Wprowadzenie
Bardzo często spotykam się z metodami wymiarowania oprogramowania, czyli mówiąc ludzkim językiem: oceny pracochłonności jego wytworzenia. Typowym argumentem za stosowaniem tych metod jest potrzeba planowania. Nie raz spotykam się z porównaniami do pomiaru powierzchni np. w budownictwie (cytat celowo ze strony stosownego stowarzyszenia):
Wymiarowanie oprogramowania, ma podobne znaczenie, co wymiarowanie w innych dziedzinach inżynierii. Określa wielkość, pozwala na porównywanie różnych przedsięwzięć, szacowanie kosztów wytwarzania i lepsze planowanie. Punkty funkcyjne ? najbardziej popularna i promowana przez specjalistów jednostka wielkości oprogramowania, to przykładowo odpowiednik metrów kwadratowych w budownictwie. Wyobraźmy sobie tę branżę, przy założeniu, że nie posługujemy się żadną jednostką powierzchni. Inwestycje byłyby wyceniane, a ich realizacja planowana nawet bez próby oszacowania np. powierzchni użytkowej? Wydaje się to absurdem, a jednak w takiej rzeczywistości funkcjonuje rynek oprogramowania i niestety -związany z nim świat zamówień publicznych.Nie jest to tylko problem polski, jest to bolączka całej branży. Nic dziwnego, że aż 63% projektów kończy się porażką, a planowany czas przekraczany średnio o 80%, zaś koszty średnio o 55%. Na świecie straty będące skutkiem tych niepowodzeń liczone są w setkach miliardów dolarów rocznie. Walkę z tym problemem podjęto już wiele lat temu. Zamawiane oprogramowanie, wszędzie tam gdzie decydenci są świadomi zagrożeń, jest mierzone. A coraz więcej administracji państwowych jako normę, traktują obowiązek wymiarowania oprogramowania przed jego zamówieniem. Dobre praktyki i narzędzia będące wynikiem tej batalii są na wyciągnięcie ręki.
(pierwotne źródło jest niedostępne, porównaj inny materiał: https://www.computerworld.pl/news/Skuteczne-metody-wymiarowania-projektow-IT,408593.html)
Ogólnie teza jakiej bronią zwolennicy tego typu metod brzmi:
możliwe jest oszacowanie pracochłonności (kosztu) wytworzenia oprogramowania wyłącznie na bazie wiedzy o tym, do czego ma ono służyć
Innymi słowy uważamy, że na bazie wymagań funkcjonalnych (z reguły mowa o przypadkach użycia) można oszacować złożoność aplikacji. Niestety w swojej wieloletniej karierze nigdy nie spotkałem się z przypadkiem by wycena taka choć zbliżyła się do późniejszych faktycznych kosztów wytworzenia aplikacji (rzadkie przypadkowe zbieżności nie są dowodem skuteczności metody). Raczej spotykam się dość często z czymś co opisałem w 2013 roku (tych wycen, zgodnie z SIWZ, dokonano na bazie metody punktów funkcyjnych):
Co mnie zastanawia? Przede wszystkim to, że ?profesjonalne? firmy z ogromnym (jak twierdzą na swoich stronach) doświadczeniem, prezentują oferty opracowane na bazie tej samej dokumentacji (w końcu to przetarg), a rozrzut cen tych ofert jest czterokrotny!!! ?(Żeliński, 2013)?
Takich przypadków jest wiele, i moim zdaniem praktycznie obalają tezę o skuteczności tego typu metod (metoda punktów funkcyjnych i pokrewne).
Punkty funkcyjne
Jedną z popularniejszych i często promowanych metod jest analiza punktów funkcyjnych promowana przez International Function Point Users Group (IFPUG). W tej rodziny należy między innymi COSMIC. Metoda ta bazuje na dość prostych założeniach:
The principles for measuring the COSMIC functional size of a piece of softwareThe COSMIC method measures a size as seen by the ?functional users? of the piece of software to be measured, i.e. the senders and/or intended recipients of the data that must enter or exit from the software, respectively.The method uses a model of software, known as the ?COSMIC Generic Software Model?, which is based on fundamental software engineering principles, namely:Functional user requirements of a piece of software can be analyzed into unique functional processes, which consist of sub-processes. A sub-process may be either a data movement or a data manipulation;Each functional process is triggered by an ?Entry? data movement from a functional user which informs the functional process that the functional user has identified an event that the software must respond to;A data movement moves a single data group of attributes describing a single ?object of interest?, where the latter is a ?thing? of interest to a functional user;There are four types of data movement sub-processes. An ?Entry? moves a data group into the software from a functional user and an ?Exit? moves a data group out. ?Writes? and ?Reads? move a data group to and from persistent storage, respectively.[…]
As an approximation for measurement purposes (and in light of the applicability of the method, described above), data manipulation sub-processes are not separately measured.
The size of a piece of software is then defined as the total number of data movements (Entries, Exits, Reads and Writes) summed over all functional processes of the piece of software. Each data movement is counted as one ?COSMIC Function Point? (?CFP?). The size of a functional process, and hence the size of a piece of software, can be a minimum of 2 CFP, with no upper limit. (The COSMIC Software Sizing Methodology. (n.d.). Retrieved May 9, 2019, from COSMIC website: http://cosmic-sizing.org/cosmic-fsm/)
(zobacz także opis wdrożonej wersji udostępniony przez ZUS).
Model opisujący fundamentalne założenia tej metody wygląda tak:
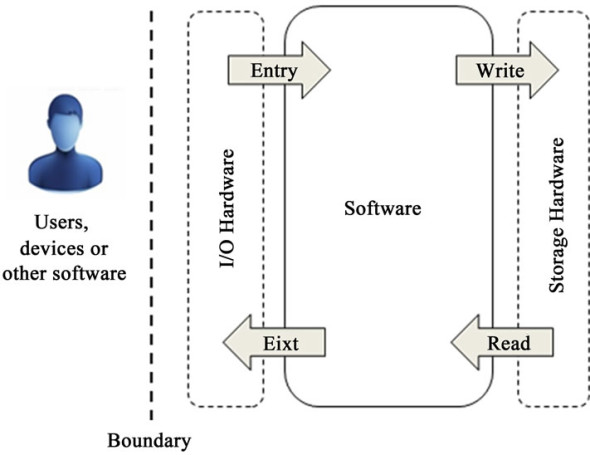
Generalnie na etapie analizy, bazującej na specyfikacji wymagań funkcjonalnych, tworzona jest lista interakcji z aplikacją Entry/Exit (czyli tego to co widzi i jest w stanie opisać przyszły użytkownik – lewa strona powyższego modelu) i lista operacji Write/Read (zapis i odczyt danych, prawa strona modelu). Komponent, który nazwano tu Software, to pewien rodzaj czarnej skrzynki. Metoda ta po pierwsze wymaga sprowadzenia wymagań do poziomu kuriozalnie rozdrobnionych przypadków użycia (co opisałem niedawno w artykule o pewnej metodzie transformacji procesu biznesowego na przypadki użycia), po drugie zupełnie abstrahuje od wewnętrznej złożoności (w najnowszej wersji tej metody przyjmuje się wagi złożoności, niestety są one uznaniowe). Metoda powstała ponad 30 lat temu, w czasach gdy inżynieria oprogramowania sprowadzała się do maksymy:
dane + funkcje = oprogramowanie
To jest niestety jednak prehistoria inżynierii oprogramowania. Owszem powstaje jeszcze oprogramowanie w myśl tej maksymy (głównie systemu zarządzania wiedzą), ale nawet średnio złożone biznesowe aplikacje, tworzone jako otwarte architektury obiektowe, niestety nie pasują do tego “wzorca”. porównajmy powyższy model z tym:
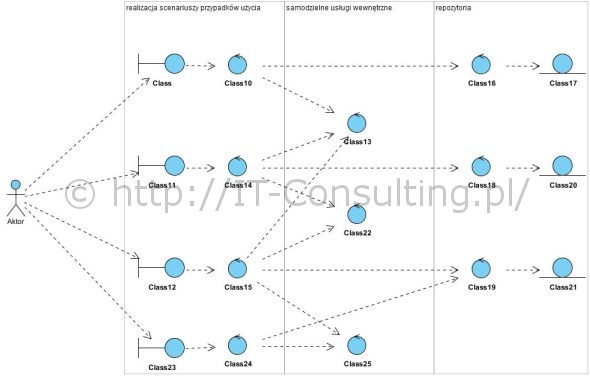
Powyżej dość typowa obiektowa architektura aplikacji. Kilka wniosków:
- przypadek użycia nie jest “niskopoziomową funkcją systemu”, takie ich definiowanie (niezgodne z UML) prowadzi do monstrualnej złożoności i pracochłonności już na etapie analizy wymagań,
- operacje zapisu i odczytu danych (repozytoria, obiekty skrajnie po prawej) w żaden sposób nie odzwierciedlają złożoności aplikacji, ta “tkwi” w komponentach wewnętrznych a te nie są znane na tym etapie,
- wiele złożonych elementów kodu – samodzielne usługi wewnętrzne – nie ma bezpośrednio nic wspólnego ani z zapisem danych ani z interakcja z samą aplikacją,
- uznanie, że można oszacować złożoność wytworzenia systemu tylko na bazie planowanych funkcjonalności i modelu danych moim zdaniem jest nie obrony.
Powyższy model pokazuje, że kluczowa złożoność aplikacji tkwi w części nazwanej w COSMIC “software”, całkowicie pomiętej w toku prowadzenia szacowania.
Model COSMIC (i podobne metody) całkowicie abstrahuje od tego, że aplikacja mogła by powstać na bazie obiektowego paradygmatu i wzorców SOLID (w szczególności otwartość na rozszerzenia przy braku wprowadzania zmian czyli tak zwane open close principle). Uznanie, że każde oprogramowanie można sprowadzić do poziomu operacji zapisu i odczytu z logiką takich operacji umieszczoną w odwołaniach do bazy danych, cofa nas o 40 lat, do czasów metod strukturalnych (w tych czasach powstała ta metoda COSMIC). Stowarzyszenie promujące metodę COSMIC pisze: “… 63% projektów kończy się porażką, a planowany czas przekraczany średnio o 80%, zaś koszty średnio o 55%. Na świecie straty będące skutkiem tych niepowodzeń liczone są w setkach miliardów dolarów rocznie …“, dodaje, że od 40 lat te statystyki się nie zmieniają a metoda ta ma porównywalny czas istnienia, wiec jak na tym tle ocenić jej stały rozwój i domniemaną skuteczność?
Wielokrotnie widziałem, jak budżet i harmonogram projektu wyliczony na bazie metody punktów funkcyjnych, był “niszczony” jednym tylko faktem rozpoczęcia dokumentowania i implementacji rabatowania w “przypadku użycia” Wystawianie Faktur Sprzedaży. Klasyka niejako obalająca skuteczność tej metody to system scoringowy, którego praktycznie cała złożoność leży poza operacjami wejścia/wyjścia, a tego rodzaju problemów w tak zwanych systemach biznesowych jest bardzo wiele, zaryzykuje nawet tezę, że to typowe problemy w obecnych systemach wspomagania zarządzania. Metody tego typu, nie raz oparta na zbieranym doświadczeniu, są nadal popuarcne .
Jak więc wymiarować oprogramowanie? Tu znowu pozostaje uczyć się od najstarszej dziedziny inżynierii czyli budownictwa: budowle można wycenić tylko na podstawie projektu całej konstrukcji (dla aplikacji jest to jej wewnętrzna architektura i logika działania), na bazie samego pomysłu na wielki dom nie da się wyliczyć ile będzie kosztowało jego postawienie. Od wielu lat mam do czynienia z ofertami składanymi w odpowiedzi na ten sam dokument opisujący wymagania, rozrzut wycen (bywa, że o rząd wielkości) obala każdą teorię mówiąca, że jest możliwe sensowne szacowanie na tym (przed-projektowym) etapie, a wiem, że wiele z tych wycen jest przygotowywanych właśnie na bazie metod opartych na punktach funkcyjnych.
Jedynym skutecznym sposobem jaki znam i jaki widuję w praktyce, jest wycena na bazie projektu zawierającego model dziedziny systemu z dokładnym modelem działania (logiki biznesowej). Dużo dokładniejsze są wyceny, dokonywane relatywnie niskim nakładem pracy, przez doświadczonych architektów oprogramowania na bazie co najmniej wstępnych projektów. Wycena na bazie “czarnej skrzynki”, jaką są przypadki użycia “deklarowane” przez zamawiającego, to raczej wróżenie z fusów.
[uzupełnienie] Pewną odmianą powyższej metody (COSMIC) jest metoda punktów funkcyjnych IFPUG (z International Function Point Users Group). Oparta jest deklarowanych funkcjonalnościach i zbieranych danych historycznych ze zrealizowanych projektów. Pomysł polega na uznaniu, że koszty implementacji “podobnych funkcji systemu” są także podobne.
Niestety to założenie nie znajduje potwierdzenia w praktyce a twórcy metody sami przyznają, że jej skuteczność jest niska .
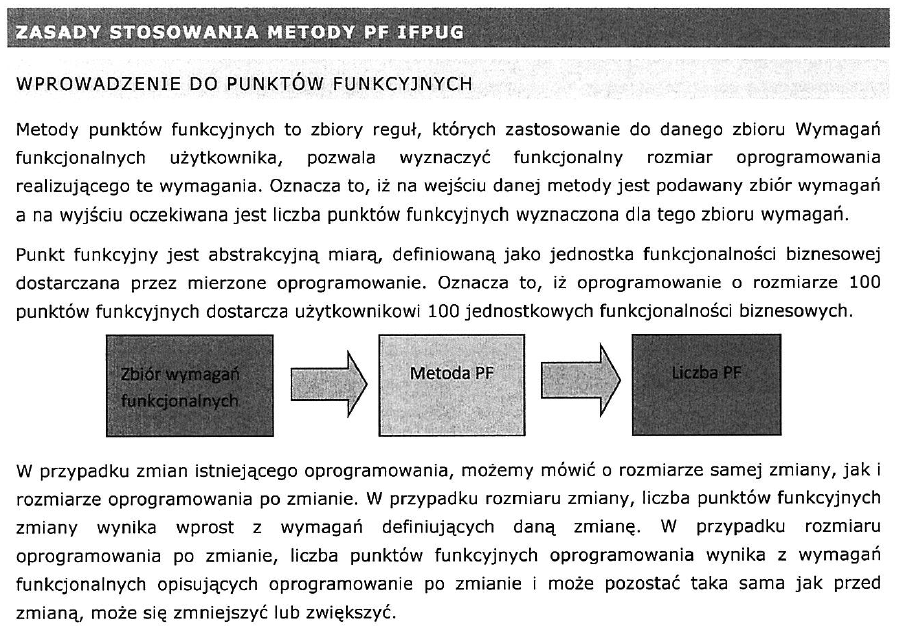
Powyższe to wstęp do pewnego oficjalnego dokumentu. Konia z rzędem temu kto określi pojęcie funkcjonalności biznesowej usługi aplikacji i jej liczbę jednostek, nie widząc jak będzie realizowana. Prosty przykład: aplikacja dla Biblioteki (patrz: Inżynieria oprogramowania z użyciem narzędzia CASE ? projekt badawczy) ma mieć funkcjonalność ‘wypożyczenie książki’ i ‘zwrot książki’, rzecz w tym, że najlepsza sprawdzona implementacja to nie będą “dwie funkcje” tylko jedna formatka ekranowa Karta Wypożyczenia a zwrot książki będzie realizowany poprzez wpisanie daty zwrotu na wystawionej wcześniej Karcie Wypożyczenia. W tym momencie wymiarowanie IFPUG (COSMIC także) jest po prostu funta kłaków warte: będzie potężnie zawyżone, a developer – pod dyktando takiej wyceny – wykona bardzo złą i kosztowną implementację. Innym powodem niskiej wiarygodności tego typu metod jest to, że na etapie w którym znamy przypadki użycia a nie znamy ich implementacji nie mam podstaw do oceny złożoności bo nie wiemy ile będzie scenariuszy dla każdego przypadku użycia a może ich być więcej niż jeden (patrz Use Case 2.0). Po trzecie jakość modelu przypadków użycia też ma ogromny wpływ na także wycenę (patrz Przypadki użycia i ich detale).
Podsumowanie
Metody wyceny bazujące na statystykach pochodzących ze zrealizowanych projektów są oparte na założeniu, że wyceniany projekt będzie realizowany tymi samymi lub analogicznymi metodami co samo z siebie jest zaprzeczeniem postępu technicznego i rozwoju metod inżynierii oprogramowania. Praktyka pokazuje, że wyceny tymi metodami są praktycznie prawie zawsze zawyżone a obszary nowatorskie mocno niedoszacowane lub przeszacowane (bo nowa funkcjonalność z zasady nie ma historii). W efekcie można podsumować to tak: metody statystyczne wymiarowania, oparte na przypadkach użycia lub funkcjonalnościach, to metody oparte na predykcji historycznych danych projektowych, gdzie materiałem wejściowym jest model czarnej skrzynki. Jeżeli do tego dodamy informację o jakości realizacji projektów informatycznych publikowane cyklicznie przez Standish Group:

To wniosek jaki się nasuwa to: stosowanie metod statystycznych, zawyżających wyceny, betonuje katastrofalny stan opisany w tych raportach. Alternatywą jest proces MDA/SPEM, który zakłada, że wycena będzie dokonywana dopiero po opracowaniu co najmniej wstępnego projektu implementacji usług aplikacji (przypadki użycia), co nie tylko uwiarygodni wycenę ale także rozwiąże wiele wątpliwości na tym wczesnym etapie.



Aplikację można bardzo dokładnie zwymiarować mając dokładny pojekt aplikacji. Nic dodać nic ująć. Tylko, musimy sobie zadać pytanie, jaki procent całkowitej aplikacji został już wykonany, w momencie gdy mamy dokladny projekt ? 20%, 30%, czy może połowa ?
W budownictwie, dokładny projekt kosztuje około 1% całej inwestycji. W przypadku oprogramowania, naprawdę dokładny projekt to gotowa aplikacja.
Patrzę na to tak. Idąc za MDA, model PIM (platform independent) to w zasadzie scenariusze realizacji przypadków użycia i udokumentowana logika domenowa (struktura obiektowa, biznesowe metody obiektów), która te scenariusze realizuje. Jest to niejako metamodel przyszłego kodu (dziedziny systemu), część domenowa odpowiadająca za realizację logiki biznesowej (czyli jakieś może 3-5% całego kodu 🙂 ). Cała reszta kodu to “inżynieria” realizująca wymagania pozafunkcjonalne.
To czy dopiero gotowa aplikacja jest jej jedynym projektem to kwestia tego co nazywamy “dokładnym projektem”. Tu się zgodzę, że robienie “tak dokładnego” projektu np. w UML nie ma żadnego sensu. Ale jeżeli “umowa” z developerem mówi, że “projekt” zawiera: architekturę kodu (logikę jego konstrukcji i działania) oraz to jak ta architektura ma realizować usługi aplikacji (scenariusze realizacji usług) to developer ma do wykonania (zaprojektowania) swój model PSM (platform specyfic) czyli implementację, zapewne ma masę problemów technicznych do rozwiązania ale logikę biznesową ma (te problemy rozwiązał mu analityk, projektant tej logiki). To dlatego nie wyobrażam sobie sensownego wymiarowania nakładu pracy tylko na podstawie “punktów funkcyjnych” i nigdy nie widziałem by taka prognoza się sprawdziła. Jedynym skutecznym sposobem wyceny jaki znam to zebranie ofert fixed-price na realizacje 🙂 i albo dostaje ofertę albo masę pytań o brakujące szczegóły :).
No i teraz: co nazywamy “wykonaną aplikacją”? Nawiązując do budownictwa: mając tylko projekt architektoniczny nie mam jeszcze nawet kawałeczka domu! Nadal pusta łąka!. Ale developer ma podstawę do opracowania kosztorysu… by złożyć ofertę.
“W budownictwie, dokładny projekt kosztuje około 1% całej inwestycji. W przypadku oprogramowania, naprawdę dokładny projekt to gotowa aplikacja.”
co jest nieprawdą, tak samo jak to, że dokładną dokumentacją techniczną samochodu nie jest samochód…