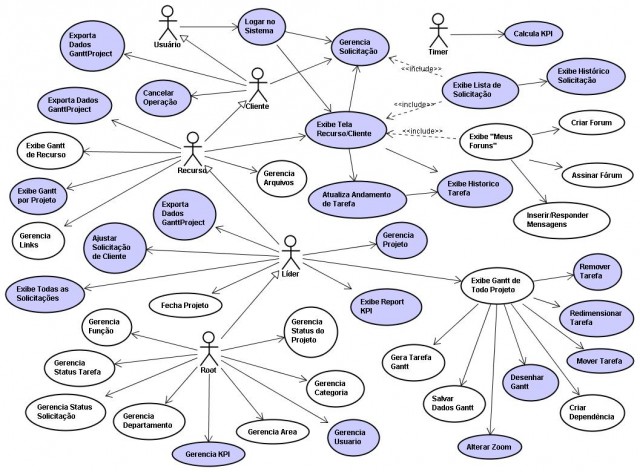
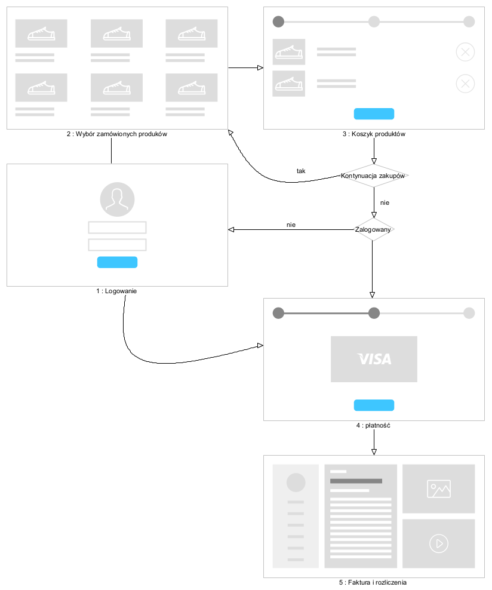
Końcówka roku, wręcz ostatni jego dzień 😉 …
Mając przed oczami kolejny projekt badawczy, kolejny raz gapię się na strony OMG i mała refleksja: porządki dobiegają końca. W artykule o UML v.2.5. wspominałem, że zrezygnowano w końcu z pojęcia “agregacji” (zwanej czasami “słabą kompozycją”), odchodzi się od całkowicie zbędnych związków “extend” i “include” w przypadkach użycia (konstrukcje te nadal pozostają w specyfikacji z uwagi na kompatybilność wstecz narzędzi CASE i dokumentów jakie w nich są nadal tworzone lub archiwizowane). Paradoksalnie specyfikacja UML jest upraszczana (stale tkwi w niej echo pierwotnego zlepku kilku notacji z lat 99-tych). Oczyma wyobraźni widzę jak ktoś, w toku prac nad UML, stale wymachuje “brzytwą Ockhama”…
To oczywiście nie wszystkie porządki. Porządkowana jest także kwestia metamodelowania oraz MDA (Model Driven Architecture). Specyfikacja MOF (Meta Object Facility) to dokument (i idea) opisujący podejście (metodykę) OMG, z którą kompatybilne są notacje z tej “stajni”.
The MetaObject Facility Specification is the foundation of OMG’s industry-standard environment where models can be exported from one application, imported into another, transported across a network, stored in a repository and then retrieved, rendered into different formats (including XMI, OMG’s XML-based standard format for model transmission and storage), transformed, and used to generate application code. (Źródło: OMG’s MetaObject Facility (MOF) Home Page)
Klarują się definicje modeli PIM i PSM, porządkowane są kwestie przenoszalności modeli (standard XMI), dopracowywana jest automatyzacja transformacji modeli. Ta ostatnia, moim zdaniem, nadal długo jeszcze pozostanie w sferze prac akademickich raczej. Nie dlatego, że “to nie działa”, a dlatego, że nakład pracy (liczba wymaganych detali) na stworzenie modelu umożliwiającego taką transformację jest niewspółmiernie duży do korzyści z tej automatyzacji (podobnie ma to miejsce w symulowaniu procesów biznesowych).
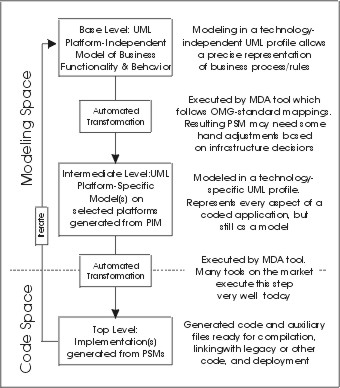
Niewątpliwie jednak uporządkowano kwestie etapów prac: PIM to model domenowy (dziedziny, kontekstowy), opisuje strukturę i zachowanie się określonego systemu, jego usługi. Model PIM to metamodel komponentu Model wzorca MVC. PSM to model stanowiący tak na prawdę model kodu programu (w rozumieniu tego co pisze programista w Java czy .NET itp.). Warto wiedzieć, że tak rozumiany kod to metamodel tego co powstanie w pamięci po uruchomieniu kodu (programista programując deklaruje klasy a nie obiekty). Jak widać liczba poziomów abstrakcji (metamodeli) ma znaczenie.
Poniżej przykład użycia podstawowych poziomów abstrakcji w toku analizy i projektowania:

Z perspektywy osoby popularnie zwanej “analitykiem biznesowym” (coraz bardziej nie znoszę tej nazwy), tworzy ona model systemu, testuje go (przydatność systemu, czyli jak i czy w ogóle, spełnia wymagania) i przekazuje do realizacji (implementacji). Wcześniej powstaje model organizacji aby przetestować tezę: “zrozumieliśmy to jak działa ta organizacja, to jest jej model, nikt go nie sfalsyfikował więc to poprawny model”, i mowa tu o motywacji biznesowej (notacja BMM), modelu procesów biznesowych i nośnikach informacji (notacja BPMN), modelu pojęciowym opisującym nazewnictwo i reguły biznesowe (notacja SBVR). To model CIM. Tu ma teraz miejsce płynne przejście z CIM do PIM (pojawia się kontrakt dokumentowany diagramem przypadków użycia, logika biznesowa i nośniki danych z procesów są modelowane jako struktury UML). Miejsce (rysunek powyżej) oznaczone Automated Transformation to nadal domena ludzi: analityków, projektantów i inżynierów programistów.
Słowo “system” pojawia się regularnie nie tylko na tym blogu, warto wiedzieć (pamiętać), że:
- organizacja (firma, urząd, itp.) to system którego elementami są ludzie i narzędzia jakich używają, w szczególności oprogramowanie,
- oprogramowanie (narzędzia w rękach ludzi pracujących w tych organizacjach) to podsystem tego powyższego systemu (czyli formalnie podsystem).
W toku prac na projektowaniem oprogramowania nie można o tym zapominać. Słownictwo (model pojęciowy) zawsze zawiera kontekst organizacji a nie oprogramowania, jest to konieczne dla zachowania spójności nie tylko nazewnictwa ale i samej dokumentacji a także kodu (mówiąc słowami koderów naming). Poniższy diagram pokazuje te zależności.
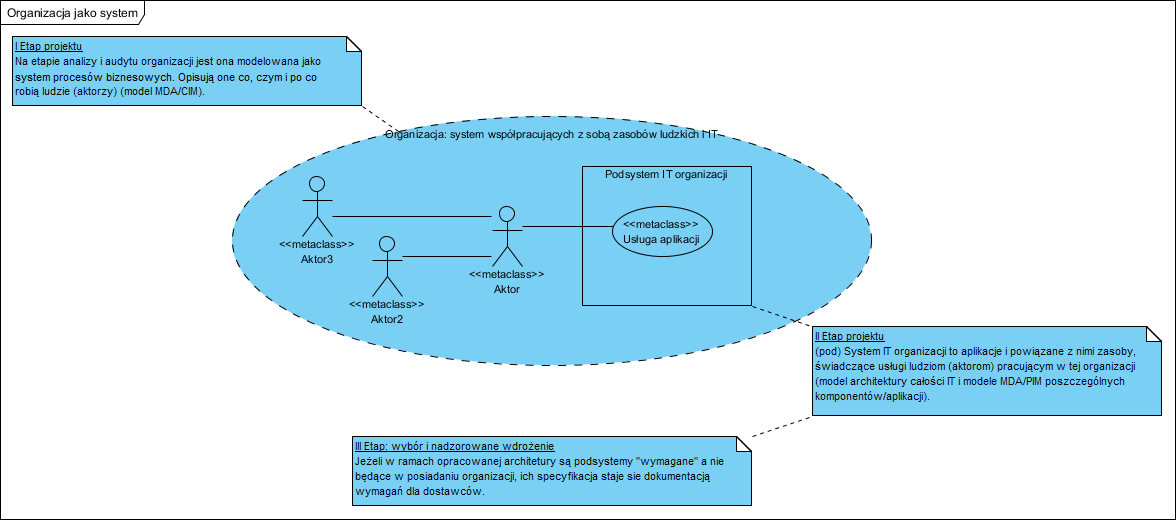
Na tym zakończę dzisiejsze, w sumie sylwestrowe, dywagacje, i zachęcam i analityków, i projektantów, i architektów, i koderów, do poznawania modelowania i stosownych notacji. To tak samo konieczne jak rysunek techniczny w pozostałych działach inżynierii. Dobra informacja: do celów analitycznych wystarczy lektura ok. 20% tych specyfikacji, rozdziały poświęcone transformacjom i przenoszalności to lektura dla akademików i producentów oprogramowania CASE.
Do Siego Roku 🙂