Wprowadzenie
Coraz częściej czytamy o środowiskach “chmurowych” (nadal nie mogę się przekonać do pisania tego bez cudzysłowu). Nawet tak zaawansowane jak Amazon WS czy AZURE, są nadal bardzo często wykorzystywane tylko jako hosting aplikacji. Oba te serwisy można wykorzystywać jako sieciowy dysk, środowisko systemowe (Windows, Linux), bazę danych SQL, ale także jako bazy NoSQL.
Jednym z najistotniejszych elementów systemów informacyjnych (patrz: information science) jest utrwalanie danych (pamiętajmy, że dane to zapisy, a informacja to to, co rozumie człowiek, który je czyta). Niedawno nawiązywałem do problemu utrwalania danych.

Poprawna obiektowa architektura i kompletny projekt techniczny aplikacji (model PIM) opisuje precyzyjnie jak wykonać implementacje i nie zawiera projektu żadnej bazy danych, ani tym bardziej zapytań SQL. Implementacja utrwalania nie może mieć wpływu na logikę biznesową systemu ani nawet zawierać jej! (źr.: Dokument a kumulacja faktów: OOAD i model dziedziny systemu) Prosty diagram po lewej stronie pokazuje problem opisany przez Smith’a jako “Computers, Models, and the Embedding World, The Limits of Correctness.”
Komputer (rozumiany jako procesor, pamięć i program) stanowi dla człowieka narzędzie pracy.
Cechą komputera jest w ogromnej większości przypadków odwzorowywanie tego co zastępujemy komputerem, a tak zwane systemy biznesowe, zastępują papierowe formy przetwarzania i przechowywania informacji. Systemy ERP, CRM, Workflow, Sklepy internetowe, Archiwa, i wiele innych to tak na prawdę dokumenty i ich treść.
Istota problemu polega na tym, że określone, dostępne technologie same z siebie często stwarzają ograniczenia tego co mogą (potrafią) odwzorować, i mimo upływu czasu i postępu technologii, analiza i projektowanie zarządzania informacją nadal jest jednym z największych problemów wdrożeń systemów.
SQL vs. NoSQL
SQL
Skrót NoSQL jest intepretowany jako “nie SQL” lub “nie tylko SQL” (Not only SQL). SQL (Structured Query Language) to język zapytań do baz danych o relacyjnym modelu danych (ang. RDBMS: Relational Data Base Management System). Cechą tego modelu danych jest usuwanie redundancji i podział danych na tabele i słowniki pól tych tabel, oraz związki między nimi (relacje). W efekcie otrzymujemy schematy tabel i relacji między nimi np. takie:
A nawet takie:

Odtworzenie dokumentu (formularza) będącego np. fakturą lub deklaracją podatkową, wymaga wykonania szeregu bardzo skomplikowanych operacji łączenia danych z tych tabel i odwzorowania ich pierwotnej postaci np. faktury. W tego typu bazach danych fizycznie nie ma żadnych dokumentów.
Drugim problemem jaki stwarza model relacyjny, jest konieczność jego przebudowy praktycznie zawsze, gdy zmieni się struktura przechowywanych w nim dokumentów (opracowanie nowego modelu, migracja danych do nowego modelu – bywa że niemożliwa w 100%, aktualizacja zapytań SQL do nowej struktury bazy danych).
Biorąc pod uwagę fakt, że realny świat to ciągłe zmiany, model relacyjny jest w tym przypadku po prostu nieadekwatny.
Koszty utrzymania i rozwoju systemów zarzadzania danymi (i aplikacjami, które je wykorzystują) w modelu relacyjnym, są wielokrotnie wyższe niż pierwotne ich wdrożenie .
Po co więc wymyślono te relacyjne bazy? To były czasy gdy pamięć była najkosztowniejszym zasobem komputera zaś dane między systemami w zasadzie nie były wymieniane! Było kilka zalet, np. brak błędów nazewnictwa itp. więcej o nich w sieci można poczytać, jednak moim zdaniem baza danych będąca implementacją tak zwanych związków pojęciowych (tym są relacyjne modele danych) nie sprawdza się bo nie modeluje obiektów świata rzeczywistego a jedynie ich nazwy i powiązania między nimi a to ogromna różnica. (źr.: SQL albo NoSQL, oto jest pytanie – 2011 r.)
NoSQL
Jednym z typowych przykładów bazy danych typu NoSQL są bazy typu key-value i ich odmiany . Z uwagi na ich cechy i powszechność skupię się na tego typu bazach.
Wśród tego typu baz są tak zwane bazy dokumentowe. Idea tego typu baz danych realizuje jedno podstawowych założeń obiektowego paradygmatu (role obiektów): repozytorium nie służy do przetwarzania treści a jedynie do jej utrwalania i szybkiego przywoływania (dostępu). Przetwarzaniem danych (treści) zajmują komponenty odpowiedzialne wyłącznie za realizację logiki aplikacji. Skoro repozytorium nie przetwarza treści, jest ono – przechowywana treść i jej struktura – neutralnym elementem. Dlatego operujemy tu często pojęciem plik, którym zależnie od typu bazy, może być np. ciąg znaków XML lub JSON albo po prostu ciąg binarny (czyli “cokolwiek”). Taka baza to hipotetyczne dwie kolumny: pierwsza zawiera identyfikatory wierszy a druga przechowywaną treść. I teraz zależnie od typu bazy i logiki aplikacji, która ją wykorzystuje, tą treścią może by ciąg znaków (np. XML, JSON) lub dowolny ciąg znaków binarny (czyli XML także, ale także np. zdjęcie lub plik edytora tekstów).
Przykładem bazy dokumentowej jest Amazon DynamoDB. Poniższy diagram pokazuje w uproszczeniu idee tej bazy i porównanie z typową modelem relacyjnym: odtworzenie dokumentu z bazy relacyjnej (po lewej) wymaga skomplikowanych operacji łączenia tabel, po prawej stronie mamy zaś zestaw ciągów znaków, każdy stanowi sobą kompletny już dokument, mogą one mieć różną strukturę. Pobranie dokumentu z bazy po prawej odbywa się zawsze prostym zapytaniem, takim samym,, bez względu na strukturę tych danych.
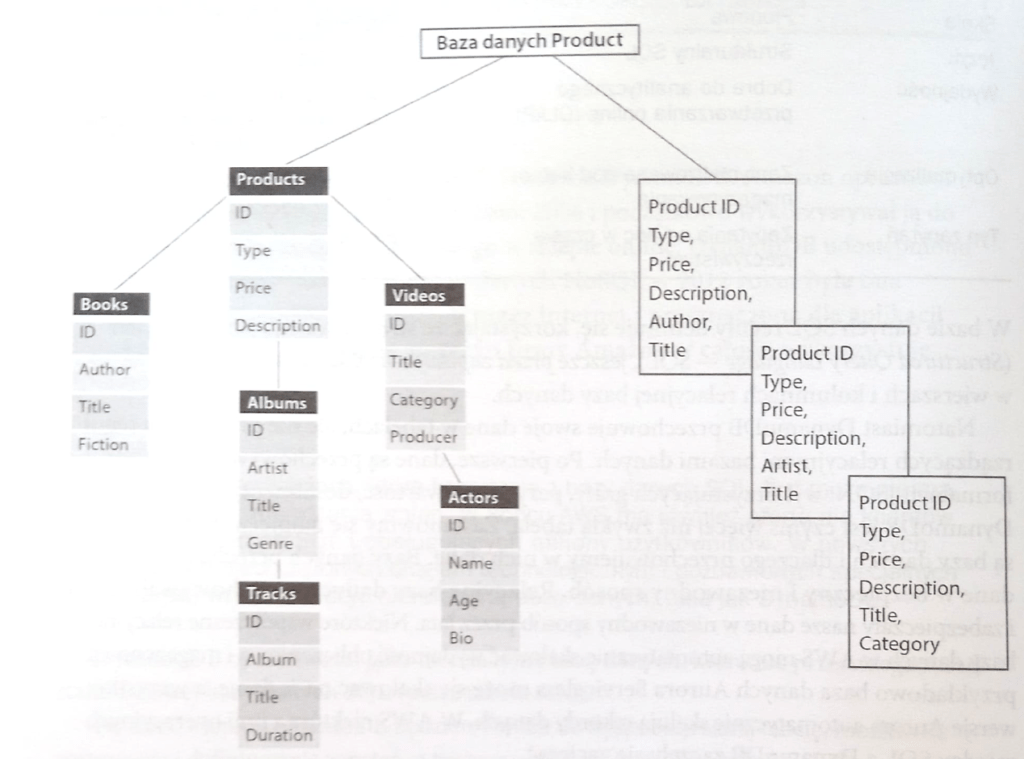
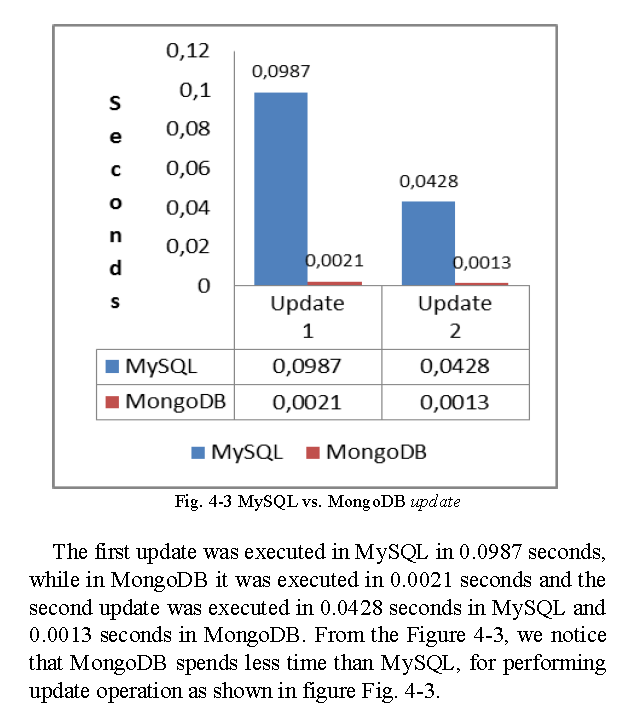
Dzięki temu osiągamy dwie kluczowe korzyści: zmieniająca się w czasie struktura dokumentów nie wpływa na bazę danych, czas pobrania dokumentu jest bardzo krótki i nie zależy od struktury dokumentu. Różnicę efektywności pokazano poniżej:

Dokument jako struktura danych
Opisane bazy NoSQL mają szereg zalet w stosunku do baz danych w modelu relacyjnym. Jednak problem tworzenia modeli relacyjnych jest zastępowany problemem modelowania struktur dokumentów . Nie jest to jednak problem budowania znormalizowanych relacyjnych struktur danych. Jest to problem natury czysto semantycznej: rzecz w tym czym jest dokument i czym są pola, z których on się składa. Jest wiele podejść do tego zagadnienia, uważam, że kluczowe jest odkrycie i zrozumienie co opisuje dany dokument. Po drugie istotne jest umiejętne zaprojektowanie logiki aplikacji. Dlatego repozytoria NoSQL z zasady nie biorą udziału w logice biznesowej ale struktura dokumentów determinuje logikę ich przetwarzania. Rolą repozytorium jest wyłącznie utrwalanie i udostępnianie. Poniżej przykład dość typowy: faktury i opisy produktów (opis produktu jako Karta Produktu): mimo tego, że oba te typy dokumentów mają inną strukturę, mogą być przechowywane w jednej i tej samej bazie danych NoSQL.
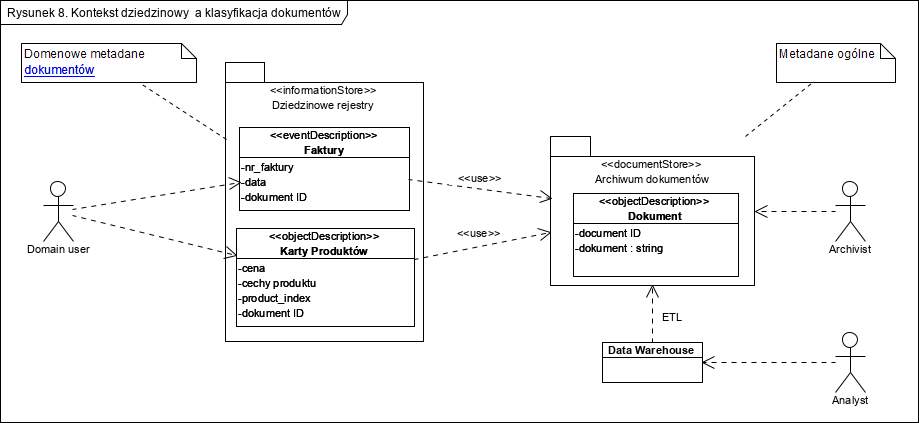
Baza dokumentowa służy wyłącznie do przechowywania danych. Kontekstowy i semantyczny dostęp do danych zapewniają dziedzinowe rejestry: dodatkowe proste tabele umieszczone przez repozytorium, w części aplikacyjnej. Z uwagi na to, że bazy dokumentowe nie nadają się do realizacji wyrafinowanych zbiorowych obliczeń na treści dokumentów, wykorzystuje się do tego typowe hurtownie danych.
[uzupełnienie miesiąc później] Z tego względu bardzo przydatny jest tu dobrze znany wzorzec projektowy Repozytorium (Repository). Istotą tego wzorca jest separacja kolekcji obiektów (np. nośników dokumentów) od logiki aplikacji za pomocą klasy realizującej interfejs do tej kolekcji. Poniżej wersja adresowana do chmury:
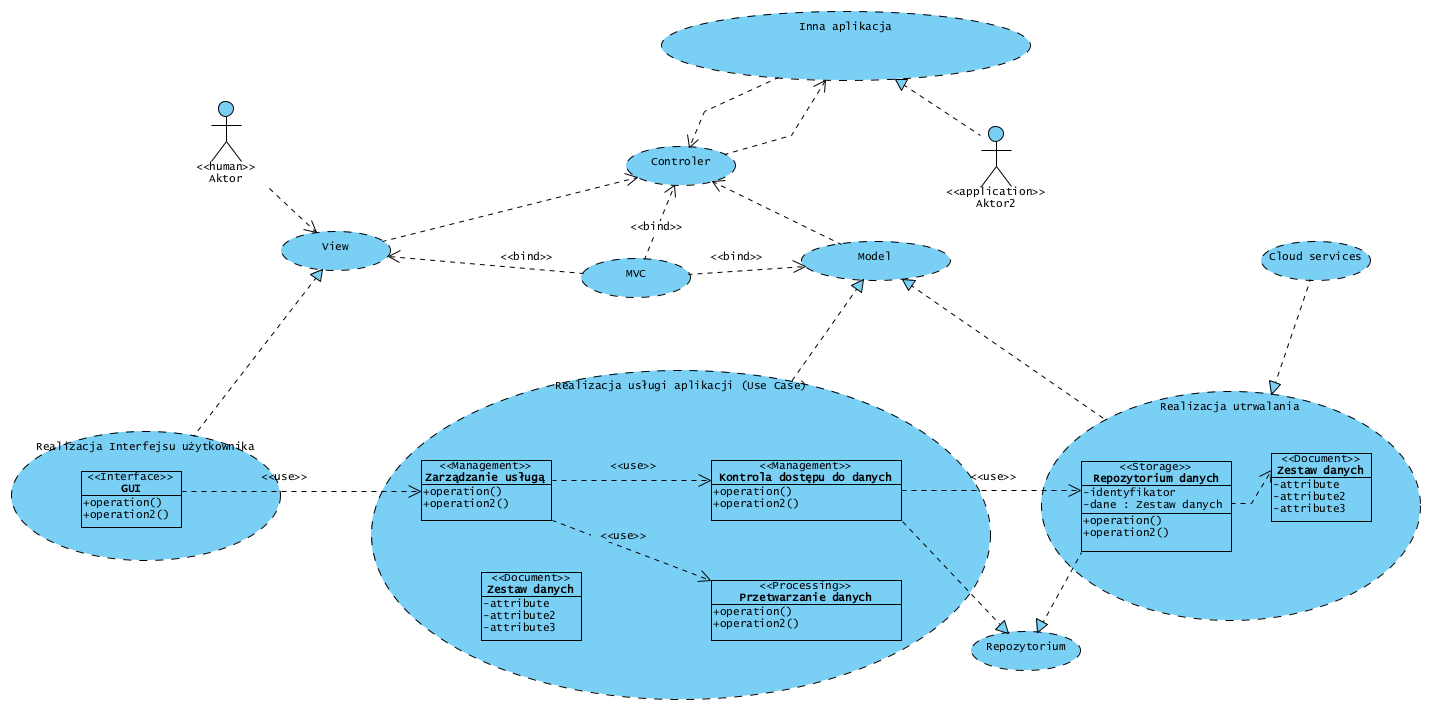
Realizacja utrwalania (zapis danych) to obiekty przechowujące (‘Storage’ Repozytorium danych) oraz dane (‘document’ Zestaw danych) przechowywane jako dokumenty (XML, JSON) lub pliki (baza key value). Dostęp do tej kolekcji zapewnia klasa ‘Management’ Kontrola dostępu do danych, stanowiąca zarazem interfejs do tej kolekcji. Interfejsów do jednego repozytorium może być więcej, realizują one wtedy kontekstowe udostępnianie danych z tej samej kolekcji. Tak więc Realizacja usługi to dziedzinowy kod aplikacji, zaś Realizacja utrwalania to chmurowa usługa taka jak bazy NoSQL dostępne w chmurze.
Chmury Amazon i AZURE
Ciekawym przykładem bazy dokumentowej jest DynamoDB. Jest to partycjonowana baza NoSQL mająca dwie kolumny z kluczem: jeden to standardowy dla tego typu bazy identyfikator, drugi to klucz wskazujący na strukturę definiującą format danych w trzeciej kolumnie przechowującej dane (dokumenty). Jest to baza przechowująca dane w formacie JSON, więc ich interpretacja wymaga definicji konkretnej struktury danych. dodatkowa kolumna (SortKey) pełni rolę definicji typu (identyfikator struktury). Jest to wygodne bo w systemach obiektowych łatwo definiuje się typy złożone, nadając każdemu rekordowi dodatkowy identyfikator, można intepretować pobrane dane.

Więcej informacji o repozytoriach Amazon, także Amazon S3 (bardzo szybka baza plików) znajdziecie w książce wydawnictwa Helion: Amazon Web Services . Analogiczne rozwiązanie oferuje AZURE.
Na zakończenie
Osobiście polecam rozważenie opisanych tu rozwiązań w swoich projektach. W obszarze dokumentów i zarządzania ich treścią są wręcz doskonałe. Model relacyjny, doskonały do obliczeń, niestety przegrywa z kretesem w aplikacjach biznesowych, gdzie zaczyna się liczyć przede wszystkim szybkość dostępu do ogromnej ilości danych oraz odporność na szybko zmieniające się wymagania co do struktury danych.
Problem projektowania struktur dokumentów, także w bazach dokumentowych, to osobne i trudne zagadnienie. Opisałem go w najnowszym artykule, który ukaże się za niedługo w wydawnictwie IGI Global: Emerging Challenges, Solutions, and Best Practices for Digital Enterprise Transformation.
C.d. czytaj Bazy NoSQL jako implementacje wzorców struktur informacji.



Ciekawy artykuł. Nie mam pytań co do zasadniczej części artykułu, natomiast do rys. 8.
Relacje zależności wskazują relację CLIENT/SUPPLIER, która sugeruje, że jeżeli zmieni się SUPPLIER to MOŻE (ale nie musi) zmienić się CLIENT.
1. Jaka jest intencja zastosowania tej relacji pomiędzy “Domain User” a <> Faktury i <> Karty Produktów? Czy nie wystarczyłaby relacja asocjacji?
2. Czy relacja użycia pomiędzy Faktury, Karty Produktów nie sugeruje, że te klasyfikatory zależą od Archiwum dokumentów i potencjalnie, jeżeli zmieni się archiwum to MOGĄ się też one zmienić (a chyba powinny być niezależne od archiwum).
3. W przypadku “Archivist” relacja zależności wydaje się mieć sens, w tym duchu, że jeżeli zmieniamy archiwum dokumentów z AMAZON na AZURE to sam archwiista musi się “zmienić”, tzn. nauczyć nowego narzędzia, strony, API itp.
Z góry dziękuję za odpowiedzi.
Najpierw kluczowa zasada: nie relacja a związek ;). W UML i obiektowym paradygmacie co do zasady mówimy o współpracy (interakcja), a to oznacza że CLIENT/SUPPLIER to USŁUGOBIORCA/USŁUGODAWCA. Innymi słowy obiekt CLIENT wywołuje operacje obiektu SUPPLIER. Nie ma tu mowy o jakimkolwiek zmienianiu czegokolwiek: nie jest prawdą, że związek zależności oznacza przenoszenie zmian z obiektu na obiekt. Tak więc zdanie “Relacje zależności wskazują relację CLIENT/SUPPLIER, która sugeruje, że jeżeli zmieni się SUPPLIER to MOŻE (ale nie musi) zmienić się CLIENT.” niestety nie jest prawdą, związek zależności niczego takiego nie sugeruje.
W UML związki użycia (zależność oznaczona ‘use’) oznaczają wyłącznie wywoływanie operacji obiektu, na który wskazuje grot strzałki, a nie że “jak się coś zmieni u dostawcy to także u klienta”. Niestety ogromna liczba autorów literatury dot. UML interpretuje pojęcie klasy i atrybutów jako związki znane z relacyjnych systemów baz danych, co jest kompletnym nieporozumieniem i nie jest prawdą (każda książka zawierająca choćby sugestię, że diagramy klas służą lub mogą służyć, do modelowania danych nadaje się wyłączne na śmietnik). Związek zależności ze stereotypem ‘use’ na modelu architektury (diagramie klas lub komponentów), reprezentuje wyłącznie wywołania operacji interfejsu na diagramach sekwencji i diagramach komunikacji. Związek zależności bez stereotypu ‘use’ oznacza ogólnie “korzystanie z..” bez wnikania w cel i metody użycia.
I teraz:
1. Aktor Domain user ma do dyspozycji (korzysta z) dokumentów typu Faktury i Karty produktów.
2. nigdzie nie ma na tym diagramie “relacji użycia pomiędzy Faktury, Karty Produktów”
3. aktor Archivist korzysta bezpośrednio (ma taka możliwość) z Archiwum dokumentów (nie ma to nic wspólnego z AZURE czy AMAZON).
Co więc mamy na diagramie 8?
1. dokumentowe repozytorium zawierające obiekty klasy Dokument, są to pary ID-string (czyli [klucz]-[treść dokumentu], tu nie ma znaczenia czy jest to baza key-value czy dokumentowa)
2. repozytorium dokumentowe z zasady nie przetwarza ich treści (pomijam sam fakt wyszukiwania w bazach dokumentowych), służy wyłącznie to utrwalania treści i jej pobierania
3. Dziedzinowe rejestry, Faktury i Karty Produktów, zawierają kluczowe atrybuty (metadane) dokumentów każdego z tych typów oraz kucz (ID) pozwalający pobrać tak znaleziony dokument z bazy dokumentowej, gdyż tu Dziedzinowe rejestry nie zawierają dokumentów, a jedynie odnośniki do nich w Archiwum dokumentów (bo tu są fizycznie składowane).
Rysunek 8. pochodzi z mojej publikacji w IGI Global gdzie jest więcej na ten temat.
Faktycznie relacja to złe określenie. To jest “relationship”, czyli związek. Teraz już zapamiętam :).
Nie jestem przekonany co do całkowitej nieprawdziwości tego co napisałem, bo w specyfikacji UML mamy:
rozdział 7.7.1 – “A Dependency signifies a supplier/client relationship between model elements where the modification of a supplier may impact the client model elements.”.
rodział 7.7.3.1. – “A Dependency implies that the semantics of the clients are not complete without the suppliers.”.
Nie napisałem, że na pewno się zmieni, tylko, że może – zgodnie ze specyfikacją jak się wydaje. “MAY impact” the client model elements. Jeżeli ma wpływ to znaczy, że coś się może zmienić pod tym wpływem.
Co więcej powyższe oznacza moim zdaniem, że związek relacji powinien być stosowany do “impact analysis”.
I znowu jak wyżej co do związku użycia – jeżeli operacja zmienia np. swoje argumenty to również musi się zmienić client, który tą operację wywołuje. Jeżeli dodajemy nową operację, to klient również może ją wykorzystać, chodź nie musi. Oczywiście w samym UML jest: 7.8.23.1 “A Usage is a Dependency in which the client Element requires the supplier Element (or set of Elements) for its full implementation or operation”, co nie potwierdza bezpośrednio tej tezy, ale wydaje się naturalne.
“Związek zależności bez stereotypu ?use? oznacza ogólnie ?korzystanie z..? bez wnikania w cel i metody użycia.”. To się zgadza, ale czy to wyklucza powyższe i analizę wpływu?
Ad 2. Przepraszam, chodziło mi o związek użycia pomiędzy Faktury a Archiwum dokumentów i Karty produktów a Archiwum dokumentów. Wracając do AZURE czy AMAZON – ostatecznie jeden lub drugi może być archiwum takich dokumentów? Tzn. gdzieś w naszym modelu ostatecznie zostanie wybrane konkretne archiwum dokumentów. A pobranie dokumentu z jednego czy drugiego może wyglądać inaczej, chodź nie znam tych technologii :).
Zdanie “modification of a supplier may impact the client” oznacza, że jeżeli efekt (wynik) pracy komponentu CLIENT zależy od efektu (wyniku) pracy komponentu SUPPLIER, to zmodyfikowanie tego drugiego może sie odbić na pierwszym, ale to dlatego paradygmat obiektowy operuje pojęciem polimorfizmu: zmiana metody nie może wpłynąć na jej produkt. Analiza wpływu polega wyłącznie na sprawdzeniu czy zmiana komponentu systemu wpłynie na zachowanie całego systemu, jeżeli tak, to jest to dramat projektanta 😉 a nie “zależność oznaczająca taki wpływ” 😉
UML to notacje uniwersalna, dlatego CO DO ZASADY każdy diagram MUSI mieć wskazanie na kontekst, bez tego nie mamy prawa interpretowania go. W UML generalnie tworzone są albo modele architektury określonego systemu (lub typu systemu) albo modele pojęciowe. Dlatego sama nazwa “diagram klas” nic nie znaczy. Albo jest to architektura systemu (jego komponenty) albo model pojęciowy (namespace).
Przypominam, że “relationship” i “relation” w j. angielskim ma nieco inne (szersze) znacznie niż “relacja” w języku polskim, “Relation” jest to związek matematyczny (identycznie intepretowany w “relacyjnych” modelach danych). UML bazuje na pojęciu asocjacja (związek). “Relationship” jest rozumiane jako “współistnienie”.
Pisze Pan:
Oczywiście w samym UML jest: 7.8.23.1 ?A Usage is a Dependency in which the client Element requires the supplier Element (or set of Elements) for its full implementation or operation?, co nie potwierdza bezpośrednio tej tezy, ale wydaje się naturalne.
Niestety nie jest naturalne. Związek użycia ma bardzo precyzyjna definicję; jest to tylko i wyłącznie wywoływanie operacji innego komponentu. Pojęcie analizy wpływu nie jest pojęciem UML. W UML pojęcie zależności nie jest tym czym słowo “zależność” w języku polskim. W języku polskim jest prawdą, że podwładny zależy od przełożonego, w UML byśmy napisali “przełożony jest zależny od podwładnego” dlatego, że efekty pracy działu księgowości (czyli jego szefa także) są zależne od efektów pracy pracowników tego działu. I to jest kluczowa różnica, na którą “łapie” sią wielu ludzi. Bo to JA (CLIENT) używam (związek ‘use’) odkurzacza (SUPPLIER), żeby posprzątać mieszkanie, i ja “zależę” od tego odkurzacza (a nie odkurzacz ode mnie), bo jak odkurzacz słabo ciągnie, to JA źle odkurzyłem mieszkanie, i to MNIE oceni rodzina za niedokładnie odkurzenie mieszkanie. Jakakolwiek zmiana konstrukcji odkurzacza NIE MA PRAWA wpłynąć na moje zachowanie, bo kupując odkurzacz zawieram kontrakt (interfejs) że on odkurza ;), konstrukcja odkurzacza nie ma prawa wpływać na to, że on ODKURZA (polimorfizm).
Pomiędzy UML a relacjami w SQL jest przepaść, i nie ma tu absolutnie żadnej analogii. Niestety wielu ludzi, tropem starych książek na temat EJB (Enterprise Java Beans), brnie w anemiczne modele dziedziny i diagramy klas jako modele danych.
AZURE i AMAZON to repozytoria, nazywane są czasami obiektowymi bo obie te platformy udostępniają API, czyli dla użytkownika są “czarną skrzynką”. To API na operację ZAPISZ i OCZYTAJ, parametrem jest identyfikator zapisywanego obiektu, a tym obiektem może być plik zdjęcie, plik XML/JSON, cokolwiek. Repozytoria z zasady nie realizująca żadnej logiki biznesowej (polecam: Evans, E. (2003). Domain-Driven Design. Pearson Education (US).).
Miłą cechą UML/obiektowości jest to, że na etapie projektowania nie ma żadnego znaczenia czym będzie to repozytorium. Ale niewątpliwie pomiędzy aplikacją a repozytorium jest związek zależności ‘use’ wskazujący strzałką na repozytorium (czyli na jego interfejs). Dlatego pobranie dokumentu z obu tych repozytoriów MUSI wyglądać identycznie ;).
* Co więcej powyższe oznacza moim zdaniem, że związek ZALEŻNOŚCI powinien być stosowany do ?impact analysis?.
Związek “zależności” nie ma prawa być używany do analizy zależności (wpływu) bo oznacza “zależność” a nie “wpływanie na coś” 😉 co nie jest tym samym. UML powstał na bazie obiektowego paradygmatu, a ten definiujemy jako “współdziałanie”: są to więc luźno powiązane komponenty wywołujące swoje usługi. Ale to projektant systemu decyduje jako to “obmyśli”.
I generalnie: UML ma specyfikacje, nie wolno mu dorabiać dodatkowych “naturalnych” interpretacji ;). I nie przypadkiem w UML ta zależność nazywa się “dependency” a nie o “impact”. 😉
Dziękuję za wyjaśnienia.
Zakupiłem publikację w IGI Global. Jaka jest najlepsza forma komunikacji w przypadku pytań do samej publikacji?
Generalnie, w kwestii publikacji naukowych, jest taka zasada, że wszędzie tam gdzie autor podał email jest to zaproszenie (otwartość) na dyskusje. Jeżeli podał tylko imię nazwisko i miejsce afiliacji (macierzysty instytut, uczelnia, itp.) piszemy do niego na adres tej jednostki.