Zapraszam wszystkich, którzy szukają pomocy, wiedzy oraz wsparcia w swoich projektach informatyzacji. Działam od 1991 roku, mój Blog działa nieprzerwanie od 1998 roku.
Jeżeli nie potrafisz czegoś narysować to znaczy że nadal tego nie rozumiesz. Jeżeli potrafisz coś narysować to potrafisz to także zbudować.
Listopadowy numer Software Develper Journal zawiera bardzo ciekawy artykuł: Czynniki sukcesu w projektach programistycznych.
Wnioski z ankiet:
Wymagania i ich odpowiednie przetwarzanie to kluczowe zagadnienie w projektach. Popełniane w tym obszarze błędy to główne źródło problemów w projektach. Dlaczego tak się dzieje? Oto główne przyczyny wskazane przez osoby badane:
nieznajomość metod i technik zbierania wymagań;
trudno dotrzeć do informacji;
osoby dostarczające wymagania są rzadko dostępne;
nieprecyzyjne wymagania.
Wydają się oczywiste, a że z faktami nie dyskutujemy uznajemy je.
Nieznajomość metod i technik zbierania wymagań
To chyba powszechna bolączka wielu dostawców IT. Najczęściej obserwuję metodę polegająca na “zbieraniu wymagań” metodą pytania “czego Pan/Pani oczekuje od systemu” i ta forma jest gwoździem do trumny projektu. Dlaczego? Odpowiedź zawarta jest w pozostałych trzech punkach: wywiady cierpią bo trudno dotrzeć do danych i ich posiadaczy a ci ostatni najczęściej podają wymagania “z głowy” co daje w efekcie ładnie sformatowany ale nieprecyzyjny opis.
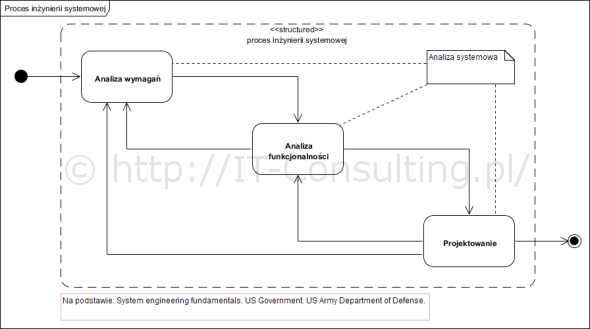
Pojawia się próba diagnozy. Pełna tak zwana śladowalność wymagań (nazwana tu hipertracebility) jest podobno kosztowna i trudna do utrzymania. Zaraz potem: niedbałość w definiowaniu wymagań – no to w końcu dokładnie czy nie? Kolej na analityków: zrzucanie odpowiedzialności ? analitycy tworzą dokument wymagań i wypychają go do programistów. Oczywiście jest to problem, co z tym? Analityk powinien ponosić odpowiedzialność za swój produkt do końca projektu. Założenie, że można stworzyć skończony dokument wymagań. Otóż można ale o tym za chwilę. Poza ważnymi elementami zarządzania takim projektem, w tym zarządzaniem zespołem autorzy wskazali jedną z głównych moim zdaniem przyczyn: brak dokumentu HLD (projektu wysokopoziomego).
Otóż nie da się czymś tak złożonym jak oprogramowanie (zakładam, że to nie trywialny system), zarządzać na poziomie detalicznych szczegółów. Jedynym sposobem jest upraszczanie i praca z abstrakcjami. Czym są owe abstrakcje? Modele! Już w 1984 roku zauważono, że:
I just read an idea by Stephen Hawking and Leonard Mlodinow, called Model-Dependent Realism[2]: “the idea that a physical theory or world picture is a model (generally of a mathematical nature) and a set of rules that connect the elements of the model to observations.” (za Model-Dependent Realism: Is This the Worldview of Software Engineering? ? THINK IN MODELS).
I nie chodzi tu o to, że inżynieria oprogramowania, to jakiś złożony model matematyczny. Chodzi w ogóle o posługiwanie się modelami – abstrakcjami – na każdym etapie projektu. To jedyny sposób by “ogarnąć projekt” w całości. Tak samo jak nie da się myśleć o samochodzie w kontekście tysięcy jego podzespołów, tak nie da się tak myśleć o czymkolwiek podobnie złożonym.
Trudno dotrzeć do informacji;
Docieranie do informacji paradoksalnie nie jest trudne, jest ich po protu mało w firmach. Bardzo często postępowanie poszczególnych wykonawców jest efektem ich doświadczenia, kompetencji oraz przyznanych uprawnień. Problemem, a może raczej wyzwaniem jest zapisanie części tych “reguł”.
Osoby dostarczające wymagania są rzadko dostępne
To dla mnie kuriozalny powód. Jest raczej dowodem słabości kierownika projektu (bo nie analityka).
Nieprecyzyjne wymagania
Zacytuje dla przypomnienia: “nieprecyzyjne wymagania”. Od tego jest analityka by były precyzyjne. Problem ten pojawia się często w sytuacji gdy owym “analitykiem” jest dostawca oprogramowania, który “czeka na wymagania” mimo, że zawarł w ofercie i umowie pozycję “analiza wymagań”.
Jarosław Żeliński: Po ukończeniu WAT w 1989 roku pracownik naukowy katedry Transmisji Danych i Utajniania. Od roku 1991 roku, po rozpoczęciu pracy w roli analityka i projektanta systemów przetwarzania informacji, nieprzerwanie realizuje kolejne projekty dla urzędów, firm i organizacji. Od 1998 roku prowadzi także samodzielne studia i prace badawcze z obszaru analizy systemowej i modelowania systemów: modele jako przedmiot badań: ORCID, publikując je nieprzerwanie także na tym blogu. Od 2005 roku, jako wykładowca akademicki wizytujący (nieetatowy), prowadzi wykłady i laboratoria (ontologie i modelowanie systemów informacyjnych, aktualnie w Wyższej Szkole Informatyki Stosowanej i Zarządzania pod auspicjami Polskiej Akademii Nauk w Warszawie.). Od 2020 roku na stałe mieszka w Szkocji (Zjednoczone Królestwo), nadal realizuje projekty dla firm i organizacji także w Polsce.