Tym razem o czymś co potrafi zabić 😉 czyli czym jest dokument oraz fakt i obiekt. Czym się różni zakup kilku produktów, w tym samym sklepie, w np. godzinnych odstępach czasu, od zakupu wszystkich razem? Poza formą udokumentowania, niczym: w sklepie to samo i tyle samo zeszło ze stanu magazynu, a my wydaliśmy w obu przypadkach tyle samo pieniędzy (o promocjach później)! W pierwszym przypadku mamy kilka faktów zakupu, w drugim, jeden, ale zawsze tyle samo obiektów (produkt). Faktura (paragon) to dokument opisjący fakt, przedmiot sprzedaży jest obiektem. Tu obiektem jest opisywany przedmiot zakupu. Ten artykuł to przykład architektury usługi aplikacji, która jest nieczuła na takie różnice.
Wprowadzenie
Żeby uporządkować treść, w stosunku to architektury aplikacji tu nie będę używał pojęć “klasa i obiekt” a komponent i dokument. Pojęcia obiekt i fakt tu będą dotyczyły świata realnego, to odpowiednio: opisywany przedmiot i zdarzenie z nim powiązane. Innymi słowy: dokument może opisywać obiekt lub zdarzenie z nim powiązane. Np. produkt oraz fakt jego sprzedania (dwa byty: separowanie kontekstu dokumentów). Konkretne oprogramowanie jako system, to komponenty (w UML obiekty określonej klasy) oraz dane zorganizowane np. jako dokumenty (dokument: nazwana, określona struktura danych). Aplikacje przetwarzają dane opisujące realny świat, co ładnie pokazał i opisał Smith :

Projektowanie oprogramowania to tworzenie jego modelu, potem pozostaje już tylko jego implementacja. Obecnie prace projektowe i przygotowanie do implementacji także są zaliczane do “programowania” .
Projekt systemu sprzedaży
Każda analiza powinna być oparta na ontologii z dziedziny problemu. Dzięki czemu nazwy dokumentów, atrybutów i ich wartości będą spójne, jednoznaczne i niesprzeczne. Poniżej prosty model pojęciowy dla dziedziny opisywanego tu problemu:
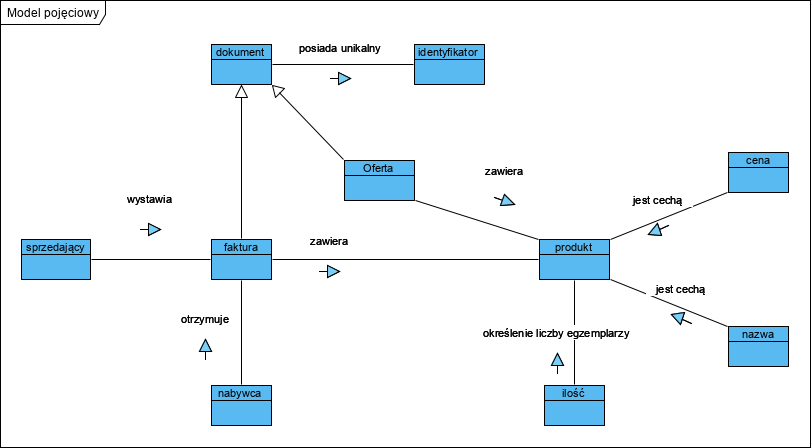
(UWAGA! Powyższy model nie jest żadnym “modelem dziedziny” ani “modelem danych”. To model pojęciowy).
Modele pojęciowe służą do zarządzania systemem pojęć (ontologia) dla danego modelu oprogramowania. Testowanie tego modelu polega na sprawdzeniu czy każda para połączonych semantycznie pojęć tworzy poprawne i prawdziwe(!) zdanie w języku naturalnym (tu musimy brać poprawkę na fleksję języka polskiego), np. ‘sprzedający wystawia fakturę’ (fakt) lub ‘faktura jest dokumentem’ (typ).
Oprogramowanie służy do przetwarzania danych, dlatego warto opisać jak się to odbywa. Bardzo wygodną metodą projektowania struktur danych dokumenty (w tym opisie diagram struktur złożonych notacji UML). Po pierwsze są one zrozumiałe dla przyszłego użytkownika, po drugie metoda ta pozwala uwolnić się od wad modeli relacyjnych: usunięcie redundancji nazw co prowadzi do utraty ich kontekstu. Dokumenty często mają różny kontekst, znaczenie pojęć zależy od kontekstu. Relacyjny model danych, pozbawiony redundancji, jest stratny: utrwalone dane nie stanowią żadnej informacji a dokumentem jest dopiero wynik zapytania SQL do tabel.
W przypadku opisywanego tu projektu wygląda to tak:

Mamy tu dwa dokumenty: Oferta i Faktura. Pojęcie Produkt ma swoją definicję realna (definicja atrybutowa: poprzez cechy): jest to “cos co ma nazwę, cenę i ilość”. Atrybuty Produktu na dokumentach przyjmują wartości opisane tym typem. Po drugie dokument niesie kontekst więc nadaje nazwie znaczenie: np. data to data faktury i data oferty. To nie są te same daty, a produkt oferowany (jako atrybut oferty) nie musi być tym samym produktem sprzedanym (jako atrybut Faktury).
Projekt powyższy pokazuje także ważną rzecz: separowanie danych o obiektach (produkty) i faktach (faktura). Nie należy na jednym dokumencie łączyć (mieszać) kontekstów (uwspólnianie danych w modelu relacyjnym). (Więcej na temat separacji kontekstów obiektu i faktu w publikacji “Chapter 3 Digital Documents as Data Carriers and a Method of Data Management Guaranteeing the Unambiguity of the Recorded Information: Ontology-Oriented Data Management and Document Databases“).
Poniżej, na diagramie sekwencji, widać, że dla komponentu zarządzającego stanami magazynowymi nie ma żadnego znaczenia ile jest (było) faktur, operacje zmiany ilości to pojedyncze operacje. Tak zaprojektowana aplikacja jest odporna na to ile produktów jest na ofercie i fakturze, mogą to być różne ilości. Oba te dokumenty: oferta i faktura, to całkowicie odrębne konstrukcje, to dokumenty rządzące się każdy inną logiką i mające każdy inny cykl życia (tu np. Oferta nie jest utrwalana). Często stosowane konstrukcje, takie jak “dziedziczenie faktury i oferty po dokumencie” są tu najgorszym pomysłem.
Architektura. Nasza aplikacja to kilka współpracujących komponentów:
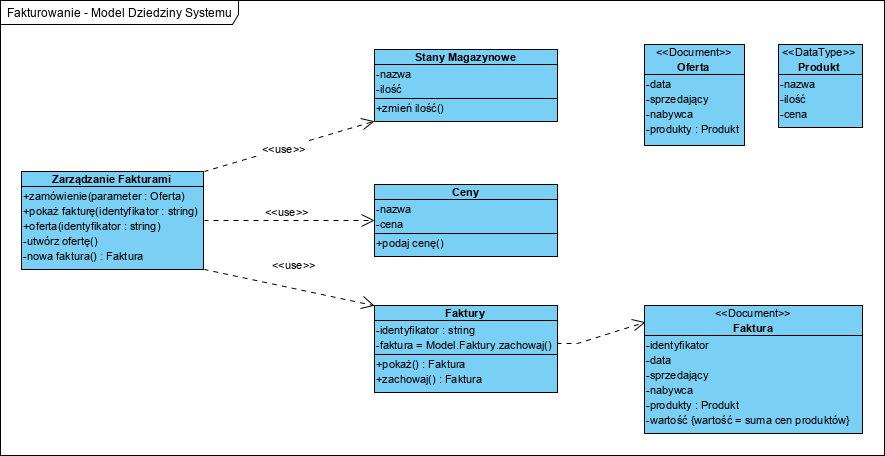
Klasy oznaczone stereotypem ‘Document’ to ciągi znaków (np. XML) stanowiące wartości atrybutów i parametry wywołań operacji. (w UML: “Document A human-readable file. Subclass of File.” .
Model architektury to statyczny model, a ten może być niezrozumiały, dlatego zawsze wzbogacamy projekt techniczny architektury modelem dynamiki systemu: diagramem sekwencji. Diagram taki powinien powstać dla każdej usługi aplikacji (przypadku użycia):
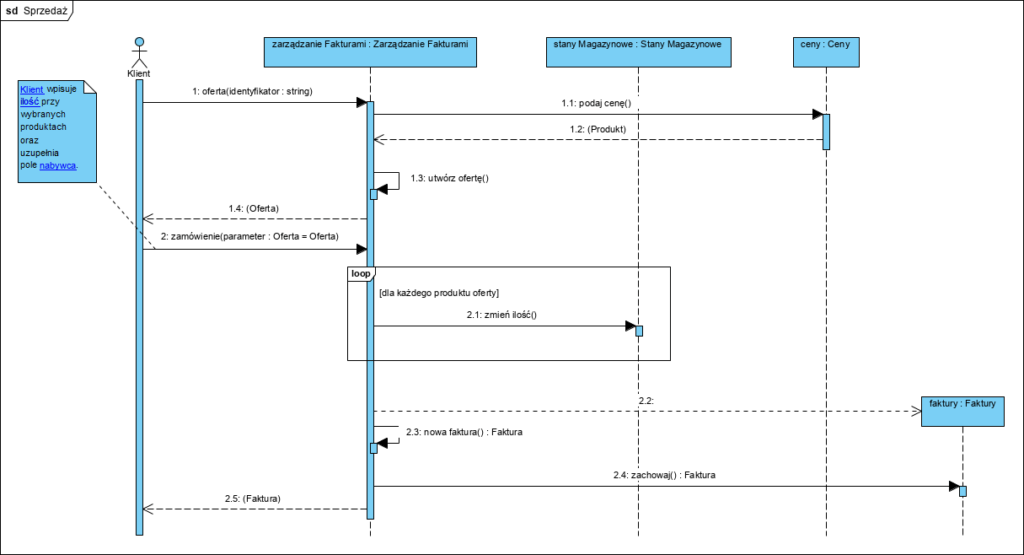
Powyższy diagram pokazuje współpracę komponentów, opisane wcześniej dokumenty są wartościami atrybutów i parametrami wywoływanych operacji i ich odpowiedzi. Powyższa architektura z powodzeniem wykona także usługi wglądu do historycznych faktur czy aktualizację cennika.
Poprawna obiektowa architektura i kompletny projekt techniczny aplikacji (model PIM) opisuje precyzyjnie jak wykonać implementacje i nie zawiera projektu żadnej bazy danych, ani tym bardziej zapytań SQL. Implementacja utrwalania nie może mieć wpływu na logikę biznesową systemu ani nawet zawierać jej!
Samo opracowanie relacyjnego modelu danych oraz zapytań SQL, by generować powyższe dokumenty z wariantami dotyczącymi różnych ilości oferowanych i zamawianych, zajmie kilkakrotnie więcej czasu niż opracowanie powyższego, gotowego do implementacji, projektu. Opracowanie modelu relacyjnego bazy danych, wymagało by dodatkowo wiedzy o wszystkich pozostałych dokumentach w tym systemie, a tego z reguły nigdy nie wiemy na początku!
Powyższy model to w pełni współpracujące obiekty mające operacje, a podstawowym związkiem modelu obiektowego jest związek użycia (wywołania operacji), czyli nie jest to tak zwany anemiczny model dziedziny.
Tu także warto zwrócić uwagę na kolejny częsty błąd i antywzorzec w projektach deklarowanych jako obiektowe: stosowanie dziedziczenia. Jest to mieszanie modeli pojęciowych i architektury (dziedziczenie, jako współdzielenie, łamie podstawową zasadę paradygmatu obiektowego jaką jest hermetyzacja). Dlatego model pojęciowy i model architektury to z zasady dwa odrębne modele z powodów jak wyżej opisane.

Podsumowanie
Powyższy opis to krótki ale praktycznie kompletny Opis Techniczny Oprogramowania. Wymaga niewielkich uzupełnień (ewentualne schematy opisujące metody operacji). Wykonanie implementacji na jego podstawie nie powinno sprawić problemu osobie radzącej sobie z czytaniem notacji UML. Projekt jest na tyle precyzyjny, że stanowi utwór w rozumieniu prawa autorskiego (programista nie ma tu żadnej swobody decyzji w pisaniu kodu dla tej części). Projekt taki to także opis określonego mechanizmu działania, zawiera więc opis know-how i jako jego udokumentowana forma chroni to know-how (ustawa o przeciwdziałaniu nieuczciwej konkurencji).
Dlatego każdy program komputerowy napisany na podstawie takiej dokumentacji, z zasady jest utworem zależnym. Developer ma prawa autorskie osobiste do kodu jaki napisze, ale nie ma prawa do dysponowania tym kodem: ma je posiadacz praw majątkowych do projektu, który jest tu utworem pierwotnym. Jedyny wybór jaki ma tu developer to wybór technologii jakiej użyje.
Powyższe diagramy wykonano z użyciem Visual Paradigm, poniżej przykładowy projekt:



