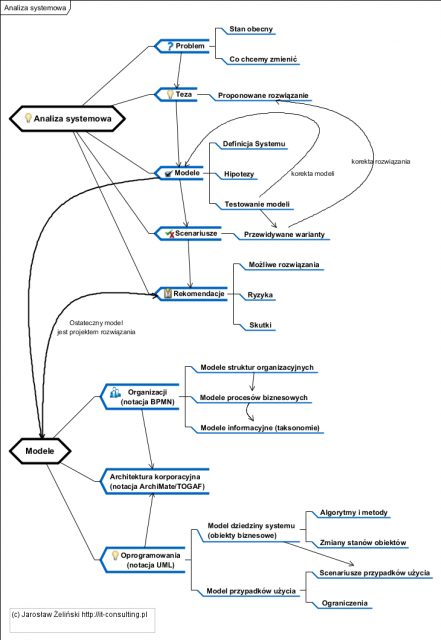
Wprowadzenie
Ostatnio napisałem dwa artykuły: o architekturze i o integracji. Pewnym ich podsumowaniem będzie dzisiejsza recenzja książki Jeff Garland i Richard Anthony .
Kilka sugestii zawartych w książce. Jedną z kluczowych jest zbyt szybkie “ładowanie się” w szczegóły, w toku analizy od ogółu do szczegółu jako pierwszy powstaje model kontekstowy, powstaje z użyciem diagramu przypadków użycia. Bardzo często na tym etapie tworzone są w projektach bardzo szczegółowe diagramy z dziesiątkami przypadków użycia, praca z taka ilością szczegółów niszczy skuteczność pracy na tym poziomie. Przypadki użycia na etapie analizy kontekstu mają za cel wychwycenie elementów otoczenia systemu a nie jego projektowanie i specyfikowanie.
Kluczowym niebezpieczeństwem w projektach integracyjnych jest praca ze złym modelem (a jeszcze gorsza jest praca bez modeli, na czuja).
O czym jest ta książka
Jednym z kluczowych elementów projektów dotyczących dużych, złożonych systemów jest praca na abstrakcji tego systemu: modelu kontekstowym i elementach pojęciowych.
Praca z dużymi systemami to projekty integracyjne, sprawdzony model analizy i projektowania wygląda tak:
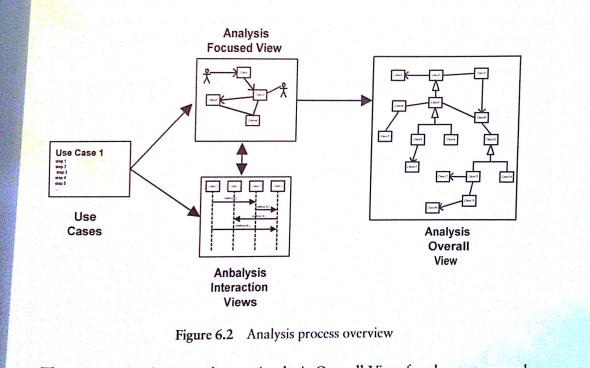
Warto zwrócić uwagę jak bardzo ten model procesu analizy i projektowania jest podobny do modeli na poziomie aplikacji (patrz artykuł o ICONIX)
Definicje:
- system: to zestaw komponentów, które realizują określoną funkcję lub zestaw funkcji.
- architektura: podstawowa organizacja systemu oparta o jego komponenty, ich wzajemnych związki i ich środowisko oraz zasady kierujące jego projektowaniem i rozwojem.
- wzorce architektoniczne: definiują ogólny zestaw typów elementów i ich interakcji; przykłady wzorców architektonicznych to model-widok-kontroler, Saga, mikroserwisy, itp.
- styl architektoniczny: termin ukuty przez Garlana i Shawa, jest to idiomatyczny wzorzec organizacji systemu; np. system klient-serwer jest stylem architektonicznym; wiele oryginalnych stylów architektonicznych zostało przeformułowanych jako wzorce.
- COTS (Commercial Off-the-Shelf): obejmują komponenty oprogramowania, które są kupowane od dostawców oprogramowania lub uzyskiwane z otwartego oprogramowania.
Jednym wielu, ale kluczowych powodów projektowania architektury jest zarządzanie ryzykiem oraz testy integracyjne na etapie poprzedzającym development, co znacznie obniża koszty i skraca czas realizacji projektów.
Ważna uwaga autorów w kwestii wymagań:
Niewłaściwe zastosowanie przypadków użycia może spowodować niepotrzebny wysiłek. Ten zmarnowany wysiłek jest czasami nazywany “paraliżem analitycznym” i doprowadził do tego, że przypadki użycia są określane jako “przypadki bezużyteczne” lub “przypadki nadużycia”. Zastosowanie przypadków użycia powinno być ograniczone do wyodrębnienia kluczowych interfejsów i interakcji, a stosowanie przypadków użycia do kompletnej specyfikacji systemu powinno być unikane.
To kolejny głos w dyskusji do czego służy diagram przypadków użycia: nie do projektowania detali aplikacji. Autorzy zwracają uwagę na to, że notacja UML jako jedyna, jest standardem i używanie innych psuje projekty. Jest to język komunikacji, bez względu na to jest to komunikacja wewnątrz zespołu czy między zespołem a kontrahentami, musi to być skuteczna komunikacja.
Największym zagrożeniem dla biznesowy ze strony modelowania architektury jest praca ze złymi modelami.
Modelowanie
Duże projekty to duża złożoność i ogromne ryzyko. Nie jest to coś co mozna “zrobić z pamięci” jednej osoby. Skoro jest to zadanie dla wielu ludzi pełniących różne role, to znaczy że będzie miała miejsce dość złożona komunikacja polegająca nie propagowaniu informacji o tym co i jak ma powstać. Ta komunikacja, jak w każdej innej inżynierii, to schematy blokowe pokazujące różne aspekty projektowanego, a potem implementowanego i wdrażanego, systemu.
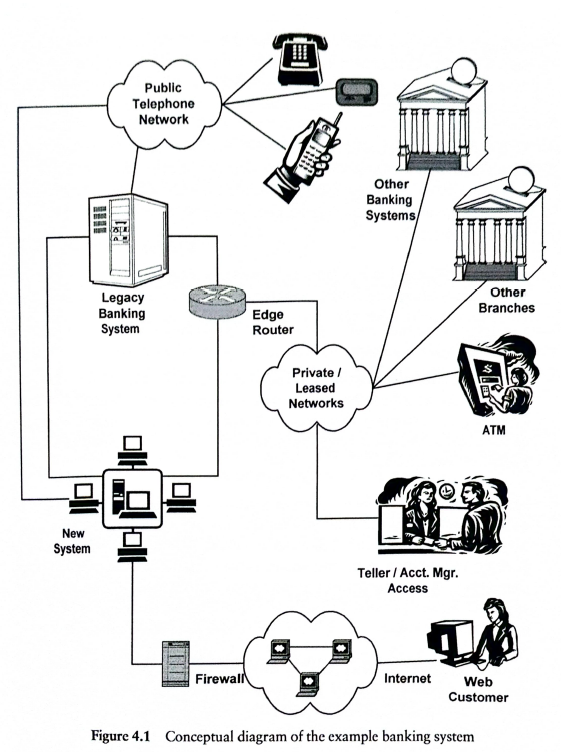
Kluczowym problemem w każdym projekcie jest jego zakres, dlatego pierwszym modelem powinien być model koncepcyjny. Celem Jego tworzenia jest zamknięcie listy “tego nas interesuje”. Jest to lekarstwo największe zagrożenie jakim jest utrata panowania nad zakresem projektu (pełzający zakres projektu). Poniżej przykład poglądowego modelu koncepcyjnego:
Po wskazaniu, który system konkretnie system jest przedmiotem projektu a co jest jego otoczeniem powstaje model kontekstowy wyrażony jako diagram przypadków użycia UML:
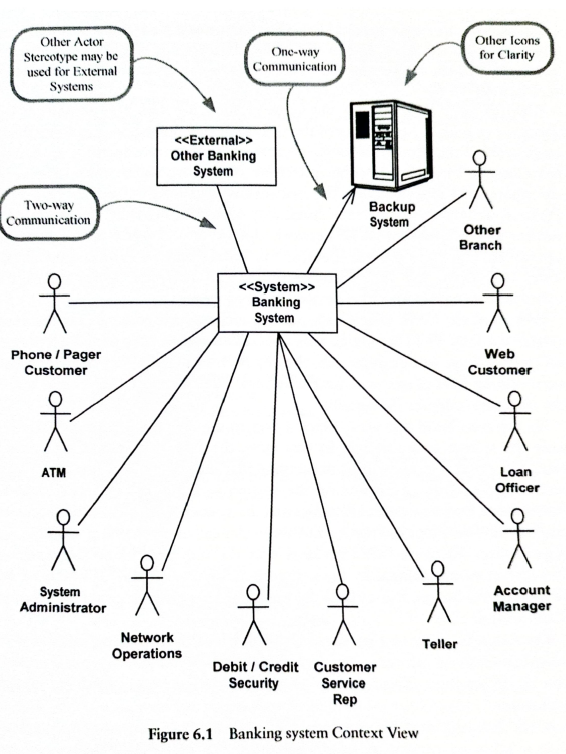
Na tym poziomie mogą zacząć powstawać modele opisujące interakcje systemu i jego otoczenia. To jest etap, w którym testujemy nasze koncepcje (i modyfikujemy modele, jeżeli okaże się jakieś scenariusz jest niewykonywalny):
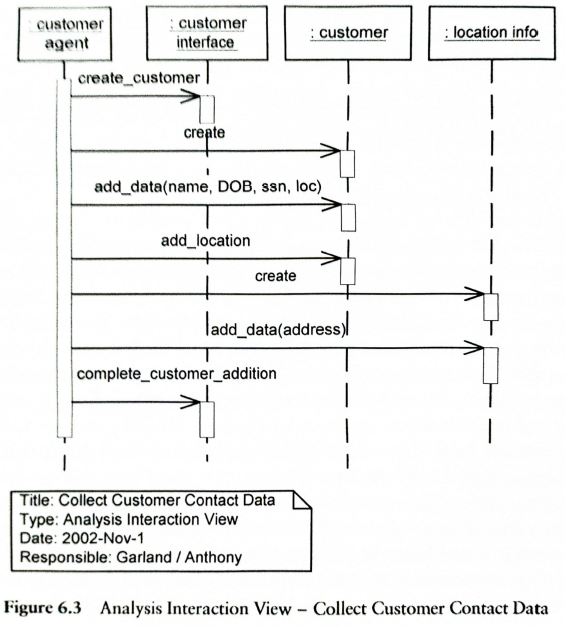
Takich schematów powstaje co najmniej tyle ile planujemy usług w projektowanym systemie:
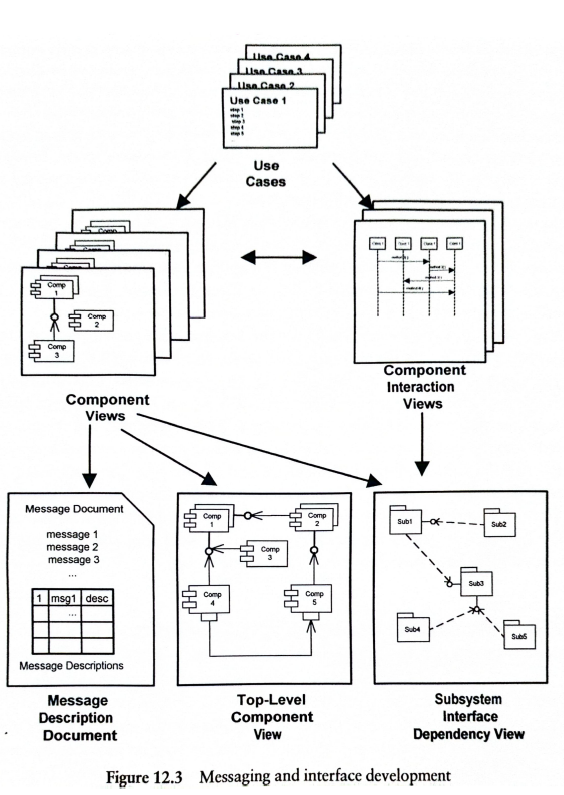
Testowane są wszystkie usługi (przypadki użycia na modelu przypadków użycia). Aby testy były możliwe muszą powstać modele architektury oraz struktury komunikatów (patrz diagram powyżej).
Na zakończenie
Nie było tu moim celem, jak zwykle w przypadku recenzji, streszczanie tej książki. Książka ma 260 stron i stanowi doskonałe, zwięzłe opracowanie na temat celu i metod projektowanie złożonych systemów. Autorzy podkreślają aspekty biznesowe i ekonomiczne: każdy błąd do ogromne koszty refaktoringu kodu, dlatego tego refaktoringu należy za wszelką cenę unikać: testy robimy na modelach.
Cała książka jest ilustrowana z użyciem UML. Autorzy ani razu nie użyli pseudo-kodu czy kodu jako przykładu. Rzecz w tym, że wybór technologii i języków programowania nie ma nic wspólnego z architekturą i funkcjonalnością (patrz rozdział o wzorcach MVC i port-adapter, znanym także architektura heksagonalna).
Książkę gorąco polecam, pozwala usystematyzować wiedzę i podejście do dużych projektów, bogato ilustrowana przykładami w UML, omawia użycie narzędzi CASE. Książka wydana w 2003 roku nadal świetnie się sprzedaje. Warto pamiętać, że pierwsze książki na temat projektowania poprzedzającego kodowanie i notacji UML zaczęły powstawać już rok po ogłoszeniu Agile Manifesto a autorami wielu z nich (ta akurat nie) są sygnatariusze tego manifestu, do najbardziej znanych autorów należą: Alistair Cockburn, Martin Fowler, Rober C. Martin.