Systemy zarządzania przepływem dokumentów (docflow) lub pracy (workflow), wzorce projektowe i … problem. Uwaga! Jeżeli nie jesteś analitykiem ani projektantem systemów, zalecam skok na koniec tekstu do punktu Na zakończenie biznesowo.
Tym razem chcę zwrócić uwagę na pewien problem ze stosowaniem wzorca projektowego State Machine Pattern. Wzorzec ten moim zdaniem stanowi pułapkę dla niedoświadczonych projektantów i programistów. Otóż wzorzec ten jest dość powszechnie stosowany do implementacji usługi zarządzania przepływem dokumentów. Ale po kolei.
State machine pattern
Wzorzec ten jest dobrze opisany w literaturze więc tu tylko kluczowe informacje. Uproszczony model wzorca:
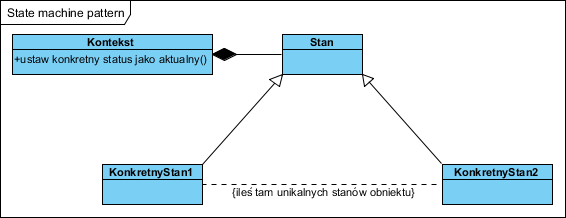
Kontekst to obiekt statusowy (charakteryzujący się pewną stanowością). Jego częścią jest zestaw (kompozycja z obiektami Status) stanów jakie może on przyjmować (KonkretneStany). Logikę zmian tych statusów umieszcza się w obiekcie Kontekst (operacja ustaw konkretny status jako aktualny), spotykaną metodą implementacji jest umieszczanie operacji reagujących na konkretne zdarzenia w obiektach stanowych. Ten drugi wariant jest w moich oczach troszkę nadużyciem: wiedza o statusach jest wnoszona do statusów, obiekt macierzysty nie panuje nad nimi, a statusy to jednak cecha (własność) obiektu Kontekst i to on “wiek jaki i dlaczego status chce przyjąć”.
Kiedy stosować
Model ten więc bazuje na założeniu, że wiedza o statusie (kiedy jaki przyjąć) tkwi w obiekcie statusowym (przyjmującym te stany). Przykładem może być np. woda i jej stany skupienia, które są cechą fizyczną wody – są więc związane z wodą. Woda może przyjąć stan skupienia stały (lód), ciekły lub gazowy (para wodna). Aktualny stan skupienia zależy wyłącznie od temperatury i ciśnienia. Żaden inny czynnik nie jest w stanie zmienić stanu kupienia wody (np. na polecenie człowieka ;)). Przykładów takich można przytoczyć wiele.
Problem zaczyna się gdy obiekt ma statusy zależne od pewnej logiki zewnętrznej, jakiś inny obiekt ma wiedzę o tym jaki status zostanie ustawiony. Ciekawym przykładem jest np. nasze mieszkanie (konkretnie zamek w drzwiach) i my. Status Zamknięte i Otwarte nie jest cechą ani zamka, ani drzwi ani nawet mieszkania tylko jest to efekt naszej woli (mieszkańca). To my decydujemy o tym czy mieszkanie jest zamknięte czy otwarte i czy być może ma inny jeszcze status (nie znany producentowi drzwi!). W efekcie logika zmiany statusu jest poza drzwiami (mieszkaniem), które dany stan przyjmują. Mieszkaniec w dowolnym momencie może ustawić swoje mieszkanie w stan nie planowany wcześniej, więc implementacja powyższego wzorca napotka na poważny problem: jak ustawić status nieznany w momencie projektowania? Przykład? W hotelach: posprzątać, nie przeszkadzać itp… Tu można zaryzykować znaną z góry listą takich znaków ale nasze drzwi w domu? Bierzemy tak zwaną żółta karteczkę i naklejamy na drzwi z zewnątrz: jestem zajęty albo co nam tam do głowy przyjdzie (domownik u sąsiada). Implementacja stanów “na żywca” staje się poważnym ograniczeniem bo wzorzec w tej postaci wymaga wiedzy o wszystkich stanach już w momencie tworzenia systemu.
Klasycznym jednak przykładem tego problemu są
Systemy obiegu dokumentów
Dokument (obiekt) biznesowy może przyjmować stany w zasadzie nieprzewidywalne na etapie analizy. Stany te mogą być (i nie raz są!) skutkiem wprowadzania lub zmian reguł biznesowych a nie cech dokumentu. Tak więc znane na początku wdrożenia statusy faktury: przyjęta, zaksięgowana, zapłacona. Mogą się zmienić po wprowadzeniu np. wewnętrznego zarządzenia o treści: dokumenty rodzące koszty przekraczające 10 tys. złotych muszą być dodatkowo zatwierdzane przed Zarząd. Jaki mamy efekt? Wiele dokumentów, nie tylko faktury ale i umowy czy reklamacje nagle muszą obsłużyć nowy status: do zatwierdzenia przez Zarząd. Mamy tu lawinową modyfikację systemu. Zmiana zasad wymaga ingerencji we wszystkie obiekty stanowe mogące “podpaść” pod nową regułę. Pytanie drugie: jak je wszystkie szybko i jednoznacznie zidentyfikować w systemie?
Już czujemy? Kto ma system obiegu dokumentów wymagający ingerencji dostawcy przy każdej zmianie zasad albo dowiaduje się, że “tego niestety nie można zrobić”?
Problem maszyny stanowej: obciążenie dokumentu odpowiedzialnością za jego status, jest w takich przypadkach złamaniem zasady właściwego przydziału odpowiedzialności w projektowaniu obiektowym. Tak więc w takich przypadkach należy zrezygnować z wzorca State machine.
Pewnym rozwiązaniem w obszarze procesów biznesowych i zarządzania przepływem pracy jest
Metamodel procesu WfMC
Workflow Management Coalition (WfMC) to organizacja standaryzująca (więcej w odnośniku). Proponuje ona taki oto metamodel (tu diagram nieco uproszczony):

(źr. WfMC: http://www.wfmc.org/standards/docs/TC-1011_term_glossary_v3.pdf)
Nasz obiekt statusowy, np. dokument, to DanePowiązane. Jednak statusy ustawia mu nie “on sam sobie” a Aktywność na bazie “wiedzy” zapisanej w obiekcie WarunekPrzekształcenia (WywołanaAplikacja to przypadek, gdy status uruchamia jakieś przetwarzanie Danych, tu nie będzie to omawiane, przydaje się np. przy projektach SOA). Aktualny status DanychPowiązanych to ich atrybut. Jak go ustawić? Poleceniem “ustaw status na …” gdzie parametrem jest “kod statusu” (lub obiekt go reprezentujący, o czym za moment). Mógł by ktoś zarzucić mi upublicznienie dostępu do atrybutów (jest zasada by tego nie robić) ale to właśnie jeden z tych przypadków gdy atrybut obiektu nie jest jego własnością. Po drugie nie upubliczniam dostępu do atrybutu. Zarządza nim operacja obiektu “ustaw status na…” i nie jest to niebezpieczne get/set. Tu nie udostępniam atrybutu a ujawniam jego istnienie a to nie to samo. Po drugie kontroluję błędy właśnie dedykowaną operacją, która może kontrolować poprawność wykonania (np. sprawdzając czy przekazywany parametr jest dopuszczalny). Kompletny opis (przepis) takiej logiki to Proces a odpowiedzialność za Aktywności ma Rola czyli jakiś aktor systemu.
Ta propozycja jest zgodna z “zadami sztuki OOAD” a rozbierając ją na czynniki pierwsze także z DDD. Zwróćmy uwagę, że model, w którym Aktywność ustawia status Danych jest zgodny z tym, że wiedzę o statusach ma Aktywność i ma swobodę ich ustawiania. Po drugie taki projekt ma w jednym tylko miejscu zgromadzona wiedzę o regułach i dopuszczanych statusach. W takiej sytuacji nawet jeżeli pojawi się nowy, nie znany nam wcześniej obiekt biznesowy, możemy go łatwo stworzyć bez potrzeby wbudowywania mu z góry jego statusów. Zmiany zestawu możliwych statusów (nowe zarządzenie) dokumentów nie wymagają przeróbek całego zestawu zaimplementowanych obiektów biznesowych. Takie podejście daje także możliwość pracy ad-hoc (ustawienie statusu dokumentu lub sprawy “z palca”).
O DDD. Status dokumentu (dokument to Encja w DDD) nie musi mieć tożsamości więc może być implementowany jako VO (Value Object) co pozwoli np. wbudować mu test (walidację). W dowolnym momencie obiekt taki można “podmienić” na obiekt statusowy zgodny z omówioną na początku Maszyna stanową, wtedy “obciążymy” bazowy obiekt biznesowy wiedzą o jego dopuszczalnych statusach.
Na zakończenie biznesowo

Systemy zarządzania przepływem dokumentów, przepływem pracy lub szumnie nazywane (i na wyrost) sytemami zarządzania procesami biznesowymi, sprawiają wiele problemów. Zaryzykuje tezę, że ich wdrażanie jest ryzykiem nie mniejszym niż wdrażanie systemów CRM (podobno tu odsetek przekroczonych budżetów i terminów przekracza 90%).
Nawet jeżeli ktoś przeprowadzi rzetelną analizę potrzeb i tak dostosuje (zaprojektuje i wytworzy) wdrażany system, że będzie spełniał pierwotne wymagania, okazuje się nie raz, że jego “życie” (cykl życia) jest bardzo kosztowne. Problem tkwi w modelu zjawiska jakim jest przepływ pracy. Nie raz wielu z Państwa (mających takie systemy) słyszało po wdrożeniu, że coś wymaga wiele pracy albo jest wręcz nie możliwe już po rozpoczęciu eksploatacji systemu. Albo, że “proces może obsłużyć tylko jeden dokument” i złączenie w jeden kontrolowany bieg wypadków czegoś takiego jak opracowanie oferty w odpowiedzi na przyjęte zapytanie jest niemożliwe albo wymaga “sztucznego połączenia dwóch procesów w jeden” (czyli dwóch dokumentów Zapytanie i Oferta w jeden ciąg). Inny przypadek to “nie da się dowolnie zmieniać statusów dokumentów, proszę określić dokładnie jakie statusy będzie miał dokument oraz kiedy i jak będą się one zmieniały”.
Specyfikacja w postaci listy wymagań funkcjonalnych i niefunkcjonalnych niestety nie chroni przed ryzykiem kosztownych zmian w przyszłości. Jedynym wyjściem jest wyspecyfikowanie w dokumencie wymagań szczegółów logiki biznesowej w postaci projektu (modelu struktury wzorca) jakiego oczekujemy od dostawcy.
Wiele dokumentów analiz zawiera statyczne tabele dopuszczalnych stanów obiektów implementowane “na żywca” czyli wprost, ich zmiana wymaga pracy programisty. W efekcie system jest bardzo kosztowny w samym posiadaniu i korzystaniu z niego, a jak wiemy środowisko biznesowe jest zmienne. Środowisko dokumentów biznesowych jest szczególnie zmienne. Tu wymaganie (dokument wymagań) nie może stanowić tablicy (skończonej listy) dopuszczalnych statusów, czego nie raz żąda wielu dostawców oprogramowania.
To są skutki stosowania (często) wzorca State Machine do budowy systemów wspomagający przepływ pracy. Wzorzec ten jest często stosowany w systemach ERP do kontroli pojedynczych dokumentów ale moim zdaniem kompletnie nie nadaje się do implementacji systemów zarządzających przepływem pracy. To nie jest przypadek, że wielu dostawców systemów ERP zaleca jednak integrację z jakimś “dobrym workflow” zamiast bardzo kosztownej kastomizacji (o tym już tu nie raz pisałem).
Co z tym zrobić? Kupujący nie ma możliwości sprawdzenia wnętrza programu (tego jak zostało zaprojektowane) jeżeli kupuje gotowe. Musi bardzo “inteligentnie” stawiać wymagania na oprogramowanie by wychwycić wady jego projektu mogące wywołać lawinę kosztów podczas “zwykłego używania”. Jeżeli zapada decyzja o projekcie dedykowanym warto pokusić się o dobrego analityka i projektanta.
A co gdy kupujemy sami i gotowe? Proponuję np. umieszczenie w specyfikacji wymagań zgodności z wzorcem (metamodelem) WfMC oraz wymaganie możliwości pracy (dekretu) ad-hoc, a potem sprawdzać czy nas nie oszukano… Ale zwracam uwagę na ryzyko, że nie ma prostej zasady “zawsze taki wzorzec” …
P.S.
Do czytających to programistów: jak znajdziecie jakieś uchybienie – proszę o litość 😉 i wskazanie błędów w postaci komentarzy 🙂


Maszyna stanów – jak każdy pattern – służy w pewnym kontekście, w innym przeszkadza a w jeszcze innym szkodzi.
Kiedy warto: 1) obiekt ma kilka odpowiedzialności, których sposób realizacji zależy od wewnętrznego stanu, oraz 2) w przyszłości spodziewam się pojawia nowych stanów ale nie spodziewam się pojawiania nowych odpowiedzialności.
Jeżeli zachodzi jedynie 1) wówczas na poziomie impl. wystarczy prosty switch. Wprowadzanie maszyny jest nadmiarowe. Chyba, że chcemy w fancy sposób zwiększyć testability. Maszyna zaczyna się “opłacać” gdy zachodzi również 2).
W Twoim przykładzie mamy kontekst na poziomie statusu w strukturze danych, dlatego podam przykład gdzie pojawia się zachowanie:
Otwórzmy sobie wdzięczy program Paint. Swego czasu tworzyłem aplikacje tej klasy, więc zdradzę jaką mają wewnętrzną mechanikę.
Klikając na kanwę, wysyłamy do niej jeden z kilku sygnałów: naciśnięto klawisz myszki, przesunięto myszkę, zwolniono klawisz myszki. Kanwa ma 3 odpowiedzialności – reakcja zdarzenia myszki. Jak powinna zareagować? A to zależy od jej stanu. Przy pomocy przybornika przełączamy kanwę w stany: spray, ołówek, gumka itd.
Wiem, że normalny człowiek nie postrzega integracji z Paintem w kategoriach zmiany stanu kanwy, ale tak jest najwygodniej implementować. Dlaczego?
Bo odpowiedzialności kanwy są stałe (kilkanaście zdarzeń z myszki i z klawiatury) i w tym wypadku wręcz niezmienne.
Natomiast sposoby obsłużenia tych odpowiedzialności (stany) – w tym wypadku przybornik narzędzi – może rozbudowywać. W zaawansowanych programach możemy instalować pluigny, które po prostu wnoszą nowe stany (wraz z logiką obsługi) do kanwy, która jest niezmienna – pochodzi z “core”.
Tak więc maszyna stanów zaczyna mieć sens, gdy mamy odpowiedzialności.
Kolejna kwesta to przełączanie się stanów. Gdzie powinna znajdować się logika mówiąca o tym w jaki kolejny stan przejść po wykonaniu logiki z danego stanu. Czyli przykładowo gdy jestem w StanieSaznaczania, wówczas zwolnienie klawisza myszki może skopiować do pamięci zaznaczony fragment, obrysować go na kanwie przerywaną linią i… zasugerować kanwie aby przełączyła się w StanPrzesuwania. Kanwa może to oczywiście zignorować. Ale warto zwrócić uwagę, że trzymanie logiki decydującej o przejściach w stanach pozwala dodawać nowe stany (pluginy) bez modyfikacji kanwy (core).
Rozumiem, ale chyba opisałeś właśnie sytuacje gdy logika zmiany stanów jest zamknięta w obiekcie (agregacie) stanowym bo tu ma to jak najbardziej sens. Dokumenty mają pewną specyfikę: nie wiedzą jak będą przetwarzane. Każda firma robi to po swojemu. Do tego reguły mogą być zmieniane. Pierwszy raz się spotkałem z problemem gdy musiałem opracować model logiki instrukcji kancelaryjnej w pewnym urzędzie. Potem okazało się, że to problem każdej sytuacji gdy to np. aktor ma wiedzę jaki status ma uzyskać obiekt. Klasyczna sytuacja dekretowania dokumentu: statusem jest między innymi tak zwany punkt zatrzymania, a ustawia go (do kogo przekazać dokument) osoba dekretująca. Tu widzę raczej związek z wzorcem strategii (saga?): strategia skojarzona z dokumentem daje jego zaplanowaną ścieżkę.
Logika jest zamknięta w agregacie w sensie takim, że z zewnątrz nie można ustawić agregatowi stanu. Wykonujemy na nim operacje, które skutkują zmianą stanu – tak to wygląda z zewnątrz.
Ale wybór kolejnego stanu tak na prawdę należy do stanu aktualnego.
Przykład:
class Canvas{
private State state;
public void mouseClick(x,y){
//wspólna logika
state = state.handleClicking(x,y)
//wspólna logika
}
}
akurat w tym wypadku Kanwa musi mieć *dodatkowo* możliwość ustawiania aktualnego stanu, ponieważ takie są wymagania.
Co do strategii, to patrząc z odpowiedniego dystansu taki stan to nic innego jak muli-strategia, która dodatkowo przełącza strategie:)
Czyli bardziej ogólnie: czynność jest obiektem.
“Status Zamknięte i Otwarte nie jest cechą ani zamka, ani drzwi ani nawet mieszkania tylko jest to efekt naszej woli (mieszkańca). ”
Jak dla mnie to jest klasyczny problem “fokusa”, tzn. na czym się skupiamy podczas projektowania, co jest istotne dla projektu.
Jeśli system obejmuje tylko drzwi z zamkiem (O, Z) to nie interesuje nas kto, co i jak je zmienia – dajemy metody Otwórz i Zamknij – nie ważne czy to zrobiono kluczem czy wytrychem (pomijam wejście na rympał :))
Jeśli interesuje nas kto otworzył i czym to “granicą systemu” będzie osoba i wtedy modelujemy, zawieramy w projekcie jej interakcję.
Podsumowując, wszystko zależy od tego jakie wyznaczymy granice systemu, a te zależą od wymagań i celu jaki chce się osiągnąć.
Dokładnie tak, dlatego celowo zwróciłem uwagę na kontekst systemów workflow bo tu granica systemu nie zawsze jest łatwa do ustalenia, po drugie prosty Przypadek Użycia dla Systemu, jeżeli modelujemy drzwi to jak najbardziej statusy są “w drzwiach” (Aktor nie ma wpływu na konstrukcje drzwi, może ich wyłącznie używać), jeżeli modelujemy układ “mieszkanie jako system -mieszkaniec jako aktor” to status jest ustalany przez mieszkańca i on ustala jakie mogą być stany jego mieszkania bo “ma nad tym władzę”. Bardzo ważne jest zrozumienie w toku analizy “istoty rzeczy” oraz, jak słusznie zauważyłeś, ustalenie granicy systemu.
“Wzorzec ten jest często stosowany w systemach ERP do kontroli pojedynczych dokumentów ale moim zdaniem kompletnie nie nadaje się do implementacji systemów zarządzających przepływem pracy. To nie jest przypadek, że wielu dostawców systemów ERP zaleca jednak integrację z jakimś ?dobrym workflow? zamiast bardzo kosztownej kastomizacji (o tym już tu nie raz pisałem).”
Stosowanie StateMachine do WF nie wydaje mi się problemem samego modelu, ale sposobu realizacji SM w aplikacji (w tym przypadku ERP) – wspomniany nakład pracy programisty.
Widzę tu pewien podstawowy problem, który będzie boleć: zbyt dokładną próbę odwzorowania dynamiki systemu w modelu statycznym. To bardzo dużo kosztuje – w pieniądzach, wydajności, utrzymaniu w ruchu itd.
Proponuję inne spojrzenie: nieważne, czy w rzeczywistości obiekt jest dokumentem, czy też aktywnością (dla mnie to inna nazwa zadania) i takie założenie wystarczy. Można wtedy stosować SM do obu przypadków.
Zamek: Otwarte/Zamknięte
Zadanie: W trakcie/Zakończono
BTW: Niezależnie od modelowania, SM zawsze musi być użyty (niejawnie) na poziomie implementacji – gdzieś musimy trzymać stan :).
Owszem, ale trzymanie stanu a logika i metoda jego ustawiania to dwa odrębne problemy :). SM to nie trzymanie stanu (do tego wystarczy np. jeden atrybut) a logika (sposób) jego zmienności. Masz rację, traktowanie takiego ERP jako statycznego systemu jest chyba główną bolączką wielu systemów ERP. Moim zdaniem jest to konsekwencja konstrukcji “baza danych i funkcje przetwarzająca te dane”. Jeżeli naście lat temu firmy były “statyczne” i można je było opisać relatywnie prostym modelem relacyjnym, tak dzisiaj jest to już wg. mnie nie możliwe. Jeżeli uznać, że wiele dokumentów jest przetwarzanych ad-hoc to znaczy, że każdy z nich jest unikalną maszyną stanową gdzie stany są ustawiane dynamicznie i co gorsza nie są z góry znane. I tu widzę problem stosowanie prostych wzorców SM.
“SM to nie trzymanie stanu (do tego wystarczy np. jeden atrybut) a logika (sposób) jego zmienności”
Tu się nie zgodzę. Podstawą SM jest właśnie trzymanie stanu. Zgadzam się czasami wystarczy jeden atrybut, ale czasami 🙂 Gorzej jak nie ma gdzie atrybutu wstawić 🙂
Moim zdaniem, każdy WF można zaimplementować za pomocą SM. Wystarczy zastosować wzorzec SM do SM 🙂 Czyli utworzyć oddzielny byt (obiekt) który jest stanem.
Podobnie opisywana tu zmiana w modelu biznesowym (nowe stany faktury). Wystarczy zastosować SM do istniejącego modelu, czy wersjonować stany/system/model/obiekty – zależnie od potrzeb.
Takim dobrym przykładem jest biblioteka prevayler (Java) w której sam kod metod jest zarządzany przez SM.
Racja pod warunkiem, że wiążemy logikę zachowania obiektu z nim samym a nie zawsze tak jest, typowym przykładem są obce dokumenty przetwarzane w sposób ad-hoc narzucony przez użytkownika, zaryzykuję tezę, że im bardziej kompetentny użytkownik tym mniej nadaje się workflow bazujący modelu SM… nie potępiam wzorca SM, zwracam uwagę, że nie jest “sposobem na wszystko”… zawsze możemy spotkać się z sytuacją:
1. zachowanie obiektu jest jego własną cechą, reaguje na swoje otoczenie – wzorzec SM
2. zachowanie obiektu jest mu narzucone z zewnątrz – obiekt jest “zwykłem” obiektem o stanie zależnym od wykonanych na nim operacji
Przypadek 1. to standardowe proste i przewidywalne wnioski urlopowe, faktury kosztowe itp. Przypadek 2. to pozostałe sytuacje gdy proces jest sterowany przez wykonawcę. Przykładem tego typu systemów są rozwiązania zbudowane dwóch podsystemów: repozytorium i motor procesowy. Repozytorium przechowuje dokumenty i ich metadane ale to jakie będą one przyjmowany statusy “wie” motor procesu a nie dokument. Co ciekawe samo repozytorium pozwala obsłużyć wiele przypadków zarządzania przepływem dokumentów, szczególnie tych ad-hoc.
Aha… można (tak sądzę) realizować model, w których obiekt biznesowy będzie miał wstrzykiwaną “odpowiednią” maszynę stanową SM…
“2. zachowanie obiektu jest mu narzucone z zewnątrz ? obiekt jest ?zwykłem? obiektem o stanie zależnym od wykonanych na nim operacji”
Na to też jest proste rozwiązanie rozwiązane znane z projektów integracyjnych: koperta. Opakowujemy obiekt obcy, własnym obiektem i trzymamy własne stany, które oczywiście mogą lub muszą wynikać ze stanów obcych, ale są zmieniane przez nasze metody.
Uważam, że my powinniśmy zawsze wiedzieć jakie stany chcemy przechowywać – jeżeli nie wiemy to jak możemy na nie reagować :). Jeśli jedna nie znamy stanów, to możemy budować obiekty ze stanami abstrakcyjnymi (string, obiekt typu object itp.), ale wtedy model jest nieczytelny.
Jak dla mnie: SM everywhere 🙂
“Uważam, że my powinniśmy zawsze wiedzieć jakie stany chcemy przechowywać ? jeżeli nie wiemy to jak możemy na nie reagować”
Wyobraźmy sobie, że Zarząd firmy na zmianę z ustawodawcą serwują nam co jakiś nowe lub zmienione “reguły” biznesowe (nowe progi zatwierdzania kosztów, nowe stany w procesie windykacji, zmiana instrukcji kancelaryjnej i nowe kody JRWA w Urzędzie itp.). Nazwy (kody) tych stanów (statusów) więc pojawiają się ad-hoc, nie będziemy ich znali na etapie projektowania systemu ale musimy je później obsługiwać np. w celu przekazywania właściwym (nowym) osobom czy po prostu do wyszukiwania spraw na “danym etapie”. To klasyczna sytuacja gdy obiekt stanowy nie jest “panem” swoich statusów (to przykłady z projektów).
“To klasyczna sytuacja gdy obiekt stanowy nie jest ?panem? swoich statusów (to przykłady z projektów)”
On nadal jest “panem” swoich statusów, tylko następuje zmiana statusów i zachowania (bo nowe statusy) – de facto następuje zmiana obiektu “pan” :). Nie ma co się oszukiwać, każda zmiana typu (klasy) przetwarzanych danych pociąga za sobą zmianę działa i konieczne jest programowanie. Cała sztuczka polega na tym, aby przewidzieć możliwość rozbudowy modelu danych bez jego komplikowania (należy cały czas pamiętać, że programowania się nie uniknie). Dlatego moim zdanie jest to jeden z tych momentów, w których projektowanie/programowanie obiektowe przynosi korzyści, a dokładnie powiązanie danych z działaniami. Przy pełnym obiektowym podejściu oraz paru algorytmom/wzorcom (np. lazy updates) bardzo łatwo jest rozbudowywać nawet duże i rozbudowanie aplikacje, uzyskując stabilne jakościowo działanie. Co przeszkadza i utrudnia ? Mapowanie na bazy SQL 🙂
ostatnie zdanie … ano 😉
Witam,
Świetny wpis i jeszcze lepsza dyskusja w komentarzach. Tak się złożyło, że od 4 lat buduję systemy w których obieg dokumentów, pracy lub ogólnie pewnych bytów jest głównym problemem. W pewnym rozwiązaniu zastosowaliśmy klasyczną SM, ale obieg był bardzo szczegółowo zdefiniowany. Kiedy jednak w innym projekcie okazało się, że obiegi są na tyle skomplikowane i nieprzewidywalne, że nie dało się ich modelować z wykorzystaniem SM. Po prostu użytkownik nie był w stanie określić co się może wydarzyć w następnym etapie i jak będzie wyglądało przetwarzanie obiektu. Zwykle stan trzymany był w obiekcie w postaci atrybutu, a jego zmiany wywoływały różne inne obiekty, np. klasa Dekretacja. Powoduje to jednak straszny bałagan i problemy z zarządzaniem funkcjonalnościami.
Teraz już trochę za późno, ale wydaje mi się, że podejście przedstawione we wpisie, w przypadku powyższym dałoby niezłe wyniki.
Byłem na Pana wystąpieniu podczas konferencji Gigacon w Krakowie. Na tej konferencji właśnie poruszył Pan ten temat. Naprawdę byłem pod wrażeniem w jaki sposób Pan przedstawił różnice pomiedzy maszyną stanową a systemem workflow w kontekście dokumentów (obiektów).
Mam za sobą parę wdrożeń opartych na silnikach workflow (zgodnych z wfmc.org) i życzyłbym sobie po stronie Klienta takiej właśnie wiedzy.
A obieg dokumentów opartych na ich stanach – to początek klapy projektu zanim się zaczął.
Pozdrawiam.
Witam. Pozostaje mi podziękować za dobre słowo i życzyć wszystkiego dobrego. Mamy podobne doświadczenia, nie wiem czemu ludzie się tak upierają pzrey tej maszynie stanowej w projektach workflow… mogę się tylko domyślać, że większość korzysta z gotowców a te maja dobre 15 lat….wtedy maszyna stanowa się przydawała do prostych FK/magazyn…