Wprowadzenie
Napisałem o orientacji na dokumenty w toku analiz:
Często jestem i ja pytany o to ??Jak wyjaśnić złożone rozwiązanie techniczne interesariuszom nietechnicznym?? Jak wielu mi podobnych odpowiadam: rozmawiaj dokumentami. Sponsor projektu, przyszli użytkownicy, postrzegają swoją pracę poprzez dokumenty: ich treść i układ. (Wymagania na formularze czyli diagramy struktur złożonych i XML)
Dzisiaj pójdziemy dalej, omówimy to gdzie i jak zachować tę informację. Posłużę się prostym przykładem przychodni weterynaryjnej. Artykuł będzie opisem metody podejścia do analizy zorientowanej na procesy i dokumenty.
Tekst ma dwie części: pierwsza jest opisem drogi jaka prowadzi nas do zdefiniowania tego jakie dokumenty, jaką mają (mieć) zawartość i strukturę. Praktycznie jest to opis analizy i projektowania. Druga – krótka – to przykładowa architektura logiki realizacji aplikacji, pokazująca miejsce dokumentowej bazy danych w architekturze i projekcie, czyli także projektowanie.
Celem tego wpisu jest pokazanie czym może być analiza oraz jej produkt jakim jest Techniczny Projekt Oprogramowania.
Przychodnia weterynarzy – analiza
Mam nadzieję, że to jak działa przychodnia weterynaryjna (Przychodnia), czytelnik jest w stanie sobie wyobrazić. Jeżeli nie, polecam lekturę regulaminu jakiejkolwiek tego typu przychodni, np. ten Regulamin. Ale od razu zaznaczam, że w przypadku realnego projektu należy od tego zacząć. Wywiady z pracownikami nie mają większego sensu, często wprowadzają w błąd. Analizę należy zacząć od analizy faktów czyli od zebrania partii przykładowych kart wizyt, regulaminów i zarządzeń, możliwe, że jest prawo regulujące tego typu usługi (a tu jest, parz USTAWA z dnia 18 grudnia 2003 r. o zakładach leczniczych dla zwierząt).
Model procesu opisującego podstawową działalność przychodni wygląda tak:

Zgłoszenie się pacjenta powoduje wystawienie Karty Wizyty, która jako planowana wizyta w przyszłości, stanowi sobą rezerwację terminu. Od tego momentu “zegar tyka”.
Jeżeli w Przychodni pojawi się Opiekun zwierzęcia, realizowana jest standardowa porada weterynaryjna. Jeżeli ktoś zgłosi odwołanie wizyty zostanie ona odwołana (ale jako dokument Karta Wizyty pozostanie w systemie ze statusem ‘odwołana’).
Zwracam uwagę, że zmiana terminu wizyty to odwołanie planowanej wizyty i nowa rezerwacja (takie podejście znakomicie upraszcza cały system, a dodatkowo zyskujemy dane do ewentualnych statystyk rzetelności klientów).
Zapewne większość biznesu (praca na user story, wywiady itp.) będzie oczekiwała możliwości edytowania Kart Wizyt i jest to własnie najgorsze rozwiązanie. To dlatego nie słucham pomysłów klientów na system, oczekuję wyłącznie opisu celu danej aktywności, a ta brzmi (powinna) raczej “chciał bym mieć możliwość przełożenia wizyty”, a nie “chce mieć możliwość edycji pola ‘termin wizyty'”. Jeżeli termin wizyty nadejdzie a opiekun sie nie pojawi, wizyta zostanie oznaczona statusem ‘zignorowana’.
Z uwagi na to, że nie umieszczamy na analitycznych modelach procesów biznesowych, opisów wypełniania formularzy czy detalicznych procedur, konieczny jest szablon dokumentu skojarzony z elementem Karta Wizyty (BPMN: DataObject). Jak już wspominałem w innym artykule, można do tego celu zastosować notację UML i diagram struktur złożonych (a dla użytkowników oprogramowania CASE jest to rekomendacja):
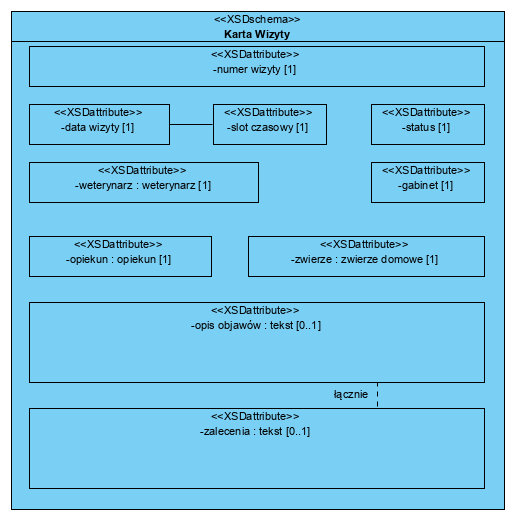
Taka forma dokumentowania ma dwie podstawowe zalety: jest zrozumiała dla zamawiającego oraz stanowi poprawny diagram klas, użyteczny na dalszych etapach analizy i projektowania.
Powyższy formularz jest także najlepszym miejscem do pokazywania i realizacji wymagań biznesowych. Np. wymaganie “System powinien pozwalać na generowanie statyk rzetelności klientów” skutkuje polem status oraz słownikiem (w dalszej części) wartości tego pola (będzie zawierał między innymi wartość ‘zignorowana’). Tu ważna informacja:
to analityk projektant, a nie developer, ma zagwarantować (jeżeli planowane jest oprogramowanie dedykowane) realizację wymagań funkcjonalnych!
Powyższy formularz Karta Wizyty na “tradycyjnym” diagramie klas, wzbogaconym o typy danych wygląda tak:
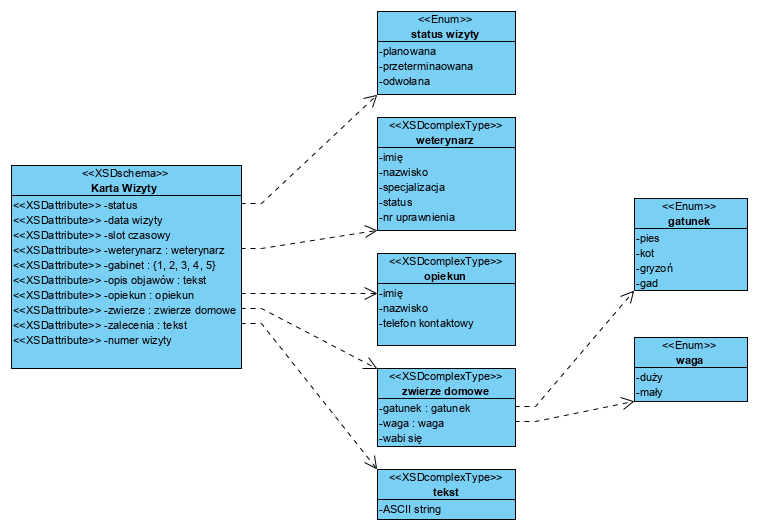
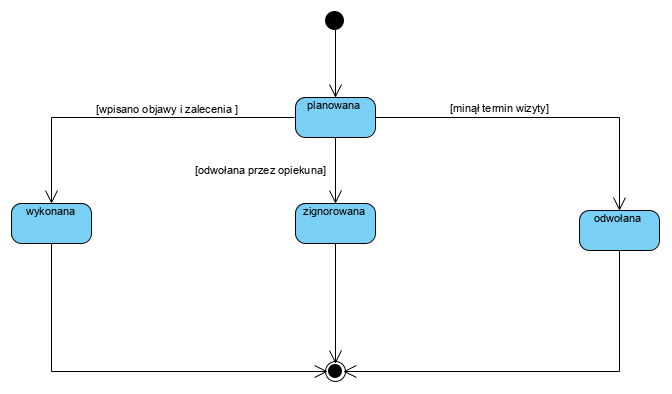
Tu jest miejsce na definiowanie typów zawartości atrybutów. Osobiście jestem gorącym zwolennikiem stosowania atrybutów ‘string’ (tekst ASCII) i definiowania struktur typów złożonych, co daje całkowitą niezależność od platformy implementacji i jednocześnie 100% panowanie nad logiką realizowaną w aplikacji. Atrybut ‘status’ opisujemy modelem maszyny stanowej UML:
Logikę biznesową definiujemy jako reguły biznesowe, np.:
zestaw danych ‘data wizyty’, ‘slot czasowy’, ‘weterynarz’ i ‘gabinet’, musi być unikalny
(można też taki zestaw nazwać i modelować jako samodzielny typ strukturalny, co pewnie było by bardziej eleganckie). Generalnie wszystkie nazwy dokumentów, atrybutów i ich wartości, powinny być zebrane w jednolitym słowniku pojęć. Bazując na tych (słownikowych) pojęciach budujemy reguły biznesowe jak wyżej (patrz: SBVR). Dzięki temu cała logika jest kompletna, spójna, niesprzeczna. Słownik pojęciowy dobrze jest opracować (przy najmniej jego kluczową część) jako model, co pozwoli testować go na okoliczność spójności i niesprzeczności:
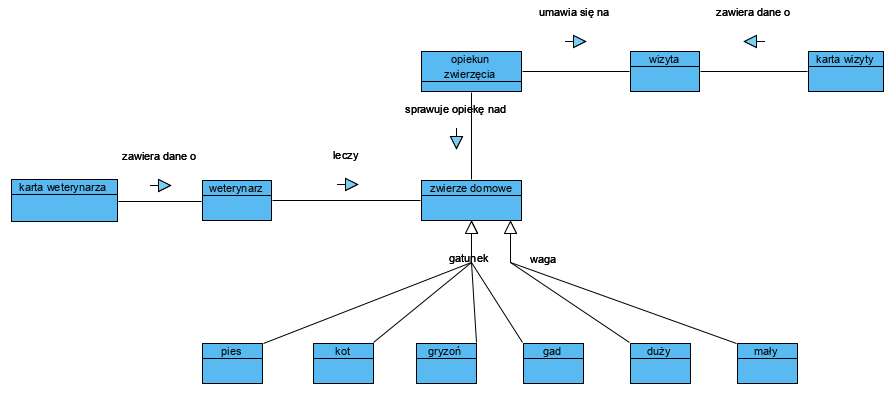
Tu ważna uwaga: to (powyższy diagram) nie jest żaden model dziedziny systemu! To “namespace” (przestrzeń pojęciowa) wyrażona jako taksonomie pojęć. Służy ona to definiowania nazw atrybutów i ich wartości na modelach struktur dokumentów. Np. ‘zwierze domowe’ to atrybut Karty Wizyty, a jego specjalizacje to materiał na słownik wartości tego atrybutu: tu potencjalnie mamy dwa atrybuty: ‘gatunek’ i ‘waga’ (patrz diagram Struktura Karty Wizyty i typów atrybutów), specjalizacje tych pojęć to materiał na wartości tych atrybutów. Model pojęciowy to element modelu CIM. Jest to najważniejszy etap projektu. Z zasady jest to pierwszy etap, tu wspominam o nim dopiero teraz, by pokazać źródło nazw atrybutów i ich wartości .
Jak bezpiecznie realizować zmianę terminu lub anulowanie wizyty? Procedura anulowania wizyty:
| 1. identyfikacja karty wizyty (numer wizyty) |
| 2. anulowanie wizyty (zmiana statusu) |
Nie chcemy np. przez telefon żądać danych osobowych, w samym gabinecie żądać dowodów tożsamości. Sprawdzonym rozwiązaniem jest stosowanie długiego losowego unikalnego numeru Karty Wizyty (atrybut ‘numer wizyty’). Dzięki temu staje się on niejako hasłem/kodem, które zna wyłącznie Przychodnia i Opiekun (dowiaduje się o nim w momencie rezerwacji).
Zakres projektu i projekt
Przypadki użycia to usługi aplikacji, nie są to ani procesy ani aktywności! Dlatego tu diagram ten wygląda tak:
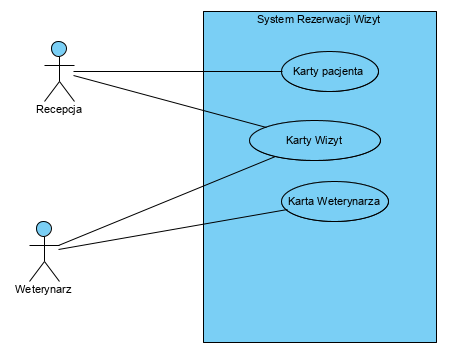
Jak widać, są tu trzy przypadki użycia, ten artykuł jest, z racji objętości, fragmentem większej całości. Generalnie przypadki użycia, jako usługi aplikacji, oferują wsparcie dla aktora np. pracownik recepcji (znający procedury) korzysta z usługi (opcja menu aplikacji) Karty Wizyt. Wszystkie aktywności w opisanym procesie są realizowane z użyciem tej samej usługi aplikacji!
Przypadki użycia dokumentujemy z pomocą scenariuszy. Kolejna rekomendacja: zamiast rozbudowanych scenariuszy z alternatywnymi krokami, znacznie lepszym rozwiązanie jest budowanie prostych scenariuszy alterntywnych:
| 1. Recepcja inicjuje Karty Wizyt |
| 2. SYSTEM wyświetla formularz Karta Wizyty |
| 3. Recepcja wprowadza dane do formularza Karta Wizyty i naciska Zapisz (reguła: Duplikowanie wizyt) |
| 4. SYSTEM wyświetla Karta Wizyty i ewentualne komunikaty |
zaś drugi scenariusz:
| 1. Recepcja inicjuje Karty Wizyt |
| 2. SYSTEM wyświetla formularz Karta Wizyty |
| 3. Recepcja wprowadza dane do pola numer wizyty formularza Karta Wizyty i naciska Szukaj |
| 4. SYSTEM wyświetla wypełniony formularz Karta Wizyty lub komunika o braku karty |
| 5. Recepcja zmienia status formularza Karta Wizyty i naciska Zapisz |
| 6. SYSTEM wyświetla zachowany formularz Karta Wizyty i ewentualne komunikaty |
Dzięki temu scenariusze są łatwe do zrozumienia i implementacji, łatwe do zmian w przyszłości (nie są od siebie zależne). W scenariuszach należy używać nazw z diagramów (nazwy aktorów, formularzy i ich atrybutów) i słownika (patrz także Dokumentowanie Przypadków Użycia)
Ostatecznie architektura realizacji tej usługi, jako model dziedziny (komponent Model we wzorcu MVC) ma postać (wykorzystano wzorzec projektowy BCE, można użyć także DDD, ):
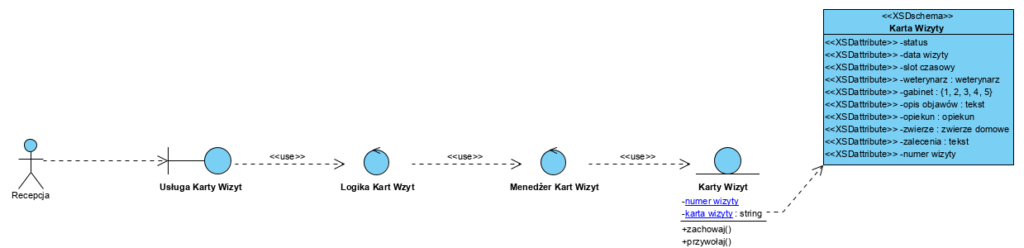
Jest to architektura realizacji pojedynczej usługi aplikacyjnej (przypadku użycia). Była na tym blogu nie raz opisywana (np. https://it-consulting.pl//2019/10/22/generator-ofert-komentarze/).
I teraz najważniejsze: repozytorium Karty Wizyt to właśnie dokumentowa baza danych. Cała Karta Wizyty jest wartością jednego atrybutu ‘karta wizyty’ klasy ‘Karty Wizyt’. Pozostałe atrybuty tej klasy (tu jeden) służą wyłącznie do obsługi wyszukiwania dokumentów i jak najbardziej mogą to być (nie muszą) powtórzone elementy treści tego dokumentu.
Gdybym doprowadził powyższy model do końca (będzie to kolejny artykuł), był by to właśnie Model Dziedziny aplikacji w rozumieniu wzorca MVC.
Podsumowanie
Dokumentowe bazy danych mają wiele zalet (np. wydajność) ale zaletą, która czyni jest na prawdę “hitem” jest możliwość całkowitej rezygnacji z modelu relacyjnego i języka SQL, co w efekcie daje ogromne uproszczenie implementacji. “Wyciągnięcie” z repozytorium nawet bardzo skomplikowanego strukturalnie dokumentu, realizujemy tu jednym bardzo prostym poleceniem. Identyczna operacja w modelu relacyjnym będzie wymagała nie raz monstrualnego, trudnego do testowania, zapytania SQL.
Bazy dokumentowe “nie boją się redundancji”, więc zmiany atrybutów nie przeniosą się na inne dokumenty. Architektura jak wyżej, jest całkowicie odporna na zmieniające się struktury kolejnych egzemplarzy dokumentów. Cała logika ich walidacji jest poza repozytorium. Repozytoria są w 100% hermetyzowane, żadne informacje nie są współdzielone między dokumentami (dlatego też ewentualna modyfikacja jednego dokumentu nigdy nie przeniesie sie na inne). Posłużyłem się formatem XML jako przykładem, ale nie musi tak być, bardzo często wykorzystywany jest JSON, ale te detale to decyzja developera w toku implementacji. Model ten także doskonale wpisuje się w środowiska chmurowe takie jak AWS czy AZURE (można także wykorzystać repozytoria obiektowe).
Implementacja wyżej opisanej architektury jest bardzo łatwa w postaci mikroserwisów. Całość projektu spełnia zasady OCP (Open Close Principle, system jest otwarty na rozszerzenia i zamknięty na zmiany).
Kiedy bazy SQL? Hurtownie Danych, BigData i wiele podobnych wymagających przetwarzania danych a nie tylko archiwizowania. Wszędzie tam, gdzie taka potrzeba sie pojawia, efektywnym rozwiązaniem jest hurtownia danych i proces ETL pobierający dane z bazy dokumentowej, lub architektura oparta na wzorcach CQRS/Event Sourcing.
A to co tu opisano to standardowy proces analizy i projektowania MDA/MDE. Powstaje najpierw model CIM, potem PIM. A całość jako Opis Techniczny Oprogramowania jest chronionym know-how, jego implementacja jest dziełem zależnym. Wartości intelektualne zamawiającego są w 100% chronione, bo developer nie ma żadnych praw do implementacji jaką wykonał (ma prawa autorskie osobiste a nie majątkowe).
Chcesz wiedzieć dlaczego tak, zapoznaj się z opisem



obszerna prezentacja na temat baz dokumentowych: http://staff.uz.zgora.pl/agramack/files/BazyDanych/NoSQL/NoSQL.pdf
Czy w modelu maszyny UML opisujący status wizyty, dopisek [odwołana przez opiekuna] nie powinien być po prawej stronie diagramu przy statusie odwołana a nie przy zignorowana ? Wydaję sie ze wizyta zignorowana to wizyta przeterminowana bez próby kontaktu ze strony klienta czyli nie odwołana i nie zrealizowana.
Tak, faktycznie 🙂