Wstęp
Tym razem o kilku powszechnie popełnianych błędach w korzystaniu z UML. Chodzi o pojęcia abstrakcji, metamodeli i zależności oraz o związki między elementami na diagramach. Kluczową, moim zdaniem, przyczyną tworzenia “złych” modeli obiektowych jest używanie notacji UML do tworzenia modeli strukturalnych, nie mających z obiektowym paradygmatem nic wspólnego. Druga to niezrozumienie pojęcia paradygmatu obiektowego. Ogromna ilość diagramów wykonanych z użyciem symboli notacji UML, z UML i paradygmatem obiektowym ma niewiele wspólnego.
Najpierw kilka definicji i pojęć.
Paradygmat programowania (ang. programming paradigm) ? wzorzec programowania komputerów przedkładany w danym okresie rozwoju informatyki ponad inne lub ceniony w pewnych okolicznościach lub zastosowaniach. (Źródło: Paradygmat programowania ? Wikipedia, wolna encyklopedia)
No to teraz obiektowy paradygmat:
Programowanie obiektowe (ang. object-oriented programming) ? paradygmat programowania, w którym programy definiuje się za pomocą obiektów ? elementów łączących stan (czyli dane, nazywane najczęściej polami) i zachowanie (czyli procedury, tu: metody). Obiektowy program komputerowy wyrażony jest jako zbiór takich obiektów, komunikujących się pomiędzy sobą w celu wykonywania zadań. Podejście to różni się od tradycyjnego programowania proceduralnego, gdzie dane i procedury nie są ze sobą bezpośrednio związane. (Źródło: Programowanie obiektowe ? Wikipedia, wolna encyklopedia)
albo:
Programowanie obiektowe lub inaczej programowanie zorientowane obiektowo (ang. object-oriented programing, OOP) to paradygmat programowania przy pomocy obiektów posiadających swoje właściwości jak pola (dane, informacje o obiekcie) oraz metody (zachowanie, działania jakie wykonuje obiekt). Programowanie obiektowe polega na definiowaniu obiektów oraz wywoływaniu ich metod, tak aby współdziałały wzajemnie ze sobą. (Źródło: Programowanie obiektowe ? Encyklopedia Zarządzania)
Słownik języka polskiego mówi:
współdziałać
1. ?działać wspólnie z kimś?
2. ?przyczyniać się do czegoś razem z innymi czynnikami?
3. ?o mechanizmach, narządach itp.: funkcjonować w powiązaniu z innymi?wywołać ? wywoływać
1. ?wołaniem skłonić kogoś do wyjścia skądś?
2. ?przypomnieć sobie lub innym coś?
3. ?spowodować coś lub stać się przyczyną czegoś?
4. ?oznajmić coś publicznie?
5. ?oddziałać na kliszę, błonę lub papier fotograficzny środkami chemicznymi w celu uwidocznienia obrazu utajonego na materiale światłoczułym?
Tak więc stwierdzenie, że “obiekty z sobą współdziałają” oznacza, że “wywołują się” wzajemnie w celu spowodowania czegoś konkretnego. Innymi słowy obiekty tworzące program (system) są od siebie wzajemnie uzależnione. Dlatego podstawowym związkiem w procesie analizy i projektowania zorientowanego obiektowo jest wzajemna “zależność”, nazywana w oryginalnej specyfikacji UML związkiem “usługodawca-usługobiorca”.
Zależności
Związek ten należy utożsamiać z każdą wzajemną zależnością. Z uwagi na to, że mamy wiele typów zależności, wskazujemy konkretny typ z pomocą stereotypu (<<[nazwa_typu]>>).
Najczęściej występujący typ zależności to związek użycia. Oznacza on, że jeden obiekt wywołuje umiejętności (operacje) innego czyli “używa go” do realizacja swojego zadania. Związek taki oznaczany stereotypem <<use>>:
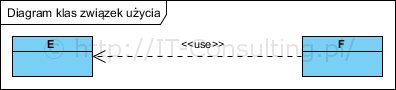
F używa (jest zależny od) E (co do zasady tu F nie jest samodzielny “w tym co robi”).
Formą zależności jest także dość rzadko wykorzystywana abstrakcja (<<Abstraction>>). Związek ten jest wykorzystywany do łączenia dwóch pojęć, z których jedno jest abstrakcją drugiego. Inna często wykorzystywana zależność to <<instanceOf>> oznacza zależność modelu (obiektu) od jego metamodelu (klasyfikatora) a także od metametamodelu.
Tak więc model oprogramowania w notacji UML z użyciem obiektowego paradygmatu powinien wyglądać mniej więcej tak:

Na diagramie użyto symboli klas (graficzna reprezentacja stereotypów) zaczerpniętych wzorca architektonicznego BCE.
Realizacja i kompozycja
Dokumentowanie detali struktury elementów np. repozytorium, wymaga stworzenia kolejnego diagramu: modelu struktury obiektów reprezentujących np. złożoną strukturę obiektu niosącego informacje (np. z formularza).

Korzystamy tu ze związku realizacja i związku kompozycja. Realizacja to związek pomiędzy specyfikacją a jej realizacją (projektem, implementacją, itp.), wskazuje zależność implementacji od jej modelu. C2 jest specyfikacją (opisem, dokumentacją) realizacji D2. Najczęściej związek ten jest stosowany pomiędzy specyfikacją interfejsu a jego implementacją a także generalnie pomiędzy abstrakcją a jej realizacją. Typowym przykładem użycia tego związku jest np. pokazanie na jednym diagramie abstrakcji bytu w repozytorium i realizacji jej struktury:
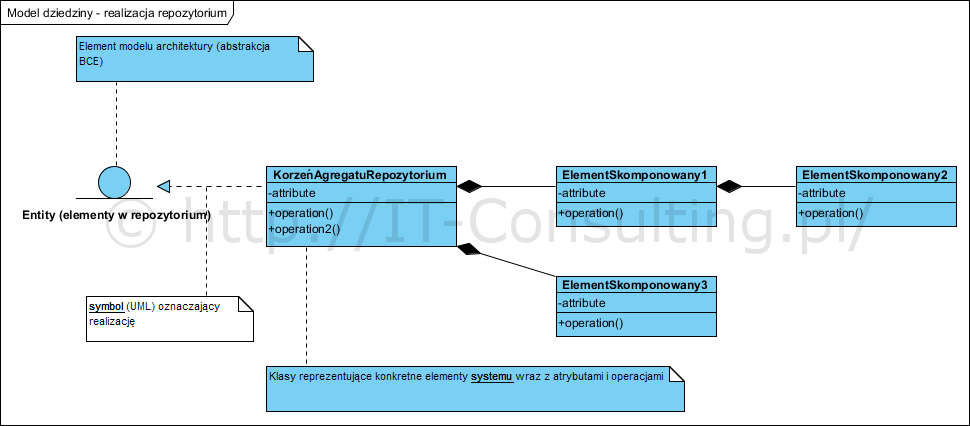
Na diagramie użyto także związku “całość-część”: linia zakończona wypełnionym rombem na jednym końcu. Romb wskazuje na “całość”: element nadrzędny drzewiastej struktury konstrukcji. Jest to specjalny związek oznaczający trwałe (konstrukcyjne) powiązanie pomiędzy detalami składającymi się na określoną całość. UWAGA! Nie ma on nic wspólnego z pojęciem “relacji” znanym z teorii relacyjnych baz danych!
Z uwagi na to, że związek kompozycji stosowany jest do “rzeczy materialnych” (np. odwzorowywanie powyższego w postaci struktury klas w kodzie, OOP, pokazanie struktury materialnych konstrukcji, np. samochodu), na modelach oprogramowania, do modelowania struktury formularzy i komunikatów (dane) stosujemy związek zawierania (ang. member w oryg. UML):
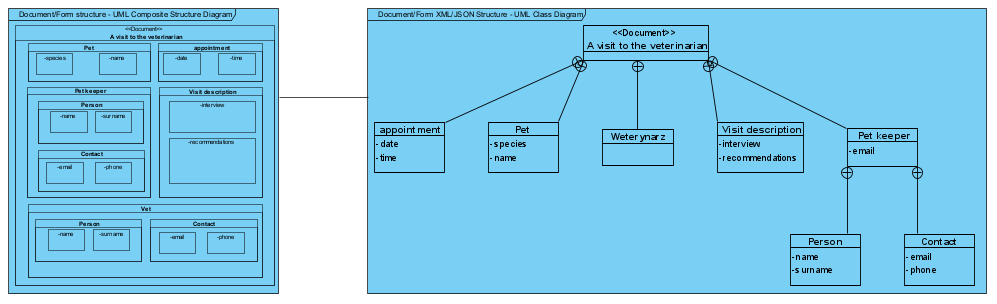
Generalizacja i asocjacja
Oprócz modeli struktur, powstają często modele pojęciowe. Są to odrębne diagramy. Ich celem jest dokumentowanie związków semantycznych i syntaktycznych pomiędzy kluczowymi pojęciami wykorzystywanymi w projekcie. Stanowią one nazwy obiektów i ich typy (atrybuty klas to także obiekty). Wykorzystywane są tu dwa rodzaje związków: generalizacja i asocjacja. Są to związki reprezentujące WYŁĄCZNIE logiczne powiązania pomiędzy pojęciami, nie modelują one struktur a ni implementacji!
Jeżeli jakieś pojęcie ma swoje specjalizowane typy, lub z drugiej strony, grupa pojęć daje się uogólnić innym nadrzędnym pojęciem (generalizowanie), stosujemy związek generalizacji. Związek ten (korzystanie z niego) ma sens tylko gdy liczba typów to co najmniej dwa, co do zasady związek generalizacji służy do grupowania. Jeżeli pomiędzy pojęciami istnieje związek wynikający z dziedziny problemu (np. związek pomiędzy zwierzęciem a karmą dla niego) modelujemy go linią ciągłą łączącą powiązane tak pojęcia. Poniżej graficzny przykład użycia tych związków:
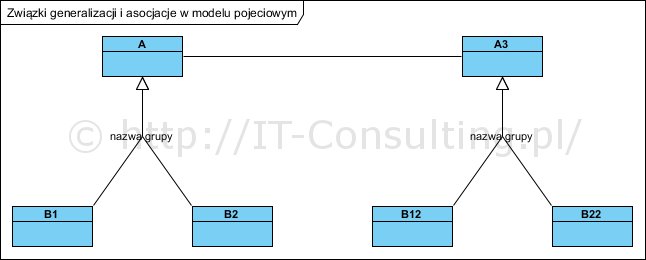
B1 i B2 to konkretne typy pojęcia A (typem jest także pojęcie). Analogicznie B12 i B22 to typy pojęcia A3. Pomiędzy pojęciami A i A3 istnieje związek logiczny (można go nazwać, wpisując te nazwę na linii). Typy mogą mieć więcej niż jeden kontekst dlatego mogą zostać pogrupowane a każda grupa otrzymuje nazwę “nazwa grupy” (oryg. Generalization Sets). Nie ma sensu związek generalizacji pomiędzy tylko jedną parą pojęć, bo oznacza wtedy po prostu tożsamość. Np. pojęcie “województwo” w Polsce ma obecnie szesnaście specjalizacji, mają one swoje nazwy, i to jest jedna grupa typów. Jednak województwa można podzielić także np. ze względu na wielkość na np. trzy grupy: małe województwo, średnie województwo i duże województwo, i to będzie druga i niezależna grupa typów.
Modele…
Wszystkie powyższe przykłady to diagramy klas notacji UML, jednak jak widać każdy ma zupełnie inne przeznaczenie (jest modelem czego innego). Nie omawiałem tu zupełnie diagramów klas modelujących kod programów. Zaznaczę jedynie, że są to kolejne modele dokumentowane z użyciem diagramów klas notacji UML, i omówione powyżej związki dziedziczenia i asocjacje na modelach pojęciowych mają tam zupełnie inne znaczenie.
Modele mogą być różne i dotyczyć różnych rzeczy (patrz Modele….). Tu chcę zwrócić uwagę na bardzo ważny aspekt: abstrakcyjne i rzeczywiste pojęcia w modelach (na diagramach). Dostrzegam ogromny bałagan nie tylko w dokumentach projektowych ale także i w literaturze, gdzie autorzy pokazują wiele różnych przykładów, które niestety są złe i pozbawione uzasadnienia.
Przede wszystkim modele dzielimy, jak już wspomniałem, na pojęciowe i te modelujące jakąś określoną rzeczywistość. Modele pojęciowe to modele pokazujące pojęcia oraz semantyczne i syntaktyczne związki miedzy nimi. Modele pojęciowe służą do udokumentowania dziedzinowej taksonomii co z jednej strony pozwala utrzymać pełną jednoznaczność dokumentacji a z drugiej, na etapie implementacji, pozwala podejmować decyzje o typach danych. Służą one np. do budowania słowników i etykietowania np. pól formularzy (pole Nazwa województwa, którego zawartość będzie wybierana ze słownika zawierającego szesnaście nazw). Na tych modelach pojawiają się w zasadzie wyłącznie pojęcia stanowiące abstrakcje i typy, nie są to modele żadnego kodu, dziedziny itp. Tu przypomnę, że model dziedziny systemu to model opisujący mechanizm jego (systemu, aplikacji) działania, reprezentowany jest przez literkę M we wzorcu MVC, poważnym błędem jest uznawanie tych modeli za modele danych.
Modele struktury to modele opisujące określone “konstrukcje”, głównie na dwóch poziomach abstrakcji: jako model i jako metamodel. Z reguły, w projektach związanych z oprogramowaniem, ta konstrukcja to właśnie Model Dziedziny czyli mechanizm działania, tak zwana logika biznesowa/dziedzinowa aplikacji.
Podsumowanie
Tak więc nie ma czegoś takiego jak “diagram klas dla projektu”. Mamy dla danego projektu: model pojęciowy, modele logiki systemu, modele struktury obiektów, modele implementacji. To wszystko są diagramy klas ale każdy z nich do model “czegoś innego”. Paradygmat obiektowy jasno mówi: obiekty współpracują, więc standardowym związkiem w modelach logiki działania są związki użycia a nie asocjacje ani związki dziedziczenia czy kompozycji. Diagramy te nie są żadnymi modelami danych między innymi dlatego, że z zasady paradygmat obiektowy ukrywa je (hermetyzacja), “na zewnątrz” dostępne są wyłącznie publiczne operacje obiektów. Utrwalanie obiektów (zapis wartości atrybutów np. w bazie danych) to zadanie do rozwiązania dopiero na etapie implementacji, polegające na zagwarantowaniu “zachowania” stanów obiektów na czas wyłączenia zasilania, by nie “uleciały” z pamięci komputera, który jest środowiskiem wykonania programu. Na etapie analizy obiektowej i modelowania logiki systemu nie modelujemy żadnych danych.
Poniższy przykład, jakich wiele w sieci, jest wzorcowym antyprzykładem.
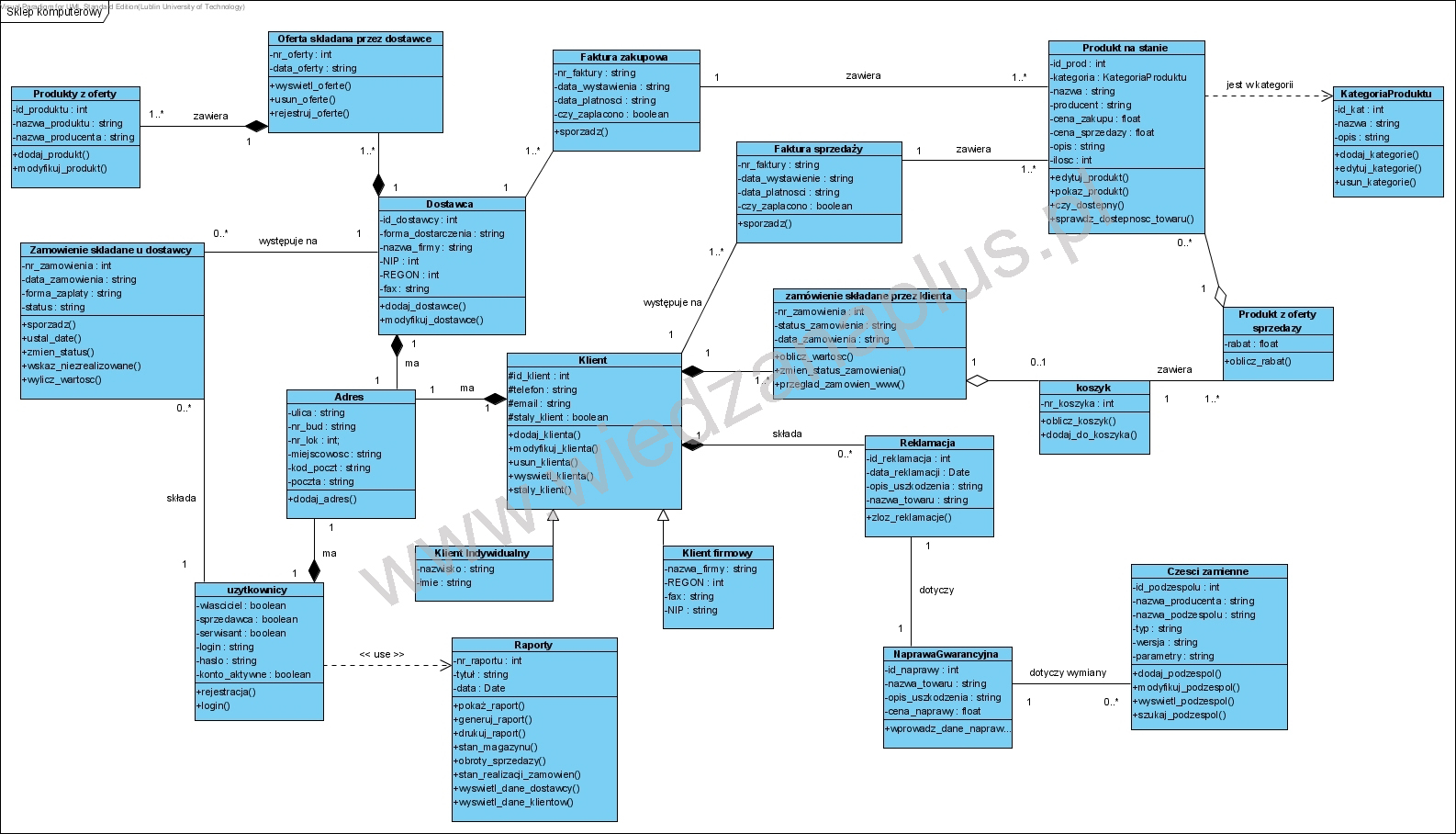
Pierwsza zła cecha tego diagramu to częsty błąd nazywany popularnie “przeciążaniem obiektów”: tu obiekt Faktura ma operacje “sporządź”. Klasyczny błąd architektoniczny polegający na obciążaniu obiektu cudzą odpowiedzialnością. Jeżeli klasa Faktura reprezentuje np. faktury sprzedaży, to system mający w pamięci kolekcję setek faktur i każda z kodem (ma te operację) służącym do jej sporządzenia byłby masakrą zajętości pamięci. Dodam, że model taki nie ma nic wspólnego z rzeczywistością, bo faktury wystawia “ktoś” a nie “faktura”. Trzecia rzecz: faktura zakupu i faktura sprzedaży to niczym nie różniące się struktury, więc tworzenie takiego rozróżnienia jest pozbawione sensu. To błędy pojęciowe i ten diagram ma masę takich błędów. Druga wada: błędne użycie związku kompozycji: powyższy diagram należałoby interpretować jako strukturę o jednej zwartej konstrukcji, np. takiej jak samochód składający się z setek podzespołów ale stanowiący jednak jedną całość. Brak modelu pojęciowego i słownika powoduje wiele niejednoznaczności. Np. związek pomiędzy Klientem a reklamacją wskazuje, że Reklamacje są integralną częścią Klienta (tak jak koła i silnik są integralną częścią samochodu) co nawet w świetle potocznego rozumienia tych słów kłóci się ze zdrowym rozsądkiem.
Użycie związków pojęciowych (asocjacja) jest zupełnie niezrozumiałe w tym przypadku. Nazwa asocjacji “zawiera” nie ma kierunku a więc nie wiadomo co jest zawarte w czym. Związki zależności także są niejasne: jak interpretować np. zapis mówiący, ze obiekty klasy użytkownicy zależą od obiektów klasy Raporty? Jeżeli autor miał na myśli “użytkownik używa raportów” to popłynął w sferę “mowy potocznej”, to chyba najczęściej spotykany błąd polegający na tym, że autor diagramu nadal pisze specyfikację prozą, ale z użyciem symboli (tu UML) zamiast słów.
Mogę się jedynie domyślać, że autor diagramu “miał w głowie” model relacyjny związków encji i użył ikon z notacji UML w całkowicie innych znaczeniach niż ta notacja definiuje. Takie diagramy nie powinny powstawać, są one niestety dowodem na to, że programiści mówiący “te dokumenty z UML nic nie wyjaśniają i są nieprecyzyjne, i tak musimy sami powtórzyć te analizę” mają rację. Są także dowodem, że są to jednak projekty strukturalne a nie obiektowe, a użycie notacji UML polegało na skorzystaniu z zestawu ikon tak się to robi tworząc niesformalizowane schematy blokowe z użyciem np. programów do tworzenia prezentacji takich jak PowerPoint. Zapewne poza autorem tego diagram, nikt nie ma pojęcia o co w nim chodzi…. Jeżeli autor miał na celu udokumentowanie “modelu danych” to powinien użyć notacji ERD. A tak to mamy schemat blokowy, w którym ktoś użył UML jako biblioteki symboli wprowadzając czytelnika w błąd.
Z przykrością muszę przyznać, że od takich błędów nie są wolne także niektóre podręczniki i materiały szkoleniowe… a także dokumenty tworzone przez pracowników wielu firm na rynku IT.
P.S.
Na przykłady poprawnych diagramów z uzasadnieniem zapraszam do mojej książki i na moje szkolenia i warsztaty.
Specyfikacja UML v.2.5
Niestety “sprawne” korzystanie z takich specyfikacji wymaga umiejętności czytania modeli pojęciowych (diagramów klas UML) opisujacych syntaktykę (syntax) jak wyżej (ich tworzenie też do łatwych nie należy…). Przytaczam to jako źródło tego o czym tu pisałem.
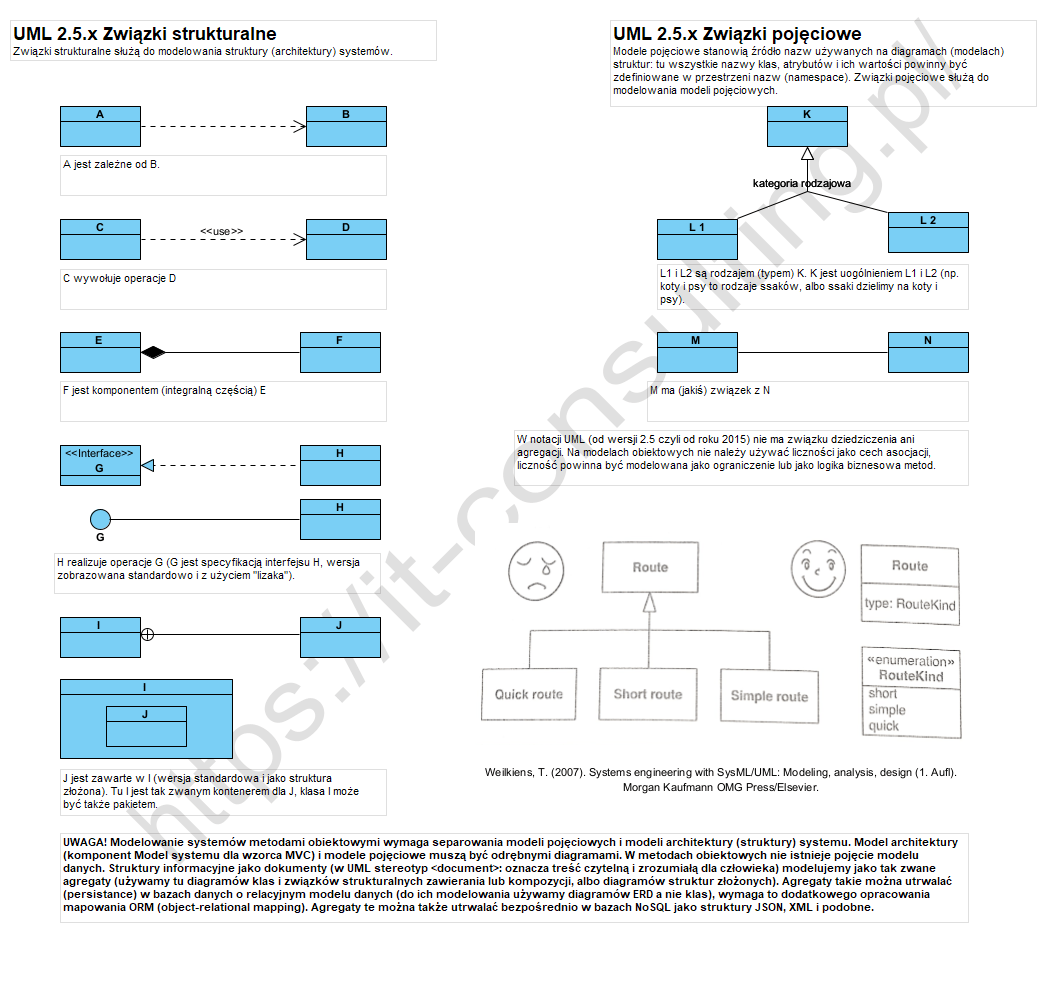
W UML “wszystko jest klasą”, związki między elementami diagramów także. Zostało to pokazane w specyfikacji UML v.2.5.:
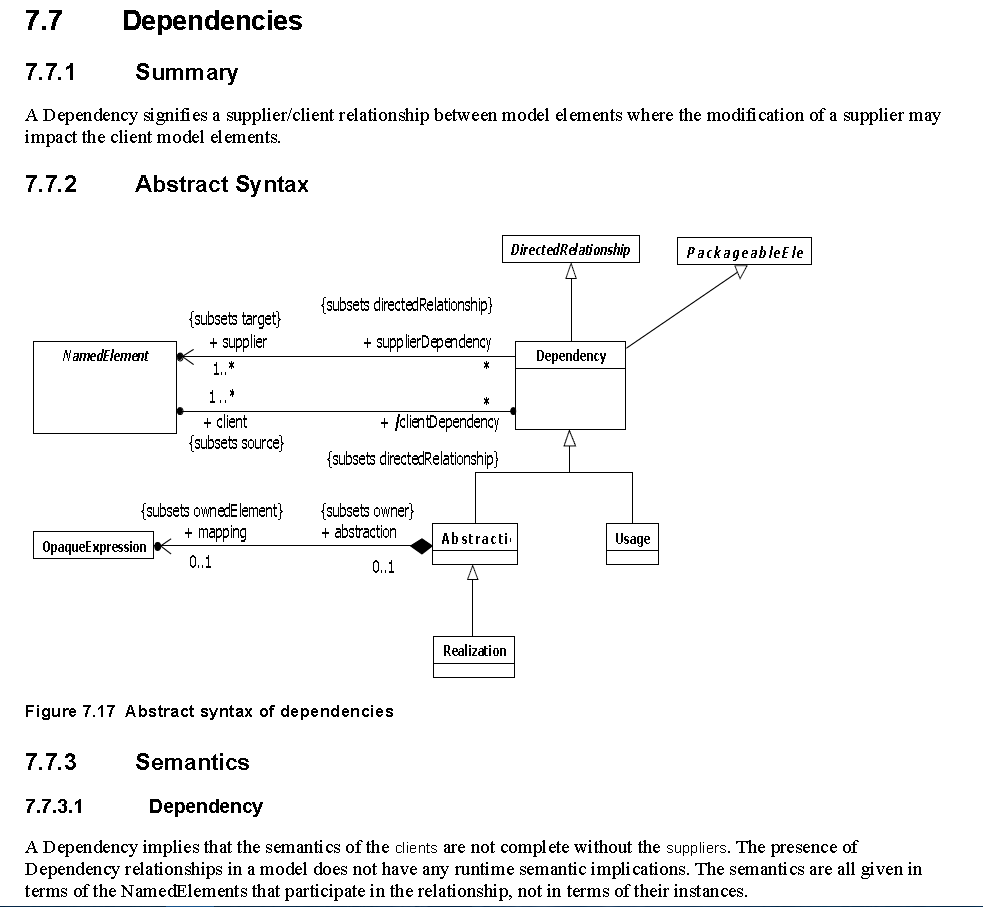
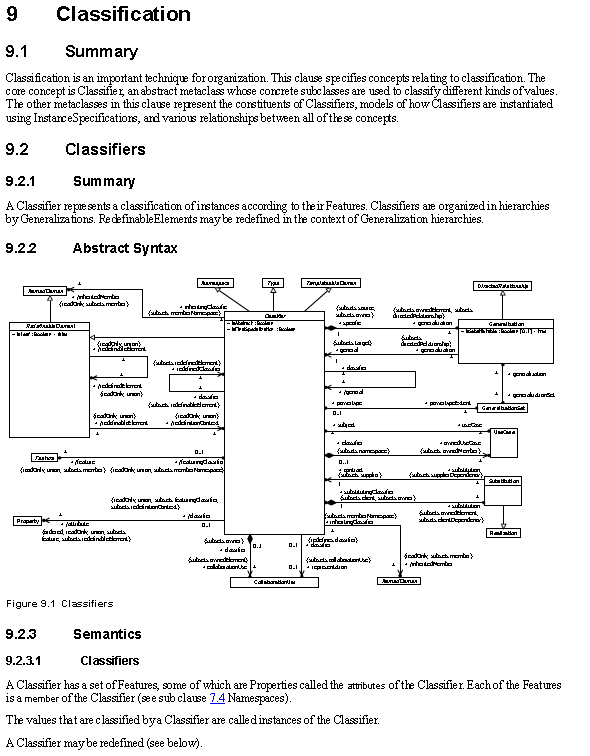
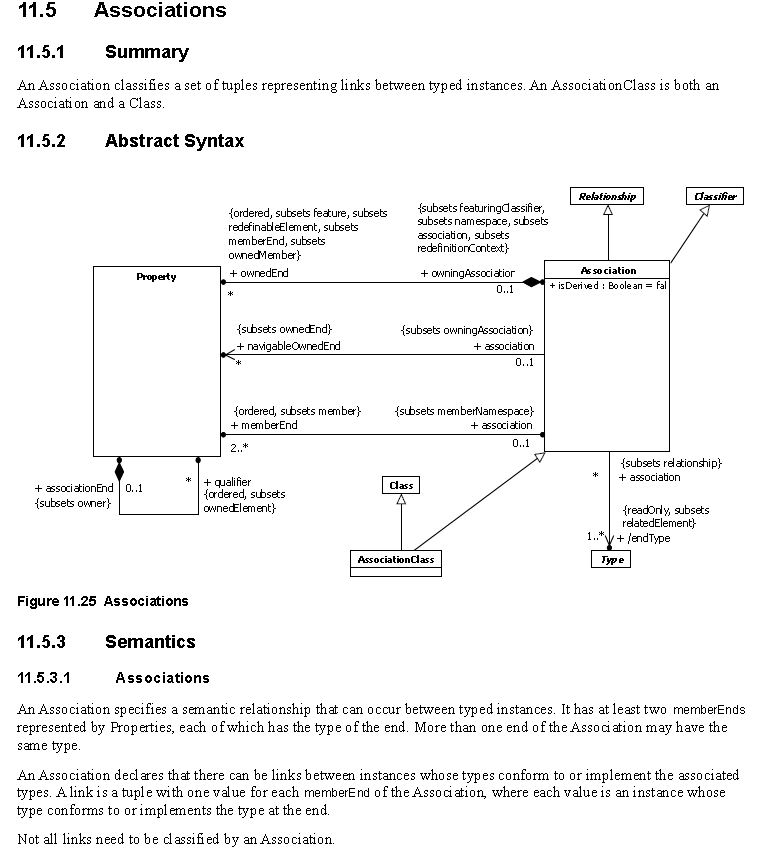
W UML 2.5 praktycznie znika w końcu dziedziczenie i agregacja. Uff… poniżej podsumowanie na jednym diagramie.
Dodatek [2022-07-22]
…chciałbym zapytać o dziedziczenie w UML. Brałem ostatnio udział w kilku rozmowach o pracę. Moi rozmówcy często utrzymują, że w UML jest to dziedziczenie. Mało tego, wykorzystują to dziedziczenie na diagramach klas, w czymś co nazywają modelem dziedziny (oczywiście bez operacji klas). Zajrzałem do specyfikacji UML i jestem trochę zdezorientowany, ponieważ pojęcie dziedziczenie dość często występuje w tej dokumentacji, choćby w tym fragmencie.

W jakim znaczeniu jest tu użyte pojęcie dziedziczenia? Czy jest gdzieś w specyfikacji wprost informacja o usunięciu dziedziczenia z UMLa?
Porównując ze specyfikacją 2.4. nie ma, pojęcie dziedziczenia nadal jest obecne w językach programowania, a w specyfikacji 2.5.xx słowo “inheritance” pojawia sie tylko 4 razy, i dotyczy wyłącznie komentarzy związanych z uogólnieniami.
Cytowany związek Generalizacji jest związkiem pojęciowym a nie strukturalnym czegoś istniejącego (struktura modelowanego systemu). Formalnie w UML mamy związek Generalizacji, i jest to związek pojęciowy, ale nie ma w UML rozdziału “Dziedziczenie”. Inherit w j. angielskim to także “przejęcie cech po czymś” czyli związek generalizowania i specjalizowania. Generalziacja, jako związek ogólny-szczególny, pokazuje że szczególny przypadek, pojęcie i jego definicja, ma wszystkie cechy przypadku ogólniejszego, więc pies jako szczególny typ ssaka ma wszystkie cechy ssaka (chodzi o definicje tego czym jest ssak). Czyli:
1. ssak: kręgowiec, którego młode karmią się mlekiem matki,
2. pies: <ssak> który szczeka,
więc:
pies: <kręgowiec, którego młode karmią się mlekiem matki>, który szczeka,
czyli pies (a konkretnie definicja psa) “dziedziczy” po ssaku (definicji ssaka) jego określone cechy, czyli oznacza to, że są one (cechy ssaka) np. dla psa i kota wspólne, a nie że, kot czy pies coś “dziedziczy” po ssaku :).
Dlatego w UML teraz jest napisane, że mamy generalizację jako związek między klasami, ale nigdzie nie ma związku “dziedziczenia” między klasami.
Tekst rozdz. 9.2.3.2. tłumaczymy tak, ze generalizacja oznacza, że generalizowana definicja (cechy czyli atrybuty i zachowania) są wspólne (dziedziczą) dla specjalizowanych elementów. W modelu pojęciowym (namespace) tak to działa. I teraz: model struktury czegokolwiek istniejącego nie ma abstrakcji (a generalizowane pojęcia to abstrakcje, pojęcie ssak to pojęcie abstrakcyjne). Opisując więc traktor jako pojazd czy dokumenty w księgowości jako dokuenty, nie ma nad nimi “uogólnień”, po których dziedziczą (sa to jednak pojęcia słownikowe). Po trawie nie biegają “ssaki” tylko psy, koty, lwy…
Znakomita większość znanych mi ludzi w IT nie odróżnia modelu pojęciowego od modelu struktury systemu, który zbudowany jest (każdy) z realnych elementów. W miejsce “starego” dziedziczenia w UML wprowadzono pojęcia: szablon (template) oraz rola (realnym czymś w samochodzie jest “silnik”, pojęcie “napęd” to nazwa funkcji/roli określonego komponentu, ale nie piszemy: “<silnik> dziedziczy po <napędzie>” tylko “<silnik> pełni rolę <napędu>” tak samo jak nie powiemy “<pies> dziedziczy po <zwierzę domowe>” tylko “<pies> pełni rolę <zwierzęcia domowego>”.
Języki programowania pozwalają na tak zwane re-użycie kodu, czyli wyciąganie pewnych wspólnych cech ponad konkretne komponenty/klasy (abstrakcja) po to by tylko raz pisać kod komponentów mających wspólne cechy. Jednak projektując “model dziedziny” nie ma w niej abstrakcji, mając model dziedziny (mechanizm działania aplikacji) zamieniamy generalizacje i “dziedziczenia” pojęciowe na atrybuty i typy realnych rzeczy, tak to opisano książce o modelowaniu systemów już w 2007 roku:
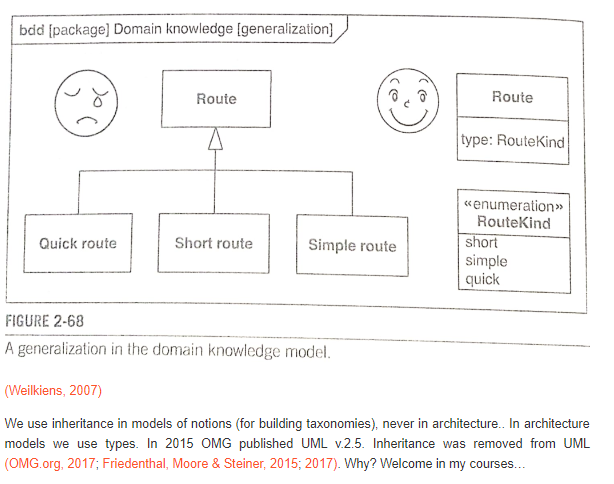
Oczywiście programista może używać gdzie chce dziedziczenia (ma taką możliwość w każdym obiektowym języku programowania) ale to jedna z najgorszych praktyk, bo łamiących kluczową zasadę jaką jest hermetyzacja komponentów (“zakaz” współdzielenia czegokolwiek). To dlatego od wielu lat OOP (Object-oriented Programming, języki i programowanie obiektowe) i OOAD (Object-oriented Analysis and Design) to odrębne “dziedziny”.



Amen.
Ja jestem ze świata programistów ale zawsze bronię analizy i analityków gdy programiści wieszają psy na artefaktach analitycznych twierdząc, że są błędne, mylące i przez to zbędne (lepiej ich nie mieć niż mieć słabe) oraz że oni muszą dokonywać prawdziwej analizy mając na wejściu to co dostali od analityków. Zawsze wtedy pytam czy dokonano rzetelnej analizy czy jedynie dyletanci spisali zeznania userów (nie mających pojęcia o dziedzinie) z łapanki. Gdy robimy pobieżny przegląd artefaktów analitycznych to wychodzą właśnie dokładnie takie kwiatki jak piszesz.
Niestety … Programista w projekcie zawsze będzie inżynierem, bardzo dobrym i rozwiązującym mega problemy implementacyjne, ale domena systemu to zupełnie inna wiedza i inne mechanizmy: nie techniczne… logika biznesowa to zupełnie inna inżynieria..
Bardzo przypadł mi do gustu niniejszy artykuł. Często spotykam się z tego typu (nad)użyciem diagramów UML, które częściej służą jako narzędzie “intelektualnej onanizacji” autora, niż zrozumienia / udokumentowania zagadnienia.
Z przykładem faktury sprzedaży / zakupu nie mogę się do końca zgodzić.
1) Nie jest mi znany współczesny język programowania (co oczywiście nie znaczy, że takowy nie istnieje), który utrzymywałby w pamięci kopię kodu każdej instancji danej klasy. Niestety, nie mogłem znaleźć niczego lepszego niż ten link – http://stackoverflow.com/questions/1298122/where-are-methods-stored-in-memory – możemy chyba roboczo przyjąć, że jeżeli coś jest oznaczone jako odpowiedź na StackOverflow, to jest zgodne z prawdą 🙂
Pomijając ten techniczny aspekt, zgadzam się w zupełności ze stwierdzeniem, iż metoda “utwórz fakturę” nie powinna być zadeklarowana w samej fakturze. Programowanie obiektowe – wbrew przekonaniu wielu programistów – nie polega na tworzeniu setek encji (najlepiej mapowanych 1 do 1 na bazę danych przy pomocy narzędzi ORM) i obarczania ich wszelkimi możliwymi obowiązkami (faktura: utwórz, koryguj i tym podobne potworki); piszę to ku przestrodze, gdyż zdarzyło mi się kilkukrotnie wpaść w tę pułapkę.
2) Co do separacji faktury sprzedaży i zakupu, to nie sądzę, by były one identyczne. Dokument / wydruk lub obraz faktury zakupu i sprzedaży może być identyczny na papierze, jednak jeśli pomyślimy o tym w szerszym kontekście, faktura sprzedaży generowana jest, przykładowo, na podstawie zamówienia sprzedaży, powiązana (nie koniecznie przez bezpośrednią referencję w kodzie, ale jednak) jest z dokumentem wydania magazynowego itp. Wydaje mi się, że w rozwiązaniach typu ERP rozdzielenie tych dwóch bytów jest zupełnie zasadne. W systemie obiegu dokumentów – może być już różnie, w zależności od potrzeb i założeń.
P.S. Śledzę od jakiegoś czasu Twojego bloga – jako osoba raczej związana z kodem niż z analizą – i doskwierała mi zawsze nadreprezentacja anty-przykładów, a brakowało mi przykładów (bardziej życiowych niż gra w szachy ;)) poprawnego podejścia do analizy i dokumentacji. Liczę, że w Twojej książce proporcje będą odwrotne.
Pozdrawiam,
Marcin
1. języki programowania (a konkretnie kompilatory) to narzędzia radzące sobie nie tylko z takimi problemami jak oszczędzanie pamięci, (stack overflow to forum programistów a nie analityków czy projektantów), jednak na etapie analizy nie należy “z góry brać od uwagę” tego co “naprawi” kompilator…
2. ustawa o podatku VAT definiuje tylko jedną fakturę, ten sam (i taki sam) dokument jest fakturą sprzedaży dla sprzedawcy i jednocześnie fakturą zakupu dla nabywcy, próba tworzenia “dwóch” szybko nauczy pokory np. przy próbie wysłania ich do urzędu skarbowego w ramach JPK (one się tam spotkają i MUSZĄ być identyczne), jednym z najgorszych nawyków analityków i projektantów jest uznanie, że faktura powstaje na bazie zamówienia; po pierwsze właściwsze jest stwierdzenie “fakturę wystawiamy NA PODSTAWIE zamówienia” ale dobry system MUSI wytrzymać przypadek testowy: zamówiono dwa produkty w określonych ilościach, w momencie realizacji wystawiono fakturę na nieco inne ilości i dodano trzeci produkt bo klient np. ma więcej pieniędzy, wydano ten towar w dwóch różnych magazynów na dwóch odrębnych dokumentach WZ, Zamówienie jako obcy dokument, nadal musi być identyczne z kopią u zamawiającego…
🙂
Co do książki, to moja piersza, następna będzie lepsza 😉
1. Owszem, to zagadnienia związane z kompilatorami, optymalizacją pamięci itp. Ja tylko odniosłem się do twierdzenia o “masakracji pamięci”, w celu jego sprostowania. Co nie oznacza, że nie zgadzam się z pozostałą częścią Twojego wywodu – patrz mój poprzedni komentarz.
2. Nie jestem analitykiem, nie jestem wyczulony na tego typu niuanse (“wystawiać na podstawie” / “tworzyć na bazie”) – być może mieliśmy to samo na myśli. Co do scenariusza testowego z niezgodnymi ilościami, właśnie dla tego uważam, że często zasadne jest rozdzielanie pojęć faktury zakupu i sprzedaży. Faktura zakupu jest dokumentem obcym, który musi zgadzać się z tym, co otrzymaliśmy od drugiej strony transakcji (przypuszczalnie akceptując drobne “wpadki” w stylu błędów zaokrągleń itp.). Fakturę sprzedaży wystawiamy “my”, na podstawie naszych reguł, “naszego” dokumentu zamówienia itp. To w moim przekonaniu czyni te dokumenty różne. A że wydruki wyglądają identycznie, to fakt, ale oprogramowanie to już nie tylko struktury danych i algorytmy (struktura – faktura, algorytm – wystawienie faktury sprzedaży / wprowadzenie faktury zakupu), prawda? Wątpię również, że poprzez “faktura zakupu” i “faktura sprzedaży” rozumiemy w tym przypadku świstki papieru.
z pamięcią wyjaśnione, co do faktur:
– z praktyki mogę powiedzieć, że każde odstępstwo modelu od “real world” mści się dosyć szybko,
– fakturę obcą łatwo odróżniamy od własnych po tym co jest w treści sekcji “sprzedawca”,
– co do możliwości wprowadzania zmian: dokumenty własne ustawiamy w stan “read only” jak jak tylko zostaną wysłane do klienta, obce od razu…
Bardzo ważna rzecz w modelowaniu: nazwę “dokument” dostaje “konkretna struktura danych” (zresztą zgodnie z ustawą) dlatego najbezpieczniej dla przyszłych zmian, faktury rozróżniamy wyłącznie kontekstem a nie tworzeniem dwóch sztucznych bytów w systemie, takie podejście pozwala zachować zasadę “Open Close Principia”…
Dodałem do podsumowania diagram podsumowujący obecnie (UML v.2.5.x.) stosowane związki na diagramach klas , czyli w ogóle w UML.