Często spotykam się z czymś takim jak “Diagramy klas (UML) to modelowanie wymagań z perspektywy danych (model danych)“. Jest to niestety dość często spotykana “herezja”, także w zalecanej przez wielu literaturze, o czym swego czasu wspominałem:
Regularnie widuje pytania takie jak to: I have an assignment for developing a hotel reservation system! One of tasks is to develop UML class diagram! However, in the task description it is written ?Class diagram should represent your database?. I am a bit confused about the rules, notations and etc? because I can?t find any official UML class diagrams specifically for databases! Could you help me please? (UML class diagram for database). I regularnie piszę: używanie diagramu klas jako reprezentacji [relacyjnej] bazy danych to świadectwo kompletnego niezrozumienia analizy i projektowania zorientowanego obiektowo (żeby nie powiedzieć ignorancji). Jest to także świadectwo braku znajomości literatury, bo faktycznie, jak zauważa autor powyższych słów, nie ma oficjalnych materiałów (organizacja standaryzująca) mówiących o modelowaniu danych diagramami klas w notacji UML. Do modelowania danych używamy notacji ERD (ang. Entity Relationship, diagram związków encji). Niestety takie wzmianki ? jak stosować diagram klas UML do modelowania danych ? można znaleźć w książkach uznawanych za wartościowe (okładka jednej z nich po prawej), można usłyszeć na wielu szkoleniach dotyczących notacji UML, a nawet usłyszeć o tym można ? modelowanie danych w UML ? z ust niejednego wykładowcy na uczelniach wyższych technicznych (co jest smutne, mam na półce podręcznik akademicki z opisem stosowania kluczy głównych i obcych na diagramach klas UML w modelowaniu danych). Źródło: Business Analysis ? diagram klas UML i bazy danych | Jarosław Żeliński IT-Consulting
Przypomnę po raz kolejny czym jest obiektowy paradygmat analizy i projektowania:
Paradygmat obiektowy analizy i projektowania to uznanie, że analizowany lub projektowany system to współpracujące w określonym celu obiekty.
Definicja ta jest zbieżna z definicją pojęcia system: złożony obiekt wyróżniony w badanej rzeczywistości, stanowiący całość tworzoną przez zbiór obiektów elementarnych (elementów) i powiązań (związków i relacji) między nimi (Sienkiewicz, 1994).
Innymi słowy system, w rozumieniu ogólnej teorii systemów (UML i metody obiektowe wspierają właśnie tę teorię), system to zbiór współpracujących obiektów. Nie ma tu żadnej mowy o danych. Dlaczego? Bo współpracują ze sobą obiekty a nie dane. Owszem, dysponujemy nimi, ale … Każdy zespół współpracujących ludzi niewątpliwie wykorzystuje, a nie raz przetwarza, określone informacje. Jednak ta współpraca polega na współpracy, informacje są wymieniane na określonych nośnikach, to obiekty biznesowe. Np. celem negocjacji jest współpraca negocjatorów i podpisana umowa (jej treść to szczegóły przydane w sporze oraz cel zawarcia umowy), celem sprzedaży jest przychód (a nie faktura), celem dostawy jest towar w określanym miejscu i czasie (list przewozowy wskazuje miejsce i czas, dokument WZ to tylko specyfikacja konkretnego przedmiotu tej dostawy) itd.
Popatrzmy na jeden z wielu szkieletów tak zwanej architektury biznesowej (architektura biznesowa, architektura korporacyjna):
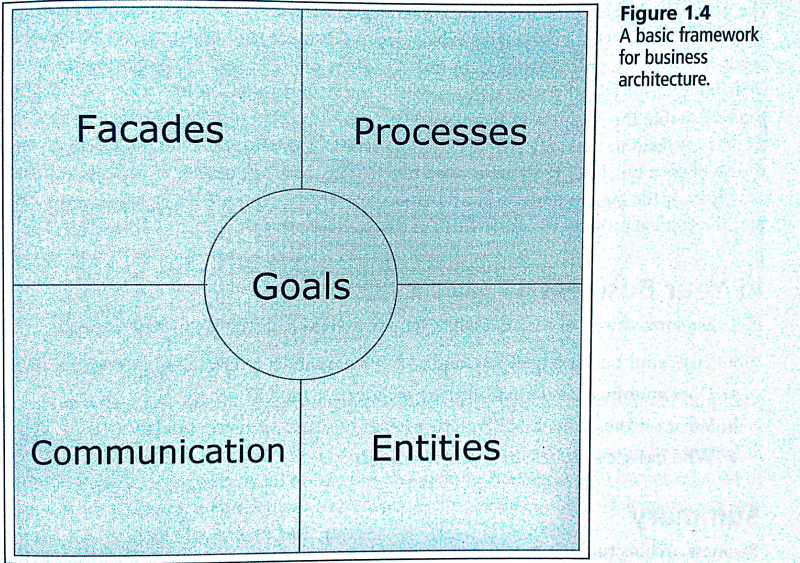
(źr. https://it-consulting.pl//2014/10/07/wstep-do-architektury-biznesowej/)
Ma ona, każda organizacja, przede wszystkim cele. By mogła je realizować ma: fasadę (tak się objawia na zewnątrz), wewnętrzne procesy biznesowe, metody komunikacja (z otoczeniem), oraz “entities” (nie mylić z modelem relacyjnym danych) czyli obiekty biznesowe, to co jest “mięsem” całości, bo to one ze przedmiotem współpracy i niosą informacje. Każda organizacja to system złożony ze współpracujących elementów: tych niosących informacje i tych mających wiedzę o mechanizmach (logice) tej współpracy.
Kolejna ważna rzecz to zauważenie, że oprogramowanie to narzędzie pracy. Część (rzadko kiedy wszystkie) obiektów biznesowych (są nimi dokumenty i ich treść) będzie miała swoje wersję elektroniczną, co jednak nie zmienia faktu, że to jedyna zmiana!
Tak więc kilka słów o wymaganiach na narzędzie pracy. Oprogramowanie to narzędzie pracy, wyrafinowane ale jednak tylko narzędzie, które jest deterministyczne, czyli 100% zachowań tego oprogramowania jest przewidywalna i została z góry określona. Te zachowania to nic innego jak nasze wymagania wobec tego narzędzia pracy. Skoro jest to narzędzie, to wymagania są opisem tego narzędzia. I tu zaczyna się “zabawa”, bo jednak nie działa “klasyczne” i anachroniczne już moim zdaniem, zestawienie wymagania funkcjonalne i poza-funkcjonalne (to podział z lat 80-tych). Tu przypomnę, że młotek może mieć kilkanaście cech, które można nazwać funkcjonalnymi i poza-funkcjonalnymi, co nie zmienia faktu, że generalnie służy wyłącznie do uderzania w coś (świadczy jedną usługę), jest to przypadek użycia: uderzyć w coś. Stan początkowy: wiemy w co uderzyć i po co (z jaką siłą), stan końcowy to efekt pożądany (np. wbity gwóźdź). Panuje moda na nazywanie przypadkami użycia kontekstu z perspektywy aktora, było by więc: uderz w gwoźdź, uderz w ścianę, uderz w osobę, uderz w szybę, uderz w stół słabo, uderz w płytę chodnikową mocno, i tak mozna w nieskończoność jak tylko np. nie przerwiemy tak zwanych “warsztatów zbierania wymagań”. To, takie podejście, nie ma większego sensu, bo zamula developera nadmiarem informacji i nic nie mówi o konstrukcji młotka.
Bardziej wyrafinowana usługą będzie zarządzanie danymi kontaktowymi. Mamy więc szafkę, szuflady, a w nich kartoteki z danymi kontaktowymi. Jest to narzędzie pracy, całość – szafka i jej zawartość – to “martwa natura”, której użytkownik (aktor) używa w sobie tylko znanym kontekście. Może nim być zapamiętywanie adresów dostawców, odbiorców, potencjalnych klientów, itp. Z uwagi na to, że ma być postęp, opisujemy tę szafkę razem z archiwistą (oprogramowanie zastąpi część jego pracy), który zarządza dostępem do niej. Czy karta katalogowa wie do czego jest używana? Nie. Czy cel użycia cokolwiek zmienia w konstrukcji tego mebla i jego zawartości? Nie. Więc co? Tu obiektem biznesowym będzie nośnik danych kontaktowych, jednak to my decydujemy co i po co zapisujemy a nie szafka, archiwista też nie wnika w treść. Owszem, wygodnie będzie opracować jednakowy szablon na te dane, nadal nie zmienia to faktu, że będziemy zaznaczali np. w polu “typ adresu” jakimś słowem czy dany adres to dostawca, odbiorca, czy może zainteresowany potencjalny klient.
Co tu jest wymaganiem? Zamawiając elektroniczną wersje kartotek, powiemy co nieco o łatwości dostępu, o wyszukiwaniu, o kontroli dostępu, i gdzieś na końcu przytoczymy wzór karty katalogowej. Dodamy reguły biznesowe (zastąpimy archiwistę), np. dane jednej osoby powinny być tylko na jednej karcie (brak dubletów) a świadectwem unikalności będzie zgodność imienia, nazwiska i kodu pocztowego (są też inne pomysły). Inną regułą może być zakaz niszczenia kart, żądanie niekontaktowania się może być realizowane dodatkowym zapisem “nie dzwonić”, nasze oprogramowanie przejmie na siebie procedury realizowane przez archiwistę.
Czy mamy tu jakąś “perspektywę danych systemu”? Gdybyś my mieli docelowo stworzyć oprogramowanie w modelu “dane + funkcje = program” to tak, ale my mówimy o obiektowych metodach analizy i projektowania, mówimy o tym deklarując użycia notacji UML (jest obiektowa). Każda większa aplikacja to wiele takich osobnych szafek na dokumenty, wiele reguł biznesowych powiązanych z dokumentami, całymi szafkami, oraz mechanizmy operowania tymi dokumentami w konkretnych celach. Czy ma tu jakikolwiek sens “wyciąganie” tego, że adres korespondencyjny podmiotu powtarza się w różnych kontekstach na większości tych dokumentach? Czy ma sens wyciąganie “na wierzch” tego, że połowa dokumentów zawiera coś takiego jak “produkt”. Nie ma to żadnego sensu, bo po pierwsze te szafki i kartoteki, każda żyje własnym życiem i nie zmienimy tego, w każdej chwili może nam dojść nowa szafka z nowymi papierami, a stara zniknąć gdy stanie się niepotrzebna. Może nam się przytrafić rezygnacja z szafki na rzecz korzystania z usługi biura numerów na telefon. Takich sytuacji nie tylko nie jesteśmy w stanie przewidzieć, możemy nie mieć możliwości przeciwdziałania temu (np. zmiany w prawie).
Obiektowe podejście uwalania nas od zajmowania się osobno “wspólnymi danymi”, powiem wręcz, podejście takie – usuwanie redundancji i współdzielenie – jest wręcz szkodliwe, “Perspektywa danych” to strukturalne a nie obiektowe podejście, nie ma w nim nic złego ale nie mieszajmy tego. Pisałem o tym:
Metody strukturalne to rozkładanie problemu biznesowego na oddzielone od siebie dane i procedury ich przetwarzania. Informacje o obiektach rzeczywistych są tracone w tych metodach. Model relacyjny danych to model, w którym utracono wiele informacji, np. nie da się z modelu relacyjnego odtworzyć np. faktury nie wiedząc jak ona wygląda. Do wydruku faktury potrzebne jest zapytanie, które wyciągnie z bazy danych właściwe dane i procedura która właściwie je sformatuje. Metody obiektowe polegają na wiernym modelowaniu (odwzorowaniu) świata rzeczywistego (domeny systemu), w efekcie nie tracimy żadnej wiedzy modelując (zapisując) ?świat? w postaci modelu dziedziny. Źródło: Czym jest a czym nie jest tak zwany model dziedziny systemu | Jarosław Żeliński IT-Consulting
Czy mamy więc jakieś perspektywy w modelach obiektowych? W zasadzie tylko dwie:
– przypadki użycia (diagram przypadków użycia) i skojarzone z każdym z nich scenariusze, jako opisy tego jak system ma się zachować w odpowiedzi na próbę jego użycia,
– struktura wewnętrzna tego systemu (model dziedziny systemu – diagram klas) , odwzorowująca “współpracujące obiekty”, jest to opis mechanizmu działania tego systemu (bloki funkcjonalne, obiekty i komponenty).
Czy ma sens tworzenie zamówienia na szafki do kartotek wysyłając tylko zdjęcie strony czołowej wraz z dziesiątkami stron opowieści o tym jak do tej pory ich używano? Jest to bardzo ryzykowne podejście. Duże bezpieczniej jest zaprojektować konstrukcję takiej szafki, wskazując gdzie jakie zamki i blokady chcemy mieć i dać taki projekt do wykonania. Owszem nie ma sensu odbieranie chleba inżynierom, pisanie z jakich materiałów to ma być zrobione i jakimi technikami wykonane i zabezpieczone. Ale wewnętrzne, “czysto biznesowe” szczegóły takie jak podział na szuflady, wzory kartotek, wymóg możliwości ich modyfikacji, kontrola dostęp do szuflad, owszem: to warto opisać samemu (lub zatrudnić projektanta).
Wiele książek zawiera opis tak zwanego widoku 4+1 Kruchtena. Co tam mamy? To jeden z wielu dostępnych w sieci opisów:
perspektywa logiki biznesu ? istnieje w każdym systemie informatycznym i ukazuje różne elementy systemu informatycznego w kontekście logiki biznesu, takie jak klasy, pakiety itp.;
perspektywa procesów ? opisuje wszystko co jest związane z współbieżnością pracy SI, najczęściej opisuje komunikację i synchronizację różnych komponentów systemu i z reguły dotyczy systemów rozproszonych i/lub współbieżnych;
perspektywa implementacji ? opisuje sposób implementacji elementów składowych systemu, z reguły jest to statyczny opis składowych elementów systemu w jego fizycznym środowisku (deweloperskim, a docelowo produkcyjnym);
perspektywa wdrożenia ? opisuje sposób fizycznego kopiowania i wdrażania różnych elementów SI, sposób ich komunikowania się w kontekście ich fizycznego rozlokowania na docelowej platformie informatycznej;
perspektywa przypadków użycia ? opisuje najbardziej znaczące wymagania SI dla użytkowników końcowych, czyli te przypadki użycia lub ich części, które wywierają największy wpływ na architekturę i są najbardziej krytyczne do zobrazowania mechanizmów działania systemu.

Wystarczy porównać to z moim opisem powyżej, by zauważyć, że powyższe to zbędne komplikowanie całości i niepotrzebne wplatanie kontekstu biznesowego (młotek nie wie w jakim celu jest używany).
Implementacja to praca dla developera a mieszanie w to późniejszego wdrożenia już zupełnie pomieszanie celów specyfikowania wymagań.
Przypadki użycia to zewnętrzne (widziane przez jego użytkownika) cechy systemu. Używanie słowa “proces” do tego co w UML nazywa się “sekwencja” powoduje tylko nieporozumienia, tu każdy przypadek użycia jest realizowany z użyciem wewnętrznych komponentów, jest to logika biznesowa (mechanizm działania) czyli i model dziedziny. Nie przypadkiem kluczową cecha obiektowego podejścia jest hermetyzacja czyli ukrywanie wnętrza komponentów (do samego końca). Najpierw analizujemy i dokumentujemy do czego służy faktura, a na końcu (mają kompletny projekt) upewniamy się (testujemy), że każdy komponent dysponuje wiedzą potrzebną mu do realizacji przypadku użycia. Na samym końcu jest mowa o danych, i nie jako odrębnej perspektywie, a jako wewnętrznych cechach (atrybutach) komponentów. Tu dopiero definiujemy ewentualne zawartości dokumentów reprezentowanych w modelu dziedziny przez odrębne komponenty. I absolutnie nie uwspólniamy (nie normalizujemy, nie pozbywamy się redundancji) na co zwróciłem uwagę na początku.
Nie powinniśmy zapominać, że model Kruchtena to połowa lat 90-tych, szczyt rozkwitu metod strukturalnych i raczkujące metody i narzędzia obiektowe. To stare systemy i ich relacyjne bazy danych wymusiły stosowanie [[mapowania ORM]] i takich narzędzi jak [[Hibernate]]. Dzisiaj mamy rok 2015, od tamtej pory minęło 20 lat. Nie musimy się cofać do początków inżynierii oprogramowania w wersji obiektowej. Coś takiego jak perspektywa danych to anachronizm. Podejście to w 100% zostały już dawno zastąpione przez MDA. Ale o tym już tu pisałem 😉



