Wprowadzenie
Nie raz tu już pisałem, że analizy i projekty związane bezpośrednio z wymaganiami na oprogramowanie to “tylko” ok. 3/4 moich projektów. Jednak nawet, jeżeli projekt nie jest “nazwany” informatycznym, to zawsze jest “informacyjny” w rozumieniu zarządzania informacją (także zarządzanie wiedzą). Tym razem kilka słów na temat dokumentów. Stanowią one podstawową jednostkę informacji (i danych) w każdym systemie biznesowym. Są także źródłem danych dla hurtowni danych.
Wiele projektów związanych z dokumentami jest sprowadzanych do problemu:
“jakie mamy dokumenty i co z nimi robimy?”
Zaniedbuje się bardzo ważny element: odpowiedź na pytanie:
“czy nasze obecne dokumenty, ich ilość i treść, są właściwe?”
Otóż praktyka pokazuje, że dość często problemem są dokumenty opracowane “kiedyś tam”. Inicjuje się projekt z różnymi wymaganiami ale nikomu nie przychodzi do głowy by zastanowić się nad tym czy obecne dokumenty, w ich obecnej postaci, są dobrym pomysłem i powinny takie pozostać.
Czy dokumenty są niezmienialnym bytem? Nie, nie są.
Każda organizacja obraca skończoną liczbą dokumentów, są to różnego rodzaju formularze, w najogólniejszym przypadku dokumentem jest po prostu każda treść, także “zwykła proza” np. notatka. Warto jednak zwrócić uwagę na to, że nawet ona ma pewną strukturę: np. autora, adresata, temat, datę i treść. Dokumenty to określona konkretna treść utrwalona z określonego powodu (w przeciwnym wypadku dokument nie by powstał). Osiem lat temu opisywałem kwestie różnicy między dokumentem, wiedzą, informacją a danymi:
Czy baza danych to wiedza?[?] Model jawnie pokazuje, że bezpośredni związek z Bazą Danych mają Dane. Dalej już są wyłącznie niematerialne pojęcia czym więc jest Zarządzanie Wiedzą (milcząco zakładam, że zarządzać można czymś materialnym)? Jest to ?przechowywanie danych jednoznacznie zrozumiałych, opisujących określone i ograniczone liczbą fakty interpretowane jako pojmowalna przez adresata informacja?. (Źródło: Potrzeby informacyjne firmy ? Zarządzanie wiedzą | Jarosław Żeliński IT-Consulting)
Dzisiaj co nieco o tym, dlaczego od czasu do czasu warto się pochylić nad wzorami dokumentów i czy czasem nie zmienić nieco podejścia do nich.
Dokumenty w organizacji
Swego czasu u jednego z moich klientów “odkryłem” ciekawy dokument. Była to faktura z dodanym zestawem danych odpowiadającym dokumentom WZ oraz analogicznym zestawieniem dotyczącym opakowań zwrotnych. Ten super dokument był pomysłem z przed wielu lat osoby odpowiedzialnej za wydawanie i zarządzanie opakowaniami zwrotnymi w magazynie. Uzasadnienie brzmiało: na jednym dokumencie będą wszystkie informacje związane z konkretną sprzedażą i dostawą. Brzmi ładnie jednak: praktycznie każdy kto miał z tym dokumentem do czynienia, w toku obsługi zamówienia, dostawał nadmiarowe dane, nie raz niejawne (niektóre) ceny, szczegóły zawartości paczek, wartość towaru (po co ta wiedza kierowcom), ilości i salda (tak) opakowań zwrotnych (jak się okazało dokument nie raz pomagał w nadużyciach, niektórzy pracownicy zaś zamazywali czasami część danych przekazując dokument dalej, by ich nie ujawniać). Ale największym problemem było to, że ta osoba uczyniła z tego wzoru dokumentu wymaganie wobec oprogramowania ERP. Jak się nie trudno domyśleć, żaden rynkowy system nie ma takiego dokumentu standardowo, dostawca ERP uznał to wymaganie bez zastrzeżeń, co przyczyniło się do wielu modyfikacji oprogramowania także w innych miejscach, znacznego wzrostu budżetu (współdzielona baza danych propaguje zmiany praktycznie na całą aplikację). Nie będę tu opisywał dalszych losów tego wzoru dokumentu bo celem moim było jedynie pokazanie problemu na realnym przykładzie.
Każdy projekt, czy to wdrożenie nowych zasad zarządzania czy nowego oprogramowania, związany z zarządzaniem organizacją, to (powinien być) także co najmniej przegląd dokumentów i ich obiegu. Kluczowym elementem tego przeglądu powinna być analiza treści tych dokumentów, ich optymalność, nie tylko obiegu ale także treści i jej struktury. Owszem, wiele dokumentów ma narzuconą strukturę np. w odpowiedniej ustawie, jednak są to minimalne zawartości (np. faktura) nie ma zakazu uzupełnienia tej struktury i np. dodania do faktury numeru zamówienia, z którym jest związana.
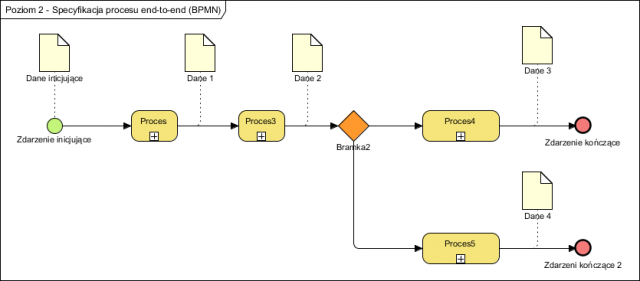
Ogólnie można określić pewne prawidłowości: jeżeli dokumenty są przeciążane treścią, czyli idziemy w kierunku małej ilości dokumentów zawierających dużo danych, rośnie złożoność reguł pracy z takim dokumentem. Jeżeli zaś idziemy w kierunku dokumentów “bardzo prostych”, rośnie ilość ich typów i rośnie liczba reguł kojarzących te dokumenty ze sobą w celu ich użycia. Ogólnie obrazuje to poniższy diagram:
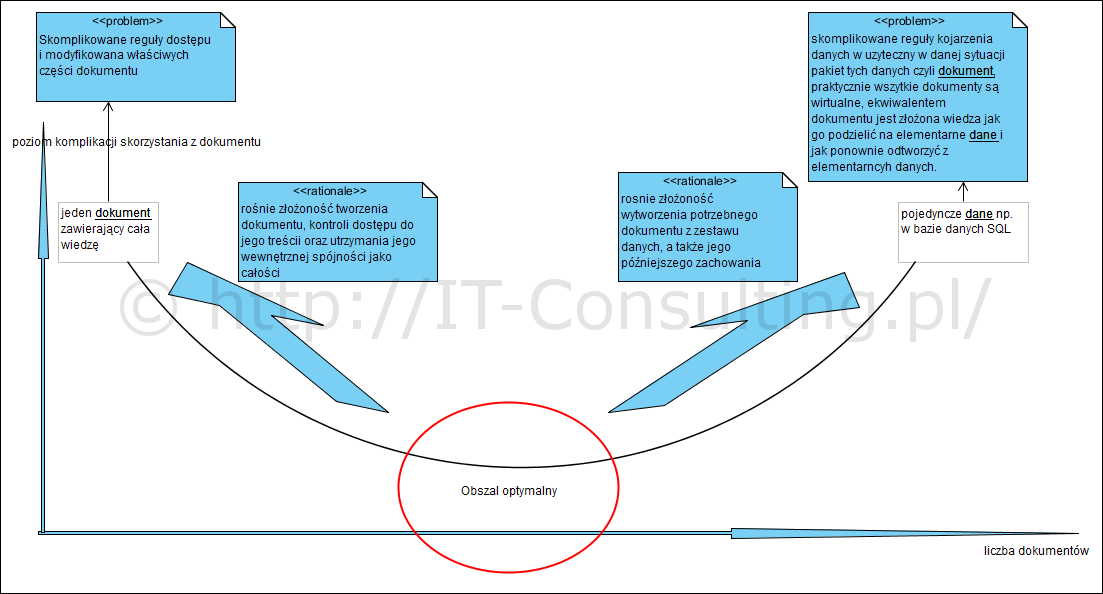
Tak więc skrajnym rozwiązaniem będzie stworzenie jednego dokumentu, na którym będą wszystkie informacje np. związane z danym zamówieniem. Drugą skrajnością jest podzielenie informacji na odrębne małe niepodzielne już grupki, jak to ma miejsce w znormalizowanych relacyjnych bazach danych. Jeżeli megadokumenty to raczej bardzo rzadkie zjawisko, to przypadek drugi jest dość powszechny. To co nazywamy często dokumentem to tu tak na prawdę nieistniejący byt w relacyjnej bazie danych, generowany ad-hoc “w locie” z szeregu rozdrobnionych tablic danych. Innymi słowy nie są to “stałe struktury” a pewna określona złożona logika, tworząca z prostych danych pobieranych z tablic, konkretne zestawy informacji np. faktury (to dlatego często w “języku dostawcy” faktura to raport a nie dokument!). Ta złożona logika realizowana jest (wykonywana w pamięci komputera) za każdym razem gdy odwołamy się do takiego dokumentu.
Optymalna sytuacja to rodzaj kompromisu pomiędzy złożonością logiki tworzenia i korzystania z dokumentu a jego zawartością. Na powyższym diagramie jest to obszar stanowiący okolice minimum krzywej opisującej zależność pomiędzy liczbą dokumentów a złożonością operowania nimi. Nie ma prostej reguły na opracowywanie i optymalizacje treści i liczby dokumentów jednak są pewne sprawdzone dobre praktyki, a mianowicie jeden dokument, o określonej strukturze, powinien zawierać dane o określonym zdarzeniu w określonym kontekście [powstaje teraz publikacja na ten temat, wydaje się można to jednak zdefiniować, przyp autora 2019]. Dokumenty te, podobnie jak fakty które dokumentują, mogą mieć każdy własny i różny od innych cykl życia, dlatego często bywa bardzo szkodliwe “rozdzielanie” ich na pola bazy danych i pozbycie się redundancji.
Przykładem mogą być: zamówienie jako udokumentowanie faktu zawarcia umowy na dostawę, faktura jako udokumentowanie faktu sprzedaży (przeniesienia własności) oraz dokument WZ dokumentujący fakt wydania z magazynu określonych produktów. Bardzo często specyfikacja tego co wydano z magazynu nie jest tożsama z treścią faktury (sprzedano odkurzacz a wydano odkurzacz i zapasowe worki), na zamówieniu mógł być wyszczególniony odkurzacz, worki oraz wymagane końcówki (które są np. u producenta pakowane w standardzie więc nie ma ich ani na fakturze ani na WZ). Dlatego ma głęboki sens by te dokumenty były jednak “osobnymi dokumentami” a nie zachowywanymi w bazie danych danymi jako odrębne pola pozbawione redundancji, wymagające skomplikowanej logiki (polecenia SQL) by je (te “dokumenty”) pokazać na ekranie czy wydrukować.
To dość trywialny przykład, bo opisane dokumenty są wymagane przepisami jako dowody księgowe, jednak każda większa organizacja ma swoje wewnętrzne dokumenty, na których ilość i treść ma pełny wpływ. Po drugie nawet te dokumenty są często właśnie zapisywane w relacyjnych bazach danych jako rozproszone po małych tabelach dane, wymagające skomplikowanych operacji łączenia w jeden “dokument”, każdorazowo przy próbie jego użycia. Tu zachodzi bardzo duże ryzyko, że postać i treść takiego dokumentu ulegnie zmianie np. po reorganizacji bazy danych. Takich “dokumentów” nie da się (w tej postaci) podpisać elektronicznie, bo one po protu fizycznie na prawdę nie istnieją.
A jak inaczej? Nie ma żadnego problemu by dowolny dokument stanowił sobą jednolity byt np. zestaw danych w formacie XML, skojarzony ewentualnie ze swoją postacią gotową do druku albo np. plik PDF skojarzony z metadanymi opisującymi go (wybór jest na prawdę duży). Nie należy zapominać, że poza dokumentami, które są tworzone w organizacji operujemy dokumentami obcymi, otrzymanymi z zewnątrz i wypadało by mieć taki dokument w postaci takiej jaką przesłał nam ich twórca. Owszem pojawia się redundancja danych ale ona nie stanowi sobą nic złego. Ogromną korzyścią takiego podejścia jest rozwiązanie problemu polegającego na niemożności rozdzielenia “dokumentów” i logiki operowania nimi jeżeli są zapisane w postaci odrębnych pól w relacyjnej bazie danych. Np. staje się niemożliwe pozostawienie faktur i wyniesienie dokumentów magazynowych do odrębnego systemu (w tym zmiana ich struktury) co ma miejsce nie raz przy wdrażaniu systemów WMS (systemy logistyczno-magazynowe). Takie operacji prawie żaden duży zintegrowany ERP nie wytrzyma (usłyszymy raczej, że “my dostosujemy do Państwa potrzeb nas moduł magazynowy…).
Podejście takie ma także inna ciekawą zaletę: jeżeli udokumentujemy osobno struktury dokumentów i logikę operowania nimi (także ich tworzenia), to otrzymamy obiektowy model organizacji: model pokazujący wzajemną współpracę obiektów biznesowych (dokumentów) odpowiedzialnych za przechowywanie informacji, obiektów odpowiedzialnych za rejestrowanie tych informacji, obiektów mających wiedzę jak operować tymi informacjami, obiektów udostępniających to wszystko zgodnie z określoną logiką. Poniżej obiektowy model na którym od prawej mamy: dokumenty z ich treścią oraz logikę ich tworzenia i udostępniania (repozytoria czyli kuwetki na dokumenty), logikę korzystania z informacji w repozytoriach, także ich wzajemnego kojarzenia (samodzielne usługi) oraz logikę dostępu do tego systemu (realizacja scenariuszy przypadków użycia). Jeżeli w toku analizy uznamy, że jakieś elementy tej logiki to zadania poddające się w 100% algorytmizacji, to poniższy model jest jednocześnie modelem logiki aplikacji i nazywamy go Modelem Dziedziny Systemu. Nie jest to absolutnie żadna baza danych, poniższe repozytoria niczego nie współdzielą (można je w dowolnym momencie zamieniać na inne bez konsekwencji dla reszty systemu).
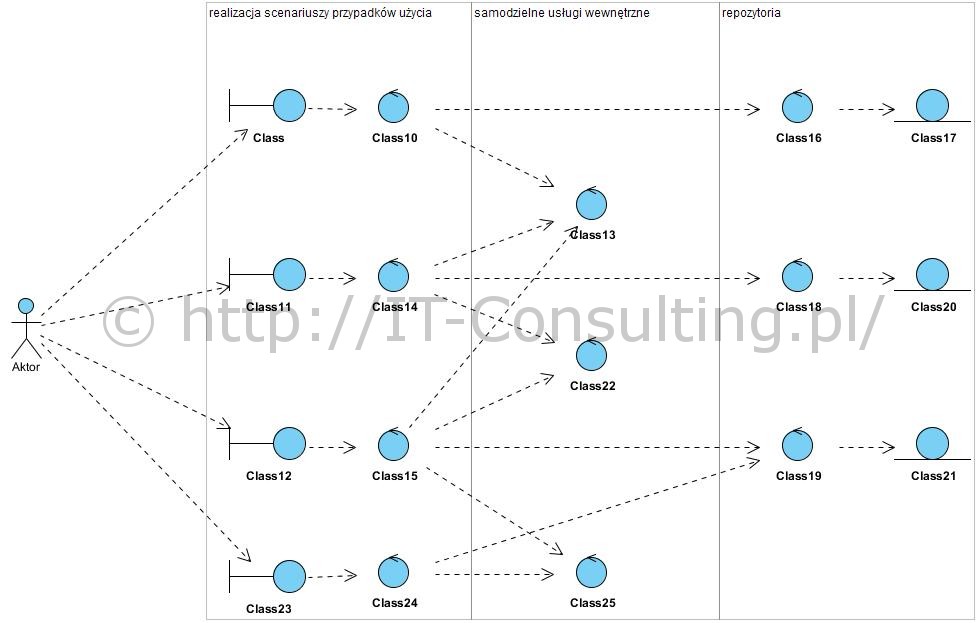
Model ten powstał z użyciem bloków funkcjonalnych wzorca BCE (opisałem go tu: Wzorzec analityczny Boundary Control Entity). Dla wyjaśnienia: powyższy diagram to w pełni poprawny Model dziedziny wykonany z użyciem diagramu klas UML, klasy mają stereotypy boundary, control i entity (powyżej od lewej do prawej), stereotypy te są reprezentowane symbolami opisanymi (ikonami) w BCE. (Źródło: Krzywe i koszty? architektury | | Jarosław Żeliński IT-Consulting)
Podsumowanie
Prawie zawsze obserwuję, że podstawowym domyślnym założeniem wdrożeń systemów wspomagających zarządzanie, jest uznanie a priori niezmienności struktury i wzorów dokumentów.
Z doświadczenia mogę powiedzieć, że analiza i optymalizacja treści dokumentów wewnętrznych może przynieść bardzo duże korzyści przekładające się na duży wzrost wewnętrznej efektywności i jakości pracy, a w przypadku wdrożeń oprogramowania wspomagającego zarządzanie, pozwala nie raz całkowicie uniknąć bardzo kosztownych i ryzykownych kastomizacji. Zaryzykuje tezę, że kilka projektów w ten sposób wręcz uratowałem…
Przypominam, że systemy ERP inne o podobnej architekturze, nie przechowują dokumentów, bo dynamicznie generowane treści (raporty SQL, i podobne generowane “w locie” na API) to w świetle prawa nie są dokumenty, i słusznie bo nie istnieją w czasie.
Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego nośnika, jeżeli tego rodzaju strona internetowa nie spełnia cech trwałego nośnika. (https://uokik.gov.pl/zwrot-i-rekompensata-od-mpay-i-revolut-bank-uab)