Architektura reprezentuje ważną decyzję projektową, która wpływa na kształt systemu, przy czym waga decyzji mierzona jest kosztami zmian, które wprowadza.
— Grady Booch
Jeśli myślisz, że dobra architektura jest droga, spróbuj złej
Foote, B., & Yoder, J. (2003).
Big Ball of Mud .
https://www.researchgate.net/publication/2938621_Big_Ball_of_Mud
Wprowadzenie
Tym razem troszkę cięższy kaliber, czyli dywagacje o tym co powszechnie jest określane jako metody obiektowe i o tym skąd “konflikty i nieporozumienia” między programistami i analitykami projektantami. Ten artykuł to streszczenie i rozwinięcie referatu:
Paradygmaty
Literatura przedmiotu zawiera wiele różnych sposobów grupowania metod programowania w paradygmaty. Autorzy z reguły skupiają się na tym, czym są programy rozumiane jako zorganizowana lista poleceń dla maszyny. Mogą to być sekwencje prostych poleceń, mogą to być wykonywane wg. określonego scenariusza funkcje. Typowym przykładem takiego grupowania jest np. wykład (tu jego spis treści) dostępny w sieci Internet:
Wstęp
1.1 Przykład pierwszy: programowanie imperatywne
1.2 Przykład drugi: programowanie obiektowe
1.3 Przykład trzeci: programowanie funkcyjne
1.4 Przykład czwarty: programowanie w logice (programowanie logiczne) ?1?
Wykład ten, z uwagi na to, że pochodzi ze stron mimów.edu .pl (Uniwersytet Warszawski, Wydział Informatyki) w moich oczach, po lekturze kilkunastu podobnych, jest reprezentatywnym dla wielu środowisk akademickich podejściem.
Problemem rynku IT od bardzo dawna jest tak zwany Kryzys Oprogramowania (Software crisis). jego źródłem jest stale rosnąca złożoność kodu aplikacji. Pierwsze komputery wykonywały jedynie pojedyncze złożone obliczenia, co skutkowało powstaniem kodu o objętości kilkuset linii kodu, rzadko więcej. Jednak od czasu gdy oprogramowanie, a konkretnie komputer, stało się narzędziem pracy poza laboratoriami: w urzędach, instytucjach czy firmach, jego złożoność zaczęła lawinowo rosnąć. Do tego wolumeny danych to już terabajty i ich struktury to wielokrotnie zagnieżdżone dokumenty i formularze. W efekcie programy z kilkuset linii doszły do setek ich tysięcy, nie raz milionów linii kodu. Jest to coś, czego umysł, pamięć i wyobraźnia człowieka nie są w stanie ogarnąć.

Dlatego prawie od samego początku inżynierii oprogramowania mówimy o “architekturze oprogramowania”. Program komputerowy to procedury i algorytmy. Jeżeli jest ich kilkadziesiąt, mozna je grupować np. w podprogramy. Jednak jeżeli są ich setki i tysiące pojawia się konieczność grupowania ich w nadrzędne grupy. Początkowo kod grupowany był w funkcje,, jednak szybko sie okazało, że lista setek funkcji jest nie mniej kłopotliwa niż wcześniej setki linii kodu.
Okazało się, że lepszym rozwiązaniem jest tematyczne, dziedzinowe grupowanie linii kodu w komponenty i realizowanie funkcjonalności oprogramowania jako scenariuszy ich użycia. Tak narodził się tak zwany paradygmat obiektowy: system składa się z komunikujących się hermetycznych obiektów (dziedziczenie i łączenie funkcji i danych w obiekty to cechy języków programowania a nie paradygmat obiektowy, patrz prezentacje na końcu artykułu).
W tym artykule postaram się wyjaśnić na czym to polega.
Programowanie strukturalne
Jest to paradygmat programowania opierający się na podziale kodu źródłowego programu na procedury i hierarchicznie ułożone bloki z wykorzystaniem struktur kontrolnych w postaci instrukcji wyboru i pętli. Rozwijał się w opozycji do programowania wykorzystującego proste instrukcje warunkowe i skoki. Programowanie strukturalne zwiększa czytelność kodu i ułatwia analizę programów, co stanowi znaczącą poprawę w stosunku do trudnego w utrzymaniu ?spaghetti code? często wynikającego z użycia instrukcji “go to”. Nadal jest to jednak długa lista silnie powiązanych procedur.
Metody strukturalne analizy i projektowania bazują na uznaniu, że oprogramowanie to stos funkcji operujących na bazach (składach) danych. Innymi słowy podstawowe założenie to istnienie odrębnych bytów jakimi są baza danych oraz funkcje, które na tych danych wykonują operacje. W metodach strukturalnych tworzy dwa się rodzaje modeli: model procesu przetwarzania i model struktury danych. Pierwszy wykorzystuje notację DFD (Data Flow Diagram, np. notacja Gane?a- Sarsona) a drugi notacja ERD (Entity Relationship Diagram, np. notacja Martina) do modelowania struktur relacyjnych baz danych.
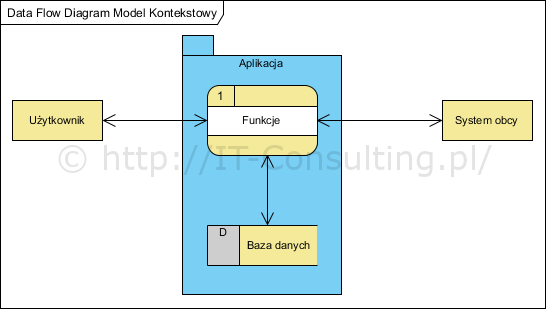
Struktura aplikacji w postaci tak zwanej ?czarnej skrzynki? została pokazana na Rysunku 1. W metodach strukturalnych, na poziomie opisu architektury, aplikacja ?dzielona jest? na podfunkcje (patrz Rysunek 2.).
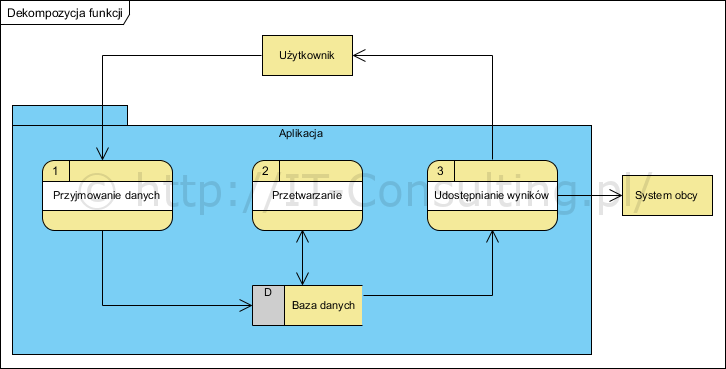
Starsze podręczniki informatyki i programowania powołują się na ?zasadę?: algorytmy + struktury danych = oprogramowanie (aplikacje). Kod zawierający funkcje jest z reguły dzielony jest na części zwane ?podprogram?, jednak niezależnie od tego jak jest zorganizowany, jest to zwarty i niepodzielny system funkcji i algorytmów, który zapisuje i odczytuje dane ze współdzielonego ?magazynu danych?. Najczęściej tym magazynem jest relacyjnie zorganizowana baza danych?2?, czyli system powiązanych tablic, w którym usuwa się redundancje i tworzy trwałe związki logiczne między tak zorganizowanymi danymi.

Architektura taka nie sprawia większych problemów do momentu gdy aplikacja nie zaczyna się rozrastać i nie pojawia się potrzeba wprowadzania kolejnych nowych lub zmienionych elementów mechanizmu jej działania. Wtedy każda ingerencja w tak zorganizowaną architekturę dotyczy prawie zawsze całej aplikacji. Stabilne kiedyś otoczenie (środowisko użytkowania tych aplikacji) pozwalało na projektowanie oprogramowania, od którego nikt nie oczekiwał, że pozwoli na łatwe i szybkie wprowadzanie zmian. Po drugie, tworzeniem oprogramowania zajmowały się małe zespoły programistów, zaś logika przetwarzania polegała raczej na realizowaniu małej liczby typów operacji na wielkich ilościach danych, to były głownie projekty inżynierskie a nie badawcze. Zamawiający (tak zwany dzisiaj ?biznes?) musiał jedynie spisać dane i operacje oraz wzory (formuły) z jakich użyciem były one przeliczane.
Zmiana paradygmatu
Rosnąca złożoność oprogramowania wymusiła szukanie nowych rozwiązań. Początkowo dzielono kod aplikacji na separowane części – moduły, jednak nadal stanowiły one jedną całość z powodu pracy z danymi w postaci jednej zwartej struktury, jaką jest współdzielona relacyjna baza danych. Fakt ten często jest postrzegany jako zaleta: wskazuje się na brak redundancji, łatwy sposób uzyskania spójności danych, współdzielenie jako łatwą integrację. Problem w tym, że duże aplikacje operują w wielu kontekstach, co powoduje, że współdzielona baza danych o ustalonej strukturze, musi stanowić kompromis. Np. dane stanowiące zapis kolejnych zakupów amortyzowanych środków trwałych mają inną strukturę i logikę wzajemnych powiązań, niż te same dane w kontekście złożonych konstrukcji mechanicznych jakimi są te środki trwałe. Innym przykładem obrazującym kwestie kontekstowości jest przykład na blogu Martina Fowlera.?3?
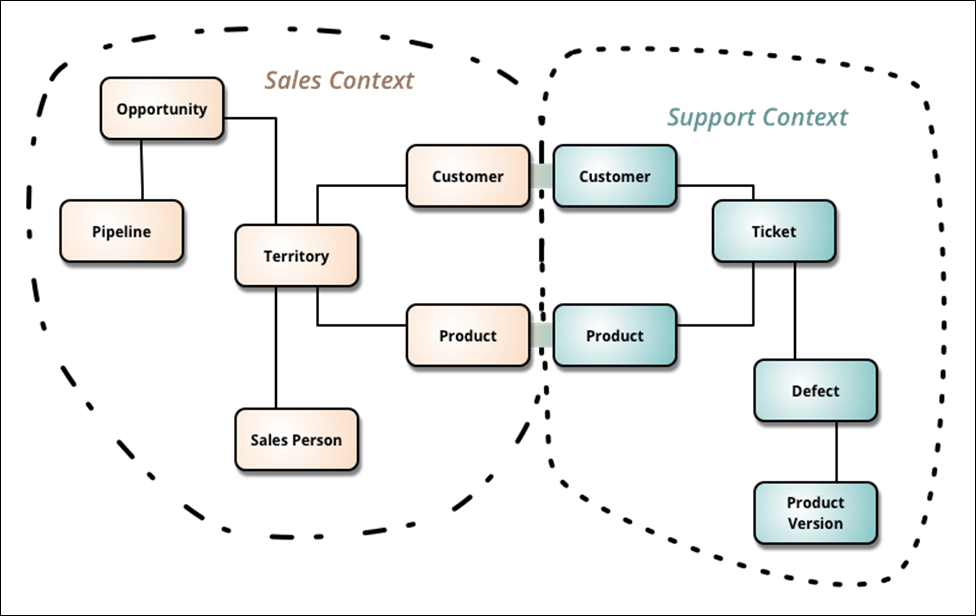
Jak widać na Rysunku 3., mamy tu dwa konteksty i redundancje (pojęcia Customer i Produkt powielone po obu stronach: w obu dziedzinach). Powyższe powinno być podstawą do podziału projektu na dwa odrębne komponenty z własnymi (nie współdzielonymi) danymi. Jak widać każdy komponent operuje pojęciami Customer i Produkt, jednak inny jest ich kontekst. Inne cechy dziedzinowe tych pojęć nie są (nie powinny być) współdzieloną informacją w jednej bazie danych, oba komponenty będą miały swoje odrębne modele danych, zapewne o różniącej strukturze. Powód pierwszy to inne związki pojęciowe i być może nawet inne definicje pojęć. Produkt w kontekście sprzedaży ma nazwę, cenę, dostępność itp. Produkt w kontekście uszkodzeń ma numer seryjny, wersję, użytkownika itp. Inne będą reguły biznesowe w każdym komponencie. Drugi powód to łatwa dostępność na rynku specjalizowanych produktów typu CRM i TicketXXX, szukanie (tworzenie) jednego ?pakietu zintegrowanego? będzie bardzo trudne, bo kontekstów sprzedaży a potem obsługi uszkodzeń czy reklamacji, jako pary, będą tysiące wariantów. Wytworzenie (zakup) osobno, i integracja dwóch odpowiednio dobranych komponentów (aplikacji), będą znacznie łatwiejsze.
Powoli zaczęły swego czasu powstawać aplikacje dziedzinowe, jednak nadal wewnętrznie miały one opisane wyżej wady współdzielenia danych w jednej bazie. Do tego ich integracja polegała na wzajemnym sięganiu do danych co stanowiło bardzo duży problem z powodu różnych struktur tych danych, zaś wymiana jednej z nich na inną wymagała opracowania od nowa całej koncepcji integracji współdzielonych danych co pokazano na Rysunku 4.
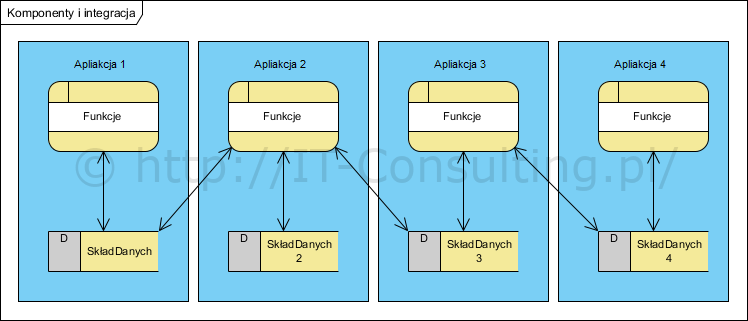
Obiektowy paradygmat
Co ciekawe powstanie metod obiektowych nie było szukaniem sposobu usunięcia wad systemów strukturalnych. Pierwsze obiektowe narzędzia powstały już w latach sześćdziesiątych XX w. narzędzia i programy strukturalne także powstają do tej pory.
Do obecnej popularności metod obiektowych doprowadziły dwie ścieżki: problem rosnącej złożoności kodu aplikacji oraz potrzeba utrzymania zrozumieniu ?tego czym jest ta aplikacja? po stronie zamawiającego.
Proces, powszechnie zwany “zbieraniem wymagań”, staje się coraz bardziej skomplikowany i ryzykowny, w miarę jak rośnie złożoność tych systemów.
Wymagania na oprogramowanie naliczające wynagrodzenia tysiącom pracowników to ?jeden wzór? na naliczenie wynagrodzenia oraz pewna liczba cech jakościowych takich jak wydajność czy dostępność. Jednak opisanie tą metodą “jednej” aplikacji, operującej dziesiątkami dokumentów o różnych strukturach i ogromnej ilości zależności między nimi, z pomocą ?listy cech? zaczyna przybierać postać setek, a nie raz tysięcy, linii i danych w tabelach. Przy takiej ilości “wymagań” praktycznie żaden sposób ich organizacji nie wprowadza wartości dodanej, zaś ich liczba praktycznie nie pozwala na kontrolę kompletności i niesprzeczności.
Popatrzmy na komentarz autora wykładu?1? do obiektowego programowania:
W programowaniu obiektowym program to zbiór porozumiewających się ze sobą obiektów, czyli jednostek zawierających pewne dane i umiejących wykonywać na nich pewne operacje
– Ważną cechą jest tu powiązanie danych (czyli stanu) z operacjami na nich (czyli poleceniami) w całość, stanowiącą odrębną jednostkę: obiekt.
– Cechą nie mniej ważną jest mechanizm dziedziczenia, czyli możliwość definiowania nowych, bardziej złożonych obiektów, na bazie obiektów już istniejących.
Zwolennicy programowania obiektowego uważają, że ten paradygmat dobrze odzwierciedla sposób, w jaki ludzie myślą o świecie
– Nawet jeśli pogląd ten uznamy za przejaw pewnej egzaltacji, to niewątpliwie programowanie obiektowe zdobyło ogromną popularność i wypada je uznać za paradygmat obecnie dominujący.
W cytowanym tekście widać stereotypowe podejście autora:
“metody obiektowe tworzenia oprogramowania, opierają się na wyróżnianiu w tworzonym oprogramowaniu dwóch rodzajów składowych: pasywnych odzwierciedlających fakt przechowywania w systemie pewnych danych oraz składowych aktywnych odzwierciedlających fakt wykonywania w systemie pewnych operacji. Metody obiektowe wyróżniają w systemie składowe, które łączą w sobie możliwość przechowywania danych oraz wykonywania operacji.” (źr. wikipedia).
Schematycznie można to przedstawić tak:
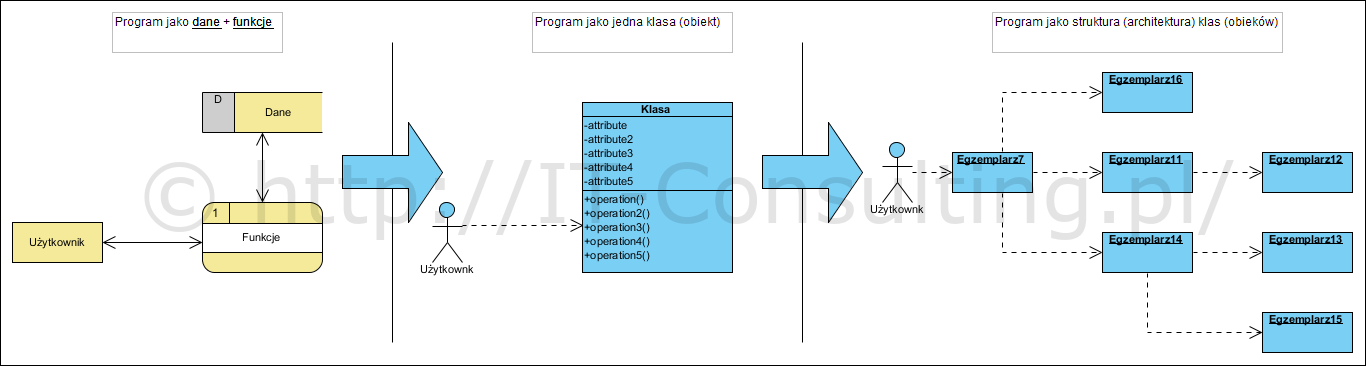
Podejście, które nazwę programistycznym, to uznanie, że trzeba podzielić dużą aplikację na mniejsze odrębne komponenty, z których każdy ma “swoje funkcje i dane”. Tu także podkreślana jest kwestia re-użycia kodu w postaci tak zwanego dziedziczenia jako “mechanizmu definiowania nowych, bardziej złożonych obiektów, na bazie obiektów już istniejących” .
Zupełnie inną drogą jest podejście oparte na uznaniu, że świat rzeczywisty to określony mechanizm, który da się odwzorować jako pewna abstrakcja za pomocą kodu (jego struktury). Tu struktura kodu jest konsekwencją struktury tego obszaru “świata rzeczywistego”, którego dotyczy tworzone oprogramowanie (o czym już na swoim blogu nie raz pisałem).
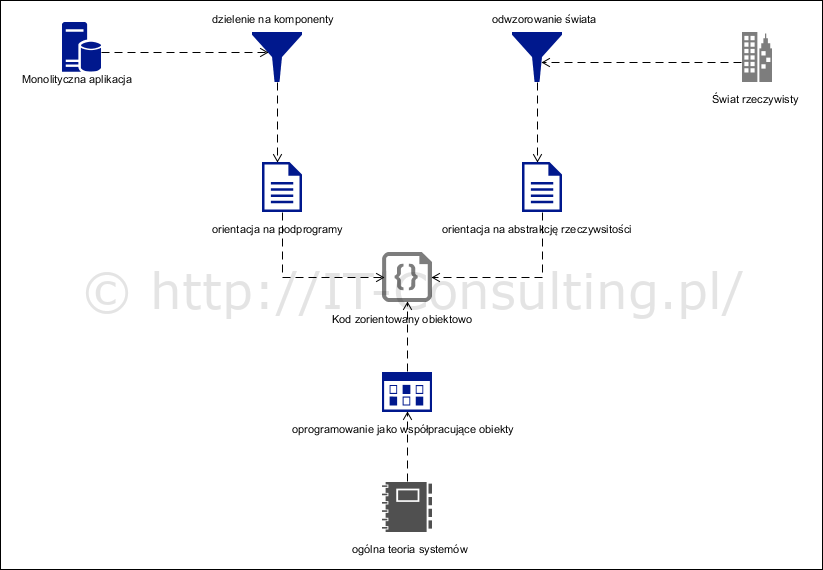
Skutek jest “taki sam”: program stworzony zgodnie z obiektowym paradygmatem będzie się owszem składał z klas obiektów, które komunikują się wzajemnie. Jednak nie jest to podejście zorientowane na dzielenie dużej aplikacji na podprogramy traktujące obiekty jako “jakieś” komponenty zawierające w sobie kod funkcji i dane na jakich one operują. Podejście zorientowane na modelowanie “świata rzeczywistego” zaowocuje obiektami stanowiącymi abstrakcje (modele) elementów świata rzeczywistego. Struktura takiego kodu w obu przypadkach będzie “obiektowa” ale jej sens nie raz jest skrajnie inny np. obiekt faktura będzie zawierał dane o sprzedaży ale nie będzie miał operacji “nowa faktura”, bo faktury nie tworzą nowych faktur (ani nie niosą informacji o tym jak powstawały). Faktury będą tworzone przez inny obiekt np. Twórca faktur (albo jak w niektórych wzorcach: fabryka faktur).?4?
Od lat sześćdziesiątych prowadzone są prace nad metodami obiektowymi w inżynierii oprogramowania, powstaje języka SIMULA w 1967 roku. W 1968 roku opublikowano pierwsze oficjalne wydanie Ogólnej Teorii Systemów Ludwiga von Bertalanffy’ego (publikacje na jej temat pojawiały się od już 1964 roku). Teoria systemów mówi, że “system to współpracujące obiekty”, język SIMULA powstał do tworzenia (programów) symulacji obiektów świata rzeczywistego.
Oba wskazane podejścia są znane od lat, jednak podejście “inżynierskie” (dzielenie dużego kodu na małe kawałki) dominuje, nie tylko jak widać w systemie kształcenia.
Ogólna teoria systemów traktuje wszystko jak “system” (współpracujące obiekty). Z zewnątrz system to obiekt reagujący na bodźce. Reakcja ta może być opisana mechanizmem jej powstawania, to wewnętrzna struktura systemu. Jeżeli uznać, że oprogramowanie (i komputer) zastępuje określoną rzeczywistość (np. mechaniczny zegar zastąpiony programem wykonywanym w komputerze) to można przyjąć, że komputer to maszyna abstrakcyjna, jej implementacja realizuje konkretne systemy i (lub) ich komponenty?5?.
Nie chodzi więc o to by podzielić oprogramowanie na “składowe, które łączą w sobie możliwość przechowywania danych oraz wykonywania operacji”. Chodzi o to by mechanizm, o dowiedzionej poprawności, zaimplementować w określonej wybranej technologii.
Chodzi też o to by nie udawać, że programowanie jako “podzielone na obiekty” partie kodu, nadal korzystające z jednej wspólnej bazy danych, różni się czymkolwiek od “strukturalnego kodu”. Chodzi o to by kod programu faktycznie implementował określony (zbadany i opisany) mechanizm.
Tak więc “obiektowy paradygmat” to nie “nowe programowanie”, to architektura kodu: “obiektowa” architektura???.
Proces projektowania oprogramowania, idąc tropem analizy systemowej i opisania mechanizmu działania “tego czegoś”, zaczyna się już na etapie analizy. Programista implementuje model a nie “wymyśla program”. Oczywiście pod warunkiem, że mamy tu na myśli analizę obiektową i projektowanie systemu a nie “jakiś podział kodu na klasy”.
Poniżej komponentowa (obiektowa) struktura aplikacji i diagramy UML jakimi jest wyrażana:
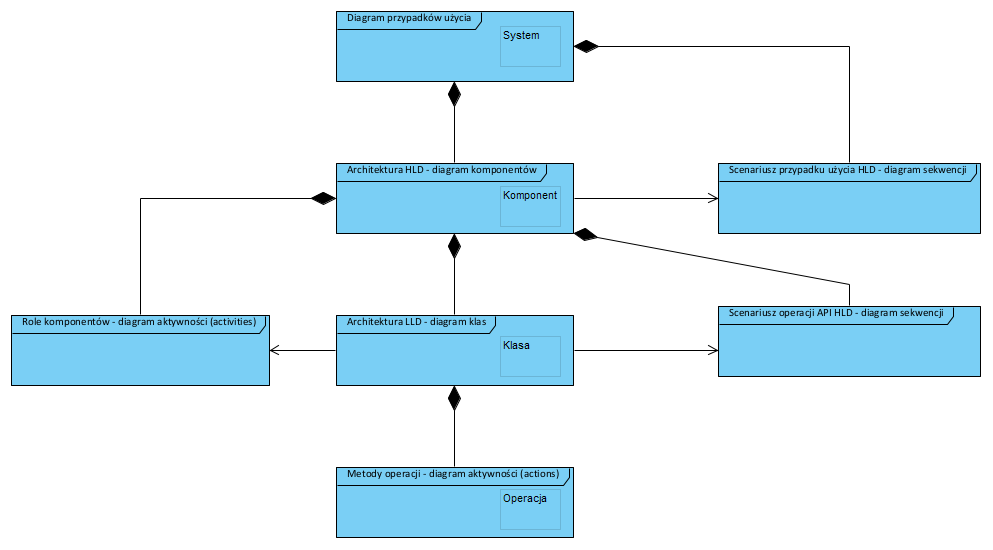
Obiekt to nic innego jak procedury zgrupowane w obiekty (metody operacji to procedury), a komponenty to procedury korzystania z tych obiektów. Całość tworzy określoną architekturę opisana np. wzorcem zwanym mikroserwisy.
Na zakończenie jeden z moich ulubionych cytatów na temat analizy i projektowania obiektowego:

Polecam wysłuchanie referatu na temat roli architeltury:
Na temat tego, że UML jest lepszy od odręcznych szkiców:
Oraz referatu na temat zalet projektowania poprzedzającego kodowanie:
Oraz kolejnego referatu o architekturze i dekompozycji:
- ?*?Artykuł został opublikowany w materiałach pokonferencyjnych: https://www.academia.edu/37284192/Materiały_pokonferencyjne_III_Ogólnopolskiej_Konferencji_Interdyscyplinarnej_Współczesne_zastosowania_informatyki_Architektura_kodu_aplikacji_jako_pierwszy_etap_tworzenia_oprogramowania
- ???Wielu autorów przywołuje tu pojęcie komponentów a nie obiektów. Komponentem jest tu każdy samodzielny, komunikujący się z otoczeniem, obiekt niezależnie od wielkości i stopnia złożoności.
Źródła:
- 1.Paradygmaty programowania/Wykład 1: Co to jest paradygmat programowania? – Studia Informatyczne. MIMUW. http://wazniak.mimuw.edu.pl/index.php?title=Paradygmaty_programowania/Wykład_1:_Co_to_jest_paradygmat_programowania%3F. Accessed July 16, 2017.
- 2.Relacyjne bazy danych -podstawy. SQLpedia. http://www.sqlpedia.pl/relacyjne-bazy-danych-pojecia-podstawowe/. Published April 16, 2013. Accessed July 17, 2017.
- 3.Fowler M. bliki: BoundedContext. martinfowler.com. https://martinfowler.com/bliki/BoundedContext.html. Published January 15, 2014. Accessed July 16, 2017.
- 4.Żeliński J. Analiza biznesowa. Praktyczne modelowanie organizacji. onepress.pl. http://onepress.pl/view/2239k/sfomod.htm. Accessed July 16, 2017.
- 5.Filozofia matematyki i informatyki. Księgarnia Internetowa PWN. https://web.archive.org/web/20240809055741/https://ksiegarnia.pwn.pl/Filozofia-matematyki-i-informatyki,84899525,p.html. Accessed July 17, 2017.
- 6.Martin Fowler, Analysis Patterns, 1997.




Ciekawa prezentacja:
Software Architecture, Team Topologies & Complexity Science ? James Lewis ? YOW! 2022
https://youtu.be/QfM38-I_Ea8