Wprowadzenie
Jednym z najczęściej stosowanych wzorców projektowych w warstwie dziedzinowej jest wzorzec CQRS (Command Query Responsibility Segregation) oraz często wykorzystywany razem z nim Event Sourcing.
W 2012 roku pisałem o tym wzorcu w kontekście optymalizacji wydajnosci:
Idea tego pomysłu na tym, by nie optymalizować wydajności systemu metodą, nie raz zgniłego, kompromisu, a podejść do problemu dzieląc go na dwa problemy: zgodność modelu z rzeczywistością i wydajność całego systemu. Pierwszy problem rozwiązujemy tworząc wierny model struktury opisującej produkty, drugi problem ? wydajności ? rozwiązujemy tworząc drugi uproszczony model produktów, do celów szybkiej realizacji kilku ważnych ??zapytań? (np. publikacja on line uproszczonej postaci cennika). ( CQRS czyli kto, co i jak zamawia i dostarcza – Jarosław Żeliński IT-Consulting).
Rok później (2013), w toku prac nad kolejnym projektem, powstała wątpliwość:
i to jest ten moment, w którym ja chyba czegoś nie zrozumiałem u Fowlera (i nie tylko u niego) (CQRS czyli jak osiągnąć wydajność c.d. – Jarosław Żeliński IT-Consulting)
Najczęściej CQRS opisywany jest przez developerów, językiem developera, i moim zdaniem, z perspektywy developera oraz domyślnego użycia relacyjnego modelu danych. M.Fowler pokazuje to tak:
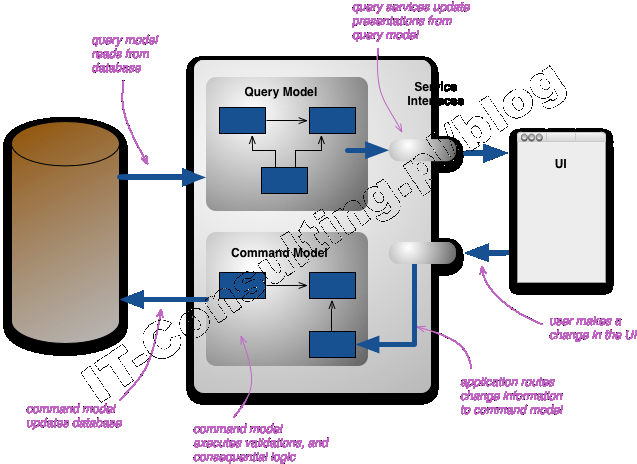
Co oznacza, że separacja jest realizowana wyłącznie w postaci odrębnych zestawów poleceń SQL, jednak do tej samej relacyjnej bazy danych (na powyższym diagramie po lewej, czyli tej samej ich struktury) przykrytej jej abstrakcją (środkowa część powyższego diagramu), używana na użytek jednolitego dostępu do niej. Warto pamiętać, że ta abstrakcyjna warstwa to mapowanie obiektowo-relacyjne (ORM, ang. Object Relational Mapping), rzecz w tym, że takie podejście owszem separuje elementy implementacji logiki aplikacji, ale nadal nie uwalnia nas od złożoności zapytań SQL do relacyjnej bazy danych. Przykładem może być ten (zresztą, uważam bardzo dobry) opis:
Dobrze, przejdźmy więc do graficznej [rys. powyżej] reprezentacji wzorca, która powinna pomóc nam zrozumieć z czym tak na prawdę mamy do czynienia… (CQRS i Event Sourcing – czyli łatwa droga do skalowalności naszych)
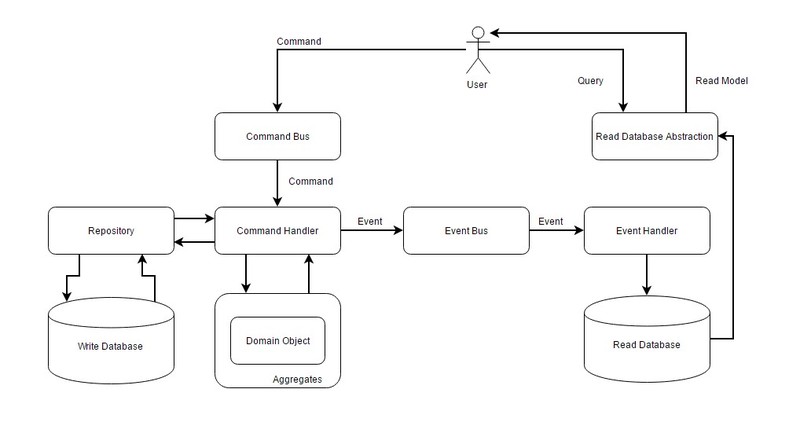
Należy tu zwrócić uwagę na fakt, że CQRS to wzorzec architektoniczny czyli dobra praktyka, a Event Sourcing to często mechanizm wbudowany w system zarządzania relacyjną bazą danych.
Separacja
Opiszę wersję PIM obu ww. wzorców, abstrahując całkowicie od warstwy technologicznej, czyli pominę kwestię “hendlerów”, szyn “bus” itp. To mam nadzieję oczyści opis z tego co nie jest istotą idei jaka, moim zdaniem, stoi a tymi wzorcami: optymalizacja zarządzania przechowywaną informacją.
Niedawno, podsumowując opis baz dokumentowych i przykładowego projektu, pisałem, że:
Dokumentowe bazy danych mają wiele zalet (np. wydajność) ale zaletą, która czyni jest na prawdę ??hitem? jest możliwość całkowitej rezygnacji z modelu relacyjnego i języka SQL, co w efekcie daje ogromne uproszczenie implementacji. ??Wyciągnięcie? z repozytorium nawet bardzo skomplikowanego strukturalnie dokumentu, realizujemy tu jednym bardzo prostym poleceniem. Identyczna operacja w modelu relacyjnym będzie wymagała nie raz monstrualnego, trudnego do testowania, zapytania SQL .Bazy dokumentowe ??nie boją się redundancji? (Projekt aplikacji czyli bazy dokumentowe – Jarosław Żeliński IT-Consulting).
Warto też nie zapominać, że wzorce projektowe są po to by rozwiązać problem (spełnienie wymagań) a nie po to by jest zastosować bo tak.
Przyjmuje się, że CQRS to zasada, która mówi że każda metoda w systemie powinna być zaklasyfikowana do jednej z dwóch grup: 1. Command – są to metody, które zmieniają stan aplikacji i nic nie zwracają, 2. Query – są to metody, które coś zwracają, ale nie zmieniają stanu aplikacji. Autor ww. artykułu przywołuje:
Dlaczego dokonujemy podziału jedynie metod na te, które pobierają dane oraz na te, które zmieniają stan naszej aplikacji? Możemy przecież zaprojektować nasz system tak, aby tymi zadaniami zajmowały się osobne klasy. To jest główna różnica między dwoma podejściami. ?Mówiąc o CQS myślimy o metodach. Mówiąc o CQRS myślimy o obiektach.?
I tu widzę problem, bo bazy relacyjne cechują się tym, że dokumenty (określone struktury danych mające postać strukturalną lub nie) w nich nie istnieją, same tabele relacyjne zawierają dane, ale nie niosą żadnej użytecznej informacji. Niezależnie od tego czy chcemy zapisać dokument (zmieniony lub nowy) czy też do odczytać, musimy wykonać, nie raz bardzo skomplikowany, kod zapytania w języku SQL. Separacja zapisów danych nowych (zmienione też są “nowe”) i ich odczytywania, ma tu sens bo czytanie nie wymaga żadnej kontroli (nie stanowi ryzyka dla systemu), zapis jest zawsze obłożony restrykcjami bo stwarza ryzyko spowodowania błędów całości struktury danych. Po drugie często odczyt, jest w takiej bazie rozumiany jako raport czyli treść tworzona na podstawie wielu dokumentów, co dodatkowo komplikuje treść zapytania SQL.
O wzorcu Event Sourcing nie będę się rozpisywał, rozwiązuje problem zarządzania historią zmian danych w relacyjnym modelu, przy jednoczesnym usuwaniu redundancji danych, a jego opisy są łatwo dostępne. Tu skupiam sie jedynie na opisie wzorca na poziomie biznesowym dziedziny problemu.
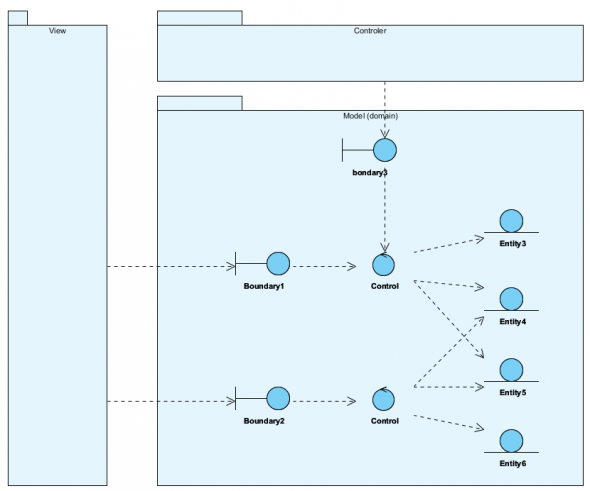
Struktura komponentu Archiwum

Powyższy diagram obrazuje architekturę Archiwum Dokumentów (odpowiada za zachowanie dokumentów i dostęp do ich treści). Opis od prawej.
Dokument jako agregat, jest to ciąg znaków, który może mieć nadaną mu strukturę . Podstawowa struktura to nazwa oraz początek i koniec dokumentu. Treść może mieć wewnętrzną strukturę :
Podstawowym elementem Archiwum jest zbiór obiektów kasy Zachowany Dokument. Obiekty tej klasy są nośnikami dokumentów (ciągów znaków jak wyżej), każdy ma określoną tożsamość (identyfikator dokumentu). Każda operacja zapisania lub przywołania dokumentu to wywołanie właściwego obiektu: przywołaj dokument (identyfikator dokumentu). Zapis dokumentu wygląda analogicznie, co oznacza, że ewentualny zapis pobranego wcześniej dokumentu o zmienionej treści nadpisze jest “starą wersję”. Jest wiele sytuacji gdy nie stanowi to problemu. Te przypadki, gdy chcemy mieć dokument jako “draft” (edytowalny) i wersję finalną (nieedytowalny) realizujemy dodają obiektowy atrybut “status dokumentu” (draft|final). Jednak jest wiele sytuacji gdy historia zmian jest potrzebna.
Pierwsza rzecz: za historię powinien odpowiadać inny obiekt więc tworzymy dodatkową Klasę obiektów Zmiany. Separowanie historii obiektów od nich samych ma dwie korzyści: nie przeciążamy Obiektów klasy Zachowany Dokument oraz możemy tę historię (mechanizm) dodać później, gdy okaże się że faktycznie jest potrzebny. Po trzecie, co jest tu bardzo ważne: w klasie Zachowany Dokument tożsamość ma dokument, zaś w klasie Zmiany tożsamość ma wersja dokumentu. Biorąc pod uwagę, że bardzo często żądamy dostępu do dokumentów i bardzo rzadko do historii ich zmian, pozwala to utrzymać minimalną wymagana liczbę obiektów klasy Zachowany Dokument (a mogą to miliony). Praktyka pokazuje, że komfort pracy jest oceniany na podstawie czynności wykonywanych często na co dzień, rzadko wykonywane czynności (odtwarzanie historii) to te, na które często mamy znacznie więcej czasu.
Tu ważna informacja: dokument może być opisem faktu lub obiektu (czytaj więcej o Separacja kontekstu…). Ma to ogromne znaczenie, bo Archiwum (kasa Zachowany dokument) wcale nie musi przechowywać dokumentów o identycznej strukturze. Zaletą tego wzorca jest to, że nie muszą czyli np. możemy w jednym jednym Archiwum trzymać dokumenty mimo tego, że ich struktura ewoluuje z czasem, co nie wymaga żadnej refaktoryzacji bazy i jej migracji. Klasyfikacji treści dokumentów możemy dokonać z pomocą specjalnej struktury identyfikatora dokumentu (system ten stale funkcjonuje w archiwistyce: każdy dokument ma unikalną sygnaturę, zawierającą także klasyfikację dokumentu). Można też dodać do każdego dokumentu opisujące go metadane i użyć ich jako dodatkowych atrybutów klasy Zachowany dokument, ale lepsze rozwiązanie w dalszej części.
Trzeci element to klasa Hurtownia Danych. Najczęściej jest to interfejs do dedykowanego systemu raportowania np. hurtowni danych, systemu BI itp..
Przed “resztą świata” cała struktura jest “ukryta” (hermetyzacja) za obiektem klasy Menedżer Repozytorium. Tu jest cała logika kontroli dostępu do Archiwum oraz logika adresowana zapytań: pytanie o dokument będzie kierowane do obiektów klasy Zachowany Dokument, pytanie o historie określonego dokumentu do obiektów klasy Zmiany, wszelkie żądania danych zbiorczych i przeliczanych, do Hurtowni Danych. komponenty korzystające z tych usług nie znają architektury tego “zaplecza”, dzięki czemu jakiekolwiek zmiany w tym “zapleczy” w żadnym stopniu nie będą dotyczyły reszty systemu.
Po lewej stronie mamy (tu dwa) ciekawe obiekty. Są to dziedzinowe spisy dokumentów. Wyżej pisałem, że można też dodać do każdego dokumentu opisujące go metadane i użyć ich jako dodatkowych atrybutów klasy Zachowany Dokument, jednak to spowoduje, że przyszła potrzeba wprowadzenia nowej klasyfikacji spowoduje konieczność refaktoryzacji obiektów klasy Zachowany Dokument (dodanie kolejnego atrybutu). Aby tego uniknąć, obiekty klasy Zachowany Dokument powinny odpowiadać wyłącznie za zachowanie dokumentu (każdy ma tożsamość w atrybucie identyfikator dokumentu). Jeżeli potrzebne jest nam operowanie dokumentami na podstawie większej ilości jego cech (daty, wartości pieniężne, osoby podpisujące itp., tematyka treści, inne) udostępniamy aktorom nie Menedżera Repozytorium (Aktor A) a Dziedzinowe Rejestry (Aktor B). Uzyskujemy dwie kluczowe korzyści: kontrole dostępu do treści (aktor może mieć dostęp tylko do obiektów klasy Dziedzinowy Rejestr X) oraz możliwość dodawania kolejnych dziedzinowych rejestrów bez konieczności refaktoryzacji właściwego Archiwum. Tak funkcjonują repertoria w urzędach i sądach.
Podsumowanie
Opisana architektura pozwala na separację kontekstów (aktualizacja treści i jej pobieranie). Pozwala na niezależne zarządzanie historią dokumentów. Spełnia zasadę OOP (ang. Open Close Principia) czyli architektura jest zamknięta na zmiany i otwarta na rozszerzenia. Oparta jest na idei wzorców powszechnie znanych jako CQRS i Event Sourcing.
Praca z pojedynczym dokumentem (w szczególności jego stworzenie i aktualizacja) jest prosta wymaga tylko (i aż) znajomości jego identyfikatora. Tu mamy do czynienia ze zmianą treści (stanu) w systemie (CQRS).
Szybkie wyszukanie dokumentu na bazie wyrafinowanych zapytań da nam hurtownia danych (tu zastrzeżona dla Aktora A), która w tablicy faktów zawiera identyfikator dokumentu, z którego pobrano dane (tu osobny temat to hurtownie danych i wielowymiarowe modele danych do obliczeń i raportowania). Jest to czytanie, operacja nie zmieniająca stanu systemu (CQRS). Dotyczy to także zmienionych, historycznych wersji dokumentów.
Obu tych operacji można dokonać także za pośrednictwem Dziedzinowego Rejestru (Aktor B).
Opisana tu konstrukcja została wykorzystana w systemie Generator Ofert dla Biura Polonijnego Kancelarii Senatu oraz w ?System Wspierania Realizacji Zadań ŻW? dla Oddziału Zabezpieczenia Żandarmerii Wojskowej. W obu przypadkach jednym z kluczowych wymagań był czas wykonania implementacji, dziedzinowa kontrola dostępu do dokumentów, oraz możliwość pracy z formularzami o często zmienianej strukturze i formularzami nowymi, bez konieczności ingerencji developera.


Cześć Jarek, jak zawsze w swoich artykułach sprawnie przekazujesz porcję wiedzy w skondensowanej formie, dzięki 🙂
Jedno pytanie o zbiory danych. W artykule mamy przechowywanie zarówno ostatniej wersji dokumentu jak i historii zmian – co jest dla klienta źródłem prawdy? Co w przypadku, kiedy dojdzie do niespójności pomiędzy zapisami historii i ostatnią wersją dokumentu. Event Sourcing zakłada przechowywanie jedynie historii zmian (zdarzeń), jako jedynego źródła prawdy o stanie obiektu.
Z najlepszymi noworocznymi życzeniami! 🙂
To dobre pytanie, bo ten wzorzec operuje na poziomie treści “dokumentu”. Podstawowe założenie to zaufanie do bazy dokumentów (nie kwestionujemy jakości danych), czyli źródłem prawdy jest posiadana baza danych. Wdrożenie tego wzorca ma niejako dwie wersje:
1. Istnieje jeden właściwy aktualny dokument (aktualizacje nadpisują stare dane) oraz chronologiczna kolekcja wprowadzanych zmian (aktualizacji tego dokumentu).
2. Istnieją wszystkie historyczne wersje dokumentu (nie nadpisujemy) i właściwy aktualny dokument “na wierzchu”, oraz chronologiczna kolekcja wprowadzanych zmian (aktualizacji tego dokumentu).
W wersji pierwszej istotna jest tylko aktualna treść dokumentu i historia faktów jego aktualizacji (wymagania biznesowe). Nie potrzebujemy “starych wersji” ale chcemy wiedzieć kiedy kto i co zmieniał. W wersji drugiej chcemy mieć dostęp ad-hoc także do “starych wersji” (inne wymaganie biznesowe). Nie wyobrażam więc sobie “niespójności pomiędzy zapisami historii i ostatnią wersją dokumentu”.
Pojęcie “stan obiektu” jest tu zwodnicze, bo tak na prawdę chodzi o określone jego atrybuty, lub po prostu “dokument” w przypadku baz dokumentowych. Jeżeli pojawia się tu problem to tyko wtedy, gdy “dokument” to tak na prawdę “raport SQL” z bazy o relacyjnym modelu danych, i tu faktycznie jest walka o jakiej piszesz. Teoretycznie jest możliwe odtworzenie dowolnego stanu z historii “odkręcając” wstecz zmiany ale to gehenna (no i to o czym piszesz czyli ryzyko niespójności). Dlatego motory baz danych SQL mają takie mechanizmy wbudowane, ale to tylko częściowe rozwiązanie problemu.
Generalnie na świecie następuje powolne odejście od stosowania relacyjnego modelu danych dla dokumentów/formularzy, między innymi z tego powodu. Bazy NoSQL rozwiązują większość problemów jaki wskazałeś. Lada moment ukaże się w USA (IGI Global) mój artykuł na ten temat (https://www.igi-global.com/book/management-strategies-digital-enterprise-transformation/244649).
Wszystko fajnie, tylko skąd założenie, że CQRS to model relacyjny? część write z natury jest dokumentowa, tak działa repozytorium, pobiera się agregat po id i go utrwala po id, nic więcej, tam nie ma żadnej filozofii. Część read może być relacyjna, ale może być dokumentowa, to zależy już od wymagań systemu, obie wersje mogą być ok. Event sourcing to już w 100% dokumentowa baza, przecież tam tylko utrwala się eventy które są dokumentami, do tego mamy tu bazę WORM. Jeśli ktoś to interpretuje inaczej chyba nie zrozumiał istoty CQRS i DDD (części taktycznej), użycie do części write sql-a oczywiście zadziała, ale tworzy nam to las obiektów, niepołączonych ze sobą drzew, gdzie każdy agregat ma swoje drzewo inaczej nie zastosujemy w pełni tych wzorców bo agregat powinien być traktowany atomowo na poziomie dziedziny, jak trzeba coś połączyć z innymi agregatami to za to odpowiada zewnętrzna warstwa aplikacyjna.
Czyli w sumie w drugiej części artykułu opisał Pan główne założenia CQRS-a, jak ktoś go stosuje inaczej, robi to źle.
“Wszystko fajnie, tylko skąd założenie, że CQRS to model relacyjny? ”
Bo w innych modelach nie istnieje problem, który rozwiązuje CQRS: wydajność skomplikowanych zapytań SQL do rozbudowany baz relacyjnych.
https://martinfowler.com/bliki/CQRS.html
Agregat do hierarchiczna struktura, można ją odwzorować jak kaskadę kompozycji klas (najgorsza forma) a mozna jako jeden plik XML w bazie dokumentowanej (jeden string).
W DDD nie ma nic o CQRS ani nawet obowiązku stosowania kaskady kompozycji klas, wymyślili to chyba Ci od Java EE.
Jest tylko jeden miernik tego “kto robi źle”: źle robi ten kto generuje większe koszty implementacji i rozwoju by uzyskać tę samą funkcjonalność apliakcji.
Zdecydowanie DDD i CQRS nie są ściśle powiązane, rozwiązuję różne problemy ale często idą w parze, i to głównie jeśli cqrs to ddd, w drugą stronę nie ma musu a często jest to szkodliwe (nadmierne skomplikowanie).
Skomplikowane zapytania wcale nie znikają wraz z użyciem bazy dokumentowej, jak trzeba danych z wielu kolekcji to też mogą powstać spore, skomplikowane i wolne zapytania, nie zawsze redundancja danych rozwiązuje problem bo znacznie komplikuje się zapis. Języki do baz dokumentowych wcale nie są łatwe i w praktyce rzadko kiedy wystarczy query po id, takie zapytania to najczęściej tylko w repozytorium.
Co do ostatniego zdania, tu podstawa to 2 najważniejsze zasady programowania, KISS i YAGNI, jak ktoś to łamie to zawsze będzie drogo.
A więc DDD i CQRS to “różne bajki” więc nie mieszajmy ich ze soba.
Nie jest prawdą, że “Skomplikowane zapytania wcale nie znikają wraz z użyciem bazy dokumentowej,” znikają. Stosowanie dokumentowego modelu danych to nie koniecznie MongoDB, wystarczy np. jedna tabela mające dwie kolumny w MS SQL i mamy bazę key-value, a jak jest to kolumna string i wartością jest XML to jest to baza dokumentowa.
KISS czyli po grzyba relacyjna baza skoro można prościej i lepiej.
Repozytorium to element taktycznego DDD i z tego powodu o nim wspomniałem, dopiero ten wzorzec w połączeniu z agregatami (też DDD) nadaje poprawny sens w CQRS i możliwość użycia baz dokumentowych, wykonania projekcji z write model do read model bez eventów w zasadzie się nie da, tzn. da operując na widokach bazy relacyjnej co jest dalekie od ideału. Stąd można mówić o DDD bez CQRS ale w drugą stronę powstają jakieś potworki w stylu skomplikowanego modelu relacyjnego do zapisu i na to setki widoków (często zmaterializowanych) żeby poprawić odczyt.
MS SQL (czy jakikolwiek inny sql) w roli key value się nada wyłącznie jako write model, read zawsze będą nieefektywne bo nie wyszukamy nic w takim dokumencie. Ale nawet jako write model będzie nieefektywny z racji tego że nvarchar(max) jest trzymany jako referencja przez co odczyty będą wolniejsze niż w prawdziwej bazie dokumentowej. Jak ze wszystkim nigdy nie ma uniwersalnego rozwiązania, zawsze takie szczegóły implementacyjne należy dobierać do konkretnego zastosowania (ale na pewno są pewne z zasady złe jak Java EE, Oralce Forms, ASP.Net WebForms itp.).
Co to za wynalazek “taktyczne DDD” 😉
“MS SQL (czy jakikolwiek inny sql) w roli key value się nada wyłącznie jako write model, read zawsze będą nieefektywne bo nie wyszukamy nic w takim dokumencie.”
jak mamy metadane w repozytorium to wyszukamy (polecam wzorzec envelope) i nie musi wymyśłać żadnych osobnych modeli do czytania i pisania..
Ma Pan dziwne pojęcie i pojmowanie nieSQLowych metod zarzadzania danymi…
“(ale na pewno są pewne z zasady złe jak Java EE, Oralce Forms, ASP.Net WebForms itp.).” – to te narzędzia to faktycznie zbiory antywzorców 🙂
DDD ma podział na wzorce taktyczne i strategiczne jak to dzieli Vernon, strategiczne to język i podział na dziedziny, taktyczne to encje, agregaty, repozytoria, zdarzenia i cała reszta.
Envelope ok, ale jeśli jest to sql to metadane będą albo jako kolumny albo jako tabela z relacją 1:1 lub 1:* w zależności czy metadane będą jako wiersze lub key value. Skoro będzie to w praktyce zmaterializowany widok do odczytu (a przynajmniej podstawa jego utworzenia) to też trzeba będzie tworzyć zapytania do wyciągnięcia tego. W kontekście noSQL używam w zasadzie tylko MongoDB, ale inne działają podobnie, są języki zapytań, często bardzo bogate, jakbym miał trzymać dokumenty w tabeli bazy relacyjnej musiałby być na prawdę bardzo ważny powód do takiej decyzji (np. już posiadany serwer u klienta gdzie takowa baza działa i chęć użycia istniejącej infrastruktury lub uzasadnione mieszanie danych relacyjnych i dokumentowych w jednym systemie). W każdym innym wypadku SQL jest raczej złym pomysłem na trzymanie dokumentów, lepiej użyć bazy dokumentowej i faktycznie móc odpytywać ją o konkretne dane, nie mówimy przecież o bazach typu key value a dokumentowych gidze dokumenty są danymi ustrukturyzowanymi dającymi się przeszukiwać co jest efektywniejsze niż pobieranie całego dokumentu i obrabianiu go w systemie poza bazą.
DDD to kilka kluczowych ról (odpowiedzialności klas) i tyle. Mieszanie do tego języka itp. to dramat, o którym pisał Cockburn wyjaśniając sens separacji logiki biznesowej i środowiska (architektura heksagonalna).
Ta dyskusja jest dowodem na to, by deweloperów platformy (full stack developer) nie dopuszczać do projektowania mechanizmu realizacji logiki biznesowej. Bez obrazy.
Nie obrażam się 😉 też uważam że część strategiczna nie powinna tam być bo to co ona obejmuje to rola BA i architekta. W swojej firmie w zasadzie pełnię prawie wszystkie role bo jest za mała żeby pozwolić sobie na więcej ale jestem w pełni świadom, że nie tak to powinno wyglądać. Dlatego też na Pana blog trafiłem bo doświadczenie pokazuje że zaczynanie od kodu nigdy się dobrze nie kończy, jakoś próbuję łatać u siebie brak BA i architekta, w pełni się zgadzam że idealnie jakby był zewnętrzny. Najbardziej przeraża mnie, że tak mało developerów to dostrzega i brnie w to szaleństwo że developer zaprojektuje dobrze system.
Generalnie (nie jestem dyplomatą) szkodliwe jest “myślenie kodem”. To jak by stolarzowi dać projektowanie wnętrz: wszystko będzie z drewna, bez względu na to czy ma to sens czy nie. I nie jest to zła wola stolarza.
“Najbardziej przeraża mnie, że tak mało developerów to dostrzega i brnie w to szaleństwo że developer zaprojektuje dobrze system.”
Mimo ponad 15 lat mnie to nadal martwi, bo obserwuję to na co dzień.