Wprowadzenie
Dziesięć lat temu pisałem o informacji i jej strukturalnym charakterze, wpis kończył się zdaniem:
czym więc jest Zarządzanie Wiedzą (milcząco zakładam, że zarządzać można czymś materialnym)? Jest to ?przechowywanie danych jednoznacznie zrozumiałych, opisujących określone i ograniczone liczbą fakty interpretowane jako pojmowalna przez adresata informacja?.Przemyślenia związane z tą ostatnią definicją pozostawiam Państwu. Ciąg dalszy może nastąpi? (źr. : Potrzeby informacyjne firmy ? Zarządzanie wiedzą | Jarosław Żeliński IT-Consulting)
Kontynuacją cytowanego tekstu będzie dzisiaj kwestia informacji i powiązanych z nią wymagań na oprogramowanie. Każdy projekt wytworzenia, lub nawet tylko dostarczenia gotowego, oprogramowania powinien mieć co najmniej dwie warstwy opisu: (1) co chcemy stworzyć i (2) jak to chcemy stworzyć. Pierwsza to tak zwana warstwa abstrakcyjna opisująca mechanizm funkcjonowania systemu. Druga to logiczna architektura systemu czyli pomysł na realizację (model Platform Independent). Na podstawie modelu PIM developer realizuje implementacje oprogramowania (Platform Specific Model). Jednak często dostawca istniejącego oprogramowania chce porównać logikę oprogramowania, które oferuje, z logiką opisaną jako wymaganą. Tu potrzebny jest nie model architektury PIM a model informacyjny opisujący logikę biznesową ale nie narzucający architekturę (bo ta już istnieje).
Bardzo często głównym celem biznesowym, i zarazem wymaganiem, jest zarządzanie treścią, czyli skończoną liczbą typów dokumentów o ustalonej (lub wymagającej ustalenia) treści i strukturze. Niestety często jest tak, że struktura dokumentów ulega pewnym zmianom przy zachowaniu głównego celu dla jakiego powstały, co utrudnia zadanie ale nie jest prawda, że jest to powód do permanentnego modyfikowania oprogramowania. Odporność (gotowość) aplikacji na zmienność treści jest tu wymaganiem i system powinien sobie z tym poradzić (i jest to możliwe).
W takich przypadkach modelując system warto skupić się wyłącznie na treści i na tym jak jest ona zarządzana, pozostawiając pewne detale architektury dostawcy, który z zasady – jako developer – dysponuje większą wiedzą o dostępnych na rynku technologiach i narzędziach. W takich przypadkach warto opracować tak zwany model informacyjny. Nie jest on jednak ani bazą danych ani modelem dziedziny (przypominam, że obiektowy model dziedziny to komponent architektoniczny wzorca MVC). Jest to model związków logicznych między dokumentami opisujący mechanizmy korzystania z nich.
O informacji
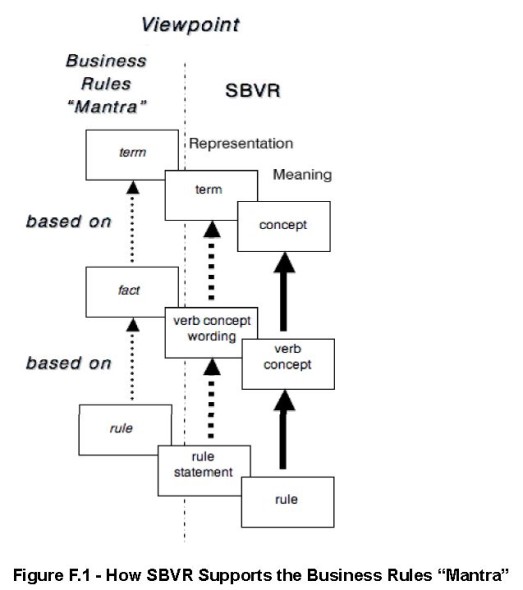
Kluczowymi pojęciami w tym obszarze analiz są: nośnik, dokument, informacja, treść, dane, wiadomość, które można zobrazować w postaci związków pojęciowych (diagram faktów SBVR):
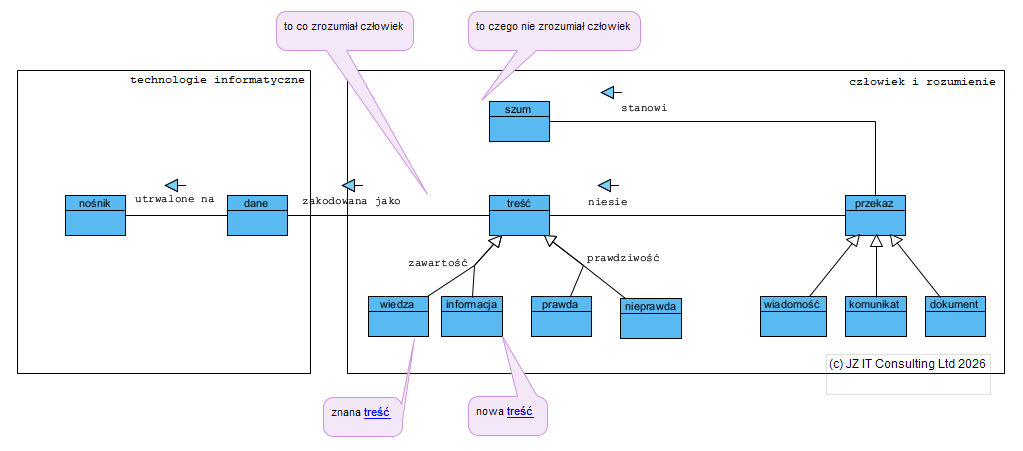
Dokument elektroniczny (obecny jako pojęcie od kilku lat w polskim prawie) jest definiowany jako
stanowiący odrębną całość znaczeniową zbiór danych uporządkowanych w określonej strukturze wewnętrznej i zapisany na informatycznym nośniku danych (na podstawie ustawy KPA1 i SJP PWN).
Innymi słowy: dokument elektroniczny to (uporządkowane) dane zapisane na elektronicznym nośniku, jednak nośnikiem może być nadal np. papier, więc generalnie pod pojęciem dokument można (należy) rozumieć “utrwaloną odrębną całość znaczeniową, zbiór danych uporządkowanych w określonej strukturze wewnętrznej”. Skoro odrębną, to także mającą unikalną nazwę, bez czego niemożliwe było by odwołanie się do takiego dokumentu. Kolejna ważna rzecz: znaczenie i struktura. Strukturę dokumentu określa jego szablon, treść zaś to to co zostanie zapisane z użyciem tego szablonu. Przykład: słowo faktura oznacza obowiązujący szablon dokumentu mogącego, po wypełnieniu, zawierać informacje o tym, kto, komu, co, kiedy i za jaką kwotę sprzedał.
Generalnie treść jest organizowana w nazwane struktury czyli dokumenty. Tu ważna uwaga: ludzie w procesie komunikacji zawsze operują treścią o określonej strukturze, bywa, że jest ona – struktura – prosta, strukturą jest także podział wymiany treści (lub informacji) na odrębne komunikaty. Nie zmienia to faktu, że taki komunikat to struktura zawierająca autora i nadawcę komunikatu, odbiorcę komunikatu oraz jego treść, jest to formularz – struktura – jaką widzimy pisząc np. kolejnego maila.
W efekcie można przyjąć, że wszelkie treści w organizacjach są zorganizowane z użyciem określonej liczby formularzy, z których każdy ma określoną strukturę. Struktury te nazywamy szablonami dokumentów (formularzy).
Model informacyjny organizacji
Przyjmując, że to co przetwarzamy w firmie do trafiające do nas nowe treści, często są to także informacje (nowe treści). W związku z tym, mamy prawo uznać, że wszystkie informacje w firmie są zorganizowane w użyciem skończonej liczby struktur i nie są to struktury znane z relacyjnych baz danych, są to odrębne i niepołączone (niewspółdzielące danych) formularze, czyli po prostu odrębne dokumenty. Formularze te mogą być jawnie logicznie skojarzone np. na fakturach są nanoszone numery zamówień. Mogą być skojarzone nie wprost, z użyciem określonych reguł np. podatek za dany miesiąc naliczamy na podstawie faktur wystawionych w tym miesiącu albo dany referent ma dostęp do dokumentu, jeżeli ten związany jest ze sprawą aktualnie przydzieloną temu referentowi. Ostatni przykład to typowe dynamiczne powiązanie gdyż przydział referenta do sprawy, a więc także dokumentów z nią powiązanych, może ulegać zmianie w czasie.
Formularze te, ich zawartość oraz logika powiązań pomiędzy nimi, to system informacyjny organizacji. Każda organizacja cechuje się własnym, indywidualnym system informacyjnym, gdyż tylko część dokumentów ma z góry narzuconą strukturę np. prawem lub standardem branżowym. Reszta, struktura wewnętrznych dokumentów, to decyzje wewnętrzne organizacji.
Postrzegam jako poważny błąd uznanie, że model informacyjny to jednolita relacyjna struktura danych (pojęć) podobna do (budowana na wzór) ontologii2. Po pierwsze relacyjny model danych przechowuje nie dokumenty a pojęcia, uznając związki między pojęciami za stałe relacje (co nie zawsze jest prawdą). Po drugie usuwanie redundancji w procesie zapisu danych z formularzy wymaga ich odtworzenia przy każdej próbie odtworzenia konkretnego dokumentu. Tak więc taka relacyjna baza danych nie przechowuje żadnych dokumentów a jedynie zbiór trwale powiązanych pojęć. Bardzo często mówi się, że informacje i wiedza to ontologia. Niestety tak nie jest, ontologia to system pojęć powiązanych związkami semantycznymi, stanowi opis językowa ale nie jest to wiedza o świecie a wiedza o języku.
Nie jest informacją samo pojęcie, jego definicja i semantyczne powiązanie z innym pojęciem. To tyko model syntaktyka i semantyka pojęć. Faktura zaś to zbiór pojęć mających określoną strukturę i treść, wartość ma to – wiedza – kto, co kiedy i od kogo kupił, a nie to co znaczy słowo produkt czy nabywca i jak jest semantycznie on powiązany z pojęciem sprzedawca. To co najwyżej pozwoli nam zrozumieć jaką treść zawiera faktura.
Kolejną wadą podejścia relacyjnego jest to, że baza taka stanowi niepodzielny monolit, w efekcie to co jest możliwe w rzeczywistości (np. praca z fakturą w całkowitym oderwaniu od odpowiadających jej zamówień) jest niemożliwe w systemie z relacyjnym modelem danych. Usuwanie redundancji powoduje także powstawanie dużego narzutu na zarządzanie historią zmian pól baz danych, co nie ma miejsca w rzeczywistych dokumentach (kartoteka klienta zawiera wyłącznie aktualne dane adresowe, historyczne są dostępne w historycznych dokumentach, np. aktualne dane adresowe klienta są w jego kartotece, jego adres z ubiegłego roku znajdziemy na dokumentach wystawionych temu klientowi w ubiegłym roku).
Rok temu pisałem przy podobnej okazji:
warto zauważyć, że zmienność środowiska biznesowego powoduje, że żadne decyzje o logice biznesowej nie są ostateczne, jednak są elementy niezmienne takie jak np. nasze dane osobowe. Tak więc to, co powszechnie nazywane jest ?modelem danych? (business data diagram) w rozumieniu opisanym przez autorki artykułu, nie ma racji bytu. Ma sens zachowanie zamówienia i osobno faktury, ale to czy regułą jest jedno zamówienie do jednej faktury, podlega zmianom wynikającym i ze zmienności prawa i ze zmienności modeli biznesowych. Nie widzę żadnego powodu deklarowania już na początku projektu, tego by nie więcej niż 5 osób mogło korzystać z jednego konta i subskrypcji. W szczególności nie widzę powodu by taka zasada była zawarta w samym kodzie aplikacji. (źr. : Biznesowy model danych ? nie chcemy | | Jarosław Żeliński IT-Consulting).
Problemy jakie wnosi do projektu oparcie się na jednym relacyjnym modelu danych dla całej aplikacji, są znane od lat:

a mimo to nadal jest on stosowany w sposób stanowiący zagrożenie dla całego projektu.
Czym więc jest model informacyjny organizacji? Jest to system szablonów dokumentów czyli ustalonych struktur informacyjnych wraz z logiką ich wzajemnych powiązań czyli asocjacji, świadomie unikam pojęcia relacji. Relacja to trwały związek, zaś asocjacja to skojarzenie budowane na bazie określonej logiki czy zachodzącego faktu. Przykład: faktura skojarzona jest z osobą, która dokonała sprzedaży, jednak w momencie gdy upłynie termin ważności i faktura nie jest opłacona, jest ona automatycznie kojarzona z windykatorem i sprzedawca przestaje być za nią odpowiedzialny (być może nawet traci dostęp do jej treści, zgodnie z zasadą bezpieczeństwa mówiącą, że pracownicy mają dostęp wyłącznie do informacji potrzebnej do realizowania ich bieżących zadań i obowiązków).
Jak podejść do opracowania i udokumentowania systemu informacyjnego, czyli jak wykonać jego model? Pierwszy krok to zidentyfikowanie dokumentów. Podstawą będzie tu analiza procesów biznesowych i opracowanie ich modeli. Elementarny (atomowy) proces biznesowy to aktywność mająca wejście i wyjście, a konkretnie dane wejściowe i dane, który powstają jako produkt tej aktywności. Te dane to nic innego jak informacje o określonej strukturze. Oznacza to, że na modelu procesów (tu w notacji BPMN) każda aktywność musi mieć skojarzony dokument wejściowy i wyjściowy (element o nazwie DataObect w noracji BPMN), w przeciwnym razie taka aktywność nie powinna się pojawić na modelu.
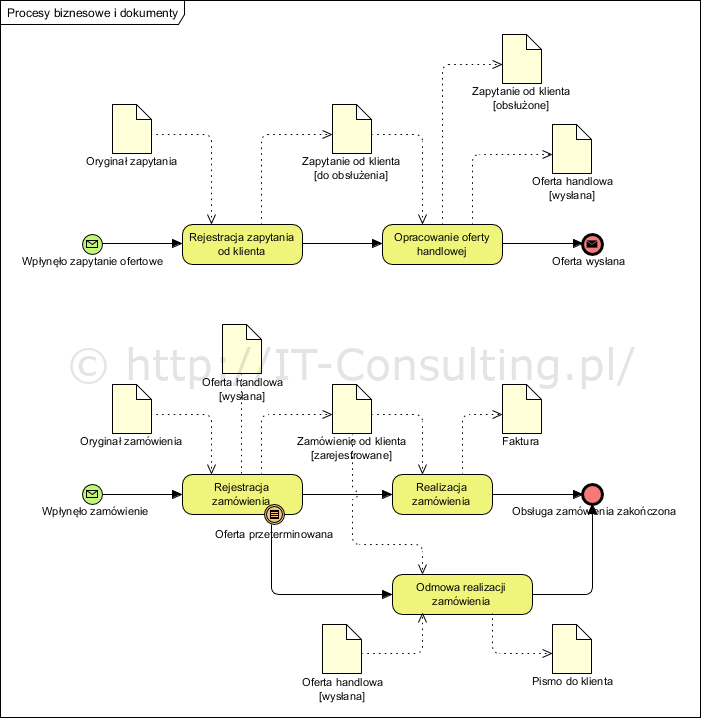
Powyższy diagram zawiera modele dwóch odrębnych procesów: obsługa zapytań ofertowych oraz obsługa zamówień. Oba diagramy to najniższy poziom modelowania procesów, poziom elementarnych (atomowych) procesów biznesowych. Pozwala zidentyfikować wszystkie dokumenty i ich statusy.
Tu mała uwaga: nie ma żadnego sensu umieszczanie na takich modelach detalicznych prac takich jak “wprowadzenie danych zamawiającego” czy “sprawdzenie salda” bo to są elementy (kroki) procedur. Innymi słowy nie “rysujemy” na diagramach tego jak i w jakiej kolejności wypełnić pola formularza. Po pierwsze zaciemni to obraz, po drugie procedur, reguł biznesowych i słowników nie modelujemy z użyciem BPMN. Robi się to w postaci odrębnych dokumentów lub diagramów.
Powyższy model obrazuje sytuację, w której pewna firma odsyła oferty na zapytania, otrzymując zaś zamówienie, sprawdza je od strony formalnej i realizuje. Każdy taki model, dla pełnej zrozumiałości, MUSI mieć załączone (diagramy, wzory wydruków, inne) struktury tych dokumentów. Dodatkiem będzie właśnie model informacyjny czyli logiczna struktura powiązań logicznych między dokumentami (korzystają z niej osoby pracujące z tymi dokumentami).
Prosta wersja takiego modelu informacyjnego może zostać wykonaną także w notacji BPMN:
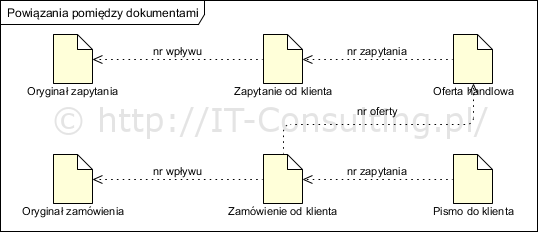
Tu jednak możliwe jest pokazanie jedynie związków jakimi są tak zwane referencje, czyli wzajemne jawne odwołania (np. formularz oferty zawiera pole z numerem zapytania). Pełny model informacyjny można wykonać z użyciem notacji UML:
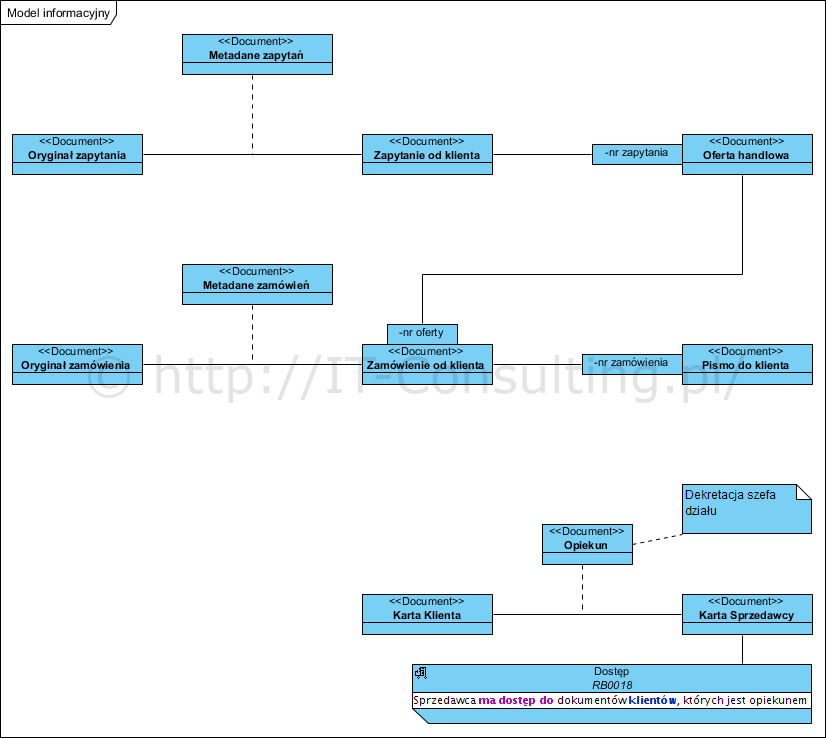
Powyższy diagram to klasy reprezentujące nazwane struktury dokumentów (ich typy) oraz związki logiczne między nimi (asocjacje w UML to nie są trwałe relacje znane z baz danych a jedynie związki semantyczne). Związki te można zobrazować jeżeli są to trwałe (wbudowane w treść) binarne powiązania (związek pomiędzy dwoma klasami). Jednak związki dynamiczne, definiowane przez reguły biznesowe, nie dają się zobrazować dlatego poprzestajemy na wyspecyfikowaniu takiej reguły.
Powyższy diagram mówi nam, że:
- powiązanie pomiędzy oryginałem zapytania (np. jego skan na dysku) a wewnętrznym dokumentem Zapytanie od klienta, jest zawarte w dokumencie (formularz) Metadane zapytań (jest to klasa asocjacyjna UML), który (hipotetyczny szablon byłby w załączeniu) zawiera informacje o położeniu pliku na dysku i przydzielonym mu np. wewnętrznym numerze Zapytania,
- powiązanie pomiędzy Ofertą handlową a Zapytaniem jest wbudowane w Oferty w postaci numeru zapytania, jako jednego z atrybutów dokumentu Oferta (Oferta w swojej treści powołuje się na numer Zapytania, zobrazowano to asocjacją kwalifikowaną UML),
- związek pomiędzy dokumentem a osobą, która ma dostęp do jego treści opisuje reguła biznesowa mówiąca, że “Sprzedawca ma dostęp do dokumentów klientów, których jest opiekunem”, reguła ta została zaimplementowana w postaci dokumentu Opiekun (klasa asocjacyjna UML) , zakładamy że jest to formularz zawierający nazwę klienta i nazwę jego opiekuna (np. udokumentowana decyzja dyr. działu sprzedaży), te dokumenty mogą być w dowolnej chwili zmieniane, dodawane i usuwane.
Jak widać diagram nie zawiera asocjacji pomiędzy Sprzedawcą a dokumentami (dostęp Sprzedawcy do treści danego dokumentu), gdyż ich sensowne zobrazowanie na diagramie jest praktycznie niemożliwe.
Taki diagram zawiera precyzyjne informacje o tym jakie i jak powiązane z sobą informacje przetwarza organizacja. Nie jest to absolutnie coś co należy odwzorować jako model kodu, nie ma tu żadnych liczności klas, bo te także są (potencjalnie zmiennymi) regułami biznesowymi (np. reguła: jeden sprzedawca nie może się opiekować więcej niż dziesięcioma klientami). Nie jest to żaden model danych, struktury formularzy dokumentujemy osobno. Nie jest też powiedziane, że implementacja formularzy to tablice z kolumnami odpowiadającymi polom formularzy (to zresztą bardzo kiepski pomysł).
Pełna dokumentacja powinna zawierać w załączeniu detaliczne struktury tych formularzy (diagramy przedstawiające struktury XML, lub skomentowane mock-up’y dokumentów). Taka specyfikacja zawiera wszystkie informacje pozwalające developerowi stworzyć oprogramowanie służące do zbierania i zarządzania informacją. Jako model wymagań na systemy typu EOD3 jest wystarczająca.
Gdyby było prawdą, że wymagamy od oprogramowania także, by zawartość wybranych pól tych formularzy była wyliczana lub weryfikowana, musimy dodatkowo udokumentować zależności między tymi polami. Model taki często warto uzupełnić wymaganą architekturą oprogramowania, bo od niej zależą cechy jakościowe aplikacji, tak zwane pozafunkcjonalne. Będzie to właśnie model dziedziny systemu, opisywany na moim blogu wielokrotnie.
Poniżej cel i proces budowy modeli pojęciowych :

Zapraszam także do lektury kontynuacji tego zagadnienia w artykule Bazy Dokumentowe.


Dzień dobry, a jak zgodnie ze sztuką powinien zostać zamodelowany szablon, którego pola nie są z góry znane? O tym ile będzie tych pól na szablonie, jaką będą miały nazwę i jakie informacje będą przechowywać (tekst, tekst formatowany, link, lista, załącznik, pdf w formie widoku, grafika, tabela itd.) zdecyduje każdorazowo przyszły użytkownik.
Jeżeli to miał by być model danych relacyjny to nie ma takiej możłiwości (tu musi być wszystko od razu).
Jeżeli szablon (dokument) modelujemy jako agregat (UML, struktury złożone, rozdz. 11) to:
– atrybut jako część (part of) także może być obiektem (strukturą) i można na szablonie umieścić jego abstrakcję zamiast detalicznej struktury (role).
– później zamienić tę abstrakcję na konkrety.
Opis z przykładem tu:
https://it-consulting.pl/autoinstalator/wordpress/2021/05/02/krotka-historia-pewnego-wymagania/