Wprowadzenie
Na temat tak zwanych metod obiektowych często można spotkać teksty takie jak ten z wikipedii:
Programowanie obiektowe (ang. object-oriented programming, OOP) ? paradygmat programowania, w którym programy definiuje się za pomocą obiektów ? elementów łączących stan (czyli dane, nazywane najczęściej polami) i zachowanie (czyli procedury, tu: metody). Obiektowy program komputerowy wyrażony jest jako zbiór takich obiektów, komunikujących się pomiędzy sobą w celu wykonywania zadań. Podejście to różni się od tradycyjnego programowania proceduralnego, gdzie dane i procedury nie są ze sobą bezpośrednio związane. Programowanie obiektowe ma ułatwić pisanie, konserwację i wielokrotne użycie programów lub ich fragmentów
Portal mFiles podaje:
Programowanie obiektowe lub inaczej programowanie zorientowane obiektowo (ang. object-oriented programing, OOP) to paradygmat programowania przy pomocy obiektów posiadających swoje właściwości jak pola (dane, informacje o obiekcie) oraz metody (zachowanie, działania jakie wykonuje obiekt). Programowanie obiektowe polega na definiowaniu obiektów oraz wywoływaniu ich metod, tak aby współdziałały wzajemnie ze sobą. (źr.: Programowanie obiektowe ? Encyklopedia Zarządzania)
Albo takie jak ten ze strony JavaStart:
Programowanie obiektowe jest paradygmatem programowania, który opiera się o tworzenie aplikacji w taki sposób, aby jak najlepiej odzwierciedlać otaczającą nas rzeczywistość i aby model danych oddawał sposób postrzegania świata przez człowieka (czyli, że na przykład że jabłko jest owocem, a nie kolorową kulą). […] Poznasz tu zagadnienia między innymi takie jak klasa, obiekt, interfejs, czy klasa abstrakcyjna i dziedziczenie. (Java – Programowanie Obiektowe | JavaStart)
Bardzo wielu autorów powiela schemat:
Założenia programowania obiektowego
?Abstrakcja
?Hermetyzacja danych (enkapsulacja)
?Dziedziczenie
?PolimorfizmProgramowanie obiektowe zakłada łączenie danych i funkcji w jednym obiekcie.
(wiele materiałów w sieci, na ten temat, podobnie jak i ten, nie zawiera danych autorów ani daty publikacji)
Przykłady z dość powszechnie wykorzystywanych materiałów dydaktycznych:
Abstrakcyjną ideą programowania obiektowego jest powiązanie stanu (danych, które określane są zwykle polami) i zachowania (algorytmy związane ze stanem i całym obiektem, określane słowem metody). Program korzystający z obiektowości wyrażony jest jako zbiór takich obiektów, komunikujących się pomiędzy sobą w celu wykonywania zadań. W pewien sposób jest to najbardziej intuicyjne podejście do rozwiązywania problemów, bo w taki sposób ? traktując zagadnienia jako obiekty wraz ze stanem i metodami; do rozwiązywania problemów podchodzi ludzki mózg. Typy obiektów nazywamy klasami. (źr. TI/Wstęp do programowania obiektowego ? Brain-wiki)
(ten tekst także nie zawiera danych autora ani źródeł)
Programowanie zorientowane obiektowo polega na intuicyjnym, naturalnym pisaniu programów, poprzez modelowanie obiektów świata rzeczywistego, ich atrybutów i zachowań odpowiednikami oprogramowania. Programowanie zorientowane obiektowo modeluje także komunikację pomiędzy obiektami przez wiadomości.
Obiekty mają atrybuty (dane) i wykazują zachowanie (funkcje, metody). Obiekty są elementami oprogramowania do ponownego użycia, tworzone są z ?planów?zwanych klasami. Różne obiekty mogą mieć wiele takich samych atrybutów i podobne zachowania. (źr. dydaktyka.polsl.pl ? kwmimkm )
W programowaniu obiektowym programy definiuje się za pomocą obiektów określających dane rzeczywiste i funkcji na nich operujących. Obiektowy program komputerowy wyrażony jest jako zbiór takich obiektów, komunikujących się między sobą w celu wykonywania określonych zadań.
Dziedziczenie porządkuje i wspomaga polimorfizm i inkapsulację
dzięki umożliwieniu definiowania i tworzenia specjalizowanych obiektów na podstawie bardziej ogólnych. Dla obiektów specjalizowanych nie trzeba redefiniować całej funkcjonalności, lecz tylko tę, której nie ma obiekt ogólniejszy.W typowym przypadku powstają grupy obiektów zwane klasami
oraz grupy klas zwane drzewami. Odzwierciedlają one wspólne cechy
obiektów. Każdy obiekt może (choć nie musi) mieć przodka, od którego się wywodzi. Np. każdy człowiek ma swojego przodka w postaci rodzica.
W zależności od przyjętej metodologii obiekt może mieć jednego lub wielu przodków. O ile może istnieć ograniczenie w postaci jednego przodka, o tyle takiego ograniczenia nie ma co do liczby potomków, których dany obiekt jest przodkiem. Fakt posiadania przodka wiąże się ściśle z dziedziczeniem.Dziecko jako obiekt może dziedziczyć po swoich przodkach
takie atrybuty, jak kolor oczu, wzrost itp. Obiekt może oprócz dziedziczenia atrybutów odziedziczyć metody, czyli ? analogicznie ? w naszym przykładzie dziecko może po swoich przodkach odziedziczyć takie ?metody? (zachowania), jak skłonność do palenia papierosów, talent w wybranych dziedzinach życia, wczesne wstawanie itp. ?(Gryglewicz-Kacerka & Duraj, 2013)?
Ta próbka jest moim zdaniem reprezentatywna, jeśli chodzi o treść publikacji na ten temat. Autorzy tych treści, najczęściej programiści, skupiają się na funkcjach, danych, i tak na prawdę traktują pojęcie “obiektowego paradygmatu” jak kolejne wcielenie strukturalnego kodu, tyle, że wg, innych zasad (obiekt łączący dane i funkcje, dziedziczenie itp.), co jest ogromnym uproszczeniem. Sam fakt zastosowania wymienianych wyżej konstrukcji języków zorientowanych obiektowo nie czyni programu obiektowym, to kolejne wcielenie programowania strukturalnego, gdzie bloki i podprogramy zyskały nazwę obiektów a re-użycie kodu nazwę dziedziczenia. Paradygmat obiektowy to przede wszystkim architektura.
Jednak paradygmat to tylko umowa, pozostaje stosowanie wzorców i dobrych praktyk w toku projektowania.
Największe nieporozumienie
Prawie nikt nie pisze o analizie i projektowaniu zorientowanym obiektowo, a cała idea polega tu na zaczynaniu od analizy i projektowania, potem dopiero się programuje. Nie przypadkiem najpopularniejszym skrótem w literaturze przedmiotu jest OOAD (ang. Object-Oriented Analysis and Design, Obiektowo Zorientowane Analiza i Projektowanie).
Największym, moim zdaniem, nieporozumieniem albo niezrozumieniem, jest utożsamianie oprogramowania z modelem świata. Popatrzmy na poniższy prosty diagram:
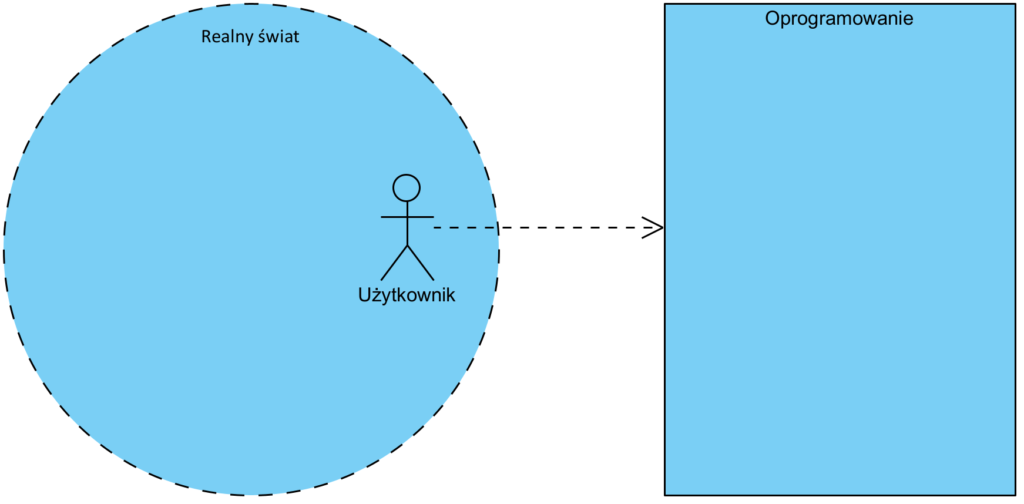
Realny świat . Opisujemy go modelem pojęciowym, który stanowi przestrzeń pojęciową: słownik dla projektu. Jeżeli jest taka potrzeba, tworzymy obiektowy model określonego fragmentu dziedziny, by go lepiej zrozumieć. Np. do poprawnego stworzenia oprogramowania zarządzającego produkcją, może być konieczny model produktu i model hali produkcyjnej, w której jest on produkowany. Powodem jest to, że system MES przetwarza dane o produkcji a nie produkty i nie hale produkcyjną. Największym błędem będzie odtwarzanie tego modelu w oprogramowaniu z użyciem obiektowo zorientowanych języków programowania.
Oprogramowanie przetwarza dane opisujące Realny świat, a nie Realny świat. Oprogramowanie, w większości, to nie gry komputerowe, to systemy zarządzające danymi. Z perspektywy człowieka jest to zarządzanie informacją o świecie a nie światem. Dlatego np. system CRM przechowuje dane o klientach a nie klientów. Warto tu także podkreślić, że jako ludzie, a także maszyny między sobą, komunikujemy sie wymieniając komunikaty, a nie współdzieląc bazy danych.
W konsekwencji projektowania oprogramowania to opracowywanie struktury komunikatów i metod ich przetwarzania, do tego dochodzi opracowanie architektury całości, bo nigdy nie jest to monolit. Projekt oprogramowania to model mechanizmu przetwarzania danych pogrupowanych w odrębne komunikaty, które jako ludzie nazywamy formularzami i dokumentami (patrz artykuł: ICONIX jako zwinny proces projektowania oprogramowania z użyciem UML).
Istotą obiektowego paradygmatu w inżynierii oprogramowania jest to, że model mechanizmu działania jest zarazem projektem systemu!
Paradygmat obiektowy
Pół roku temu w artykule Paradygmat obiektowy i Przypadki Użycia pisałem o paradygmacie obiektowym:
Paradygmat obiektowy, w swej istocie, nawiązuje do teorii systemów: system (analizowany lub projektowany) składa się z współpracujących obiektów. Cechą obiektów jest ich hermetyzacja, która oznacza, że obiekt nie udostępnia (i nie współdzieli) swojej wewnętrznej struktury (implementcji), ma z otoczeniem wyłącznie określone interakcje: wykonywane operacje. Innymi słowy obiekt reaguje w określony sposób na określone bodźce, ignorując wszelkie pozostałe, a zbiór tych bodźców (operacji) nazywamy interfejsem obiektu. Jedynym sposobem pozyskanie informacji o obiekcie jest ?zapytanie go o to?.
Generalnie więc:
Paradygmat obiektowy to przyjęcie zasady: system składa się ze współpracujących i niezależnych obiektów, obiekty cechuje określona odpowiedzialność, współpraca obiektów polega na wzajemnym wywoływaniu (call) operacji w celu uzyskania określonego efektu. Obiekty udostępniają operacje, jest to interfejs publiczny obiektu nazywany także jego kontraktem (odpowiedzialność). Obiekty ukrywają przed otoczeniem swoją wewnętrzną budowę (hermetyzacja) a kontrakt gwarantuje, że ta sama operacja zawsze da ten sam efekt, niezależnie od użytego w danej chwili do jej realizacji algorytmu (metody), co nazywamy polimorfizmem. (patrz także ).
Związek dziedziczenia jest stosowany w obiektowych językach programowania ale nie jest on elementem (cechą) paradygmatu obiektowego jako takiego (został nawet usunięty z notacji UML w 2015 roku patrz UML 2.5). Związek dziedziczenia to sposób re-użycia kodu w językach zorientowanych obiektowo i stanowi sobą łamanie podstawowej cechy obiektów jaką jest niezależność i hermetyzacja (niewspółdzielenie i nie ujawnianie niczego).
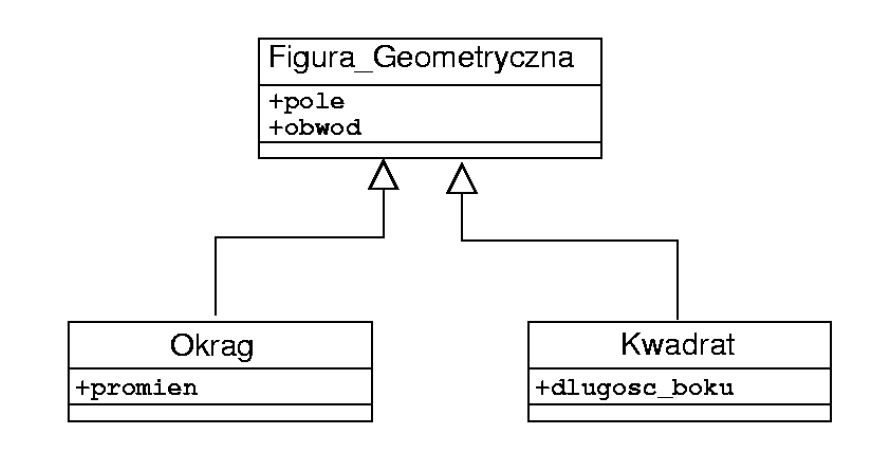
Powyższa konstrukcja jest bardzo łatwa do implementacji w językach zorientowanych obiektowo, jest bardzo często podawana jako przykład, jednak łamie podstawowe cechy paradygmatu obiektowego: niezależność obiektów i hermetyzację. Kod reprezentowany klasą Figura_Geometryczna jest wspólną częścią konstrukcji Okrąg i Kwadrat, w efekcie wszystkie trzy klasy są z sobą ściśle powiązane (zależne od siebie) co przeczy zasadzie projektowania obiektowego zwanej loose coupling (luźne powiązanie).
Kluczową cechą obiektowej architektury systemu jest współpraca hermetycznych i luźno powiązanych obiektów, więc podstawowym związkiem pomiędzy obiektami jest zależność (związek użycia) a nie asocjacja czy kompozycja, bo te to związki strukturalne. Wszystkie obiekty MUSZĄ mieć operacje, bez których nie ma mowy o jakiejkolwiek komunikacji czyli także współpracy. Od lat znany jest antywzorzec obiektowy o nazwie “anemiczny model dziedziny”. Jest to struktura trwale (asocjacje) powiązanych klas (obiektów) pozbawionych operacji ?(Fowler, 2003)?. Taki model, jak ten poniżej, nie jest modelem obiektowym:
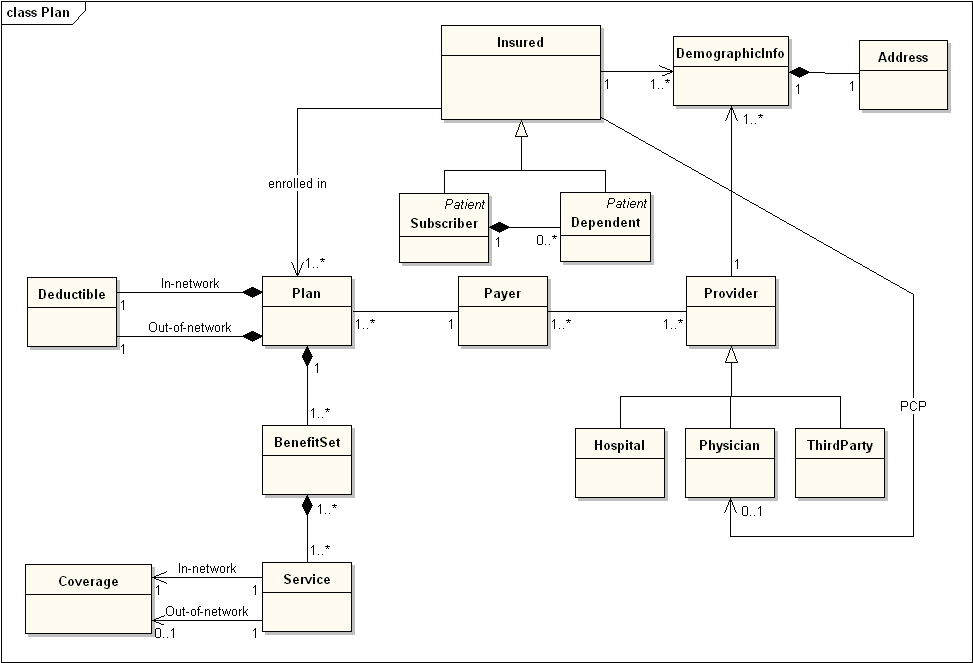
Kluczowe wady powyższego diagramu to: brak operacji i w konsekwencji brak związków użycia, trwałe powiązania oraz dziedziczenie (jego wady opisano wcześniej): te obiekty nie komunikują się w żaden sposób. Diagram zorientowany jest na dane.
Mitem wyrządzającym chyba najwięcej szkód jest teza o modelowaniu danych z użyciem UML (“UML łączy najlepsze cechy: modelowania danych ERD, modelowania czynności DFD., […]”, materiały dydaktyczne: Modelowanie z wykorzystaniem UML, Politechnika Poznańska) oraz teza, że podstawowa idea obiektu to “łączenie danych i funkcji je przetwarzających”. Tu warto wiedzieć, że jednym z podstawowych wzorców projektowych i dobrych praktyk architektury jest separowanie tworzenia elementów informacji, składowania informacji, i przetwarzania informacji (odrębne komponenty: fabryka, repozytorium, usługa) ?(Evans, 2015)?. Atrybuty obiektu to nie są pola bazy danych a stan obiektu to nie aktualna wartość jego wszystkich atrybutów.
Nie mniej wadliwe są często publikowane diagramy przypadków użycia składające się z dużej ich liczby, wielu związków include i extend a nie raz i owego dziedziczenia, ale ten temat już opisałem w artykule Paradygmat obiektowy i Przypadki Użycia (więcej o szkodliwości dziedziczenia: Why inheritance is bad?).
UML: klasa, klasyfikator, obiekt
Modele obiektowe dokumentuje się z użyciem notacji UML (Unified Modeling Notation?*?). Notacja ta nie powstała do dokumentowania kodu (jak piszą niektórzy autorzy) a do dokumentowania wyników analizy i projektowania (OOAD, Object Oriented Analysis and Design, Analiza i Projektowanie Zorientowane Obiektowo). Zostało to opisane w OMG (Object Management Group???) jako proces MDA (Model Driven Architecture???). Kolejność powstawania oprogramowania to: analiza i model biznesowy, decyzja o zakresie projektu czyli wymagania, model logiki systemu (Platform Independent Model) czyli opis rozwiązania i dopiero projekt implementacji (Platform Specific Model). Wszystkie te modele (jeżeli dotyczą tego samego systemu) muszą korzystać z tej samej przestrzeni pojęciowej (jednolity słownik pojęć). Pokazano to poniżej:
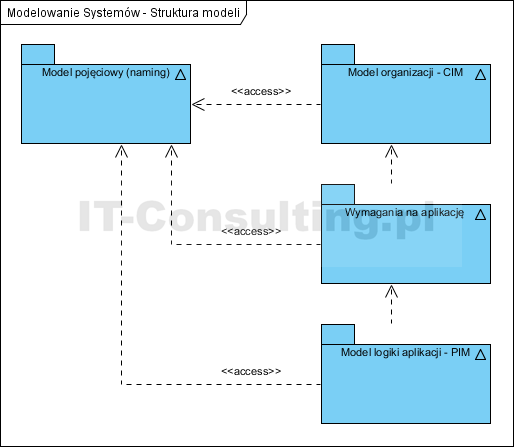
Niektórzy autorzy jednak piszą:
Proces projektowania systemu informatycznego obejmuje następujące główne etapy:
? programowanie (tworzenie kodu programu w wybranym języku programowania),
? opracowywanie dokumentacji (opisywanie wszystkich elementów składowych systemu, zależności zachodzących między nimi, a także opracowywanie szczegółowej instrukcji użytkownika),
? wdrażanie systemu do pracy (jest to proces odpowiedzialny, złożony i długotrwały obejmujący: instalację systemu w miejscu przeznaczenia, uruchamianie, testowanie oraz szkolenie personelu obsługującego system).Projektowanie systemu informatycznego wymaga określenia:
?(Gryglewicz-Kacerka & Duraj, 2013)?
? modelu danych (Data Model),
? interfejsu użytkownika (User Interface, Front-End).
Model danych określa zbiór ogólnych zasad posługiwania się danymi.
Autorzy tu całkowicie pominęli etap analizy i projektowania co przeczy tytułowi tej publikacji: Projektowanie obiektowe systemów informatycznych. Padają tu także słowa o modelu danych, od których paradygmat obiektowy całkowicie abstrahuje.
Notacja UML operuje trzema kluczowymi pojęciami: klasa (nazwa), klasyfikator (znaczenie, definicja obiektów), obiekty (desygnaty, mające tożsamość egzemplarze). Pojęcia te są oparte na tak zwanym trójkącie semiotycznym:

Trójkąt semiotyczny to kontekstowe powiązanie pojęć: znak (słowo), definicja, przedmiot. Określony znak (nazwa) wskazuje (denotuje) przedmiot (używamy nazwy/znaku do wskazania/nazwania przedmiotu). Wszystkie przedmioty zgodne z określonym opisem (desygnaty danej nazwy) można nazwać (oznaczyć) tym słowem (nazwa). Np. “każde stworzenie, które szczeka” (znaczenie/opis) można nazwać słowem “pies” i są to “te wszystkie psy” (konkretne znane nam psy czyli desygnaty słowa pies). W notacji UML “klasa” to pojęcie: “nazwa”, klasyfikator do definicja, a obiekty to desygnaty (instancje klasyfikatora, tu UWAGA: z uwagi na niejednoznaczność pewnych zapisów w UML, instancje – obiekty – ma klasyfikator a nie klasa, klasa to tylko nazwa zbioru).
W modelach pojęciowych używane są związki semantyczne (asocjacja) i definicyjne (generalizacja). Związek generalizacji jest kluczowym narzędziem tworzenia definicji sprawozdawczych (patrz przypis na stronie Słownik pojęć). W notacji UML stosowany jest także związek kompozycji (związek strukturalny całość – część), służy do dokumentowania tak zwanych klasyfikatorów złożonych zwanych także agregatami.
Tak więc projekt obiektowy to udokumentowany zestaw współpracujących w określonym celu obiektów (komponentów). Wymaganym i kluczowym elementem projektu jest słownik pojęć, czyli znaczenia i struktura nazw użytych w tym projekcie (nazwy klas, atrybutów i ich wartości, operacji, parametrów itp.). Jest to tak zwana przestrzeń pojęciowa systemu (słownik, namespace) przedstawiana jako model pojęciowy (taksonomie). Jeżeli dany atrybut przyjmuje skończoną liczbę wartości jako skutków określonych faktów, dokumentujemy to diagramem maszyny stanowej. Kolejnym elementem projektu obiektowego są scenariusze (modele) opisujące współpracę (dynamikę) elementów systemu (obiektów), której efektem są oczekiwane rezultaty (przypadki użycia oraz ich scenariusze, jako diagramy sekwencji UML).
Model obiektowy systemu
Należało by raczej powiedzieć, zorientowany obiektowo lub zgodny z obiektowym paradygmatem. Oznacza to, że struktura systemu (jego model) składa się z samodzielnych obiektów, które razem jako system, realizują określone zadania. System jako taki może być także obiektem, mogącym współpracować z innym systemem. Innymi słowy każdy obiekt sam z siebie jest prostym (atomowym, elementarnym) systemem.
Omówię tu przykład projektu prostej aplikacji. Projekt zostanie udokumentowany z użyciem notacji UML. Pominę etap tworzenia modeli CIM (procesy biznesowe).
Zakres projektu to usługa rejestracji wizyt u weterynarza oraz usługa prezentowania weterynarzom ich podstawowych danych a także terminów wizyt im przyporządkowanych. Zakres udokumentowano z użyciem diagramu przypadków użycia notacji UML.
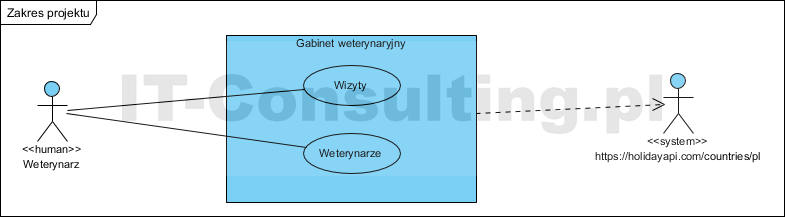
Z aplikacji będą korzystali weterynarze. Aplikacja świadczy dwie usługi: zarządzanie wizytami oraz profile weterynarzy. Można zapisać informacje o planowanych wizytach, karta wizyty będzie zawierała także podstawowe dane przyporządkowanego weterynarza, pobrane z profilu tego weterynarza. Każdy weterynarz będzie prowadził swój profil: podając kluczowe informacje o sobie np. imię, nazwisko, specjalizacja, kontakt do siebie. Będzie także widział swój kalendarz wizyt. Pełny projekt zawierałby detaliczne szablony tych formularzy. W ramach wymagań spisano reguły biznesowe czyli logikę biznesową systemu:
- Wizyty nie mogą być umawiane w dni wolne od pracy
- Weterynarz może mieć tylko jedną zaplanowana wizytę w danym terminie
- Profil określonego weterynarza może edytować wyłącznie on sam
(reguły biznesowe i słownik pojęć, patrz specyfikacja SBVR: Semantics Of Business Vocabulary and Rules?§?). Reguł biznesowych nie dokumentujemy w UML bo nie do tego służy.
Do kontroli pola Data wizyty, zaplanowano sprawdzanie danych o dniach wolnych od pracy w zewnętrznym systemie, udostępniającym dane o dniach wolnych od pracy (na diagramie aktor po prawej stronie, taka sytuacja to nie przypadek użycia! a związek zależności od aktora).
Kluczowa część projektu to analiza pojęciowa i opracowanie modelu pojęciowego czyli słownika pojęć, ich taksonomii i definicji.

Słownik pojęć stanowi podstawowe źródło nazw wszystkich elementów modelu dziedziny systemu. Jak widać słownik to tylko klasy (same nazwy) połączone asocjacjami (związki semantyczne) i związkami generalizacji (łączą pojęcia ogólniejsze i ich typy). Pojęcia ogólne są często kandydatami na nazwy klasyfikatorów (komponentów systemu) i ich atrybutów, typy pojęć (liście taksonomii) są kandydatami na nazwy wartości atrybutów (ich słowniki). To nie jest ani model danych ani model architektury tego systemu!
Zaprojektowano komponent Model (model dziedzinowy) systemu (patrz opis wzorca MVC: Model, View, Controller), jego architektura jest zgodna z opisanym obiektowym paradygmatem i ma cechy dobrej architektury (zasady SOLID). Dla uproszczenia pominąłem na diagramie implementację rejestru weterynarzy).
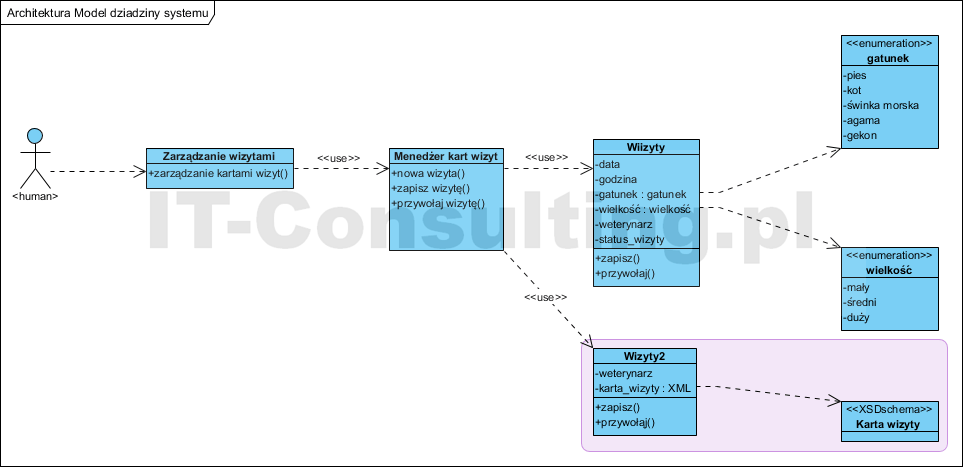
Przedstawiony przykład nie ma poważnej wady architektonicznej (wręcz plagi), polegającej na “wyciąganiu” zawartości atrybutów obiektu serią poleceń Get/Set dla każdego atrybutu. Powoduje to bardzo silnie uzależnienie obiektu pobierającego dane od obiektu będącego ich źródłem (wadę tę opisał dokładnie Fowler we wzorcu DTO. Operacje zapisz i przywołaj powodują zapisanie i przywołanie całej karty wizyty (wszystkich jej danych).
Jak widać mamy pełną hermetyzację komponentów i luźne powiązania między nimi (tylko związki użycia). Oddzielono logikę biznesową od repozytorium. Nie ma tu żadnego dziedziczenia (nie ma go w UML od 2015 roku). Każdy komponent (klasyfikator) ma operacje. Pola gatunek i wielkość mają zdefiniowane słowniki (enumerator). Nazwy te są zdefiniowane w odrębnym modelu pojęciowym (bo do tego on między innymi służy). Model powyższy jest jednak nadal dość “tradycyjny” (przestarzały) bo atrybuty reprezentują poszczególne pola formularzy (od czego się odchodzi!).
Wadą tego “przestarzałego” pomysłu jest to, że każda modyfikacja formularzy będzie wymagała refaktoringu tego systemu (atrybuty klasyfikatorów i metody). Dlatego pokazałem alternatywne nowocześniejsze podejście (różowe tło), w którym klasyfikator Wizyty2 ma identyczny interfejs, nadal odpowiada za przechowywanie informacji o wizytach, ale tu są one – cała karta wizyty – przechowywane jako treść jednego atrybutu: tu w postaci tekstu XML. Dzięki temu zmiana struktury formularza nie będzie wymagała refaktoryzacji, a jedynie wymiany szablonów XML i XSD. Polimorfizm i hermetyzacja pozwoli na wymianę implementacji z Wizyty na Wizyty2 bez konsekwencji dla reszty systemu (klasa Wizyty2 ma identyczny interfejs).
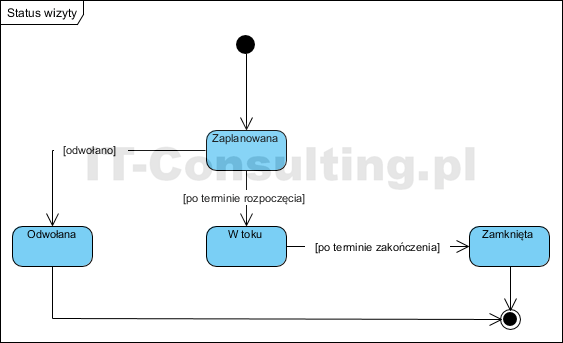
Aktualne wartości atrybutów nie są “stanem obiektu” (kolejny mit). Obiekt Wizyty to repozytorium kart wizyt, stanem (statusem) danej wizyty jest jedna informacja (wartość jednego atrybutu). Wizyta jako taka ma statusy, zmieniają się one automatycznie.
Aby udokumentować przypadek użycia (jego scenariusz) oraz jednocześnie przetestować tę architekturę (udokumentować dynamikę systemu) tworzymy diagram sekwencji.
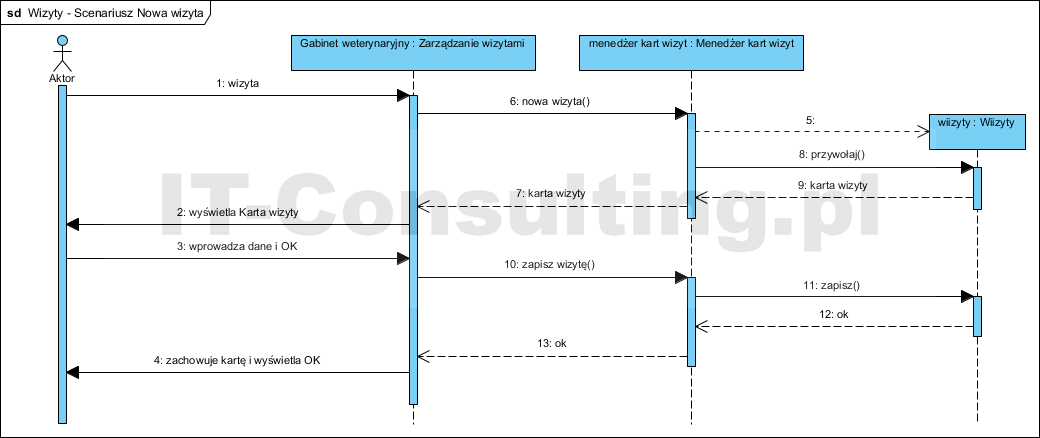
Myślę, że nie wymaga on komentarza. Warto wiedzieć, że używanie do tego celu diagramów aktywności jest mało efektywne, a w UML 2.5 diagramy aktywności są zarezerwowane już wyłącznie do modelowania kodu programu.
Cały projekt ma następującą strukturę:
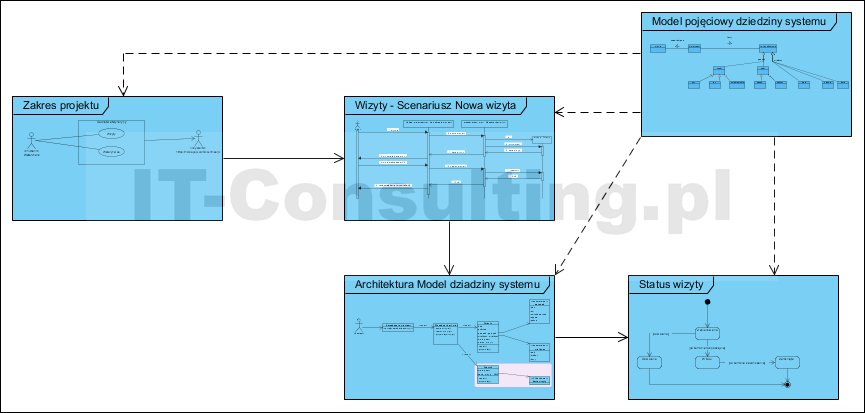
Pełna dokumentacja zawierałaby:
- model pojęciowy (jeden lub kilka diagramów klas),
- jeden diagram przypadków użycia,
- jeden lub więcej (alternatywne) scenariuszy dla każdego przypadku użycia (diagramy sekwencji),
- jeden model dziedziny systemu czyli model architektury komponentu Model dla wzorca MVC (diagram klas, duży system to diagram komponentów, każdy z osobnym modelem swojej wewnętrznej architektury),
- dla każdego obiektu w modelu dziedziny, mającego statusy, model maszyny stanowej opisujący wartości atrybutu reprezentującego stan obiektu (może ich być więcej niż jeden).
- struktury tak zwanych obiektów transferowych czyli struktury danych wymieniane pomiędzy obiektami (agregaty, najczęściej XML).
Do tego bogatszy opis kontekstu, makiety formularzy, pełną specyfikację reguł biznesowych.
Model taki nadaje się (pomijając potrzebę zaprojektowania grafiki i środowiska wykonawczego) do implementacji wprost, stanowi więc bardzo precyzyjne wymaganie.
Korzyści
Najczęściej jako korzyści ze stosowania metod obiektowych wskazywane jest re-użycie kodu, łatwe korzystanie z bibliotek, podział pracy na zespoły. A tak na prawdę kluczową korzyścią są skutki hermetyzacji i polimorfizmu: system podzielony na całkowicie niezależne (hermetyzacja) komponenty i całkowita niezależność od ich wewnętrznej budowy (polimorfizm) powoduje, że rozwój i wprowadzanie zmian dla systemu jest szybkie, łatwe i niemalże pozbawione ryzyka. To jak rower, jeżeli nie jest spawany a złożony ze standardowych elementów łączonych na unormowane zaciski i śrubki (standaryzacja interfejsów), modyfikujemy go w dowolnym momencie, małym nakładem pracy, w miarę zmian naszych potrzeb i nawyków. W 2013 pisałem:
Zasada ?nigdy nie mów nigdy? oznacza, że żaden program nie jest skończony. Innymi słowy powinno być możliwe rozszerzanie jego funkcjonalności bez przebudowy. (czytaj więcej: Plansza do gry w szachy czyli analiza i projektowanie | | Jarosław Żeliński IT-Consulting )
Opisałem tam obiektowy model gry w szachy spełniający powyższą zasadę.
Na zakończenie
Mam nadzieję, że ten artykuł wyjaśni wiele wątpliwości. Wiele różnych przykładowych diagramów można znaleźć w literaturze i w sieci internet. Wiele z nich, mimo że są zgodne z notacją UML, to nie modele obiektowe a strukturalne. Niestety wiele zawiera także błędy notacyjne. Dodam także, co bardzo ważne: specyfikacja UML to nie jest podręcznik analizy i modelowania a tylko specyfikacja notacji. Zawiera poprawne konstrukcje UML ale nie koniecznie są to zawsze dobre wzorce architektury.
Warto wiedzieć, że to co nazywamy paradygmatem obiektowym to aksjomat a nie dogmat. Dlatego notacja UML nie narzuca niczego poza zasadami jej stosowania, jednak jeżeli już piszemy, że nasz projekt jest obiektowy, to musimy (wypadało by) uznać aksjomat: system to współpracujące samodzielne obiekty (a więc uznać konsekwentnie hermetyzację i polimorfizm). Dobre praktyki architektury to już konsekwencje dotyczące cyklu życia systemu, w szczególności kosztu jego utrzymania i rozwoju.
Ciekawostką jest także to, że o opisanych tu zaletach architektury obiektowej pisano już w 1994 roku (i później też nie raz). Wiedza, którą tu prezentuję ma 25 lat:

Na zakończenie powiedzmy sobie wprost: nie ma czegoś takiego jak “obiektowy model danych”!.
Dane to informacje (znaki), które mogą zostać zorganizowane w określone nazwane struktury, one same z siebie nic nie robią. Obiekt to “coś co ma określone zachowanie”, więc określenie “obiektowy model danych” jest pozbawione sensu… Jednym z najbardziej znanych antywzorców obiektowych jest tak zwany ‘anemicznym model dziedziny‘. Jest to model który składa się z klas mających atrybuty, ale niezawierających żadnych metod, co powoduje, że nie jest obiektowy.

Dla mających więcej czasu:
Jak zawsze zachęcam do zadawania pytań…
- ?*?https://www.uml.org
- ???https://www.omg.org
- ???https://www.omg.org/mda/
- ?§?https://www.omg.org/spec/SBVR/About-SBVR/
Cytaty
- Evans, E. (2015). Domain-Driven Design. Zapanuj nad złożonym systemem informatycznym. Gliwice: HELION.
- Fowler, M. (2003). AnemicDomainModel. Retrieved 2019, from martinFowler.com website: https://martinfowler.com/bliki/AnemicDomainModel.html
- Gryglewicz-Kacerka, W., & Duraj, A. (2013). Projektowanie obiektowe systemów informatycznych. Włocławek: Państwowa Wyższa Szkoła Zawodowa we Włocławku.


Na pewnym forum pojawiły sie pytania do tego tekstu, jednak forum jest zamknięte więc moje komentarze publikuje tu:
Kluczowa zasada: model dziedziny to nic innego jak komponenty systemu, skoro hermetyzowane to znaczy, że jako komponent mogą zostać w dowolnym momencie usunięte lub zastąpione czymś innym (polimorfizm) a także zmienione (hermetyzacja). W konsekwencji:
– w modelu architektury logiki systemu z zasady nie ma klas abstrakcyjnych (czegoś “nad nimi”) bo uzależniają od siebie potomne komponenty
– zaspokajanie potrzeb biznesowych użytkowników to cecha hermetycznego komponentu (patrz wyżej) więc implementacja nowej cechy powinna się zamknąć w jednym wybranym komponencie,
– jak słusznie zauważono: nadrzędne klasy abstrakcyjne niszczą hermetyzację (niezależność komponentów) więc w Modelu nie należy ich używać,
– dodanie kolejnego typu (np. zwierzę Tygrys) to nic innego jak rozbudowa słownika, jeżeli to może być częste to nie będzie to (słownik) enumerator o kolekcja (czyli coś co użytkownik może rozbudowywać),
– biorącą pod uwagę fakt, że dziedzinowy słownik jest jeden i dziedzina też (bounded context) mamy także jeden współdzielony walidator, więc dodanie pojęcia słownikowego odbywa sie poza strukturą dokumentów XML (w XSD), w jednym miejscu i nie ma prawa wpływać na historyczne dokumenty,
– klasa pojazd (przykład podany przez forumowicza) jest zawsze nielogiczna, logiczna jest klasa “dane pojazdu”, gdzie typy to nie dziedziczenie a słownik wartości atrybutu “Typ pojazdu”, cechy mechaniczne konstrukcyjne to jeden agregat (kolor, waga silnik itp.) numer rejestracyjny nie jest cechą konstrukcyjna pojazdy a cechą dowodu rejestracyjnego (i umieszczoną w postaci wymienianej tablicy na pojeździe),
– daty rejestracji itp. to nie cechy pojazdy a treść dowodu rejestracyjnego, jeżeli dla użytkownika istotne są inne ekstra cechy np. Forda Mustanga, ale cechy te nie są “przetwarzane automatycznie, to stanowią one treść opisu “prozą” np. jako ostatnie pole XML “inne notatki “..
– poziom modularności zależy wyłącznie od wielkości aplikacji, nie zmienia to faktu że nie powinny one niczego współdzielić (czyli dziedziczenie odpada, zwracam uwagę że zniknęło z UML i nie jest to przypadek)
“? dodanie kolejnego typu (np. zwierzę Tygrys) to nic innego jak rozbudowa słownika, jeżeli to może być częste to nie będzie to (słownik) enumerator o kolekcja (czyli coś co użytkownik może rozbudowywać)”
Nie enumerator, czyli zwykła klasa?
Nie tyle “zwykła” klasa, co zarządzana kolekcja. Enumerator to zamknięty typ, a nie należy ich zmieniać po implementacji. Dlatego dni tygodnia to będzie raczej enumerator, ale już nazwy województw powinny być modyfikowalne. Tu słownik zwierząt, na których zna się weterynarz, powinien być modyfikowalny przez użytkownika.
Jak “zarządzaną kolekcję” pokazać na diagramie klas?
Jako prostą kompozycję: korzeń to klasa stanowiąca narzędzie jej udostępniania i zarządzania nią, ma operacje: dodaj element, usuń element, lista elementów.
Przykład: https://it-consulting.pl/wp-content/uploads/2019/10/managedListUML.png
Dziękuję za wyczerpującą odpowiedź.
Ja myślałem o tym, żeby w modelu pojęciowym pokazać klasę Województwa o stereotypie <>, ale patrząc na ten przykład: widzę, że wchodziłbym już w architekturę.
Dlatego należy bardzo się pilnować i nie mylić modeli pojęciowych dziedziny systemu z modelami architektury systemu. Są to odrębne modele w UML (model pojęciowy zamykamy jako Namespace).
Witam. Jaka rolę pełni komponent “Zarządzanie wizytami” na diagramie dziedziny?
(to jest Model Dziedziny 🙂 ) Obsługuje dialog aktor-system (klasa typu boundary wzorca BCE), realizuje scenariusze tego przypadku użycia (pierwszy element kaskady elementów wzorca Łańcuch odpowiedzialności, opisującego między innymi projektowanie realizacji mikrousług jako implementacji usług aplikacji).
Kluczowy fragment podcastu:
https://youtube.com/clip/UgkxKwfolRQSQKqazb6nFeLgRzbWLcz7Xhvm
Aktualizacja: dodano kilka referatów z YT na końcu artykułu.