Separacja kontekstu dziedziny oraz separacja synonimów jako metoda zapewnienia jednoznaczności modeli obiektowych.
Streszczenie: Przedstawiono metodę pozwalającą zapewnić jednoznaczność modeli obiektowych mimo istnienia synonimów w słownictwie analizowanego problemu. Wykorzystano znaną juz metodę separowania kontekstów, autor proponuje dodatkowy prosty metamodel (profil UML) pozwalający na bezpieczne użycie tego samego pojęcia zarówno jako nazwy obiektu jak i nazwy cechy obiektu.
Słowa kluczowe: UML, profil, metody obiektowe, kontekst
___
Wprowadzenie
Wielu autorów piszących o projektowaniu oprogramowania zwraca uwagę na problemy związane z kontekstem i synonimami pojęć w badanej dziedzinie. Jednym z popularniejszych autorów, zwracających uwagę na to, jest Martin Fowler, autor znany między innymi z książki o wzorcach projektowych w programowaniu obiektowym . Fowler opisał ten problem na swojej stronie internetowej (FOWLER 2014).
W artykule na swoim blogu Fowler opisał przyczynę i konsekwencje, zwrócił uwagę na konieczność separowania kontekstów w procesie projektowania oprogramowania, a konkretnie tak zwanego modelu dziedziny, czyli komponentu odpowiedzialnego za realizację logiki dziedzinowej (zwanej także logiką biznesową), jednak nie opisał rozwiązania.
Autor w tej pracy proponuje metodę rozwiązywania takich problemów opartą na matamodelu rozdzielającym kontekst zarówno dziedzinowy jak i znaczeniowy przetwarzanych informacji.
Metody
Do opisania i rozwiązania problemu wykorzystano analizę pojęciową. Modele pojęciowe, opisujące w postaci graficznej struktury pojęć, ich klas i ich wzajemne związki, zostały zobrazowane z użyciem tak zwanego diagramu faktów notacji SBVR (SBVR, jest to diagram klas UML ograniczony do związków pojęciowych generalizacji i nazwanej kontekstowej asocjacji).
Z uwagi na popularną w inżynierii oprogramowania notację UML (UML), stanowiącą standard de facto w inżynierii oprogramowania, została ona wykorzystania do zaprezentowania efektów prac na schematach blokowych opisujących struktury informacji i oprogramowania.
Język definicje i znaczenia
Na początek kilka definicji ogólnych (wszystkie sł. j. polskiego PWN):
język: utrwalony społecznie zespół znaków dotyczących jakichś działań człowieka lub wyrażających jego emocje oraz każdy układ elementów rzeczywistości, któremu człowiek nadał jakąś treść
Język jest więc określonym zespołem norm, są nimi jednak nie tylko znaki ale także to, co znaczą i jaką treść niosą. Wyrażanie emocji czy myśli w ogóle, rzadko jest możliwe z użyciem tylko jednego znaku. Dlatego w toku ich wyrażania operujemy raczej zdaniami:
zdanie: log. sensowne wyrażenie oznajmiające podlegające falsyfikacji
Tu zaczynamy powoli iść w porządkowanie tego o czym piszę. Każde zdanie (w logice) może być prawdziwe lub nie (tautologia jest zdaniem zawsze prawdziwym, czyli jest znany fakt je falsyfikujący ale wiemy, że nigdy taki nie wystąpi). Jeżeli więc, że treść najczęściej wyrażamy słowami (a raczej rzadko nie jednym słowem) to znaczy, że należy umieć odczytać znaczenie złożenia wielu słów w jednym zdaniu. Jak wiemy o zrozumiałości (zrozumiałość oznacza, że zdanie ma dla czytającego określone znaczenie) decyduje układ słów w zdaniu, znaki interpunkcyjne itp.
Jednoznaczność (zrozumiałość, znaczenie) zdań jest także efektem kontekstu:
kontekst: fragment tekstu potrzebny do dokładnego rozumienia danych wyrazów lub wyrażeń
Jeżeli napiszę ?Te dwie krowy są paskudne? to nadal nie ma pewności o czym mowa. Bez wiedzy o tym, czy to rozmowa dwóch rolników o inwentarzu, czy też dwóch koleżanek o dwóch innych, nie wiemy .
Kluczowe pojęcia
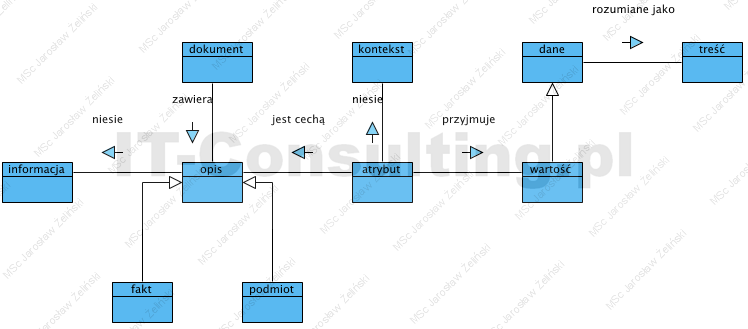
Opracowano model pojęciowy. Model ten pozwala uporządkować nazewnictwo wykorzystane do klasyfikacji obiektów w systemach.
Oprogramowanie to system przetwarzający dane, te mogą nieść określone informacje. Dane to zapisane znaki (wartości), służą do stworzenia opisu (description), ten zaś niesie informacje. Treść to to, co te znaki (dane) znaczą czyli to co rozumie człowiek. W oprogramowaniu dane są organizowane w określone struktury, które jako opis opisują określony fakt (fact) lub podmiot (subject). Opis to określony zestaw atrybutów i ich wartości. Znaczenie atrybutu nadaje mu kontekst.
Kluczowym ustaleniem jest tu pojęcie dokument (document) jako nazwana struktura zawierająca opis lub opisy. Oprogramowanie przechowuje dokumenty i przetwarza ich treść.
Profil UML

Profilowanie w notacji UML to metoda pozwalająca rozszerzyć metaklasy notacji UML w celu dostosowania ich do różnych celów. Obejmuje ono możliwość dostosowania metamodelu UML dla różnych platform (takich jak J2EE lub .NET) lub domen (takich jak architektura czasu rzeczywistego lub architektura zorientowana na usługi) (patrz UML).
W tym przypadku stworzono zestaw stereotypów (typów klas) pozwalających dodatkowo klasyfikować elementy na modelach UML, nadając im określony kontekst i znaczenie. Użyto tu nazw opisanych powyżej w części Kluczowe pojęcia. Package i class to pojęcia z notacji UML oznaczające określone elementy na diagramach.
Rezultaty
Efektem prac jest metoda modelowania struktur dokumentów (informacji) w sposób pozwalający przetwarzać je w łatwy do interpretacji sposób, dzieląc dokument na spójne kontekstowe sekcje lub klasyfikując cały dokument jako jedną kontekstową sekcję.
Dokument i jego struktura
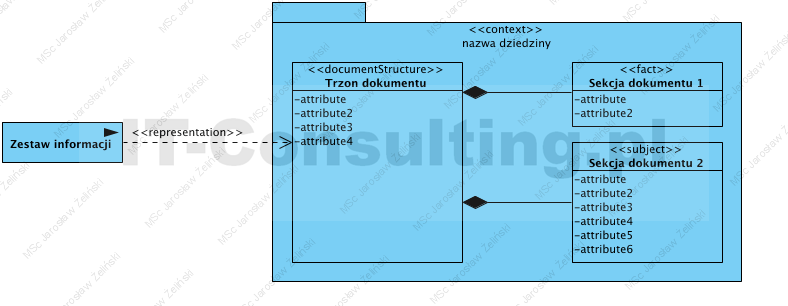
Istotą strukturyzacji kontekstowej jest rozwiązywanie problemów jakie stwarzają interpretacje zależne od dziedziny i kontekstu. Jak już napisano, Dokument i jego ewentualne sekcje niosą dane, te podlegają interpretacji zależnej od kontaktu. Kontekst ma tu dwa poziomy: znaczenie pojęć, zgodnie z semiotyką, nadaje im dziedzina zaś znaczenie pojęcia w rozumieniu jest ono nazwą obiektu lub jego atrybutu, nadaje mi położenie w strukturze.
Fowler Problem zmiany kontekstu
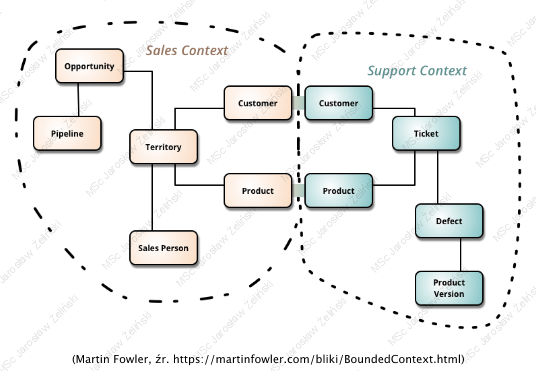
Fowler pisze na swoim blogu: “Podczas próby modelowania większej domeny coraz trudniej jest zbudować pojedynczy zunifikowany model. Różne grupy ludzi będą używać subtelnie różnych słowników w różnych częściach dużej organizacji. Brak precyzji modelowania szybko prowadzi do wielu nieporozumień. Zazwyczaj to zamieszanie koncentruje się na kluczowych pojęciach danej domeny. Na początku mojej kariery pracowałem w branży narzędzi elektrycznych – tutaj słowo ?licznik? oznaczało różne rzeczy w różnych obszarach organizacji: raz było to połączenie między siecią a lokalizacją, raz siecią i klientem, innym razem było konkretnym miernikiem fizycznym (wymienianym w razie uszkodzenia). Te subtelne różnice znaczeń nie szkodzą w rozmowie, ale w precyzyjnym świecie programów komputerów tak. Raz po raz widzę, że to zamieszanie powtarza się w przypadku problemów z pojęciami ?Klient? i ?Produkt?.”
Opis ten i powyższy schemat, zawierający skojarzone z sobą pojęcia, są typowym przykładem problemu zapisu informacji z wielu dziedzin. Po lewej stronie mamy kontekst sprzedaży produktów po prawej kontakt obsługi zgłoszeń uszkodzeń. Problematyczne pojęcia to Klient (Customer) i Produkt (Product) oraz Zgłoszenie (Ticket): w obu kontekstach mają inne znaczenie: w kontekście sprzedaży Klient i produkt to odrębne, mające tożsamość obiekty, w kontekście zgłoszeń uszkodzeń obiektem jest Zgłoszenie (Ticket) a Klient i Produkt sa wartościami atrybutów Zgłoszenia. W tym drugim przypadku są to nie mające tożsamości wartości atrybutów nazywane Value Object . W konsekwencji nie jest możliwe umieszczenie tych danych w jednej relacyjnej bazie danych.
Fowler wskazuje jako rozwiązanie rozdzielenie tych dwóch, stanowiących różne konteksty, obszarów dziedzinowych, jednak nie opisuje tego rozwiązania. Inna ciekawa forma zobrazowania problemu:
Jeden model dwa konteksty

Diagram przedstawia obiekty biznesowe – dokumenty (<<document>>) pochodzące z dwóch różnych kontaktów. Na schemacie mamy trzy klasyfikatory reprezentujące dokumenty i ich struktury. W celu usunięcia kolizji pojęć opisanej przez Fowlera (FOWLER 2014) obiekty funkcjonujące w dwóch różnych kontaktach zostały rozdzielone na dwie kontekstowe przestrzenie pojęciowe: Sprzedaż oraz Serwis. W kontekście Sprzedaż pojęcia Klient i Produkt zostały użyte do nazwania obiektów biznesowych będących przedmiotami mającymi tożsamość. W kontekście Serwis pojęcia te (klient i produkt) ca jedynie cechami (atrybutami) obiektu biznesowego Uszkodzenie, słowa te (pojęcia) stanowią jedynie nazwy atrybutów a konkretne nazwy klienta i produktu stanowią wartość tych atrybutów i jako obiekty nie mają tu tożsamości (value UML i value object w DDD).
Tak więc problem kolizji nazewnictwa została rozwiązany, warto tu zwrócić, że zbudowanie jednej spójnej relacyjnej bazy danych dla wszystkich pojęć obu tych dziedzin jest niemożliwe bez dodatkowych zabiegów z nazewnictwem.
Dalsze Badania
Opisane zagadnienia stanowią materiał dalszych badań w obszarze tworzenie generalizacji modelu danych opartego na dokumencie i jego strukturze i wykorzystaniu tej metody do modelowania danych i metamodeli dokumentów jak określonych struktur infomacji.