Dane niestrukturalne stanowią ponad 80% składowanych danych, to oznacza, że model relacyjny pozwala opisać i przetwarzać tylko ułamek posiadanej informacji (UNSTRUCTURED DATA AND THE 80 PERCENT RULE)
Wstęp
W podsumowaniu niedawnego artykułu o NoSQL w chmurze, napisałem:
Problem projektowania struktur dokumentów, także w bazach dokumentowych, to osobne i trudne zagadnienie. Opisałem go w najnowszym artykule, który ukaże się za niedługo w wydawnictwie IGI Global: Emerging Challenges, Solutions, and Best Practices for Digital Enterprise Transformation. (Repozytorium w chmurze – NoSQL – Jarosław Żeliński IT-Consulting – Systemy Informacyjne)
Artykuł sie właśnie ukazał. We wstępie napisałem:
Dokumenty często zawierają dużą ilość różnych danych tworzących wspólnie wiele kontekstowych zbiorów danych (agregatów). Zastosowanie modelu relacyjnego do organizacji takich danych prowadzi do wygenerowania rozbudowanego systemu powiązanych relacyjnie tabel, przy czym usunięcie redundancji często powoduje utratę kontekstu treści poszczególnych pól w tabelach. Rodzi to konieczność stosowania wysoce złożonych zapytań SQL, aby dokumenty te mogły być zapisywane w tej bazie danych i z niej pobierane. W ten sposób sama baza danych zawiera wyłącznie dane pozbawione kontekstu obecnego w tabelach, a nie dokumenty.
Wielu autorów zwracało uwagę na problem złożoności i utraty jednolitego kontekstu modelu relacyjnego (Ślęzak i in., 2018). Autorzy ci sugerowali, że konteksty powinny być separowane w dużych relacyjnych modelach danych. Jednak zalecenie separacji kontekstów (Evans, 2003; Fowler, 1997; Fowler & Rice, 2005), przy zachowaniu modelu relacyjnego, nie pomaga w całkowitym rozwiązaniu problemu (Awang et al., 2012, 2012, 2012).
Zmiana kontekstu często zmienia znaczenie danych (Danesi, 2004). Podejmowane próby zachowania znaczenia danych często prowadzą do tworzenia rozbudowanych relacyjnych modeli danych, generując tym samym dodatkowe koszty. Dlatego też wykorzystanie jednego relacyjnego modelu danych do zapisu zawartości wielu różnych dokumentów może uczynić z takiego systemu ogromny i niepodzielny monolit, który jest kosztowny zarówno w rozwoju, jak i w utrzymaniu. (Digital Documents as Data Carriers and a Method of Data Management Guaranteeing the Unambiguity of the Recorded Information: Ontology-Oriented Data Management and Document Databases)
Biorąc pod uwagę to czym są bazy danych zwane NoSQL, uważam, że należałoby raczej nazywać je “bazami nierelacyjnymi”. Krótkie zestawienie tu: Bazy NoSQL Nowoczesne Rozwiązania do Przechowywania Danych (autor: dr inż. Michał Malinowski). Poniżej kilka wyjasnień.
Rodzaje baz danych NoSQL na rynku
Praktyka pokazuje, że bazy te to odpowiedź na standardowe obecnie wymagania wobec systemów informacyjnych, jakimi są zmienność struktur danych, ich ograniczona strukturalizacja lub nawet jej całkowity brak.
Akronim NoSQL został po raz pierwszy użyty w 1998 roku przez Carlo Strozzi’ego jako nazwa jego lekkiej, opensource “relacyjnej” bazy danych, która nie używała SQL. Nazwa ta pojawiła się ponownie w 2009 roku, kiedy Eric Evans i Johan Oskarsson użyli jej do opisania nierelacyjnych baz danych. Relacyjne bazy danych są często określane jako systemy SQL. Termin NoSQL może oznaczać zarówno “Nierelacyjna SQL” lub bardziej popularne tłumaczenie “Nie tylko SQL” (Not only SQL), aby podkreślić fakt, że niektóre systemy mogą obsługiwać języki zapytań podobne do SQL. (źr.: A Brief History of Non-Relational Databases – DATAVERSITY)
Jeden z moim zdaniem ciekawszych artykułów o NoSQL napisał Fowler 10 lat temu .
Bazy danych ‘key-value’.
Bazy te są najprostszym typem bazy NoSQL. Każdy element (wiersz) w takiej bazie to para klucz i wartość (dane przechowywane), tu zawartość (dane przechowywane) to zawsze “jakiś plik” (podobnie jak pole typu BLOB: Binary Large OBject). Zawartość ta może być pobrana wyłącznie poprzez odwołanie się do jej identyfikatora (klucza) . Bazy te są doskonałe do przechowywania dużych ilości różnorodnych danych, gdzie nie trzeba przetwarzać treści tych danych w samej bazie (np. wyszukiwanie zawartości na podstawie jej określonych cech). Służą one wyłącznie do zachowywania i odzyskiwania plików. Praktycznie jest to płaski system plików.
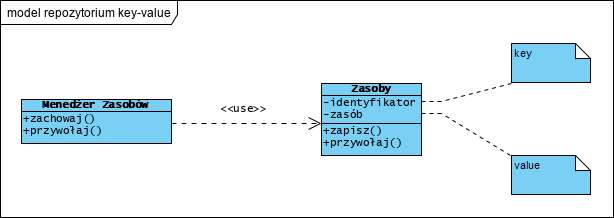
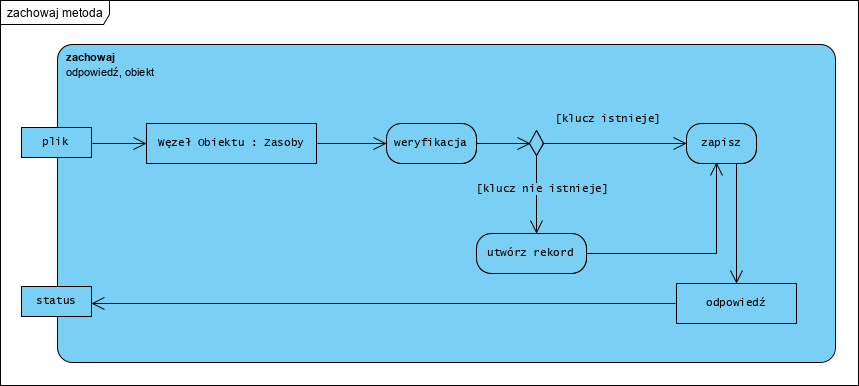
Dokumentowe bazy danych.
To odmiana bazy key-value. Przechowuje dane w postaci określonej strukturalnej treści: dokumentów (np. JSON czy XML). Struktury te mają swoje definicje, a ich typów może być dowolna liczba. Jedna baza może więc zawierać dokumenty o dowolnie wybranej, określonej strukturze. Dostępne na rynku bazy tego typu maja także bardzo dobre i szybkie motory zapytań, są coraz częściej stosowane jako bazy danych ogólnego przeznaczenia.

Bazy zmieno-kolumnowe
Przechowują dane w postaci agregatów o zmiennych “liściach”. Bazy tego typu zapewniają dużą elastyczność w stosunku do relacyjnych baz danych, ponieważ nie jest wymagane, aby każdy wiersz agregat posiadał tyle samo i te same elementy (kolumny) . Bazy tego typu są powszechnie stosowane do przechowywania danych np. danych profilowych użytkowników. Są często opisywane w poniższy sposób:
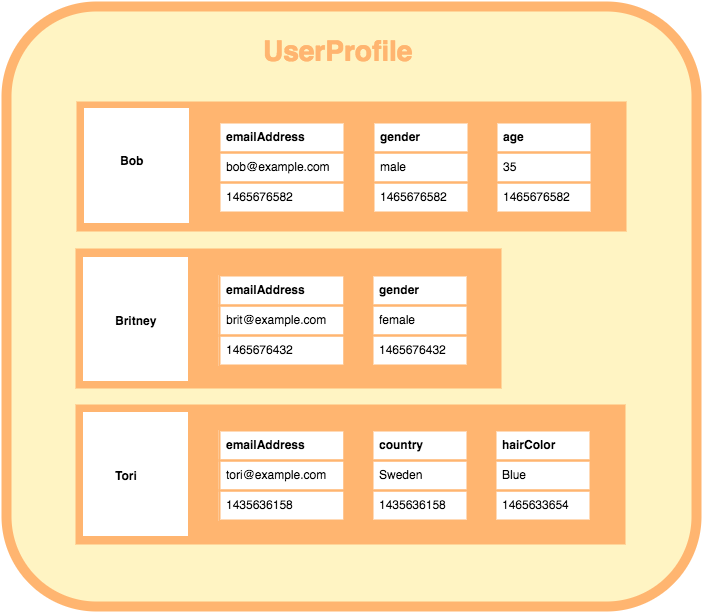
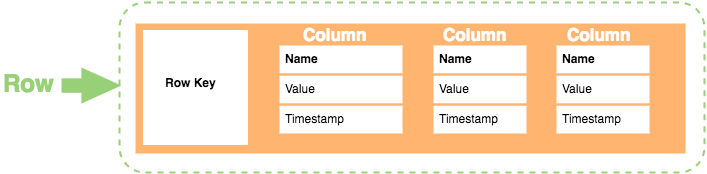
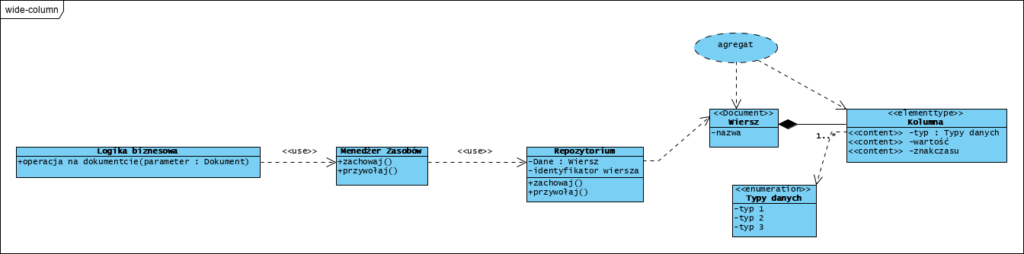
Jak widać, bazy te przechowują agregaty. Nazwanie agregatu “wierszem” jest niefortunne bo to jednak nie są płaskie tabele, jednak pojęcia wierszy i kolumn zrzucam tu jednak na karb stereotypu zaczerpniętego z modelu relacyjnego.
Grafowe bazy danych.
Przechowują dane w postaci węzłów i krawędzi (asocjacje między węzłami). Węzły zazwyczaj przechowują informacje o obiektach (ludzie, miejsca, przedmioty) krawędzie zaś przechowują informacje o możliwych związkach między węzłami . Grafowe bazy danych doskonale sprawdzają się w przypadkach gdy trzeba zapisywać i śledzić związki między obiektami i analizować je, np. sieci społecznościowe czy wykrywanie oszustw. Tak są najczęściej opisywane grafowe bazy danych, a przedstawiane są np. tak:
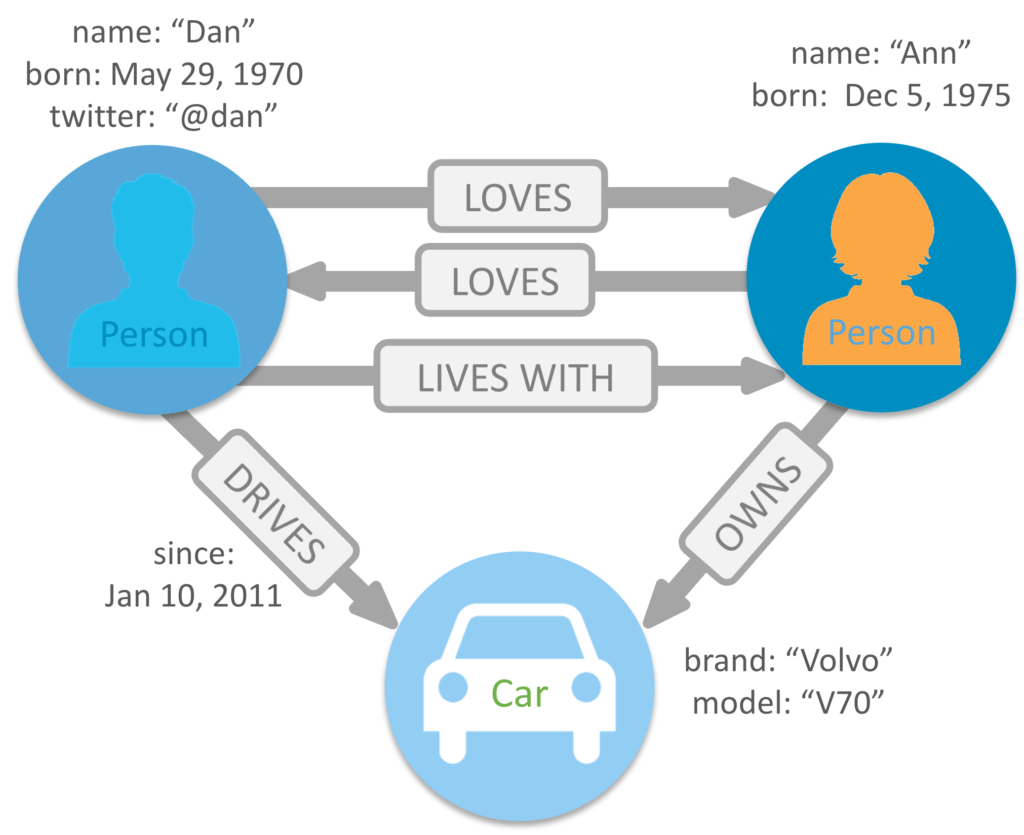
Uważam, że powyższe to trywialna i naiwna metoda przedstawiania baz tego typu. Istotą systemu przetwarzania informacji jest tu (w takim modelu) jest przechowywanie informacji o obiektach i o faktach je łączących takich jak zdarzenia dotyczące pary obiektów . Mogą to być typowe fakty, np. Samochód miał kolizje w Mieście, gdzie Samochód i Miasto to węzły, a kolizja to zdarzenie. Ważne jest to, że Samochód i Miasto można opisać określonym cech, sama kolizje także, ważne jest to, że faktów łączących dwa obiekty może być wiele (w czasie).
Związki między obiektami opisywane są też metodą RDF (Resource Description Framework) jako zdania: Subject – Predicate – Object .
O każdym obiekcie będzie jeden rekord w bazie danych, o każdym fakcie też, ale różnych faktów, których cechami są te obiekty może być wiele (cechą stłuczki jest między innymi miejsce stłuczki i samochód, który miał tę stłuczkę). Cechami obiektów są nazwa, data powstania i ewentualna data usunięcia (zniszczenia), także cechy definiujące takie jak np. kolor, typ czy wydawane dźwięki. Cechami fakty są czas zaistnienia oraz obiekty (ich nazwy), których określony fakt dotyczy. Ważne jest to, że położenie obiektu nie jest jego cechą definiującą. Graf jest definiowany jako nazwane związki między obiektami, są nimi właśnie fakty (a szerzej: predykaty). Warto też zaznaczyć, że w kontekście np. zdarzeń gospodarczych, faktem jest faktura opisująca transakcje do jakiej doszło. Jednak w archiwum dokumentów faktura jest obiektem archiwalnym .
Tak więc bardziej sformalizowana struktura danych w bazie grafowej mogła by wyglądać tak:
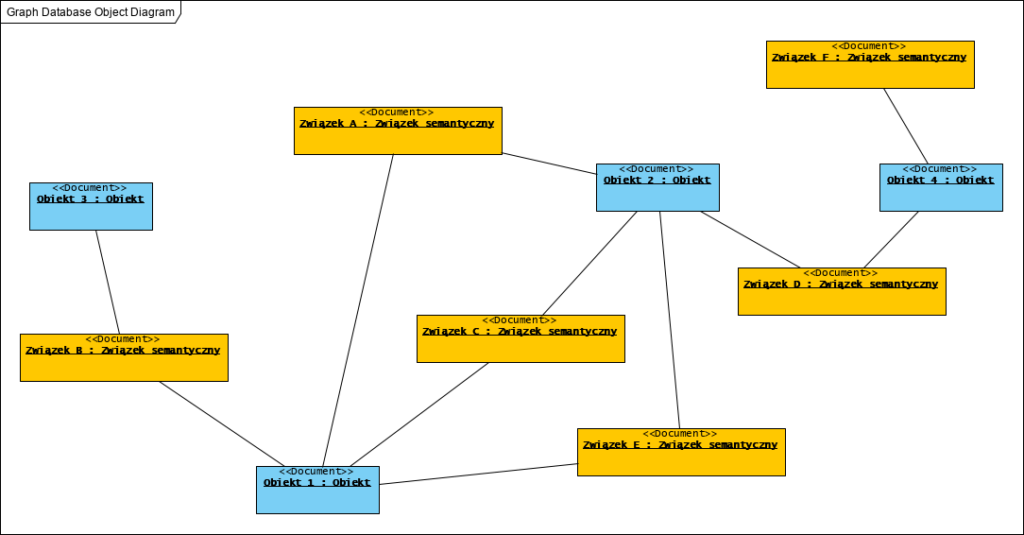
Diagram powyższy jest kolorowany dla poprawy czytelności. W tej postaci widać obiekty i łączące je fakty: w bazach grafowych są to formalnie tak zwane związki semantyczne (znaczeniowe), ale jest to jednak duże uproszczenie. Systemy zapisu informacji w postaci trójek: pojęcie-predykat-pojęcie mają szersze uzasadnienie (planuję publikację z wynikami szerszych badań). Metamodel systemu zapisu informacji o obiektach i związkach między nimi wygląda tak:

Warto zauważyć, że zarówno Obiekt jak i Związek semantyczny mogą być przechowywane w bazie dokumentowej lub kolumnowej…
Podsumowanie
To co dzisiaj nazywamy bazami danych NoSQL to tylko naturalne modele informacyjne. Kiedy odkryte? Nie wiem, ale wiem, że w tym wszystkim najbardziej nienaturalny jest model relacyjny. Dlaczego? Bo nie występuje w naturze i sprawia same problemy. Celowo zaprezentowałem sformalizowane diagramy UML dla każdego typu, by pokazać, że NoSQL to tylko i aż modele informacyjne spotykane w rzeczywistości życia człowieka. Konstrukcje jak te wyżej opisane, to tak na prawdę modele informacji wynikające z dziedziny problemu, nie jest tak że są używane z powodu “wynalezienia” baz NoSQL, jest dokładnie odwrotnie.
Obecne bazy NoSQL rozumiane jako “motory baz danych”, to implementacje informacyjnych wzorców projektowych. Diagramy UML powyżej to metamodele tych wzorców.
Na temat baz danych i baz NoSQL polecam kompleksowe opracowanie Joe Celko: Complete guide to NoSQL: what every SQL professional needs to know about nonrelational databases .
Polecam też poniższe wystąpienie gdzie Martin Fowler wyjaśnia to na przykładach:
Podsumowanie 2
Pojawiają się tezy że to się nie nadaje do ERP, że nikt tak nie robi… Otóż:
Systemy ERP budowane w oparciu o centralne bazy danych RDBMS ewoluujące do chmury są niejako skazane na bazy NoSQL (znakomita większość chmurowych repozytoriów chmurowych to bazy NoSQL).

Podstawowym problemem systemów zbudowanych w oparciu o bazy RDBMS/SQL jest to, że nie ma w nich dokumentów, a jedynie dane rozłożone w tabelach. Uzyskanie dokumentu (np. faktury) wymaga każdorazowo dynamicznego zebrania danych z wielu tabel, ich złączenia i sformatowania, czyli użycia języka SQL. Dlatego ewolucja nowoczesnych systemów ERP idzie w kierunku systemów, w których funkcje kalkulacyjne oraz dokumenty są rozdzielone, a dokumenty są przechowywane w postaci zmaterializowanej:
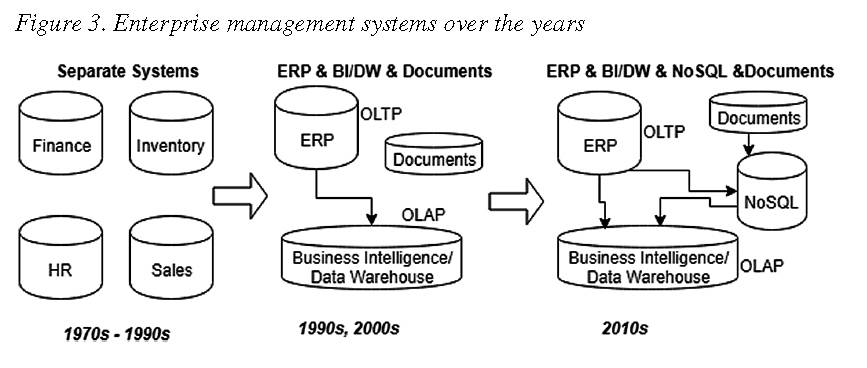
Przypominam, że systemy ERP inne o podobnej architekturze, nie przechowują dokumentów, bo dynamicznie generowane treści (raporty SQL, i podobne generowane “w locie” na API) to w świetle prawa nie są dokumenty, i słusznie bo nie istnieją w czasie.
Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego nośnika, jeżeli tego rodzaju strona internetowa nie spełnia cech trwałego nośnika. (https://uokik.gov.pl/zwrot-i-rekompensata-od-mpay-i-revolut-bank-uab)
Podsumowanie 3
Od dłuższego czasu stosuje w projektach struktury informacyjne nazywane NoSQL. Sa to praktycznie wszystkie opisane wyżej struktury. Projekt dla agencji fotograficznej BE&W (archiwum zdjęć), projekt dla Biura Polonii Kancelarii Senatu (obsługa wniosków o dofinansowanie o zmiennej strukturze), projekt dla Żandarmerii Wojskowej (zarządzanie sprawami dochodzeniowo-śledczymi w całej Polsce), projekt dla KGHM (standaryzacja systemu utrzymania ruchu, zarządzanie infrastrukturą produkcyjną).
Na przykładzie MongoBD
Więcej już niedługo… Zachęcam do zadawania pytań o NoSQL pod tym wpisem.


Bardot to ciekawe. Moją uwagę przykuło, w szczególności stwierdzenie, że bazy danych NoSQL, są bliżej natury człowieka. Być może bazy SQL czeka ten sam los co płyt CD lub raczej winylowych. To znaczy nie wypadną w całości z rynku, ale przestaną być dominujące w użyciu.
Model relacyjny i system zapytań SQL to bardzo specjalistyczna forma zarządzania danymi, niestety takie pojęcia jak “treść” czy “dokument”, naturalne dla człowieka, nie występują w tym modelu… Stąd od ok. 2000 roku stale trwają prace nad innymi modelami (NoSQL to skrót od “Not only SQL”). Wygląda na to, że tak zwany “paradygmat zorientowany na dokumenty” wygra, trwają prace nad jego formalizacją.
Nierelacyjne bazy danych są stosowane od dawna (ich historia sięga dalej niż systemów relacyjnych). Moim zdaniem obecnie stały się w końcu popularne i stosowane na szeroką skalę z uwagi na dostępność w miarę tanich zasobów. Niestety ich piętą achillesową jest właśnie zasobożerność. Bazy relacyjne nadal będą wykorzystywane ze względu na spójność, którą gwarantują, brak redundancji i możliwości standaryzowanego języka SQL. Właśnie tych cech brakuje bazom NoSQL. Obecnie ciekawym trendem jest łączenie możliwości obu światów – implementacja funkcjonalności baz NoSQL w ramach relacyjnych baz danych (co ciekawe odwrotna sytuacja nie ma miejsca). Te dwa uzupełniające się narzędzia należy wykorzystać do odpowiadających im zadań. W większości projektów idealnym rozwiązaniem jest użycie mocnych stron każdego z rozwiązań.
Owszem, model relacyjny/SQL powstał w 1972 roku, wcześniej były inne. Kluczowym problemem modelu relacyjnego bez redundancji jest jest stratność: bez zapytań SQL relacyjne tabele danych to śmietnik a nie dokumenty. To jakieś dane. Co do zasobożerności baz NoSQL to testy wydajności pokazują coś zupełnie odwrotnego: pobranie dokumentu z bazy dokumentowej jest nawet 1000 (tysiąc razy) szybsze niz na tej samej maszynie z SQL. Zorganizowanie nierelzyjnego modelu na motorze np. MS SQL itp. nie jest żadnym problemem, wiele systemów używa tych motorów do zarządzania niepowiązanymi tabelami. Stare wzorce obiektowe utrwalania takie jak Active Table czy Active Records są używane od wielu lat. Jednak takie systemy jak sklep Amazon czy eBay na modelu relacyjnym nie mają racji bytu. Osobiście nie widzę dzisiaj żadnej przewagi baz relacyjnych: są sztywne i betonują struktury danych. Po drugie nie ma tam dokumentów a tylko dane i zapytania SQL, które osiągają monstrualne długości już przy średnio złożonych dokumentach o zmiennej w czasie strukturze i słownikach.
Bardzo ciekawy artykuł na temat fascynacji danymi:
https://www.linkedin.com/pulse/data-dead-why-data-driven-enterprise-doa-wouter-van-aerle/
W książce Fowlera: NoSQL – kompedium wiedzy, przeczytać można, że bazy NoSQL nie zawierają schematu. Co najwyżej zawierają domniemamy schemat
“domniemany schemat to zestaw założeń w kodzie manipulującym danymi, dotyczących struktury tych danych”.
Jak zatem rozumieć modele przedstawione w tym artykule?
Fowler pisze o schemacie w sensie powiązane tabele i takiego nie ma w NoSQL. Fowler, jak wielu pisze o motorze bazy danych NoSQL a nie o modelu danych jako takim. A to jest “proste”: przechowywane dane to np. “jeden” JSON jako wartość atrybutu. W przypadku NoSQL sugeruję zapomnieć o “relacjach” i “schematach tabel”. Polecam na YT prezentacje np. MongoDB.