Poza wymaganiami funkcjonalnymi, podajemy tak zwane wymagania poza-funkcjonalne. Mają one, między innymi, ważna rolę do spełnienia. Jaką?
Najpierw cytat:
Technologia klient/serwer jest zależna od komunikacji pomiędzy poszczególnymi komputerami. Sieci LAN i WAN stają się znacznym wydatkiem oraz wymagają dużych nakładów pracy w związku z zarządzaniem nimi. Co więcej, zmiana wersji oprogramowania na wielu komputerach, co szczególnie widoczne jest w przypadku przetwarzania rozproszonego, staje się istotnym problemem. Wielokrotnie działy IT zastanawiają się nad przejściem na strukturę Internet/Intranet w celu rozwiązania tego problemu. (Wstęp do ERP – technologia u podwalin przedsiębiorstwa).
Pomijając “prostotę” tego tłumaczenia, chcę zwrócić uwagę na ważną rzecz: bardzo duże znacznie ma architektura systemu, niestety wielu producentów ukrywa zastosowaną technologię i architekturę. Jedną z przyczyn jest to, że są to nie raz technologie rodem z lat 90-tych a bywa, że nawet wcześniejsze. Jedną z takich “staroci” jest architektura client-server (tak zwany gruby klient). Innym typem “dinozaura” technologicznego jest tworzenie oprogramowania, w którym logika biznesowa jest w jakiejś części w procedurach wbudowanych bazy danych (w rozumieniu konkretnego tak zwanego motora SQL bazy).
Jaki mamy wybór?
Zanim powiemy sobie o wyborze, kilka słów na temat klasycznej trójwarstwowej architektury jako fundamencie dalszych rozważań. Struktura taka wygląda następująco:
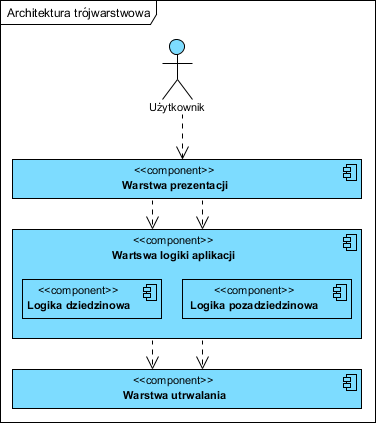
Mamy tu trzy warstwy: Warstwa prezentacji, czyli komponent odpowiedzialny za wyświetlanie informacji na ekranie użytkownikowi i ich przyjmowanie. Warstwa logiki aplikacji podzielona na Logikę dziedzinową (część specyficzna dla dziedziny problemu, tu są np. faktury, sposób naliczania podatków, rabatów itp. ta część realizuje wymagania funkcjonalne) oraz Logikę poza-dziedzinową (wydajność, niezawodność, bezpieczeństwo, integracja z innymi aplikacjami itp.). Najniżej jest warstwa Utrwalania, coraz częściej w paradygmacie obiektowym pomijana na tym poziomie abstrakcji (utożsamiana z realizacją wymagań poza-funkcjonalnych związanych z zachowywaniem informacji).
Praca w sieci wielu użytkowników to wielodostęp (wiele stacji roboczych korzysta z jednego serwera):

Gruby klient
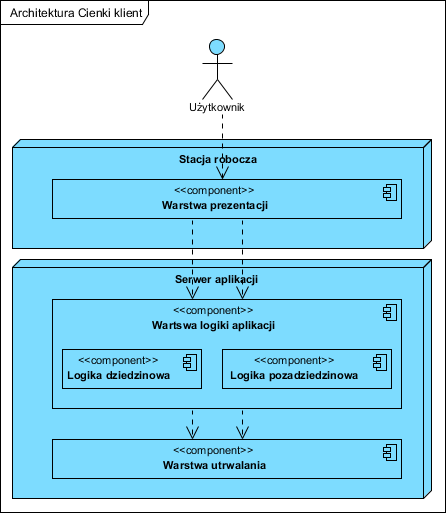
Gruby klient to architektura w której każdy użytkownik ma na swoim lokalnym komputerze nie tylko warstwę prezentacji ale także całą logikę aplikacji. Każde takie stanowisko komunikuje się z serwerem danych:

Do powyższej architektury odnoszą się główne uwagi o wadach z cytatu na początku. Cechy architektury po lewej stronie: kosztowne stacje robocze (muszą, każda, udźwignąć całe oprogramowanie), kosztowna administracja (niezgodność wersji na stacjach roboczych może prowadzić do krachu systemu), kosztowne modyfikacje (także z uwagi na wymaganą zgodność oprogramowania na stacjach roboczych), bardzo duże wymagania na pasmo i niezawodność sieci (duże transfery danych pomiędzy stacjami roboczymi i serwerem, zerwanie połączenia powoduje blokady dostępu do danych) powodują, że praca w sieci rozległej terytorialnie może być wręcz niemożliwa (wtedy wymaga powielania instalacji w każdej lokalizacji i synchronizacji danych, kolejne niemałe koszty). Pewną odmianą jest wariant po prawej stronie, gdzie część logiki aplikacji jest umieszczona na serwerze danych (konkretnie bazy danych), powoduje to nieco zmniejszony ruch w sieci ale dodatkowo komplikuje wszelkie rozszerzenia funkcjonalności i upgrade oraz praktycznie uniemożliwia zmianę (wybór) producenta bazy danych. Duże koszty tej architektury dodatkowo potęguje wymóg wykupienia licencji na bazę danych dla każdego użytkownika.
W większości przypadków tej architektury, logika biznesowa (dziedzinowa) nie jest separowana od reszty, w efekcie dodatkowo wszelkie prace dostosowawcze są bardzo kosztowne (ingerencja w całą aplikację).
Architektura internetowa – cienki klient
Taką nazwę od pewnego czasu nadaje się architekturze opartej na dostępie do aplikacji z pomocą przeglądarki WWW:
Powyższa architektura praktycznie nie ma żadnej wady poprzedniego rozwiązania. Dodatkowo baza danych licencjonowana jest z reguły na aplikację a nie na każdego użytkownika (czyli jest taniej). Stosując tak zwane metody i architektoniczne wzorce obiektowe (najpopularniejszy to MVC: Model, View, Controller) separuje się komponent logiki biznesowej od logiki sterowania aplikacją. W efekcie dostosowanie aplikacji nie polega na kosztownym modyfikowaniu logiki aplikacji, dodaje się i integruje niezależny komponent Logiki biznesowej, co dodatkowo pozwala zachować separację praw autorskich do kodu logiki biznesowej (know-how firmy). Korzyścią takiej architektury jest także możliwość łatwego dodawania możliwości dostępu z innych niż komputer PC, urządzeń (smartfony, tablety, itp.) gdyż wymaga to wyłącznie nowej warstwy prezentacji, logia pozostaje spójna na serwerze.
Kolejna korzyść to łatwa integracja z innymi aplikacjami. Oprogramowanie w tej architekturze “ukrywa” dane, dostęp do nich jest wyłącznie przez Logikę aplikacji za pośrednictwem tak zwanych API (interfejs programistyczny) metodami znanymi w sieci WWW, unikamy kosztownych i ryzykownych łączy bezpośrednich do baz danych (niska pracochłonność integracji, bardzo wysokie koszty utrzymania i rozwoju).
W efekcie rekomendowana architektura mogła by wyglądać tak:
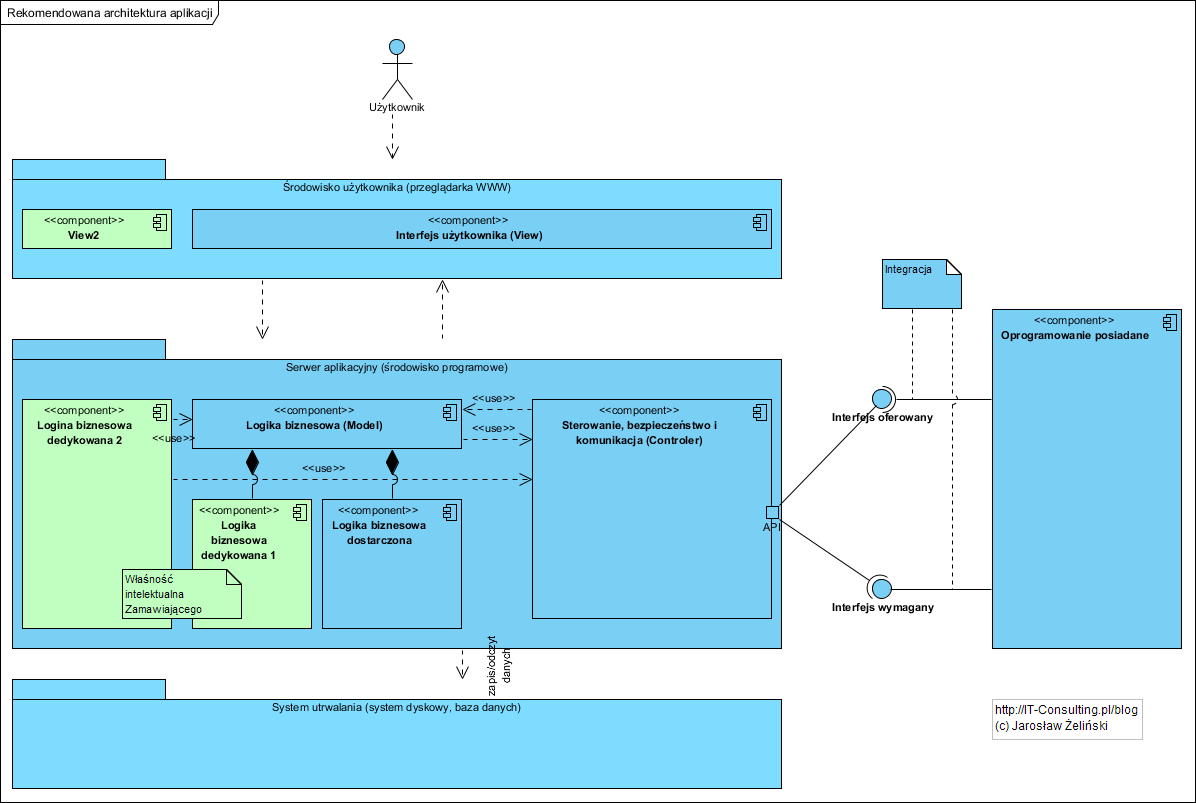
Zalety: niskie koszty utrzymania systemu i infrastruktury, separacja logiki biznesowej (dziedzinowej) dedykowanej od “kupionej”, łatwość i niski koszt upgrade, praca z pomocą przeglądarki WWW, łatwa integracja z innymi aplikacjami, łatwość pracy w sieci lokalnej i rozległej (w tym łatwy zdalny dostęp z dowolnego cudzego komputera). To tylko główne korzyści.
Wymagania pozafunkcjonalne
Jak wspomniałem, wielu dostawców oprogramowania jak Rejtan, broni się przed ujawnianiem architektury, swoich produktów. Głównym powodem jest zapobieganie przedwczesnego wyjawienia opisanych wyżej wad systemów z grubym klientem (znacznie rzadziej spektakularny pomysł, w końcu mamy jednak jakieś standardy). Przypadki, w których zakup systemu był relatywnie niski ale koszt utrzymania, rozwoju i dostosowania nie raz wręcz ogromny, to z reguły właśnie zakup systemu w tej kosztownej architekturze.
Jak starać się tego unikać? Na etapie definiowania wymagań poza-funkcjonalnych, żądać takich cech jak opisane powyżej czyli własnie: dostęp do całości przez przeglądarkę WWW, niskie wymagania na łącza przy zdalnej pracy i pracy w sieci rozproszonej terytorialnie, oddzielenie komponentu z własną dedykowaną logiką biznesową.
[2015]
Polecam pogadankę Martina Fowlera na temat roli architektury oraz Davida Farley’a o tym czym są pozafunkcjonalne wymagania i czy na pewno są “pozafunkcjonalne”:

Z mojej praktyki wynika, że MVC nie nadaje się do realizacji sugerowanej “architektury cienkiego klienta”. Głównym powodem jest trudność w odseparowaniu logiki aplikacji od “proceduralnej implementacji wywołań”, czyli kodu niezbędnego, aby wszystko zadziałało, ale nieistotnego z punktu widzenia logiki aplikacji. Znacznie lepsze jest bezpośrednie implementowanie w kodzie DDD (Domain Driven Design) lub BDD (Behavior Driven Development).
DDD to wzorce “Modelu”…. Sugerowana architektura to “View” po stronie klienta i reszta po stronie serwera. Co to jest “proceduralna implementacja wywołań”?
Przykład aplikacji typu “gruby klient”: SAP Business One, BPSC, …
dlaczego “dinozaurem technologicznym” nazywasz aplikacje z częścią logiki przechowywaną w procedurach wbudowanych baz danych. Mógłbyś to jakoś rozwinąć?
W dużym uproszczeniu: to bardzo kosztowny (koszt wprowadzania zmian) i archaiczny sposób na przechowywanie logiki biznesowej, w 100% uzależnia od konkretnej implementacji motora SQL. Rozbudowane aplikacje stają tak trudne i kosztowne do utrzymania. Tak zaimplementowana logika jest niepodzielna, trudno o podzielenie jej na odseparowane, rozłączne moduły. Język procedur wbudowanych jest trudny do zarządzania przy rosnącej ilości “linii kodu”. Wszystkie systemy ERP, z którymi miałem kontakt, zbudowane w oparciu o tę metodę implementacji, były bardzo kosztowne w rozwoju i modyfikacji, oprogramowanie komponentowe, zbudowane metodami obiektowymi (ale to nie to samo co napisane w języku obiektowym!) z reguły daje niższe koszty rozwoju. To także konsekwencja stosowania baz w modelu relacyjnym, trudno taką bazę modyfikować w “żyjącym” systemie (np. system IFS). Co ciekawe, takie implementacje są zawsze droższe (a mam stały kontakt z ofertami w odpowiedzi na te same zapytania). Nie jest to tylko moja opinia, śledząc literaturę z obszaru projektowania i implementacji, obserwuję odwrót od metod strukturalnych i monolitycznych baz relacyjnych. Dzielnie logiki biznesowej na część w bazie i część w kodzie prowadzi do dużych trudności z utrzymaniem jej spójności w większych projektach (a raczej nie da się 100% logiki systemu wtłoczyć w ubogi język procedur wbudowanych).
Wymienione wady i zalety obydwu architektur jak najbardziej są uzasadnione. Jednak w nie traktowałbym architektury opartej na grubym kliencie jako “dinozaura”. Są sytuacje kiedy zastosowanie tego podejścia jest wskazane i ma znaczną przewagę nad systemami opartymi o przeglądarkę.
Parę lat temu brałem udział w projekcie dla dużego klienta. Kilkanaście tysięcy jego pracowników pracowało w terenie i niestety regularnie zdążały się przypadki, kiedy nie mieli dostępu do Internetu. Dlatego stworzyliśmy aplikację grubego klienta, która była wypełni samodzielnym rozwiązaniem. Dopiero w momencie podpięcia się użytkownika do sieci system, synchronizował się z centralną bazą. Oczywiście przy takiej skali, nawet przy zastosowaniu automatycznych aktualizacji, pojawiły się wymienione problemy (ale w rozsądnej ilości). W tym przypadku, problem z licencjami lokalnych baz danych udało się rozwiązać darmowymi wersjami baz Microsoftu (Express, Compact).
Inna sytuacja kiedy bym brał pod uwagę architekturę z zastosowaniem “grubego klienta” – aplikacje wymagające pracy na ciężkich obiektach. Przykład który chodzi mi po głowie to np. obróbka grafiki – czasy oczekiwania, aż do klienta po przeliczeniach spłyną obrazy, zostaną przesłane na serwer mógłby zbić efektywność pracy prawie do zera.
Osobiście jestem zwolennikiem architektury opartej o cienkiego klienta. Niestety specyfika danego systemu i biznesu niejako wymusza jedno lub drugie podejście.
To prawda, że są sytuacje wymykające się “ogólnym zaleceniom” czy dobrym praktykom. Generalnie są to te przypadki gdzie indywidualizm pracy użytkownika jest główną cechą danego systemu, a umożliwienie tego indywidualizmu wymaganiem. Klasyką są aplikacje inżynierskie i graficzne np. mój CASE to ciężki klient, serwer jedynie wersjonuje projekt i analizuje (na żądanie) różnice między wersjami, obsługuje uwagi recenzentów. Wiele quasi samodzielnych aplikacji na smartfony to lokalne aplikacje klienckie. Przykładów można podać wiele, jednak ja w swoim artykule skupiłem się na aplikacjach czysto biznesowych, gdzie logika biznesowa jest jedna i wspólna, rola użytkownika sprowadza się do wprowadzania danych i korzystania z danych przetworzonych. Tak więc Pana wnioski jak najbardziej są zbieżne z moimi ;).
Wskazywanie systemów obiektowych jako rozwiązania każdego problemu zdecydowanie nie jest poprawne. Już dziś wiemy, że podejście, które miało drastycznie obniżyć koszty produkcji systemów informatycznych odniosło przeciwny skutek. Podobnie jest z architekturą cienkiego klienta. Po prostu czasem będzie nie wydajna lub zbyt kosztowna (niektóre przypadki opisali przedmówcy). Oczywiście w przypadku wielu systemów sprawdzi się doskonale. Aplikacje z częścią logiki przechowywaną w procedurach wbudowanych baz danych także często okazują się wydajniejsze od wielowarstwowych. A już na pewno są dużo tańsze w utrzymaniu i wytworzeniu. Szczególnie w systemach transakcyjnych (zajmuję się produkcją sporego systemu klasy ERP i z rozwiązań wielowarstwowcyh byliśmy zmuszeni częściowo zrezygnować z uwagi na koszty oraz wydajność systemu).
Prawdą jest, że “obiektowość” to nie “lekarstwo na wszelkie zło” ale… Po pierwsze podejście obiektowe nie miało na celu obniżenia kosztów projektowania i wytwarzania (bo faktycznie je podnosi) a kosztów utrzymania i rozwoju (polecam [[Open Close pryncypia]]). Nie mylmy kosztów projektowania z kosztami utrzymania. Projekt i wykonanie roweru spawanego zawsze będzie tańsze niż zaprojektowanie roweru z masą śrubek, motylków i standardowych gwintów w celu łatwej przyszłej zmiany budowy i rozbudowy roweru. Jednak z jakiegoś powodu nie produkuje się spawanych rowerów…
Nie tylko moim zdaniem powszechnym błędem “technokracji” jest uznanie, że np. wydajność jest kluczem: bardzo wydajny, ale też bardzo kosztowny w utrzymaniu, system nie będzie sukcesem biznesowym. Zresztą jest masa rozwiązań architektonicznych rozwiązujących problemy wydajnościowe (np. CQRS).
Wytworzenie aplikacji z logiką w procedurach wbudowanych jest zapewne tańsze ale z niskimi kosztami jej utrzymania bym polemizował, z reguły dodanie lub zmiana logiki działania wymaga nie raz przeglądu (a bywa, że nawet refaktoringu) całości a silne powiązania wewnętrzne (w zasadzie żadnej hermetyzacji bo całość wiąże jeden relacyjny, znormalizowany model danych) uniemożliwiają wydzielenie i wymianę jakiejkolwiek części.
Obecnie w zasadzie regułą na rynku jest zmienność tego rynku, firmy z jednych swoich funkcji biznesowych rezygnują inne adoptują, systemy zbudowane na zasadzie “model danych + funkcje” to monolit nie dający się kroić na kawałki. Z moich doświadczeń wynika, że “spory system ERP” bardzo szybko staje się zakałą firmy, bo to strategia “wszystko albo nic”. Regularnie jestem świadkiem sytuacji, gdy firma rezygnuje z całego ERP bo nie da się zmienić tylko jego części. Niestety to rynek dyktuje wymagania a nie technologia. Owszem 30 lat temu można było założyć, że model działania firmy się nie zmieni np. 15 lat więc ma sens budowanie jednolitego modelu danych dla niej, dzisiaj nie ma to raczej już sensu.
Obiektywność to nie tylko “klasy i obiekty” ale podział dużego systemu na niezależne logiczne i zintegrowane komponenty. Nawet jeżeli jeden autobus jest tańszy od 10 samochodów osobowych, żadna rozsądna firma dzisiaj nie kupi dla działu handlowego autobusu… Ja patrze na to tak: klient raz płaci za aplikację a potem ją utrzymuje np. 10 lat. To architektura decyduje o kosztach utrzymania… Co do wydajności systemów z procedurami wbudowanymi, to bądźmy szczerzy: wydajność zabija normalizacja danych a nie to ile warstw logiki ma, bo tych warstw jest najwyżej trzy i poprawna ich architektura raczej spowoduje wzrost szybkości pracy niż jej spadek.
Na koniec warto nie zapominać, że użycie procedur wbudowanych niemalże uniemożliwia wymienność serwera SQL.
Dodam kilka słów wyjaśnienia w kwestii tak zwanego “grubego klienta” bo w powyższych komentarzach przemilczano jedną ważną rzecz dotycząca architektury. Gruby klient to architektura, w której na stacji użytkownika jest tylko aplikacja a baza danych systemu na serwerze, taki klient “zdalnie” korzysta z tej bazy danych (wywołania SQL po sieci).
A to co opisał jeden z przedmówców:
“Parę lat temu brałem udział w projekcie dla dużego klienta. Kilkanaście tysięcy jego pracowników pracowało w terenie i niestety regularnie zdążały się przypadki, kiedy nie mieli dostępu do Internetu. Dlatego stworzyliśmy aplikację grubego klienta, która była wypełni samodzielnym rozwiązaniem. Dopiero w momencie podpięcia się użytkownika do sieci system, synchronizował się z centralną bazą.”
to nie jest “klient serwer” a autonomiczna aplikacja zintegrowana z drugą w centrali, i to dla odmiany jest dość często spotykane rozwiązanie.