Wprowadzenie
Nadal obserwuję to, że model relacyjny i “tworzenie bazowych modeli danych na etapie analizy wymagań” (kanoniczny model danych) trzymają się twardo mimo tego, że nie wiele wnoszą do projektu a narzucają (sugerują) kiepską architekturę aplikacji z jedną relacyjna bazą danych. Co ciekawe zaczynanie od bazy danych jest wręcz zaprzeczeniem zwinności (konieczność ukończenia projektu docelowej bazy danych przed rozpoczęciem kodowania czyli klasyka waterfall, w efekcie betonowanie stanu z dnia rozpoczęcia) mimo, że autorki artykułu piszą o sobie że są agile…)
Biznesowy model danych czyli co
Popatrzmy na to co proponują w tym 2017 roku.:
Jeśli w systemie istnieją określone reguły biznesowe, które określają maksymalne wartości relacji 0..n lub 1..n, można je uwzględnić w granicach kontekstu. Na przykład, PO dla SeiSounds może chcieć określić, że każde konto może być powiązane tylko z maksymalnie pięcioma użytkownikami lub słuchaczami, aby uniknąć sytuacji, w której znajomi kupują jedną płatną subskrypcję i dzielą się nią ze wszystkimi innymi. Proszę zobaczyć poniższy przykład:

[…]PODSUMOWANIE Diagramy danych biznesowych są jednym z tych modeli, które MUSZĄ BYĆ dla każdego produktu, który ma do czynienia z danymi. Samo ćwiczenie tworzenia modelu tworzy potężne, wspólne zrozumienie podstawowych konstrukcji danych, tak jak rozumieją je użytkownicy. BDD może również pomóc w zidentyfikowaniu dodatkowych, bardziej szczegółowych modeli, które mogą być potrzebne, a także w uzyskaniu pełnego zestawu historii użytkowników dotyczących interakcji użytkowników z danymi po wykonaniu czynności tworzenia, używania, edytowania, usuwania, przenoszenia i kopiowania. (Źródło: Deep Dive Models in Agile Series: Business Data Diagram)
Powyższy model:
- deklaruje konkretną znaną “na teraz”, wartość limitu liczby użytkowników Konta,
- pomiędzy autorem, utworem i stacją jest nic niemówiąca (każde z każdym bez żadnych ograniczeń) zależność,
- pozostałe elementy nie wnoszą wartości dodanej (utwór jest cechą artysty czy może artysta jest cechą utworu…).
Zaryzykuję tezę, że powyższe w zasadzie nie pomaga developerowi w niczym. Czy wnosi coś do projektu? W moich oczach stanowi proste “zapisanie” tego co zeznali indagowani zamawiający (artykuł zawiera opis historyjek użytkownika i ich kojarzenia z tym modelem danych). Stwierdzenie zaś, że “…określone reguły biznesowe w systemie, które ustalają maksymalne wartości dla relacji 0..n lub 1..n…”, (np. maksimum pięcioro użytkowników może jednocześnie słuchać), to nie reguła biznesowa a kryterium decyzyjne (więcej o regułach biznesowych w literaturze).
Trzeba sobie tu jasno powiedzieć, że indukcyjne podejście do analizy (zbieranie i zapisywanie obserwacji w celu identyfikacji trendu lub powtórzeń) przypomina próby zrozumienia gry w szachy metodą wielokrotnej obserwacji rozgrywek. Im wierniejszy opis gry ma powstać, tym więcej obserwacji należy udokumentować, co nie zmienia faktu, że taki dokument nie mówi absolutnie nic o przyszłych rozgrywkach. Alternatywą jest dedukcyjne podejście, polegające na zrozumieniu i opracowaniu, możliwie najmniejszym nakładem pracy, reguł gry w szachy, czego udokumentowanie wymaga najwyżej dwóch stron papieru A4, taki dokument opisuje także w 100% wszystkie przyszłe rozgrywki…
Jak inaczej podejść do tego?
Na początek należy zrozumieć dziedzinę problemu i opisać ją słownikiem:
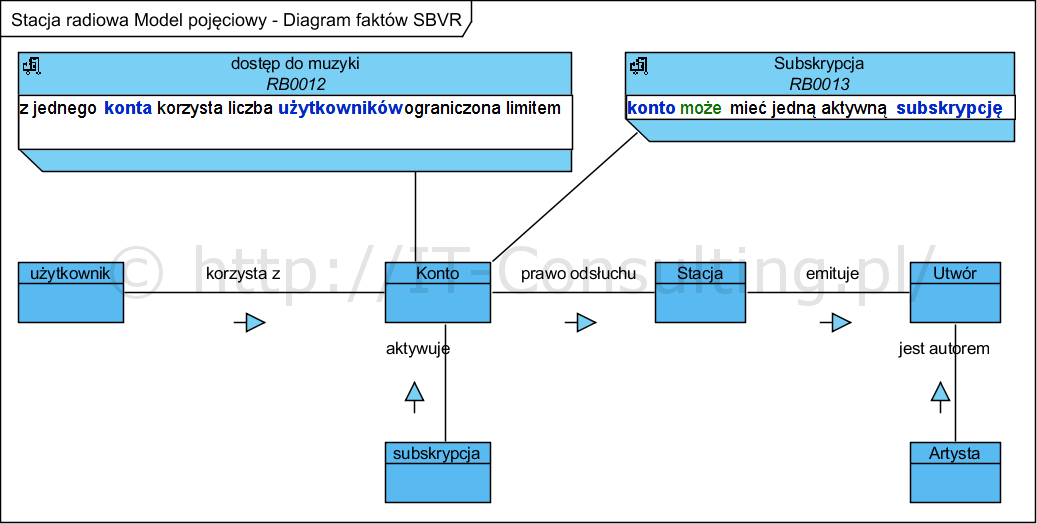
Powyższy model pojęciowy (diagram notacji SBVR, diagram klas notacji UML) to słownik pojęć a nie model danych. To diagram obrazujący pojęcia i kontekstowe związki między nimi (tym kontekstem są fakty z dziedziny analizowanego problemu). Nie są to ani dane ani reguły biznesowe.
Są to graficznie wyrażone zdania, testem tego modelu jest sprawdzenie czy są to zdania prawdziwe w danej dziedzinie, np. “artysta jest autorem utworu”.
Są to pojęcia 9nazwy), a nie “byty systemowe”. Poza takim diagramem, należy także stworzyć słownik pojęć biznesowych w postaci tabeli zawierającej precyzyjne, dziedzinowe definicje tych pojęć. Dla wygody i prezentacji ich treści naniosłem dwie reguły na diagram, są skojarzone z Kontem gdyż jego dotyczą. Co do zasady reguły biznesowe są kojarzone z elementami na innych diagramach poprzez słowa zdefiniowane.
Cała analiza powinna się zaczynać od udokumentowania modeli procesów. Tu pominąłem te modele bo ich opisów jest na moim blogu wiele, a chcę się skupić na dziedzinie dla jakiej powstaje aplikacja. Analiza i zrozumienie problemu prowadzi do stworzenia modelu dziedziny aplikacji. Taki model powstaje na podstawie treści dokumentów wewnętrznych i zewnętrznych (tu np. Ustawa o prawach autorskich), pomagają co najwyżej bieżące wyjaśnienia. Do jego powstania nie są potrzebne żadne warsztaty ani całodzienne spotkania.
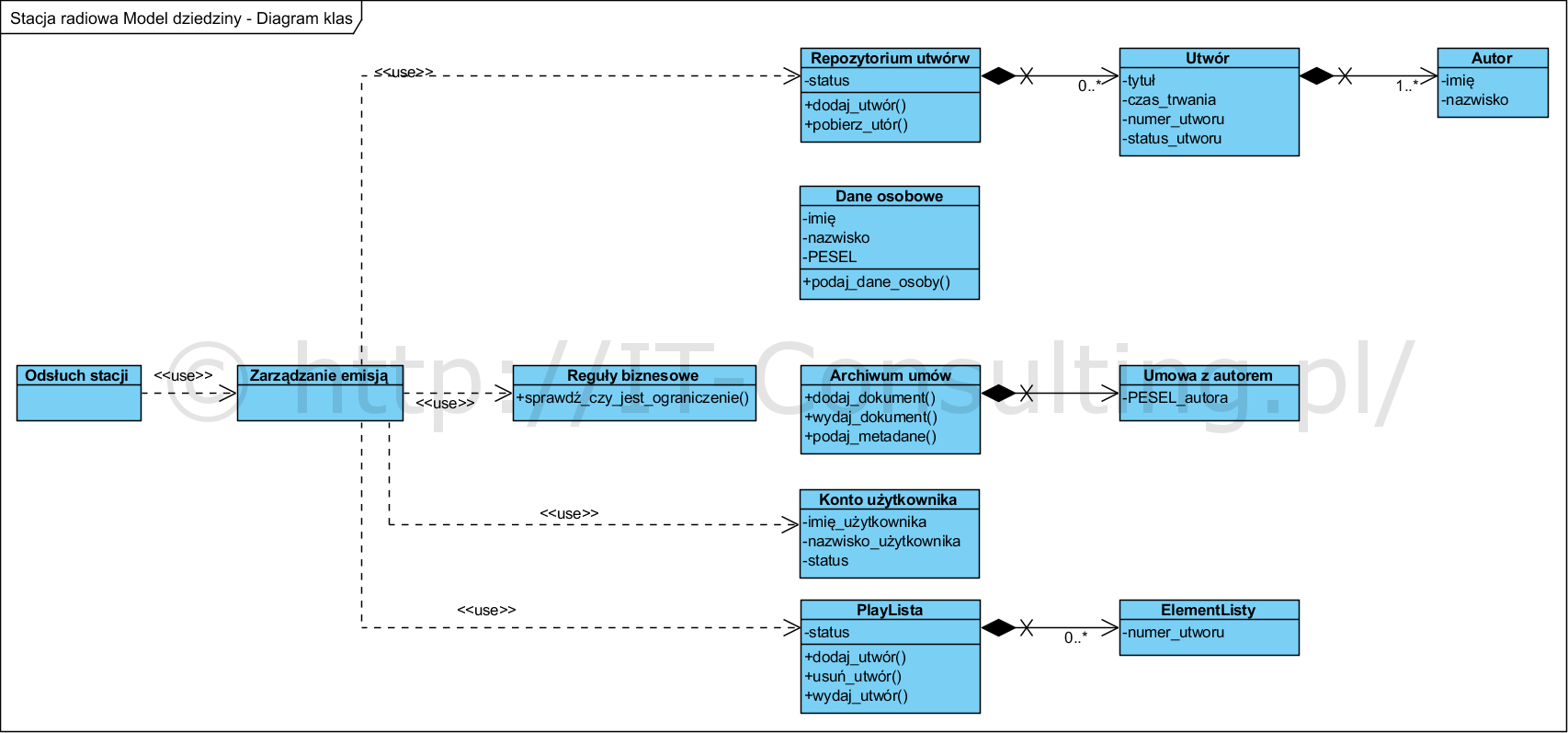
Celem modelowania dziedziny systemu (tu aplikacji) jest udokumentowanie wewnętrznej logiki aplikacji, czyli mechanizmu jej działania. Absolutnie nie jest to model danych. Powyższy model nie jest modelem “ukończonym”, wymaga na pewno dopracowania, jednak moim celem jest jedynie pokazanie idei jego tworzenia. Nazwy klas, atrybutów, operacji zawierają pojęcia zawarte w słowniku pojęć. Zapewnia to jednoznaczność i zrozumienie. Dodam, że dopiero ten model pokazuje bardzo ważną rzecz, to że autor jest cechą utworu a nie odwrotnie.
Tak więc:
- uruchomienie i korzystanie z emisji kontrolowane jest przez Zarządzanie emisją, tu sprawdzane są i egzekwowane, reguły biznesowe,
- komponent Zarządzanie emisją korzysta także z informacji zawartych w Koncie użytkownika i Playlisty, detale utworów pobiera z Repozytorium utworów.
Tu ważne jest podkreślenie, że reguła dotycząca ograniczenia liczby jednocześnie słuchających, jest oddzielona od Kont użytkowników i (nie pokazanych tu) Subskrypcji. Dzięki temu parametr ten jest łatwo modyfikowalny z poziomu aplikacji (parametryzowane kryterium decyzyjne) bez potrzeby jakichkolwiek ingerencji w “model danych”. Umieszczanie jakichkolwiek reguł w bazie danych (czyli na poziomie implementacji utrwalania) jest niestety ich “betonowaniem”.
Zmienność, nie tylko rynku ale i samych reguł w organizacjach, to stały element środowiska aplikacji. Dlatego dobrą praktyką jest, by utrwalanie danych (wszelkie bazy danych, pliki itp..) nie służyło do niczego poza utrwalaniem. Logika biznesowa powinna być w w 100% w aplikacji a nie podzielona pomiędzy aplikację i dane (żadna baza danych nie jest w stanie przechowywać innych reguł biznesowych niż bezpośrednie związki ilościowe). Na etapie implementacji, stosujemy zasadę hermetyzacji, czyli nie współdzielimy, na żadnym poziomie, danych pomiędzy repozytoriami i nie usuwamy redundancji. Dzięki temu nie odcinamy sobie drogi do zmian systemu takich jak np. zastąpienie klasy Dane osobowe interfejsem do zewnętrznego systemu, dysponującego takimi informacjami (klasa ta zostanie zmieniona, stanie się wtedy mostem do API zewnętrznego systemu co nie pociągnie za sobą jakichkolwiek zmian, bo interfejs tej klasy i jej nazwa pozostaną niezmienione, patrz zasada open-close principia oraz polimorfizm).
Poniżej kluczowe związki w UML i ilustracja związku pomiędzy modelem pojęciowym a modelem struktury (architektury, to model dziedziny):

Podsumowanie
Zmienność środowiska biznesowego powoduje, że żadne decyzje o logice biznesowej nie są ostateczne, jednak są elementy niezmienne takie jak np. nasze dane osobowe. Tak więc to, co powszechnie nazywane jest “modelem danych” (business data diagram) w rozumieniu opisanym przez autorki artykułu, nie ma dzisiaj racji bytu. Ma sens zachowanie zamówienia i osobno faktury, ale to czy regułą jest jedno zamówienie do jednej faktury, podlega zmianom wynikającym i ze zmienności prawa i ze zmienności modeli biznesowych. Nie widzę żadnego powodu deklarowania już na początku projektu, tego by nie więcej niż 5 osób mogło korzystać z jednego konta i subskrypcji. W szczególności nie widzę powodu by taka zasada była zawarta w samym kodzie aplikacji.
Warto także mieć na uwadze to, że oprogramowanie może być tworzone z użyciem zewnętrznych komponentów dostępnych na rynku. Założenie więc na samym początku projektu, że dane są w jednolity sposób przechowywane i współdzielone w jednej centralnej i współdzielonej bazie danych, wraz z logiką ich użycia, jest tu nie tylko nieuzasadnione ale wręcz szkodliwe. Dokładnie ta powstała, i nadal tak wygląda, znaczna większość obecnych na rynku systemów ERP, CRM itp….
Polecam ciekawą prezentację na temat budowania architektury systemów, autor zwraca uwagę, że istotą działania systemów są sekwencje interakcji modułów a nie statyczne modele danych:
oraz cytat z literatury z 1994 roku:



Jako eks-developer potwierdzam: polucje typu diagram rzeczowników w niczym nie pomagają.
Ciekawe ujął to znakomity G. Weinberg w https://www.amazon.com/Rethinking-Systems-Analysis-Design-Weinberg/dp/0932633080
Można modelować:
– being – struktury danych
– behaving – zachowania i reguły
– becoming – zmiany
To pierwsze pozwala zadać mało sensownych pytań: co to ma, jakiego typu to jest, ile tego jest.
Dwa kolejne pozwalają zadać masę sensownych pytań: kiedy się, dlaczego, kto to zmienia, czy można to powtórzyć lub odwrócić, jak często się zmienia,….
No i jestem znowu lżejszy o kilkanaście dolców 😉 … dziękuję 😀
Cześć.
Od razu przyznaję się – nie czytałem Weinberga, ale zapoznając się (przyznaję pobieżnie) z digestami jego książki, odnoszę wrażenie, że chodzi o jakieś architektoniczne podejście w SE. Rzeczywiście, rozwiązuje wiele problemów , w szczegóności brak osadzania modeli obiektów biznesowych (danych) w kontekście dynamicznym oraz brak separacji reguł biznesowych i zaszywanie ich w modelu danych, czego dziś już od dawna, o ile wiem, nie ptraktykuje się. Biorąc pod uwagę rok publikacji książki (1988), zaryzykuję stwierdzenie, że w świadomośći wielu analityków problem został już dawno uświadomiony i rozwiązany . Nie wykluczam jednak, że nawet po tylu latach książka wciąż zachowuje świeżość spojrzenia.
Pozdrawiam,
Marek
Ta książka ma swoje kolejne wydania, zaś podejście bazujące na osadzaniu całych systemów na jednym relacyjnym systemie bazodanowym jest od lat krytykowane jako nieskuteczne i wręcz szkodliwe (pierwsze publikacje D’Souzy na temat skuteczności hermetyzowanych architektur komponentowych ukazały się ponad 20 lat temu). Parcie na stosowanie systemów relacyjnych baz danych ma dwa źródła: korporacje zarabiające na tym miliardy oraz nadal popularne koncepcje dające wiarę w istnienie jednej ontologii. Ontologia (jako jeden uniwersalny system znaczeń i pojęć) to metafizyka, od której pozytywna filozofia odeszła już chyba w latach 30-tych. Umberto Eco, chyba najsłynniejszy semiotyk (poza tym, ze pisarz i filozof), dawno wykazał, że nie da się oderwać znaczenia słowa od kontekstu jego użycia co potwierdza teoria komunikacji (ludzkie języki mają mniej znaków/słów niż znaczeń, co tłumaczy istnienie i potrzebę słów wieloznacznych). Innymi słowy: poza wąsko kontekstowym systemem, nie ma jest możliwe opisania “świata” jednym spójnym systemem nazw. Walczą z tym, nadal bez żadnych sukcesów, wyznawcy uniwersalnej interoperacyjności systemów IT.
Jako że od lat jestem mocno przesunięty w poglądach w kierunku podejścia architektonicznego w analizie, myślenie relacyjne pozostawiłem developerom. Dziś częściej skłaniam się ku modelom i narzędziom grafowym (np. ostatnio ćwiczę Neo4J). Co do tezy na temat ontologii intuicyjnie zgadzam się (intuicyjnie bo brak mi”papierów” z tej dziedziny). Natomiast potwiedzam, że znane mi próby projektowania dużych systemów w oparciu o tzw. kanoniczne modele danych nie kończą się najlepiej. Przynajmniej ja nie mam pozytywnych doświadczeń.
No to mamy podobne doświadczenia 🙂 …
W kwestii Neo4 – może się mylę – to powtórne odkrywanie koła, polecam specyfikację notacji i systemu pojęciowego SBVR (omg.org).
A propos Neo4J, rzeczywiście idea jest stara, ale za to w nowym opakowaniu.
Czy znacie , Koledzy, jakieś narządko, na którym możnaby wprawiać się w SBVR?
Np. Visual-Paradigm 😉
Narzędzie ma zaimplementowany cały SBVR czyli: słownik biznesowy, diagram faktów i reguły biznesowe….
Dzięki. Zainstalowałem demo i biorę się za SBVR.
Dyskusja na LinkdIn:
https://www.linkedin.com/feed/update/urn:li:activity:6233332412919746560/
Pierwsze poważne publikacje o komponentowej orientacji w architekturze:
https://en.wikipedia.org/wiki/Catalysis_software_design_method
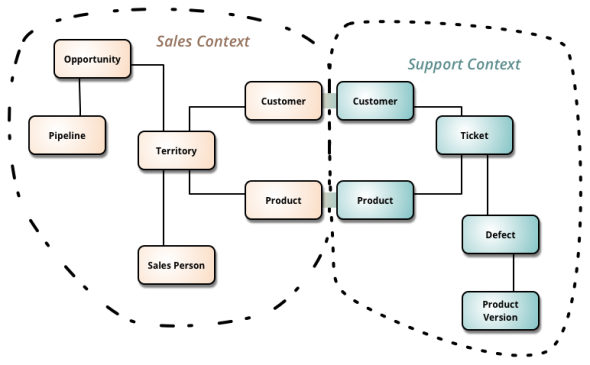
O tym, że budowanie kontekstowych komponentów rozwiązuje problemy ontologii i kanoicznych “ogólnych” modeli:
https://martinfowler.com/bliki/BoundedContext.html