekwatne wyniki.
Sposób dokumentowania reguł biznesowych opisałem w artykule: SBVR czyli reguły biznesowe i słownik. a tworzenie makiet formularzy w Wymagania na formularze czyli diagram struktur złożonych.
Pełna dokumentacja systemu dla biblioteki zostanie niebawem umieszczona na blogu. Zapoznaj się także z Dokumentowanie przypadków użycia.