Rok temu pisałem o wzorcu CQRS, tamten wpis bazował głównie na artykule M.Fowlera i stanowił raczej zajawkę tematu. Teraz mam troszkę własnych doświadczeń, także w dyskusjach z programistami, i przytoczę tu moja konkluzję, nieco chyba odbiegającą od opisu M.Fowlera, którego albo nie zrozumiałem ale on uprościł swój wpis (dzięki czemu ja wtedy nie zrozumiałem).
Mamy problem polegający na tym, że firma ma ogromną ofertę pewnych bardzo złożonych podzespołów, żeby nie psuć ich opisu i możliwości rozbudowy, model dziedziny odwzorowuje strukturę tych części. Jednak bardzo duża liczba użytkowników sklepu internetowego regularnie przywołuje na ekran listę podzespołów w postaci cennika, pełnego, stronicowanego, sortowanego alfabetycznie lub ceną.
Rozwiązanie: repozytorium przetrzymuje dwa komplety tych danych: jeden jako pełny katalog danych o produktach drugi jako płaski cennik. bardzo często spotykam się z opinia (implementacją), w której (np. za pomocą ORM) mapuje się model (projekt) logiczny na bazę danych w sposób jak poniżej:

Prawdopodobnie dlatego, że na stronie http://martinfowler.com/bliki/CQRS.html mamy taki oto diagram opisujący wzorzec CQRS:
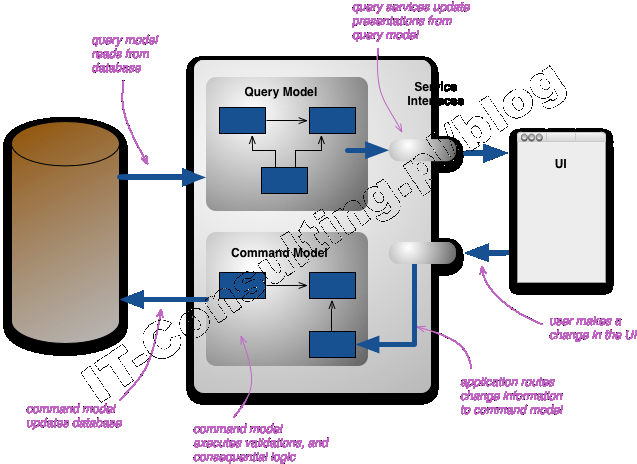
i to jest ten moment, w którym ja chyba czegoś nie zrozumiałem u Fowlera (i nie tylko u niego). W moim mniemaniu (i w mojej wersji w projektach) wygląda to jednak tak:
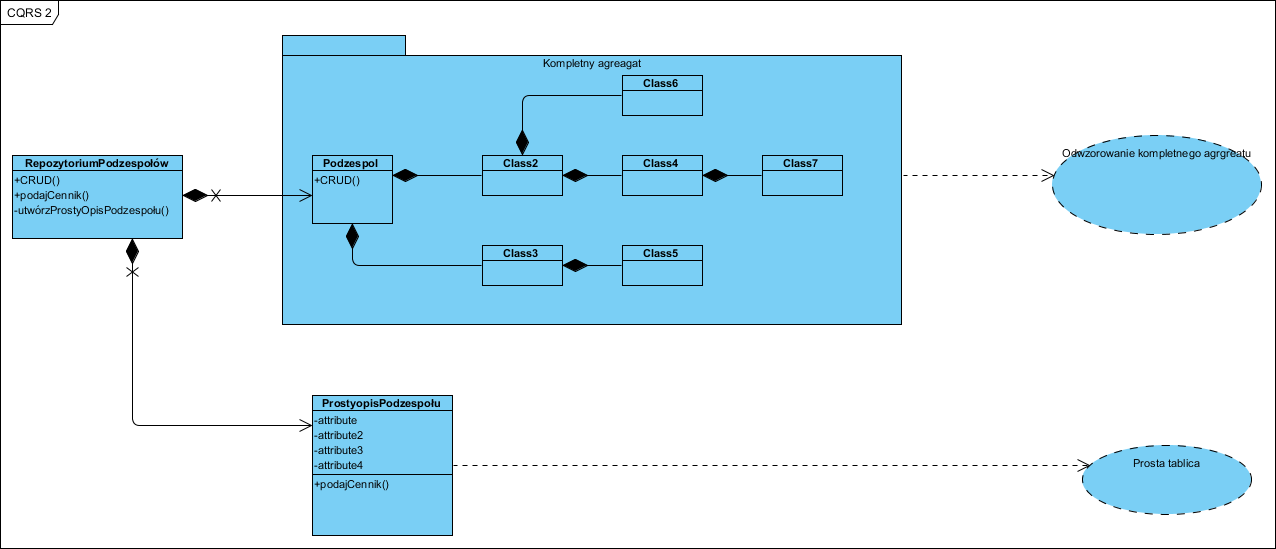
Czyli “z zewnątrz” mamy RepozytoriumPodzespołów (jeden interfejs) a logika jest taka: na bazie kolekcji agregatów powstaje równolegle (jest aktualizowana okresowo) niezależna płaska lista. Korzystający z tego komponentu – wykonując operacje podajCennik() – nie wie, czy cennik jest generowany wprost z agregatów czy z płaskiej tablicy, bo to jest ukryte za interfejsem. Jednak, jak nie trudno się domyśleć, odpowiedź z kolekcji ProstyopisPodzespołów będzie “o niebo” szybsza niż ad-hoc zapytanie do kolekcji bardzo złożonych agregatów. Agregaty praktycznie wyłącznie obsługują operacje CRUD. Warunkiem uzyskania dużej wydajnosci operacji podajCennik() jest, projektując utrwalanie, zbudowanie dwóch odrębnych zestawów tablic dla agregatów i dla płaskiej kolekcji.




W CqRS chodzi o to aby odseparować od siebie 2 klasy operacji: rozkazy kierowane do domeny i kwerendy służące do “podglądania” stanu domeny.
Robimy to w celu:
– zorientowania API stosu command na bardziej induktywne niż crudowe
– zwracania ze stosu query modelu, który będzie bardziej odpowiedni do prezentacji niż domena (w aplikacjach, które nie są prostym crudem model domenowy może nie nadawać się do prezentacji, szczególnie na przekrojowych raportach/tabelkach)
– hermetyzacji domeny (nie chcemy aby aplikacje klienckie “wiedziały” o naszych tajemnicach domenowych
– przy okazji możemy “ugrać” nieco technicznych “bonusów” typu wydajność, skalowanie, osobne cykle deploymentu, podejście aspektowe po stronie stosu command
Natomiast to jak to jest zaimplementowane, to już sprawa drugorzędna. Możemy podejść do problemu na kilka sposobów.
– stos query “spłaszcza” model domenowy przy pomocy SQL: w stosie command używamy ORM, który świetnie nadaje się do operowaniu na Agregatach DDD, ale nie nadaje się kompletnie do przekrojowych kwerend
– widoki zmaterializowane – stos query jest widokiem na domenę; generalnie projekuyejmy modele danych relacyjnych dążąc do III postaci normalnej (która jest doskonała do zapisu, ale słaba do odczytu), podczas gdy większość systemów biznesowych częściej czyta niż pisze do bazy (3-5 rzędów wielkości częściej)
– osobny model do odczytu, który jest odświeżany np. przy pomocy zdarzeń generowanych przez obiekty domenowe w ważnym momentach ich życia; tych osobnych modeli do odczytu może być wiele (w zależności od potrzeb) i mogą być zaimplementowane na bazach innych niż relacyjne, ta, gdzie ma to sens, np bazy grafowe w przypadku gdy chcemy modelować np. grafy powiązań w sieci klientów.
Generalnie: ważne aby zacząć od separacji API projektując 2 stosy warstw. Z czasem wraz ze wzrostem obciążenia możemy zmieniać impl przechodząc przez kolejne poziomy separacji technicznej.
No tak. Ale to co opisałem to faktycznie konkretne rozwiązanie, ale z perspektywy “mojej” (to jest cel użycia w projekcie) cele są dwa (powiązane ze sobą):
– zwiększyć wydajność operacji “pokaż cennik”,
– uniknąć (zabronić) optymalizacji metodą upraszczania agregatów (czyli psucia projektu), które faktycznie (wiernie) modelują elementy dziedzinowe.
Innymi słowy agregaty wiernie odwzorowują realia, płaska tablica (możliwe, że więcej) pełni rolę metody szybkiego dostępu do konkretnego stosowanego widoku danych uproszczonych.
Traktuje to (dodatkowa płaska kolekcja) jak podręczny, prosty zeszycik magazyniera, który służy wyłącznie do szybkiego znalezienia produktu a nie do czerpania informacji o nim.
Ok, już rozumiem, bo nawet mi przez myśl nie przeszło, że ktoś może chcieć psuć model agregatów:)
A zdziwił byś się 🙂 jak często jest to robione….
Model z separowaniem danych został opisany także tu: CQRS Introduction.