Wprowadzenie
Bardzo wiele problemów w toku wdrożeń IT rodzą wadliwie zaprojektowane struktury dokumentów. Dotyczy to w szczególności zarządzania dostępem do treści, a patrząc szerzej: do informacji. Ostatnie lata to między innymi problemy urzędów z udzielaniem dostępu do informacji publicznej, od dwóch lat dodatkowo problemy stwarza RODO. Źródłem problemów jest treść dokumentów, rozumiana jako pytanie: “Czy te informacje muszą być zawarte w tym dokumencie”. Najpierw opiszę mechanizm powstawania przyczyn problemów i sposób ich rozwiązania. W podsumowaniu wskażę jak i gdzie sobie z tym radzić.
Struktury treści dokumentów
Po pewnym dość dużym projekcie, mającym w zakresie także ochronę kno-how, napisałem :
Każdy projekt, czy to wdrożenie nowych zasad zarządzania czy nowego oprogramowania, związany z zarządzaniem organizacją, to (powinien być) także co najmniej przegląd dokumentów i ich obiegu. Kluczowym elementem tego przeglądu powinna być analiza treści tych dokumentów, ich optymalność, nie tylko ich obiegu ale także treści i jej struktury. Owszem, wiele dokumentów ma narzuconą strukturę np. w ustawie, jednak są to minimalne zawartości (np. faktura VAT), nie ma jednak zakazu uzupełnienia tej struktury i np. dodania do faktury numeru zamówienia, z którym jest związana (co umożliwia skojarzenie tych dokumentów ze sobą).
Ogólnie można określić pewne prawidłowości: jeżeli dokumenty są przeciążane treścią, czyli idziemy w kierunku małej ilości dokumentów zawierających dużo danych, rośnie złożoność reguł pracy z takim dokumentem. Jeżeli zaś idziemy w kierunku dokumentów ??bardzo prostych?, rośnie ilość ich typów i rośnie liczba reguł kojarzących te dokumenty ze sobą w celu ich użycia. (Dokumenty czy niedokumenty…. czyli zarządzanie informacją i jej standaryzacja)
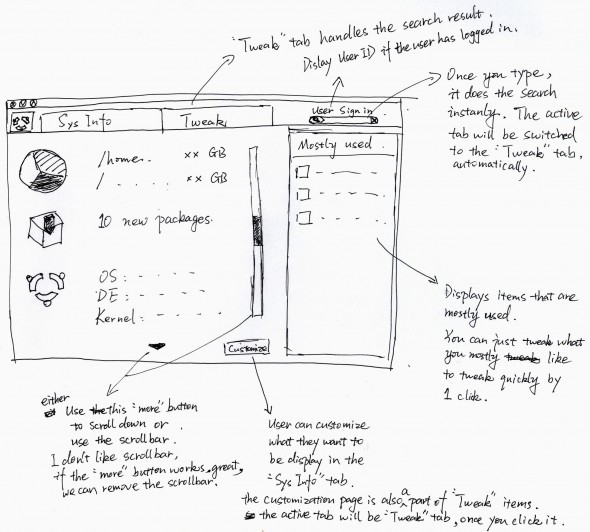
Dlatego bardzo ważną częścią projektu jest opracowanie polityki zarządzania informacją. Jednym z kluczowych jej elementów są szablony struktur dokumentów, bo tu właśnie realizowane są wymagania biznesowe :
Powyższy formularz jest także najlepszym miejscem do pokazywania miejsca realizacji wymagań biznesowych. Np. wymaganie ??System powinien pozwalać na generowanie statystyk rzetelności klientów? skutkuje polem status oraz słownikiem (w dalszej części) wartości tego pola (będzie zawierał między innymi wartość ?zignorowana?). Tu ważna informacja: to analityk projektant, a nie developer, ma zagwarantować (jeżeli planowane jest oprogramowanie dedykowane) realizację wymagań funkcjonalnych! (Projekt aplikacji czyli bazy dokumentowe)
Kontrola dostępu do treści
Jednym z głównych problemów ochrony danych osobowych oraz ochrony know-how są przeciążone treścią dokumenty. Niestety, w toku wymiany dokumentów między podmiotami, nie zawsze jest możliwe “gumkowanie” ich fragmentów. Problem bywa poważny, gdy chodzi o ochronę danych osobowych i dostęp do informacji publicznej. Dlatego bardzo ważne jest, by w specyfikacji wymagań pojawiły się Wymagania na formularze (o czym pisałem wcześniej). Jest to element polityki zarządzania informacją w organizacji (Dokumenty czy niedokumenty…. czyli zarządzanie informacją i jej standaryzacja).
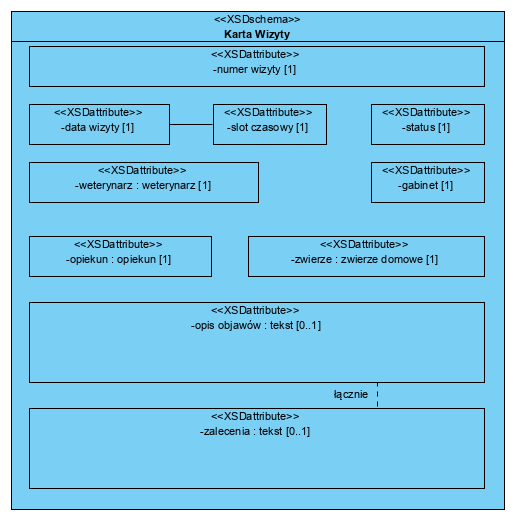
Budowanie polityk dostępu do treści jest znacznie prostsze na poziomie dokumentów niż ich pól: zamiast tworzyć odrębne reguły dla poszczególnych pól dokumentów, tworzymy nowy dokument o zmienionej strukturze (zawartości informacji) i tworzymy reguły dostępu dla całego dokumentu (określona nazwa takiej struktury to klasa dokumentów).
Dokumenty znane nam od lat (umowy, zamówienia, faktury, wydania z magazynów, itp.) często intuicyjnie były tworzone jako dedykowane odrębne zestawy redundantnych danych np. faktura zawierająca dane o cenach produktów i niemalże bliźniaczy dokument, jakim jest zlecenie wydania sprzedanego towaru z magazynu, niezawierającego cen, co pozwala zlecić magazynierom dokonanie operacji bez informowania ich o cenach transakcyjnych towarów (w wielu firmach ceny stanowią chronioną informacje handlową). Dlatego warto stosować zasadę utrzymania jednego kontekstu dla dokumentu: faktura ma kontekst finansowo-księgowy a dokumenty magazynowe mają kontekst ilościowy, bardzo często mają innych adresatów.
Ogromnym problemem, są wdrożenia systemów ERP nie respektujących zasady rozdzielenia kontekstów treści dokumentów! Jeżeli wewnętrzna integracja w systemie ERP polega na współdzieleniu danych w oparciu o relacyjny ich model, będzie to niemożliwe do zrealizowania.
Forma dokumentowa organizacji danych służy wyłącznie do zarządzania treścią i danymi, dlatego wszelkie obliczenia i statystyki prowadzone są z pomocą kopii danych zorganizowanych inaczej, np. w Hurtowniach Danych lub systemach typu Business Intelligence.
Opisana metoda organizacji informacji (opracowywanie dedykowanych, kontekstowych szablonów dokumentów) została z powodzeniem przeze mnie wykorzystana do projektowania i wdrażania oprogramowania dla administracji publicznej i dla przemysłu (ten fragment to cytat z mojej publikacji naukowej, w przygotowaniu, na temat zarządzania treścią).
Prawie zawsze obserwuję, że podstawowym domyślnym założeniem wdrożeń systemów wspomagających zarządzanie, jest uznanie a priori niezmienności struktury i wzorów istniejących dokumentów. Co jest poważnym błędem.
Z doświadczenia mogę powiedzieć, że analiza i optymalizacja treści dokumentów wewnętrznych może przynieść bardzo duże korzyści przekładające się na duży wzrost wewnętrznej efektywności i jakości pracy, a w przypadku wdrożeń oprogramowania wspomagającego zarządzanie, pozwala nie raz całkowicie uniknąć bardzo kosztownych i ryzykownych kastomizacji. Zaryzykuje tezę, że kilka projektów w ten sposób wręcz uratowałem?
Projektowanie struktury dokumentu
Kluczowym elementem opisu organizacji jest jej model informacyjny.
Generalnie informacje są organizowane w nazwane struktury czyli dokumenty. Tu ważna uwaga: ludzie w procesie komunikacji zawsze operują informacją o określonej strukturze, bywa, że jest ona ? struktura ? prosta, strukturą jest także podział wymiany informacji na odrębne komunikaty, gdzie jeden komunikat to ??jedno pole formularza?. Nie zmienia to faktu, że taki komunikat to struktura zawierająca autora i nadawcę komunikatu, odbiorcę komunikatu oraz jego treść, jest to formularz ? struktura ? jaką widzimy pisząc np. kolejnego maila.
W efekcie można przyjąć, że wszelkie informacje w organizacjach są zorganizowane z użyciem określonej liczby formularzy, z których każdy ma określoną strukturę. Struktury te nazywamy szablonami dokumentów (formularzy). Nie jest niestety prawdą, że informacje są zorganizowane w bazach danych rozumianych jako system relacyjnych tablic. Model relacyjny jest nienaturalny i stratny. Człowiek nie jest w stanie korzystać z niego wprost, jest to tylko jakaś technologiczna metoda zapisu danych. (Modele informacyjne)
Prostym i popularnym dokumentem biznesowym, obecnym w każdej firmie, jest np. Wniosek urlopowy. W aplikacjach na ekranie wygląda np. tak:
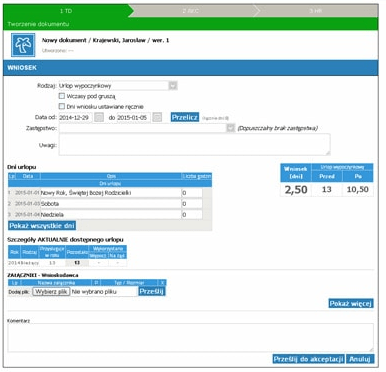
W wielu przypadkach jest to formularz wygenerowany z bazy danych. Jednak wniosek urlopowy może być (na wydrukach często jest) także tekstem, w postaci takiej jak np. ta poniższej:
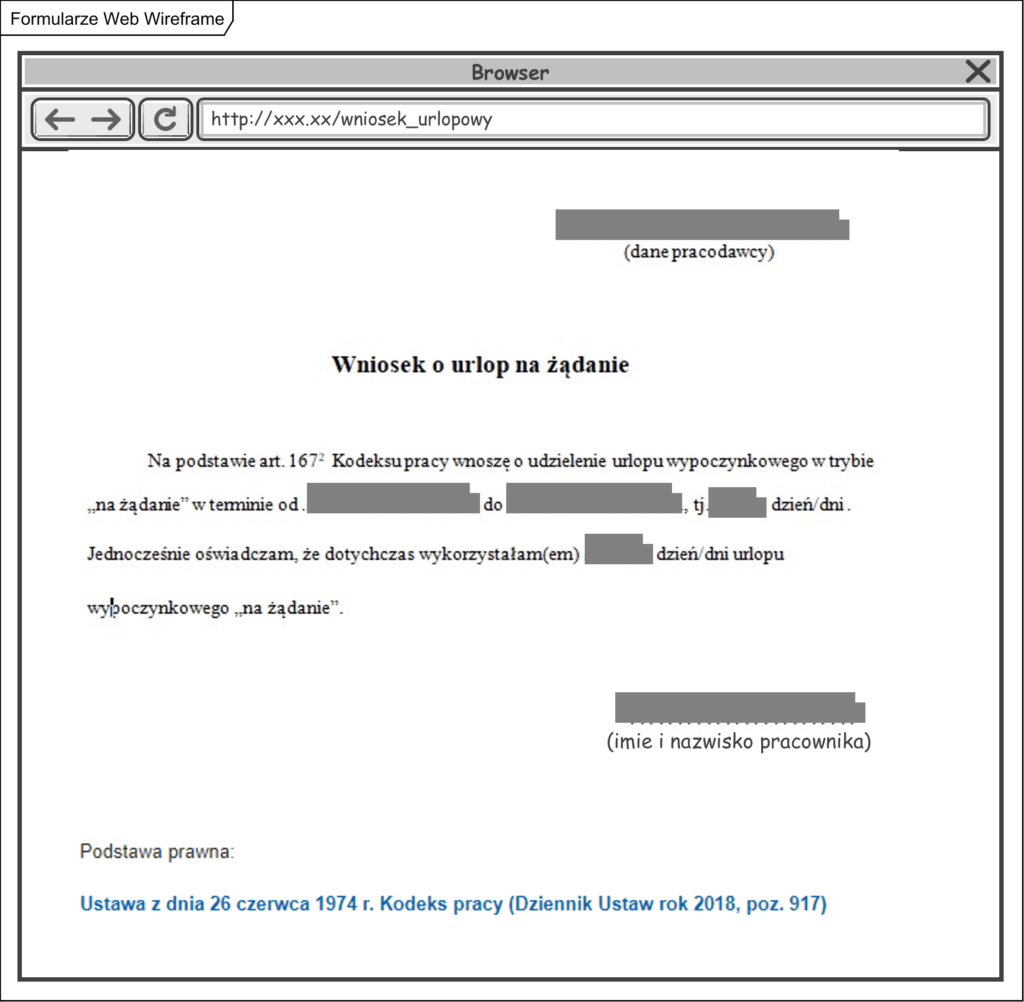
Oznaczone na powyższym prototypie szare pola to miejsca na wprowadzane dane (znaczniki XML) i w tym miejscu mozna w dokumentacji wpisywać pojęcia ze słownika np. tak: ?urlop [typ urlopu] w dniach od [data początku] do [data końca]?. (więcej o formacie XML)
Dokument taki można zapisać w systemie informatycznym w postaci strukturalnego tekstu:
<wniosek_urlopowy> <pracodawca>nazwa firmy</pracodawca> Wniosek Urlopowy Na podstawie art. 167 Kodeksu Pracy wnoszę o udzielenie urlopu w trybie "na żądanie" w terminie od <data_początku_urlopu>xxxx.xx.xx</data_początku_urlopu> do <data_końca_urlopu>xxxx.xx.xx</data_końca_urlopu> t.j. <liczba_dni_urlopu>xxx </liczba_dni_urlopu> dni. Jednocześnie oświadczam, że dotychczas wykorzystałem <liczba_wykorzystanych_dni_urlopu>xxx </liczba_wykorzystanych_dni_urlopu> dni urlopu. <pracownik> <imię_pracownika>imię </imię_pracownika> <nazwisko_pracownika>nazwisko <nazwisko_pracownika> </pracownik> Podstawa prawna: Ustawa z dnia 26 czerwca 1974, Kodeks Pracy (dziennik ustaw rok 2018, poz 917) </wniowek_urlopowy>
Podsumowanie
Artykuł ten pisałem głównie z dwóch powodów: problemy wdrożeń systemów ERP oraz problemy ze stosowaniem RODO i udostępniania informacji publicznej. Te ostatnie mają pewną wspólną cechę: często wymagane ręczne anonimizowanie treści.
Przeciążone dokumenty (zbyt wiele treści) i blokowanie użytkownikowi dostępu do wybranych pól dokumentu powoduje, że monstrualnie rośnie złożoność logiki oprogramowania. Wyobraźmy sobie, że mamy 10 typów dokumentów i każdy ma 10 pól. Tradycyjna kontrola dostępu do treści to reguła dla każdego pola. Nawet, jeżeli uznamy, że połowa treści jest na dokumentach powielana (np. dane podmiotów) to i tak mówimy o kilkudziesięciu regułach kontroli dostępu do tych danych, które łącznie powinny być spójne i niesprzeczne. W modelu zakładającym kontrolę dostępu do dokumentu jako całości tych reguł będzie dokładnie 10. Dodatkowo będą relatywnie proste, bo dostęp do konkretnych dokumentów to konsekwencja roli użytkownika (w firmie, w procesie, itp.).
Gdyby np. systemy informatyczne i dokumenty urzędowe w nich przetwarzane, były zaprojektowane według ww. reguł, problemy dostępu do informacji publicznej oraz kontroli dostępu do danych wewnątrz tych instytucji w zasadzie by nie występowały. Na żądania dostępu do informacji publicznej odsyłane byłyby automatycznie dokumenty mające z góry określony kontekst, w całości. W przypadku RODO analogicznie. Anonimizowanie dokumentów też można by robić automatycznie (powyższy przykład: wniosek urlopowy można zanonimizować, automatycznie usuwając zawartość znaczników <xxx> zawierających dane osobowe. Wiele z tych informacji można byłoby udostępniać na stronie WWW (np. BIP) nawet w rybie bezwnioskowym automatycznie.
W czasie gdy piszę ten artykuł, na Facebooku, w jednej z grup, toczy się dyskusja jak udostępnić informację publiczną, jaką są wynagrodzenia osób pełniących funkcje publiczne, jeżeli system informatyczny drukuje wyłącznie listę płac zawierającą także inne, wrażliwe dane osobowe (np. potrącenia komornicze). Prawdopodobnie urzędników czeka ręczna anonimizacja tych list płac na koszt urzędu.
W opisany powyżej sposób zaprojektowałem między innymi:

- System informatyczny do obsługi ofert na realizację zadań publicznych w zakresie opieki nad Polonią i Polakami za granicą: Generator Ofert. (ogłoszenie o przetargu i kontakt do zamawiającego, uwagi i pytania zgłoszone do treści) [analiza i opracowanie OPZ – 1 miesiąc, implementacja i wdrożenie 4 m-ce]
- ?System Wspierania Realizacji Zadań ŻW? dla Oddziału Zabezpieczenia Żandarmerii Wojskowej (Opis Techniczny Przedmiotu Zamówienia). [analiza biznesowa i projektowanie ok. 6 m-cy z przerwami, implementacja i oddanie do użytku 4 m-c]
- Projekt standaryzacji procedur i dokumentów systemu utrzymania ruchu KGHM SA Polska Miedź. [analiza procesów, dokumentów, modele pojęciowe, opracowanie standaryzacji pojęciowej i struktur dokumentów, model standaryzacji procedur, 8 m-cy].
- wszystkie powyższe projekty objęte nadzorem autorskim w toku realizacji przez dostawców i wykonawców.
Przykład:
15.01.2025 Prezes UOKiK opublikował informację:
Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego nośnika, jeżeli tego rodzaju strona internetowa nie spełnia cech trwałego nośnika.