Wprowadzenie
Gdybym miał ocenić statystycznie diagram klas opisywany w książkach o UML , projektach jakie widuję nie tylko w pracach studentów, to powiedział bym, że jest jakiś problem z nimi.
Jeżeli jakaś aplikacja ma powyższą strukturę to jest to absolutny dramat architektoniczny: typowy spaghetti modeling bez podziału na komponenty.
Dlaczego? Pokaże to, co moim zdaniem jest chyba nie tak. Szczególnie jak ktoś uważa, że diagram klas do model danych co wprost prowadzi do antywzorca obiektowego o nazwie anemiczny model dziedziny ?*?Ten artykuł to kontynuacja poprzedniego artykułu o modelach dziedziny systemu.
Bo nie ma czego takiego jak “diagram klas dla projektu”.
Klasa i klasyfikator
Pojęcia klasa i klasyfikator mają swój rodowód w teorii zbiorów, gdzie pojęcie klasyfikator oznacza definicję elementów zbioru: np. zbiór rzeczy czerwonych, zbiór rzeczy mających cztery koła, kierownice i silnik czy też zbiór rzecz które można bezpiecznie zjeść. Klasa zaś to nazwa tego zbioru.
W języku polskim klasa oznacza:
«kategoria przedmiotów lub zjawisk wyróżnianych na podstawie wspólnych cech lub kategoria przedmiotów jednakowej jakości»
log. «zbiór przedmiotów wyodrębnionych ze względu na posiadaną przez nie pewną wspólną cechę»
Klasyfikator to:
w matematyce (logika) jest to reguła która pozwala odróżnić elementy określonego zbioru od pozostałych elementów.
Jako ludzie na co dzień posługujemy się tak zwanymi definicjami sprawozdawczymi (opisowymi) czyli definiujemy rzeczy opisując je “prozą”. Np. słownikowa, opisowa, definicja psa brzmi: pies to “zwierzę domowe hodowane m.in. dla przyjemności lub do polowań” (SJP). Innym rodzajem definicji są definicje atrybutowe (zwane w logice: realne). Są to definicje budowane na cechach wyróżniających daną rzecz od innych, np. “pies to coś co szczeka [wydawany dźwięk to szczekanie]” (gdyby było prawdą, że faktycznie poza psem nikt i nic nie szczeka). .
Możemy więc powiedzieć, że słowo “pies” oznacza klasę [zwierząt, wszystkie zwierzęta], które szczekają. Klasyfikatorem jest fakt, że dźwięki jakie one wydają to szczekanie.
Notacja UML została zbudowana na logice więc rzeczy definiowane są poprzez ich cechy: atrybuty i zachowania (operacje). Powody są prozaiczne: wzory matematyczne “nie myślą i nie rozumieją” więc definicje opisowe (sprawozdawcze) nie mogą być tu stosowane.
I tak powstało pojęcie Klasa i Klasyfikator w UML. Pierwotnie zostało zawężone do kodu programu (obiektowo zorientowane języki programowania), w którym rzeczy realne były reprezentowane przez obiekty w pamięci komputera. Pierwszym takim językiem był język Simula w wersji z roku 1967.
W latach siedemdziesiątych Simula stała się inspiracją do stworzenia pierwszego w pełni obiektowego języka Smalltalk, którego opracowanie miało istotny wpływ na rozwój teorii programowania obiektowego. Strasznie się to później zemściło gdy powstał język C++ a potem JavaEE (EJB). Autorzy książek podchwycili tezę, że “paradygmat obiektowy polega na dziedziczeniu oraz łączeniu funkcji i danych w obiekty”. Niestety, to nie jest prawda: “paradygmat obiektowy to hermetyczne obiekty i ich wzajemna komunikacja i kluczowym elementem jest tu obiekt i komunikat”:
UML powstał jako konglomerat trzech notacji, których autorami byli: Rumbaugh, Booch, Jacobson (co ciekawe, Jacobson początkowo nie używał związków extend i include), a celem było modelowanie przyszłego kodu oprogramowania.
Unified Modeling Language
Specyfikacja OMG.org o klasach i klasyfikatorach:

9 Klasyfikacja
9.1 Podsumowanie
Klasyfikacja jest ważną techniką organizacji. Niniejszy rozdział określa pojęcia związane z klasyfikacją. Podstawowym
jest Klasyfikator, jest to abstrakcyjna metaklasa, której podklasy [specjalizacje] są używane do klasyfikowania różnych rodzajów wartości [rzeczy]. Inne metaklasy w tym rozdziale reprezentują składniki Klasyfikatora, które są modelem tego, jak na bazie Klasyfikatorów są tworzone ich instancje za pomocą Specyfikacji Instancji oraz różne relacje między wszystkimi tymi pojęciami.
Innymi słowy klasa to abstrakcyjne pojęcie i cały rozdział 9. specyfikacji UML jest bardzo abstrakcyjny, w zasadzie jest definicją pojęć. Dopiero rozdz. 11 Structured Classifiers, pokazuje praktyczne przykłady, tu już w odniesieniu do kodowania:
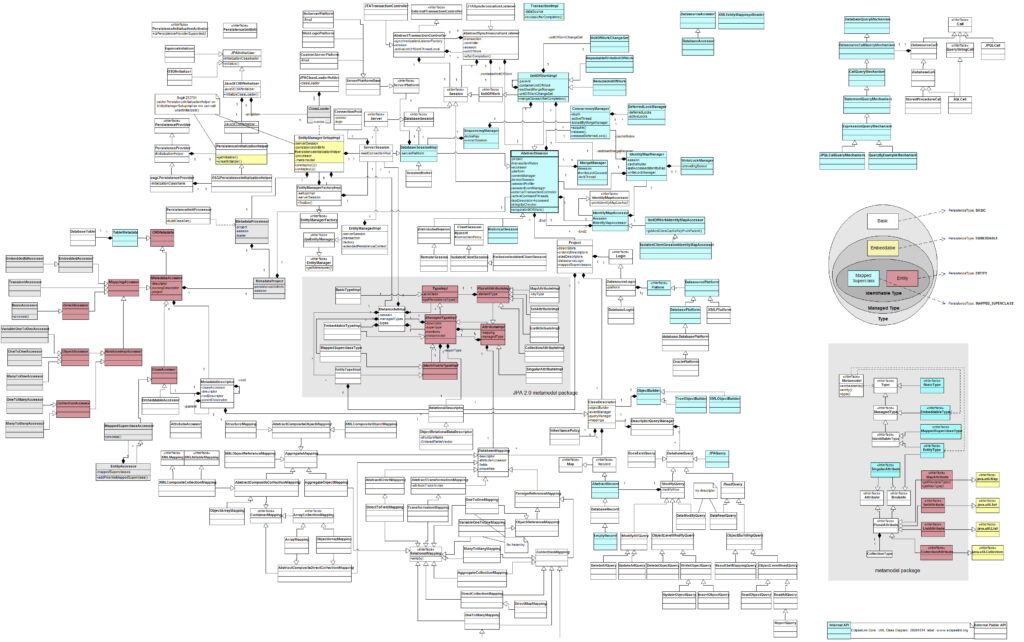
Zależnie od potrzeby, możemy użyć samej nazwy, prostej reprezentacji z atrybutami i operacjami, możemy dodać typy wartości atrybutów i widoczność operacji. Zastosowania diagramów klas (i UML w ogóle) są bardzo szerokie, inżynieria oprogramowania to tylko jedno z wielu.
Model pojęciowy czyli taksonomia i cechy
Przede wszystkim analiza to nie projekt, powinna pokazać obiektywny stan faktyczny. Druga rzecz, o tym już niektórzy zapominają: wynikiem analizy jest dokumentacja zrozumienia, tak więc model analityczny nie może być modelem pokazującym stan po uproszczeniach. To powinien być model rzeczywistości z naniesionymi, zastosowanymi lokalnie, ograniczeniami i uproszczeniami. Innymi słowy: dla fabryki spodni budujemy kompletny model człowieka (manekin) z komentarzem, że tu w użyciu jest część od pasa w dół a nie wmawiamy nikomu, że w tej fabryce człowiek składa sie wyłącznie z bioder i nóg. W przeciwnym wypadku, przyszła rozbudowa systemu będzie co najmniej problematyczna.
Produkt analizy przekazuje informację o tym co zastano, opisuje pojęcia i reguły jakie nimi rządzą. Tak na prawdę, opisać firmę (organizację) to znaczy stworzyć listę pojęć jakimi się w niej operuje (jakimi można ją opisać) i reguły jakie ograniczają swobodę użycia (funkcjonowania) tych pojęć. Model pojęciowy (ich specyfikacja) to semantyka systemu, ograniczenia swobody ich wzajemnego kojarzenia to syntaktyka, i na koniec dziedzinowe ograniczenie swobody ich użycia to pragmatyka. Wkrada się tu także przydatne pojęcie jakim jest entropia czyli miara nieuporządkowania. Tak więc mamy system pojęć, jego entropia (stopień nieuporządkowania) jest ograniczona syntaktyką i pragmatyką specyficzną dla dziedziny i miejsca (organizacji). Co to oznacza dla analizy przedwdrożniowej?
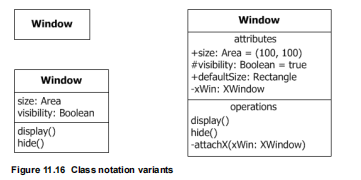
Jednym z celów tej analizy jest odkrycie i zapisanie wiedzy o podmiocie “informatyzowanym”. Jak ją zapisać? Ano właśnie tak: zbudować listę pojęć i wskazać opisane ograniczenia. Doskonałym narzędziem do tego jest diagram klas (odradzam diagram ERD, można go później zbudować w oparciu o model pojęciowy, jeżeli zajdzie taka potrzeba, ale nie należy tych dwóch modeli stosować zamiennie). Diagram klas opisujący taki system pojęciowy to tak zwana przestrzeń pojęciowa (namespace) . Przykłady :
Powyżej pokazano model pojęciowy (ontologia) czyli taksonomię (systematyka pojęć) i predykaty czyli związki semantyczne miedzy pojęciami. Taksonomia to klasy połączone związkiem generalizacji. Od góry czytamy to “dzielimy na” a od dołu czytamy “jest rodzajem”. Predykaty (związki zdaniowe) pokazują związki między pojęciami tworzące prawdziwe zdania w danej dziedzinie (opisują ją). Np. “Sklep realizuje zakup od dostawcy?” czy “Sklep prowadzi handel”. Celem tworzenia tego modelu jest wykazanie spójności i niesprzeczności pojęć dziedzinowych. Będą one używane jako kluczowe pojęcia w regułach biznesowych oraz jako nazwy np. pól czy ich wartości. Na modelach pojęciowych pokazujemy wyłącznie nazwę (klasa, pojęcie).
Klasy definiujemy opisowo na użytek ludzi oraz atrybutowo na użytek systemów przetwarzania danych. Przykład z innej dziedziny:
Cechą produktu jest kolor a barwa to wartość. Atrybut i cecha w języku potocznym to synonimy, ale:
- cechą samochodu jest jego kolor
- cechą samochodu jest także to, że ma koła
Dlatego analizując daną dziedzinę trzeba wiedzieć czym są tak zwane cechy definiujące produktu:
- kolor nie czyni przedmiotu samochodem
- ale posiadanie kół owszem
Jednak w przypadku flagi lub logo firmy, kolor jest cechą definiującą i należy z bardzo dużym zrozumieniem tego prowadzić te analizy: UML operuje tylko pojęciem klasa, atrybut, operacja. Kwestia tego czy są to cechy definiujące to problem który powinien rozwiązać analityk-projektant. jest to bardzo ważne przy projektowaniu dokumentów i formularzy. Dlatego używanie pojęcia klasy wymaga “zastanowienia” bo to ma więcej niż jeden kontakt:
- inny w kodzie
- inny w ontologii
a tu i tu używamy pojęcia klasy i klasyfikatora.
Model dziedziny to model mechanizmu działania
Klasa to dość ogólne pojęcie w UML i

11 Klasyfikatory strukturalne
11.1 Podsumowanie
Klasyfikatory Strukturalne to klasyfikatory, które mogą mieć wewnętrzną strukturę obejmującą sieć powiązanych ról (które same mogą być instancjami klasyfikatorów strukturalnych, a także mogą być instancjami klasyfikatorów strukturalnych) i zewnętrzną strukturę składającą się z jednego lub więcej portów. Porty (hermetyzowane klasyfikatory) działają jako “lokalni agenci zdalnych współpracowników”, umożliwiając rozróżnianie między nimi, ale bez bezpośredniego połączenia z nimi. Klasy, komponenty, asocjacje i kolaboracje to konkretne metaklasy, które wykorzystują te możliwości.
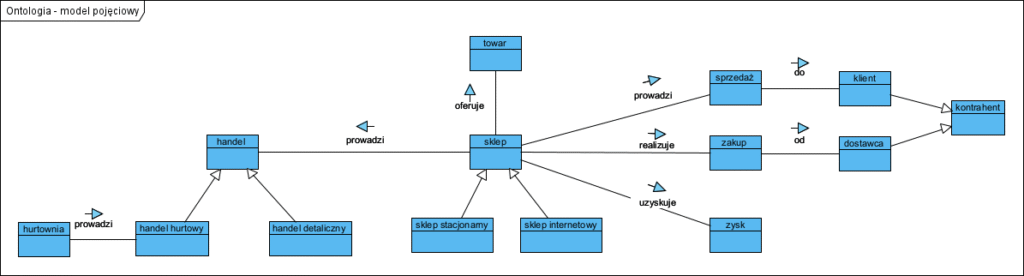
Ten niestety zawiły, troszkę akademicki, opis mówi nam, że: klasyfikator strukturalny to złożona konstrukcja składająca się z klas podrzędnych (zawartych). Całość tworzy określony złożony (strukturalny) byt, pewna konstrukcję. Elementy tej konstrukcji współpracują z sobą (ścieżki wymiany komunikatów). Porty to “punkty styku”. Specyfikacja UML zawiera taki przykład:
Jest on niestety mało czytelny i mało zrozumiały, dlatego poniżej pokazałem to na realnym projekcie (pominął porty by nie zaciemniać modeli).
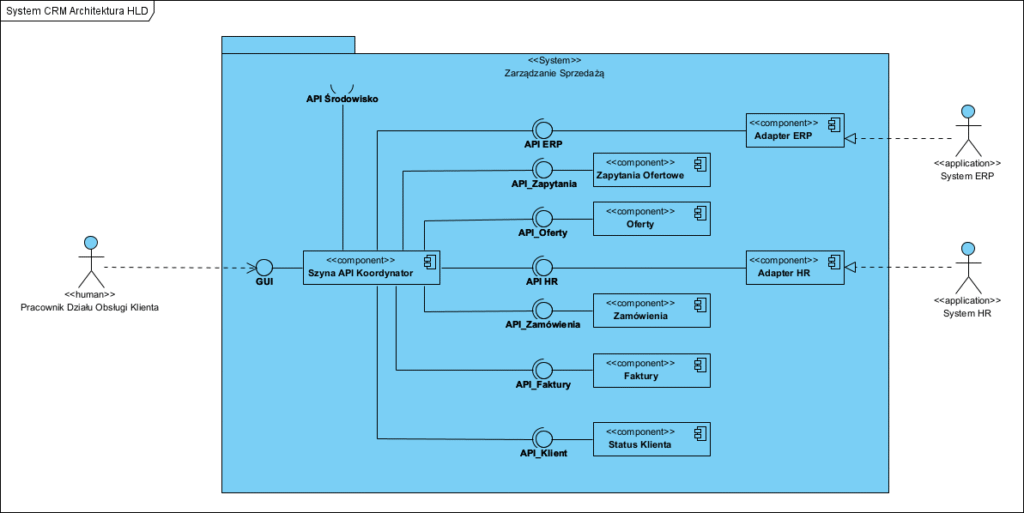
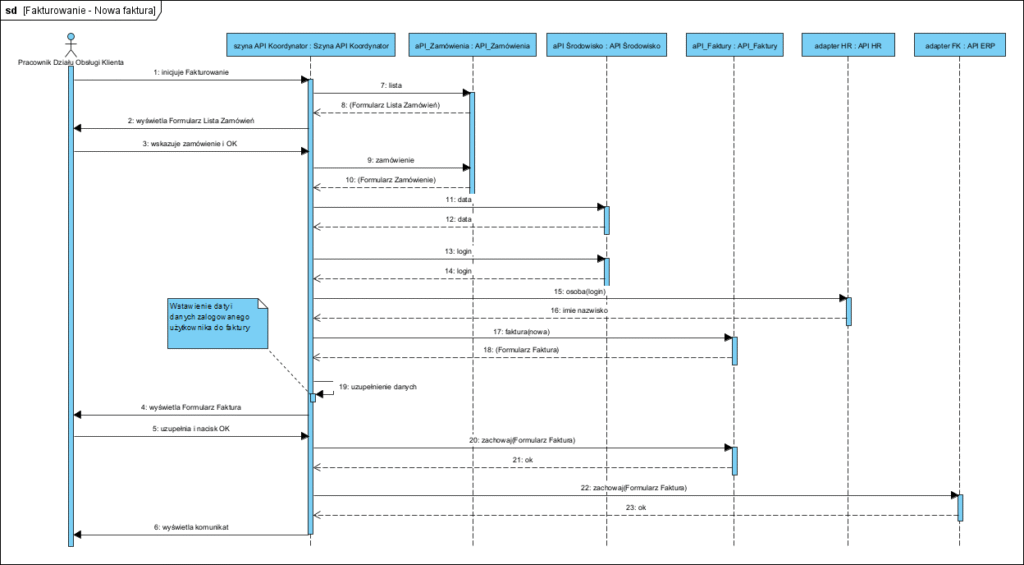
Z uwagi na to, że taki model pokazuje architekturę ale nie tłumaczy “jak to działa”, zawsze opisujemy jego zachowania z pomocą diagramów sekwencji, poniżej jeden przykładowy:
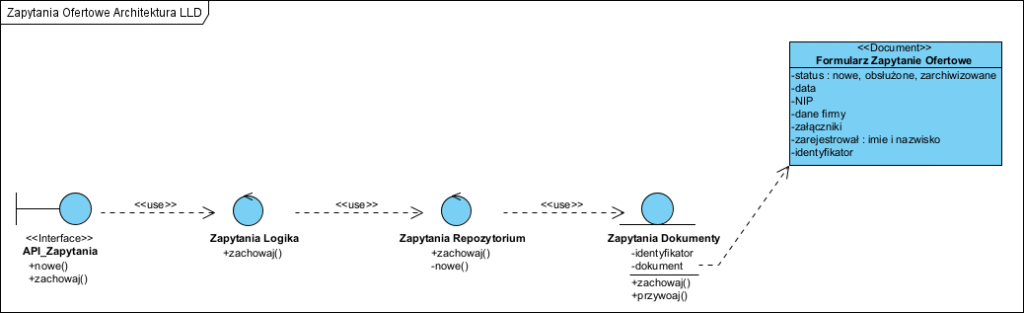
Każdy komponent ma swoją wewnętrzną architekturę i tu znowu kolejny diagram klas:
Działanie tego komponentu także dokumentujemy diagramem sekwencji:
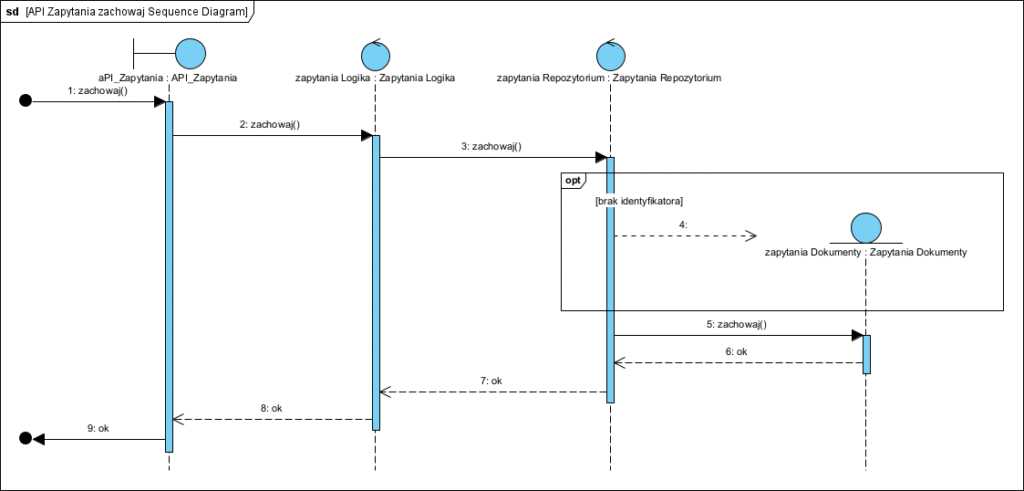
Na powyższych dwóch diagramach klas użyto wzorca BCE (patrz wzorzec BCE).
Formularz czyli struktura danych
Kolejny diagram klas to Diagram Struktur Złożonych. W specyfikacji jest wymieniony z nazwy a przykłady są dość “odjazdowe”:
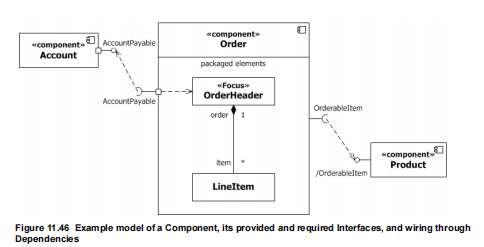
Dlatego tu bardziej pomocne są opracowania naukowe, niektóre pisane przez członków OMG:
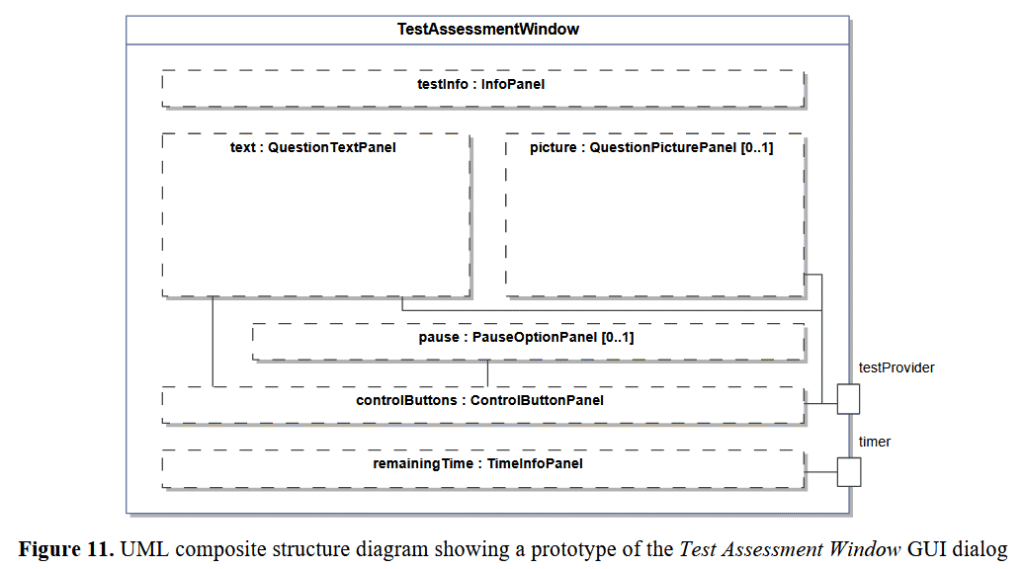
Tu znowu posłużę bardziej czytelnym przykładem:
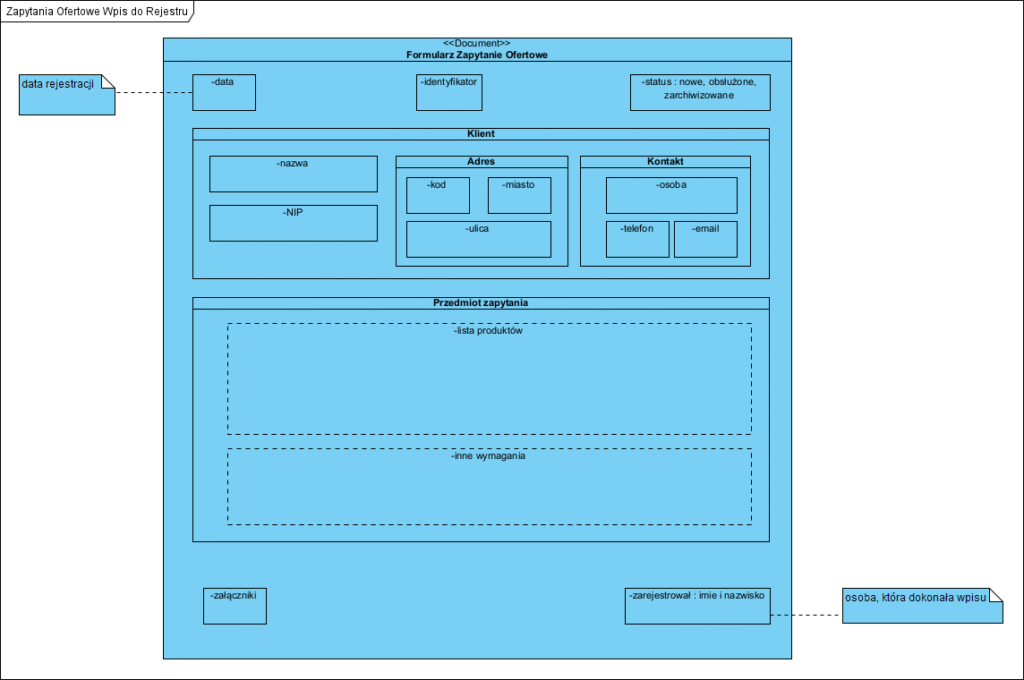
Powyższe jest relatywnie łatwe do zrozumienia. Poniżej “zwykły diagram klas” obrazujący to samo:
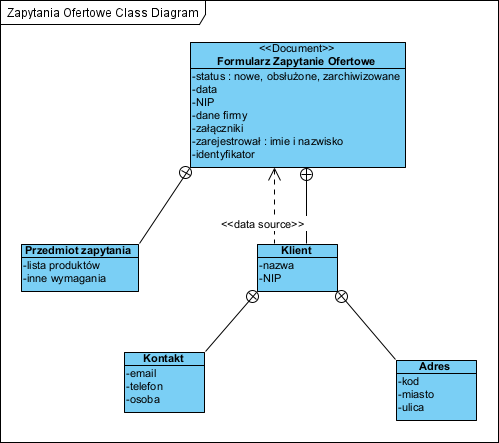
Na powyższych diagramach użyto stereotypu i słowa kluczowego UML “Document”, ta klasa nie ma operacji.

Tak więc warto zwrócić uwagę na to, że diagram klas diagramowi nie równy, to samo narzędzie może posłużyć do wielu różnych celów w tej samej dokumentacji. Widać także (mam nadzieję), że próba pokazania na jednym diagramie zarówno systemu pojęć jak i sposobu ich przetwarzania, jako informacji w systemach informatycznych, jest raczej błędnym podejściem. Wydaje mi się, że podejmowanie takich prób świadczy o niezrozumieniu różnicy pomiędzy systemem pojęciowym a modelem przetwarzania informacji. W szczególności gdy dotyczy to systemów obiektowych.
Powyższe przykłady pochodzą z:
C++, Java i podobne języki
Paradygmat obiektowy to hermetyzacja i komunikacja, a nie “dziedziczenie i łączenie danych i funkcji w obiekty”. C++/C# czy Java nie są reprezentacją obiektowego paradygmatu i niosą ze sobą narastający dług technologiczny:
Popatrzmy także na to:
W tym filmie przedstawiamy niektóre z technik stosowanych przez autorów kompilatorów w celu osiągnięcia mechanizmów języków obiektowych. Ciekawie jest zobaczyć, jak blisko C++ jest do C i jak proste są te mechanizmy pod maską. Chociaż film koncentruje się na C++, podobne techniki są stosowane przez wirtualną maszynę Javy, wirtualną maszynę .Net w C# i wiele innych języków OO.
https://youtu.be/HClSfuT2bFA?si=b5W7dLOkjRTPLGbf
Od pewnego czasu [2024] słyszę od deweloperów: Teraz w Javie króluje Spring. Słyszał pan o nim? Jestem ciekaw opinii
Tak, słyszałem:
“The Spring Framework is an application framework and inversion of control container for the Java platform.[2] The framework’s core features can be used by any Java application, but there are extensions for building web applications on top of the Java EE (Enterprise Edition) platform. The framework does not impose any specific programming model.[citation needed]. The framework has become popular in the Java community as an addition to the Enterprise JavaBeans (EJB) model.[3] The Spring Framework is free and open source software.[4]: 121–122 [5]”
[https://en.wikipedia.org/wiki/Spring_Framework]
Czym jest Enterprise JavaBeans (EJB) model?
“Java Beans, As part of the standardization, all beans must be serializable, have a zero-argument constructor, and allow access to properties using getter and setter methods.”
[https://en.wikipedia.org/wiki/JavaBeans]
To oceniane jako najgorsze metody w postaci “access to properties using getter and setter methods”.
“Every getter and setter in your code represents a failure to encapsulate and creates unnecessary coupling. A profusion of getters and setters (also referred to as accessors, accessor methods, and properties) is a sign of a poorly-designed set of classes.”
[https://typicalprogrammer.com/doing-it-wrong-getters-and-setters]
(patrz także: https://www.infoworld.com/article/2073723/why-getter-and-setter-methods-are-evil.html)
“Anemiczny model dziedziny (ang. Anemic Domain Model): Antywzorzec opisany przez Martina Fowlera. W tym przypadku model dziedziny składa się z klas z atrybutami bez metod, nie jest więc obiektowy. Logika biznesowa przeniesiona jest do innych klas, które transformują klasy dziedziny zmieniając ich stan (stąd nazwa Fowlera: skrypty transakcyjne). Antywzorzec ten przedmiotem wielu dyskusji – znaczna część metodyk tworzenia oprogramowania w Javie (w tym EJB) operuje na takim modelu. Duża część projektantów przenosi też swoje przyzwyczajenia z modelowania baz danych modelując system w ten sposób.”
https://pl.wikipedia.org/wiki/Antywzorzec_projektowy
znaczna część metodyk tworzenia oprogramowania w Javie (w tym EJB) operuje na takim modelu (patrz https://martinfowler.com/bliki/AnemicDomainModel.html, programistom polecam także te strony). Warto też pamiętać, że w 2015 roku zmieniła się specyfikacja UML, usunięto pojęcie dziedziczenia i agregacji, sugeruję uzupełnić wiedzę wpisami na blogu, które powstały po 2015 roku.



Czyli taksonomię (niebieskie) przygotowujemy na wczesnym etapie i zatwierdzamy z zamawiającym, a model dziedziny (żółte) przygotowujemy dla siebie (nie pokazujemy klientowi, ale przekazujemy zespołowi wykonawców)?
mniej więcej, chociaż coraz częściej zastępuję taksonomię w postaci diagramu klas, sformalizowanym słownikiem pojęciowym i specyfikacją reguł biznesowych, sprawdza się znacznie lepiej (to klient powinien ze zrozumieniem zatwierdzić, diagram klas tu niestety nie jest łatwy dla biznesu), z tego klient potrafi korzystać (np. uporządkowanie zarządzeń wewnętrznych otp..) http://en.wikipedia.org/wiki/Semantics_of_Business_Vocabulary_and_Business_Rules
…
Z jakich relacji należy korzystać przy budowaniu modelu pojęciowym (taksonomii)? Na przedstawionym schemacie są tylko asocjacje i uogólnienia. Czy zaznaczanie na tym etapie kompozycji czy agregacji jest zasadne?
I druga sprawa – na ile głęboko schodzić na etapie modelu pojęciowego. Przykład: zarówno Zamówienie jak i Faktura składa się z pozycji. Na podanym przykładzie zostało to pominięte. Pytanie czy celowo czy dla uproszczenia?
Model pojęciowy to nic innego jak słownikowe podejście “do tematu” podobne do podręcznikowej klasyfikacji roślin czy psów. Stosując diagram klas do tego, należy się wystrzegać “choroby relacyjnej” czyli traktowania pojęć (klas) jak encji (tabel) na diagramach baz danych (ERD) bo mają tu one zupełnie inny sens. Przedstawiony przykład pokazuje wyłącznie logikę pojęciową więc Faktura “jest jakoś” powiązana logicznie z Zamówieniem. Ale! Tu (model pojęciowy) Faktura i Zamówienie to nie “dokumenty” z ich treścią, a pojęcia np. Faktura do “dokument, który…”.
Głębokość uszczegółowienia. Więc wyjaśniło się jedno: na modelu pojęciowym Faktura to zdefiniowane pojęcie – termin, więc nie ma żadnych pozycji faktury itp. Można zdefiniować pojęcie “produkt” itp. ale wtedy diagram klas jako model pojęciowy (chcąc pokazać każdy związek logiczny) stanie się nieczytelnym “talerzem spagetti” albo będzie niekompletny (w zasadzie w biznesie wszystkie pojęcia jakoś się ze sobą wiążą). Dlatego od jakiegoś czasu diagramu klas nie używam do modelowania systemu pojęć, poprzestając na słowniku pojęć i specyfikacji dokumentów (obiektów biznesowych). Diagramów klas używam wyłącznie do modelowania dziedziny stylem opisanym jako DDD, czasami do zobrazowania metamodeli.
Mam pytanie ponieważ w książce B. Bruegge i A.H. Duttoit “Inżynieria oprogramowania w ujęciu obiektowym” autorzy wspominają o modelach dziedziny aplikacyjnej i realizacyjnej. Na stronie 40 piszą, że: “Istotą podejścia zorientowanego obiektowo jest połączenie modeli obu dziedzin(…)”. Czy zatem wspomniany w tym artykule (i innych artykułach na tym blogu) model dziedziny mamy utożsamiać z obydwoma modelami ze wspomnianego opracowania?
Hm… dobre pytanie… Generalnie mamy model logiki “systemu” czyli jego “mechanizm działania”. Myślę, że intencją autora było oddzielnie logiki “systemu” od logiki “interakcji z nim”. Jeżeli tak, to odpowiada temu wzorzec MVC-MV-VM. Model dziedziny to taki e”prawa fizyki w tym systemie”. To podstawa jego działania. Ale już “model” interakcji z aplikacją na komputerze a model interakcji na smartfonie mają swoją specyfikę.
Dzięki za info. Teraz jest to dla mnie bardziej jasne.
Pingback: Semiotyka - czyli dlaczego sama notacja to za mało - Jarosław Żeliński IT-Consulting