Streszczenie
Profil UML i meta-model typów dokumentów jako system organizacji danych. Dokument jako kontekstowa struktura informacyjna.
Opisano sprawdzona w praktyce metodę składowania danych zorganizowanych w dokumenty. Opisana metoda nie ma wad relacyjnego modelu organizacji danych, jakim jest utrata kontekstu danych i komplikacje wywołane brakiem redundancji danych. W pracy tej przedstawiono metodę organizacji danych w dokumenty jako sklasyfikowane agregaty, metodę ich klasyfikacji oraz metamodel ich budowy. Opisany metamodel zakłada, że dokumenty jako struktury danych to zwarte agregaty, klasyfikowane jako opisy obiektów (object) lub wydarzeń (events) co nadaje im zawsze określony i jednoznaczny kontekst. Opisano także metodę projektowania dokumentów jako agregatów kontekstowych, co pozwala zniwelować wskazane wady modelu relacyjnego oraz zagwarantować skuteczność zarządzania informacją. Dodatkowo opisany model rozwiązuje problemy zarządzania dostępem do danych poprzez określanie dostępu do całego kontekstowego dokumentu, a nie do poszczególnych pól. Dzięki temu zarządzanie dostępem do danych staje się znacznie prostsze.
Słowa kluczowe: systemy informacyjne, inżynieria oprogramowania, bazy danych, BCE, agregat, metody obiektowe, paradygmat obiektowy, inżynieria systemów, DDD, aggregate
Dla zainteresowanych prezentacja: https://youtu.be/Wh8Yaao_rYM?si=klnNxGXct6ir8GfJ
1. Wprowadzenie
W wielu projektach, których celem jest zarządzanie informacją i przetwarzanie jej, pojawia się problem z opracowaniem modelu danych. Często a priori przyjmuje się, że dokumenty to informacja organizowana w postaci formularzy złożonych z określonych pól, a te będą przechowywane w modelu relacyjnym [Shimura, T., Yoshikawa, M., Uemura, S., 1999]. Model ten prowadzi do sytuacji gdzie: <dokument> = <zbiór danych w modelu relacyjnym> + <zapytanie SQL do tego zbioru>. Innymi słowy dokumenty to dynamicznie generowane treści, nie istniejące jako trwałe byty. Dla rozbudowanych modeli danych procedury nazwane <zapytanie SQL do tego zbioru> są bardzo złożone i ich wykonanie generuje duże zapotrzebowanie na czas i moc procesora. Ich opracowanie i testowanie jest kosztowne, bo zajmuje wiele czasu specjalistów, którzy je tworzą. Nie mniej kosztowne jest wprowadzanie do nich zmian w cyklu życia oprogramowania.
Dokumenty bardzo często zawierają bardzo wiele różnych informacji stanowiących sobą złożone wielokontekstowe zestawy (agregaty) danych. Zastosowanie modelu relacyjnego do organizowania takich informacji, prowadzi do powstania złożonego systemu powiązanych relacyjnie tabel a usuwanie redundancji prowadzi często utraty kontekstu treści poszczególnych pól w tabelach. W konsekwencji pojawia się konieczność stosowania bardzo złożonych zapytań w języku SQL, by dokumenty te zapisywać w takiej bazie i odtwarzać z niej. W samej bazie są to tylko pozbawione kontekstu dane w tabelach a nie dokumenty.
Wielu autorów zwraca uwagę na problem złożoności i utraty kontekstu jednolitych modeli relacyjnych, zalecając separowanie kontekstów w dużych relacyjnych modelach danych, jednak poprzestają oni tylko na rekomendacji by te konteksty separować [EVANS 2003, M.Fowler 2014] pozostając nadal przy modelu relacyjnym, co nie rozwiązuje problemu całkowicie [Awang, M.K., Labadu, N.L., Campus, G.B., 2012].
Zmiana kontekstu często zmienia znaczenie danych [Danesi, M., 2004]. Próby zachowania tego znaczenia prowadzą często do powstawania rozbudowywania relacyjnych modeli danych, co z kolei powoduje dodatkowy koszt. W konsekwencji stosowanie jednego modelu relacyjnego danych do zapisu treści wielu różnych dokumentów powoduje, że system taki staje się wielkim i niepodzielnym monolitem, kosztownym w opracowaniu i utrzymaniu.
Stosowane jest też podejście, w którym oprogramowanie przetwarza dokument (jego treść) traktując go jako samodzielny obiekt zapisując jednak jego treść (poszczególne pola) w modelu relacyjnym [O?Neil, E. J. (2008)] co powoduje dodatkowy nakład pracy w toku projektowania takiego systemu oraz duże zapotrzebowanie na moc procesora w trakcie odczytu i zapisu dokumentów z pomocą dodatkowej warstwy aplikacji, jaką jest tu mapowanie obiektowo-relacyjune (ORM, Object-Relational Mapping). Problem ten jest często nazywany niedopasowaniem oporu modelu relacyjnego i obiektowego (object-relational impedance mismatch) [Ireland, C., Bowers, D., 2015].
Celem badań było znalezienie odpowiedzi na pytanie dlaczego tylko ok. 10% wdrożeń systemów informacyjnych kończy się sukcesem [The Standish Group International, Inc. (2015)] i czy inny niż, nie raz krytykowany za nieskuteczność [Cook, S., & Daniels, J. (1994)] relacyjny korporacyjny model organizacji danych, pomoże zwiększyć skuteczność tych projektów. Obszar badań autora to modele jako metody analizy i projektowania a metamodele jako narzędzie budowy teorii (patrz także Gray, J., & Rumpe, B. (2019)).
2. Użyte metody i narzędzia
Materiałem źródłowym do analiz pojęciowych i struktur danych były dokumenty w badanych firmach, w szczególności w obszarze finanse i księgowość, zarządzanie produktami, rejestry nieruchomości a także archiwa plików multimedialnych. Były to dane dostępne dla autora w toku pracy zawodowej.
Opisane tu metody projektowania dokumentowych struktur danych zostały zastosowane przez autora w kilku projektach. Uzyskane efekty pokazały przewagę tej formy analizy i projektowania struktur danych do celów zarządzania wiedzą, w porównaniu do metod opartych na relacyjnym modelu danych.
Jako podstawowe narzędzia wykorzystano w pracy analizę pojęciową i obiektową oraz modelowanie obiektowe. Do udokumentowania wyników wykorzystano systemy notacyjne: Semantic Business Vocabulary and Rules [SBVR 2017] oraz Unified Modeling Language [UML 2017]. Wykorzystano także wiedzę z zakresu semantyki [semantic triangle Sowa, J.F., 2000] oraz pojęcia klasy, klasyfikatora i obiektu [UML 2017]. Celem tej publikacji jest prezentacje opracowanej metody a nie przegląd systemów projektowanych i wdrażanych przez autora.
3. Wyniki
Opracowano system standaryzacji organizowania informacji, jej przechowywania i przetwarzania. W wyniku tych prac opracowano metamodel i profil UML, dla architektury modelowania danych metodą organizacji ich w dokumenty. Opracowano metody projektowania struktur dokumentów gromadzących informacje. Opiera się ona na założeniu, że dokumenty stanowią agregaty danych George Papamarkos, Lucas Zamboulis, Alexandra Poulovassilis, 2015]).
3.1. Przetwarzanie informacji
Informacje zawsze są o czymś, innymi słowy opisują coś co istnieje lub mogłoby zaistnieć. Jeżeli mówimy, że system informatyczny przetwarza informacje, to znaczy, że przetwarza dane, które są zapisanymi informacjami (dane oczywiście mogą nie nieść żadnej informacji, ale w tej publikacji się tym nie zajmuję).
![Przetwarzanie informacji o tym co jest i co zaszłoNa diagramie Przetwarzanie informacji o tym co jest i co zaszło pokazano schematycznie związek między światem rzeczywistym (Świat opisywany danymi), danymi zapisanymi metodami tradycyjnymi (Dokumenty papierowe (nośniki danych) i danymi zapisanymi i przetwarzanymi z użyciem oprogramowania, tu: Aplikacja zarządzająca danymi.
Innymi słowy Dokumenty papierowe (nośniki danych) "niosą" dane stanowiące określone informacje o świecie rzeczywistym. Stanowią więc sobą informacje o historii, czyli informacje o stanie "świata rzeczywistego" w czasie przeszłym. Mogą to być także informacje o czasie przyszłym, są to np. plany lub prognozy.
Celem tworzenia oprogramowania jest przetwarzanie danych, stanowiących określone informacje, które opisują określone elementy świata rzeczywistego. Struktura tych danych, powinna odpowiadać strukturze rzeczy, które są opisywane (o których informacje przetwarzamy) [Mountriver 2011,Smith 1985]. Wynalezienie komputera otworzyło nowe możliwości przetwarzania (wdrożenie oprogramowania - kierunek zmian), ale nie zmienia rzeczywistości opisywanej danymi przetwarzanymi w nim, gdzie same dokumenty jako takie, także są elementem tej rzeczywistości.
Zgodnie z tym co już napisano, informacje opisują albo zdarzenie albo obiekt. Złożone dokumenty mogą zawierać wiele informacji, jednak powinno być możliwe przyporządkowanie danego dokumentu do jednego z typów: opis obiektu lub opis zdarzenia, gdyż jak już napisano, jeden dokument może (powinien) mieć jeden kontekst, z uwagi na wymaganą jednoznaczność jego treści (kontekst). W dalszej części opisano dlaczego.](https://it-consulting.pl//wp-content/uploads/2020/10/przetwarzanie-informacji-o-tym-co-jest-i-co-zaszlo.png)
Rysunek 1. Przetwarzanie informacji o tym co jest i co zaszło
Na diagramie Rysunek 1. Przetwarzanie informacji o tym co jest i co zaszło pokazano schematycznie związek między światem rzeczywistym (Świat opisywany danymi), danymi zapisanymi metodami tradycyjnymi (Dokumenty papierowe (nośniki danych) i danymi zapisanymi i przetwarzanymi z użyciem oprogramowania, tu: Aplikacja zarządzająca danymi.
Innymi słowy Dokumenty papierowe (nośniki danych) “niosą” dane stanowiące określone informacje o świecie rzeczywistym. Stanowią więc sobą informacje o historii, czyli informacje o stanie “świata rzeczywistego” w czasie przeszłym. Mogą to być także informacje o czasie przyszłym, są to np. plany lub prognozy.
Celem tworzenia oprogramowania jest przetwarzanie danych, stanowiących określone informacje, które opisują określone elementy świata rzeczywistego. Struktura tych danych, powinna odpowiadać strukturze rzeczy, które są opisywane (o których informacje przetwarzamy) [Mountriver 2011,Smith 1985]. Wynalezienie komputera otworzyło nowe możliwości przetwarzania (wdrożenie oprogramowania – kierunek zmian), ale nie zmienia rzeczywistości opisywanej danymi przetwarzanymi w nim, gdzie same dokumenty jako takie, także są elementem tej rzeczywistości.
Zgodnie z tym co już napisano, informacje opisują albo zdarzenie albo obiekt. Złożone dokumenty mogą zawierać wiele informacji, jednak powinno być możliwe przyporządkowanie danego dokumentu do jednego z typów: opis obiektu lub opis zdarzenia, gdyż jak już napisano, jeden dokument może (powinien) mieć jeden kontekst, z uwagi na wymaganą jednoznaczność jego treści (kontekst). W dalszej części opisano dlaczego.
![Obiekt i jego historiaW sytuacji przedstawionej na diagramie Obiekt i jego historia mamy jeden obiekt i trzy związane z nim zdarzenia. To znaczy, że mogły by istnieć - co postuluję - cztery niezależne opisy (dokumenty): jeden opisujący obiekt i trzy opisujące zaszłe zdarzenia. Te cztery opisy to hipotetyczne cztery dokumenty, jednak każdy z nich byłby opisem albo zdarzenia albo obiektu. Kluczowe jest przyjęcie zasady, że dokument może mieć jeden z dwóch możliwych kontekstów: informacje o obiekcie lub informacje o zdarzeniu.
Pojęcie przedmiot (subject), zobrazowano i opisano w dalszej części na diagramie Rozszerzony model pojęciowy. Ma ono tylko dwa typy: zdarzenie oraz obiekt ("Data are symbols that represent the properties of objects and events" [Ackoff, R.L., 1999. ]). Taksonomia ta ma kluczowe znaczenie w opracowanym metamodelu. Źródłem tego podziału jest kontekst opisu, co pokazano na diagramie Obiekt i jego historia. Obiekt niezmiennie trwa w czasie. Może on ulegać zmianom: ma cykl życia, ale co do zasady trwa, zmiany są (mogą być) skutkiem określonych zdarzeń, powiązanych z tym obiektem. Zdarzenia jednak nie muszą zmieniać przedmiotu, mogą go jedynie "dotyczyć". Obiekty (object) i zdarzenia (events) definiowane są przez ich cechy (properties).
To co łączy zdarzenia z obiektami to określone czas i miejsce zdarzenia. Obiekt, którego zdarzenie dotyczy, jest elementem jego opisu. Obiekt niezmiennie trwa w czasie, więc wiąże się z nim także pojęcie jego cyklu życia: jest to jego historia. Historia obiektu to zbiór powiązanych z nim zdarzeń (których dany obiekt był uczestnikiem). Zdarzenia i obiekty opisujemy z użyciem cech. Zdarzenie i obiekty muszą być unikalne (odróżniamy je od siebie), jednak wartości poszczególnych cech nie muszą już być unikalne, np. ta sama data wielu różnych zdarzeń, to samo miejsce wystąpienia różnych zdarzeń. Wartości (value) cech (properties) nie są ani zdarzeniem ani obiektem, choć mogą mieć złożoną strukturę (np. pełny adres pocztowy jest wartością cechy położenie, ale nie jest ani zdarzeniem ani obiektem). To dlatego nie są one typem tematu. Temat opisu to albo obiekt albo zdarzenie. Jeżeli przyjmiemy założenie, że kontekst określa znaczenie pojęć, opis zaś składa sie z pojęć, to w konsekwencji określony dokument, by jego treść była jednoznaczna, może mieć tylko jeden kontekst.
Z perspektywy przetwarzania danych nie ma znaczenia czy zdarzenie (event) jest z przeszłości czy przyszłości bo oba maja identyczne cechy (dane opisujące: atrybuty). Pojecie czasu ma znaczenie dla człowieka który interpretuje dane (patrz A-theory and B-theory, [Mountriver 2011]). Dlatego system informatyczny posortuje chronologicznie zdarzenia, ale określenie czy dane zdarzenie było czy będzie, wymaga skorelowania daty tego zdarzenia (jego cecha) z datą dnia gdy pytanie takie jest zadane. Innymi słowy pytanie o "zdarzenia wczorajsze" każdego dnia da inny wynik mimo, że dane o zdarzeniach nie ulegają zmianie.](https://it-consulting.pl//wp-content/uploads/2020/10/obiekt-i-jego-historia-w-sytuacji-przedstawionej.png)
Rysunek 2. Obiekt i jego historia
W sytuacji przedstawionej na diagramie Rysunek 2. Obiekt i jego historia, mamy jeden obiekt i trzy związane z nim zdarzenia. To znaczy, że powinny tu istnieć – co postuluję – cztery niezależne opisy (dokumenty): jeden to wersjonowany opis obiektu, pozostałe trzy to opisy faktów do jakich doszło w związku z tym obiektem. Kluczowe jest przyjęcie zasady: dokument może mieć jeden z dwóch możliwych kontekstów: informacje o obiekcie lub informacje o zdarzeniu.
Pojęcie przedmiot (subject), zobrazowano i opisano w dalszej części na diagramie Rozszerzony model pojęciowy. Ma ono tylko dwa typy: zdarzenie oraz obiekt (“Data are symbols that represent the properties of objects and events” [Ackoff, R.L., 1999. ]). Taksonomia ta ma kluczowe znaczenie w opracowanym metamodelu. Źródłem tego podziału jest kontekst opisu, co pokazano na diagramie Rysunek 2. Obiekt i jego historia. Obiekt niezmiennie trwa w czasie. Może on ulegać zmianom: ma cykl życia, ale co do zasady trwa, zmiany są (mogą być) skutkiem określonych zdarzeń, powiązanych z tym obiektem. Zdarzenia jednak nie muszą zmieniać przedmiotu, mogą go jedynie “dotyczyć”. Obiekty (object) i zdarzenia (events) definiowane są przez ich cechy (properties).
To co łączy zdarzenia z obiektami to określone czas i miejsce zdarzenia. Obiekt, którego zdarzenie dotyczy, jest elementem jego opisu. Obiekt niezmiennie trwa w czasie, więc wiąże się z nim także pojęcie jego cyklu życia: jest to jego historia. Historia obiektu to zbiór powiązanych z nim zdarzeń (których dany obiekt był uczestnikiem). Zdarzenia i obiekty opisujemy z użyciem cech. Zdarzenie i obiekty muszą być unikalne (odróżniamy je od siebie), jednak wartości poszczególnych cech nie muszą już być unikalne, np. ta sama data wielu różnych zdarzeń, to samo miejsce wystąpienia różnych zdarzeń. Wartości (value) cech (properties) nie są ani zdarzeniem ani obiektem, choć mogą mieć złożoną strukturę (np. pełny adres pocztowy jest wartością cechy położenie, ale nie jest ani zdarzeniem ani obiektem). To dlatego nie są one typem tematu. Temat opisu to albo obiekt albo zdarzenie. Jeżeli przyjmiemy założenie, że kontekst określa znaczenie pojęć, opis zaś składa sie z pojęć, to w konsekwencji określony dokument, by jego treść była jednoznaczna, może mieć tylko jeden kontekst.
Z perspektywy przetwarzania danych nie ma znaczenia czy zdarzenie (event) jest z przeszłości czy przyszłości bo oba maja identyczne cechy (dane opisujące: atrybuty). Pojęcie czasu ma znaczenie dla człowieka który interpretuje dane (patrz A-theory and B-theory, [Mountriver 2011]). Dlatego system informatyczny posortuje chronologicznie zdarzenia, ale określenie czy dane zdarzenie było czy będzie, wymaga skorelowania daty tego zdarzenia (jego cecha) z datą dnia gdy pytanie takie jest zadane. Innymi słowy pytanie o “zdarzenia wczorajsze” każdego dnia da inny wynik mimo, że dane o zdarzeniach nie ulegają zmianie.
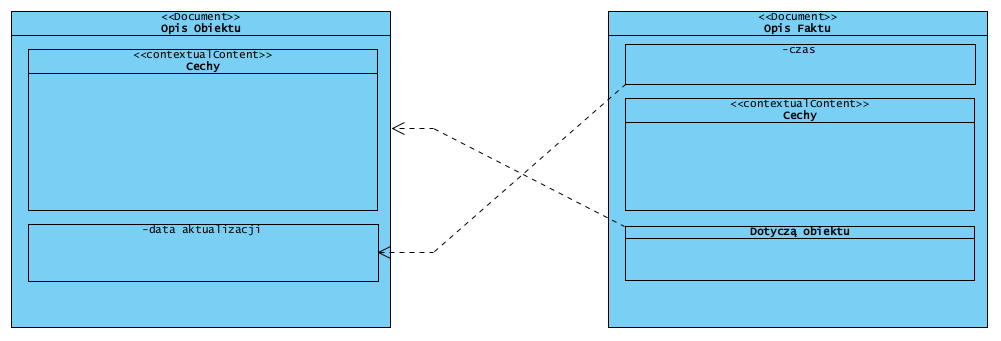
Kluczowe reguły: dokument jest klasyfikowany albo jako opis obiektu albo faktu, opis faktu nie może być modyfikowany, opis obiektu może być (aktualizacja stanu faktycznego). Modyfikacja opisu obiektu jest faktem (który należy udokumentować), fakt musi dotyczyć co najmniej jednego obiektu.
(kompletny tekst ma 26 stron, zawiera kompletny opis metody i metamodel informacji organizowanych w dokumenty, przykłady użycia metody; data i miejsce publikacji będą tu podane w komentarzach, które można subskrybować, publikacja ukazała sie w 2021 roku )
Uzupełnienie
[Marzec 2023] Zarządzanie zestawem powiązanych danych jako agregatem jest bardzo efektywne. Traktowanie dokumentów jako agregatów to sposób na budowanie bardzo efektywnej architektury. Niedawno ukazała się bardzo ciekawa prezentacja na temat agregatów w DDD. Autor pokazuje jakim ogromnym problemem są zapytania do relacyjnych baz danych już w systemach mających kilkadziesiąt tabel i jakim “dobrodziejstwem” jest operowanie pojęciami Aggregate i Value Object.
Struktura i treść dokumentu (formularz jako agregat) może być zapisana i potem odzyskana w bazie danych o relacyjnym modelu danych, poniżej struktura zapytania SQL do tej bazy (kilkaset tablic):
Po obejrzeniu całej powyższej prezentacji pomyśl, że struktura i treść dokumentu (formularz jako agregat) może być wyrażona także w postaci jednego ciągu znaków XML (lub JSON, itp.) jako wartość jednego pola dowolnej bazy danych (szczególnie bazy NoSQL) a zapytanie do takiej bazy danych to polecenie na kilka słów. Wtedy obiekt niosący taki XML jest właśnie tym ‘entity’, korzeniem i tożsamością całego agregatu, tyle, że powyższe monstrualne zapytania SQL do relacyjnej bazy nie są już potrzebne.
Agregat – kontekst treści formularza
[Grudzień 2023] Jako ludzie zapisujemy informacje z zasady w określonym kontekście. To co dla nas jest informacją, dla papieru (i każdego innego nośnika) jest znakiem (znakami). Znaki do dane, których nie rozumie ani nośnik ani stos reguł (procedura). Czyli komputer też nie rozumie!
Standardową “ludzką” formą zapisu są dokumenty i formularze. Dokument ma kontekst, każda część dokumentu także. Poniższy formularz to dwa identyczne zestawy danych o dwóch osobach, pełniących jednak różne role. Ten dokument to: kontekst dokumentu oraz zagnieżdżone dwa konteksty osób (ich role).
Wyobraźmy sobie, że mamy kilkadziesiąt takich różnych dokumentów, każdy ma swój własny inny kontekst, i na każdym powtarzają się pewne dane (w innym kontekście). Żadna z tych danych nie jest liczbą, na której można wykonać operację matematyczną.
Jaki sens ma ładowanie danych z wielu różnych formularzy (pól i ich wartości) do jednego systemu relacyjnych tabel i pozbawianie ich kontekstu i redundancji? Ile pracy należy włożyć w każdorazowy zapis i odtworzenie każdego z tych formularzy?

O tym, że liczby nie są dobrym pomysłem na “bycie danymi” pisał także :
Why the number input is the worst input. Think that web form has got your number? If you used input type=”number”, you may be surprised to find that it doesn’t.


Padają pytania o wydajność, tu testy:
Győrödi, C., Győrödi, R., Pecherle, G., & Olah, A. (2015). A comparative study: MongoDB vs. MySQL. 2015 13th International Conference on Engineering of Modern Electric Systems (EMES), 1?6. https://doi.org/10.1109/EMES.2015.7158433
oraz tu w innej formie:
Gyorödi, C., Gyorödi, R., & Sotoc, R. (2015). A Comparative Study of Relational and Non-Relational Database Models in a Web- Based Application. International Journal of Advanced Computer Science and Applications, 6(11). https://doi.org/10.14569/IJACSA.2015.061111
Stosowanie agregatów ma też ogromną zaletę: pozwala unikać serii operacji get/set, czyli jednej z najgorszych praktyk kodowania:
https://dev.to/scottshipp/avoid-getters-and-setters-whenever-possible-c8m