Dwa tygodnie temu, na konferencji o jakości systemów IT, prezentowałem między innymi dwa poniższe wykresy:
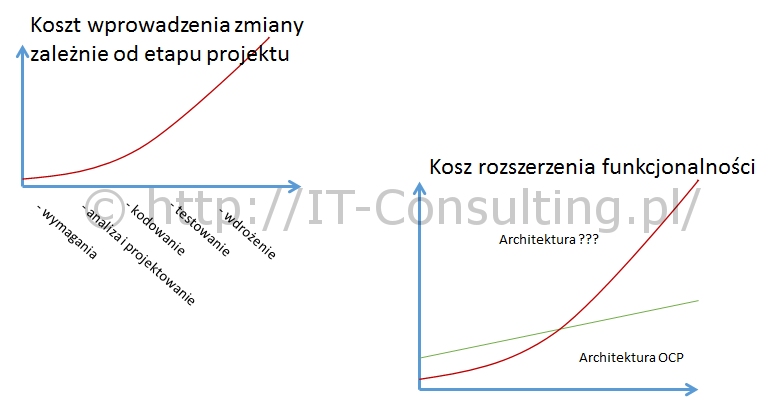
Pierwszy wykres jest bardzo popularny w literaturze przedmiotu, tu jeden z wielu przykładów. Powołam się na niego później.
Drugi jest wynikiem moich studiów literatury , własnych badan i doświadczenia i właśnie o nim nieco więcej. Wyjaśnię jak powstał.
W zasadzie wystarczy uznać, że jeżeli spełnienie zasady “[[open closed principle in object oriented software]]” (architektura systemu jest otwarta na rozszerzenia i zamknięta na zmiany) jest możliwe, to kod tak zbudowanej aplikacji “rośnie” liniowo, a koszt rozwoju podobnie. Początkowy koszt, to koszt opracowania szkieletu (zwanego [[core domain]]). To właśnie – w aplikacjach konstruowanych zgodnie z [[zasadami SOLID]] – powoduje, że koszt początkowy jest relatywnie wyższy niż koszt architektury budowanej “ad-hoc” (oznaczonej ???).
Nie mam ambicji tworzenia przykładu “brzydkiej architektury”, chyba już nie umiem 😉 dlatego poniżej tylko struktura aplikacji (architektura komponentu Model/MVC) w obiektowym paradygmacie (aplikacja to współpracujące obiekty) zgodna z SOLID:
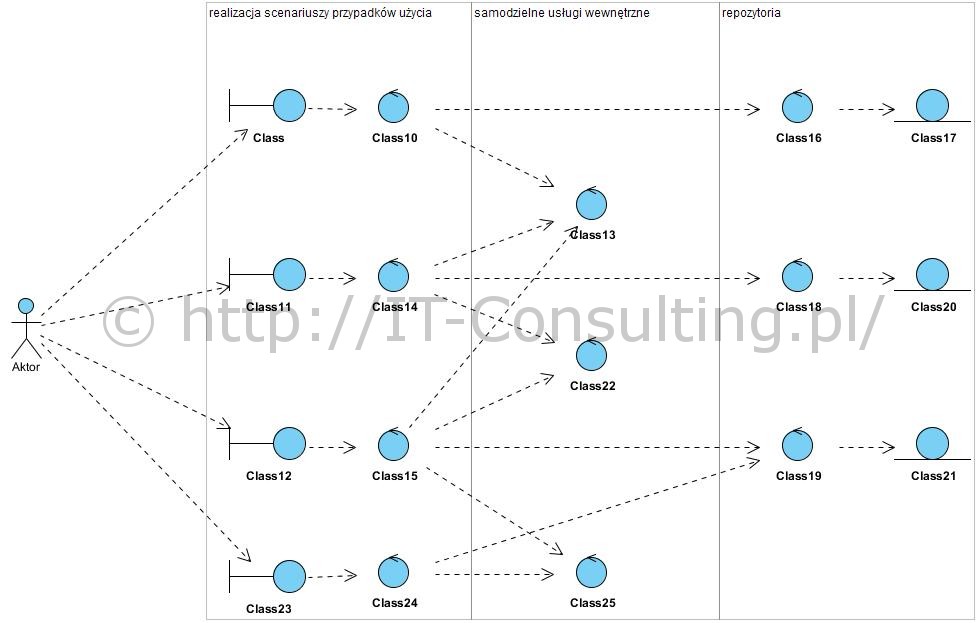
Model ten powstał z użyciem bloków funkcjonalnych wzorca BCE (opisałem go tu: Wzorzec analityczny Boundary Control Entity). Dla wyjaśnienia: powyższy diagram to w pełni poprawny Model dziedziny wykonany z użyciem diagramu klas UML, klasy mają stereotypy boundary, control i entity (powyżej od lewej do prawej), stereotypy te są reprezentowane symbolami opisanymi (ikonami) w BCE. Kilka cech tej architektury:
- każdy przypadek użycia ma dedykowaną klasę (ta połączona z aktorem) odpowiedzialną za jego interfejs i scenariusz (ale nie logikę biznesową!),
- scenariusz przypadku użycia to “recepta” na to, kiedy i czego wewnątrz aplikacji należy użyć do realizacji celu użytkownika,
- to co “potrafi” aplikacja to usługi wewnętrzne (logika biznesowa),
- to co aplikacja musi “wiedzieć” zapamiętało się (jest przechowywane) w repozytoriach,
- żadne informacje nie są, logicznie ani w szczególności fizycznie, współdzielone: każde repozytorium, powyżej są trzy, jest w 100% hermetyzowane (implementacja repozytoriów to absolutnie! nie jest jedna współdzielona relacyjna baza danych i mapowanie ORM!).
Widać (mam nadzieję na tym dość prostym schemacie), że każdy przypadek użycia to odrębny “serwis”, praktycznie niezależna usługa (u Fowlera nazywane mikroserwisami). Są od siebie całkowicie odseparowane, co najwyżej korzystają z tych samych specjalizowanych usług wewnętrznych (np. z generatora plików PDF będzie korzystała każda usługa operująca na dokumentach do druku). Dodanie kolejnego przypadku użycia w ogóle nie wpływa na resztę aplikacji (zaleta hermetyzacji), ewentualne redundancje są raczej zbawieniem niż wadą, gdyż każda usługa ma swój kontekst i własny cykl życia, i jakiekolwiek współdzielenie treści (nie mylić z wykorzystaniem tych samych) raczej zmusi do (zgniłego) kompromisu.
Współdzielenie danych najczęściej przynosi szkody, np. współdzielenie listy produktów pomiędzy zamówieniem i fakturą powoduje zależność uniemożliwiającą wystawienie faktury na produkty inne (w innej ilości) niż na tym zamówienia (nie takie rzadkie zjawisko w dostępnych na rynku systemach ERP). Utworzenie faktury poprzez skopiowanie (wykorzystanie) zawartości Zamówienia, pozwala na jej (faktury) dowolną modyfikację bez potrzeby zmiany Zamówienia (żądania powtórnego jego przysłania lub o zgrozo, wewnętrznej korekty!). Współdzielenie danych firm pomiędzy np. fakturami i rejestrem kontrahentów, skutkuje problemem gdy aktualizacja adresu kontrahenta przenosi się na historyczne faktury. Owszem może nam się przytrafić koszt nowej usługi wewnętrznej, ale zrobimy to bez jakiejkolwiek ingerencji w dotychczasową logikę (i kod).
Aplikacje, których architektura wewnętrzna bazuje na współdzielonych danych, relacyjnej jednej bazie danych (jeden spójny system tablic relacyjnej bazy danych “pod” aplikacją), gęstej sieci wewnętrznych zależności, wymagają – dla dodania nowej usługi lub zmiany istniejącej – prawie zawsze częściowego lub całkowitego re-faktoringu, a w skrajnych przypadkach nawet migracji danych do nowej ich struktury. W efekcie, to co użytkownik postrzega jako rozszerzenie, dla dewelopera stanowi pracochłonny refaktoring, tym bardziej pracochłonny im większa ta aplikacja. Z tego powodu koszty wprowadzania zmian do tak stworzonej aplikacji są tym większe im większa i złożona jest ta aplikacja (czerwona linia na wykresie kosztu rozszerzenia funkcjonalności).
Pisanie oprogramowania ad-hoc, bez przemyślanej logiki i architektury całości, prowadzi do powstawania tak zwanego “[[długu architektonicznego]]” (analogicznie do [[dług technologiczny]]). To dlatego bardzo często źle pojmowane “agile” pozwala bardzo szybko uzyskać pierwsze efekty, niestety okupione bardzo kosztownym późniejszym utrzymaniem i rozwojem takiej aplikacji. Chyba, że produkt taki potraktowany zostanie jako efemeryda albo jako prototyp odrzucany.
Niestety wiele systemów ERP i i nie tylko, powstało w latach 90’tych, mają one niestety scentralizowaną architekturę strukturalną (jedna baza danych i “nad nią” funkcje przetwarzające te dane). Efekty tego widać przy wdrożeniach, w których dopuszczono tak zwaną kastomizacje systemu, czyli właśnie wprowadzanie, nie raz bardzo wielu, zmian. To bardzo kosztowne projekty o praktycznie nieprzewidywalnym budżecie. Niestety współdzielenie danych wewnątrz takiego systemu jest jego poważną wadą a nie – jak to zachwalają ich dostawcy – zaletą…



{kind=link}