Bardzo często spotykam się w firmach z wymaganiem by analiza zawierała “opis integracji”. Brzmi ładnie jednak “pod maską” czai się “diabeł”:
Obraz gęstej i coraz bardziej sieci aplikacji wyłania się z badania ponad tysiąca dyrektorów działów IT przez firmę Capgemini. Taki stan rzeczy obciąża departamenty IT i hamuje transformację cyfrową. (źr. Skomplikowana sieć aplikacji to kula u nogi działów IT. wnp.pl | Informatyka. Informatyka dla przemysłu.).
Opisze to krótko i od końca.
W ofertach i prezentacjach dostawców technologii integracyjnych nie raz zobaczymy piękny obrazek pokazujący jakie to zbawienie nas czeka po wdrożeniu magicznie brzmiącego ESB ([[Enterprise Service Bus]]). Z reguły ma to taką lub podobną postać:
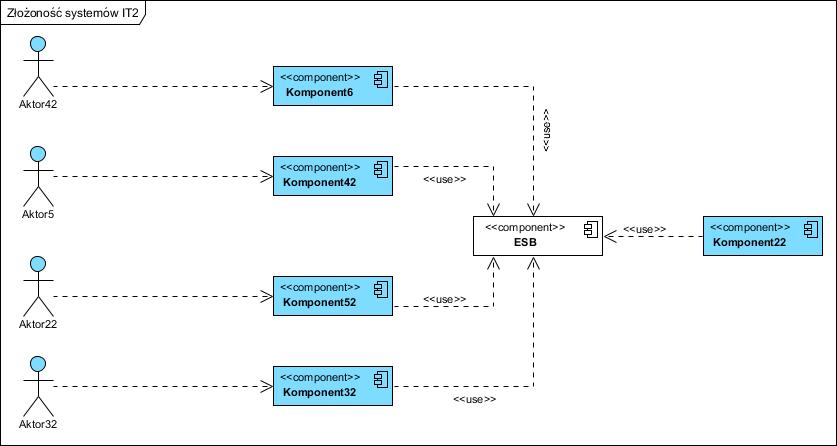
Na diagramie tym jednak “sprytnie” pokazałem wyłącznie odwołania pomiędzy komponentami ułożonymi w “gwiazdę”, której centrum stanowi ESB, a nie faktyczny przepływ danych. Diagram taki jest ładny bo prosty a do tego “nie kłamie”. Na czym polega podstęp? Na tym, że ESB to wyłącznie “pośrednik” w modelu komunikacji [[publish-subscribe]].
Tak na prawdę integracja taka polega nie na samym zainstalowaniu ESB i “podłączeniu” komponentów, to samo z siebie nic nie wnosi i nie jest łatwe. Integracja z użyciem ESB, to po pierwsze stworzenie (lub użycie jeżeli istnieje) dla każdego komponentu odpowiedniego adaptera i API, po drugie zaprojektowanie schematu (scenariuszy) komunikacji. Na tym etapie jeszcze nie widać podstępu. Widać go dopiero po odkryciu (udokumentowaniu), z reguły, bałaganu architektonicznego. Bardzo często komunikacja w takich sieciach ma taką postać (pokazano także użytkowników):
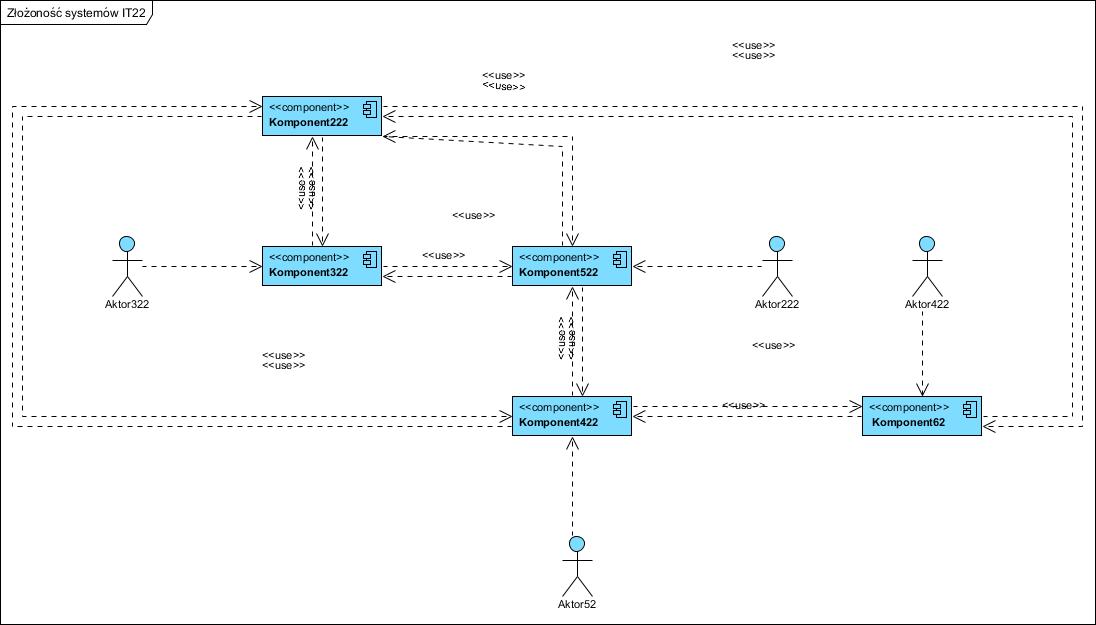
Tu bardzo delikatnie chciałem pokazać coś w rodzaju “niemalże każdy z każdym”, a mamy tu tylko pięć komponentów (aplikacji). A jak jest ich więcej? Bardzo często kolejne nowe aplikacje w firmach są kupowane i integrowane chaotycznie, bez przemyślanej wizji całości architektury. Mści się to w późniejszym okresie, przy każdej próbie ingerencji w taką strukturę (znam przypadki gdy tak bano się takiej ingerencji, że zaniechano rozwoju IT). To powód, dla którego wiele takich wdrożeń kończy się przerwaniem ich (czyli porażką). Jest to – porażka – prawie pewne, gdy jako metody integracji użyto współdzielenia danych (opisałem to tu).
W takich projektach pierwszą rzeczą jaką należy zrobić, to wykonać analizę i opracować model informacyjny firmy, czyli model tego jakie informacje są tworzone, po co i jak są ze sobą skojarzone, przetwarzane i przekazywane. W drugim kroku należy ustalić gdzie są ich wersje pierwotne (źródłowe, referencyjne) a gdzie wtórne (np. kopie wykorzystywane). Kolejny krok to uporządkowanie wymiany danych, doprowadzenie struktury sieci do postaci hierarchicznej (źródło referencyjne i użytkownicy), która bardzo uprości powyższy model, z reguły do postaci:
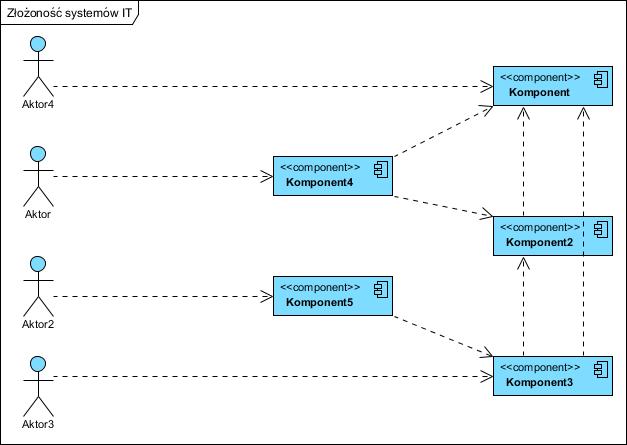
Taka analiza i optymalizacja pozwoli po pierwsze w ogóle opanować narastający latami chaos, a po drugie nie raz odkrywa się stare i nieużywane aplikacje czy dublujące się co do ich funkcjonalności, które po protu wyłącza się. Po takich porządkach wdrożenie ESB owszem wygląda jak na pierwszym diagramie, jednak projekt ma duże szanse powodzenia, znacznie większe w porównaniu z integracją “chaosu”. Podejście takie nazywane jest [[Enterprise application integration]].
Co ciekawe, po takim projekcie pozostanie nam dokumentacja systemu, którą wystarczy konserwować (to nie jest aż tak kosztowne ale zawsze znacznie tańsze niż kolejna analiza od zera przy kolejnym wdrożeniu). Z taką dokumentacją już tylko krok do SOA i architektury korporacyjnej :).
Bardzo ciekawy artykuł dotyczący utrzymania lub rezygnacji ze “starych aplikacji” zawiera COMPUTERWORLD nr 9/2014



