Wprowadzenie
W 2019 opisałem swoistą próbę rewitalizacji wzorca BCE (Boundary, Control, Entity). Po wielu latach używania tego wzorca i dwóch latach prób jego rewitalizacji uznałem jednak, że
Zarzucam prace nad wzorcem BCE. Podstawowy powód to bogata literatura i utrwalone znaczenia pojęć opisujących ten wzorzec. Co do zasady redefiniowanie utrwalonych pojęć nie wnosi niczego do nauki. Moja publikacja zawierająca także opis tego wzorca bazowała na pierwotnych znaczeniach pojęć Boundary, Control, Entity. Sprawiły one jednak nieco problemu w kolejnej publikacji na temat dokumentów . Dlatego w modelu pojęciowym opisującym role komponentów przyjąłem następujące bazowe stwierdzenie:
Implementacja usługi aplikacyjnej wymaga wymiany danych z otoczeniem (?Interface?), przetwarzania danych (?Processing?) i ich przechowywania (?Storage?) danych. Działania te to role komponentów (ich typy). Dane, dla ułatwienia zarządzania nimi, są organizowane w dokumenty (?Document?). Całość może wymagać zarządzania (?Management?).
Dalsze prace pójdą więc w kierunku nowego wzorca a nie rozszerzania wzorca BCE. (Koncepcja rozszerzenia wzorca projektowego BCE)
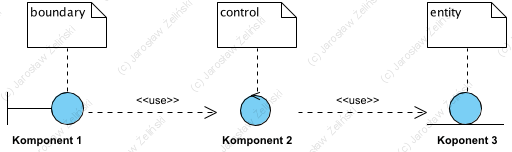
BCE powstał w czasach świetności metod RUP (Rational Unified Process) i ICONIX . Metody te doskonale pasowały do implementacji realizowanych w środowisku EJB (Enterprise JavaBeans). Pojęcia Boundary, Control, Entity (BCE) przylgnęły do trójwarstwowego pojmowania architektury aplikacji (interfejs użytkownika, logika, bada danych) a pojęcie “robustness diagram” także ma utrwalone znaczenie w literaturze. Początkowo wydawało się, że przeniesienie tych pojęć na grunt metod obiektowych i odpowiedzialności klas uda sie bez kolizji z wcześniejszym stosowaniem wzorca BCE, jednak prace badawcze i praktyka (szczególnie komunikacja tych modeli) pokazały, że pojęcia te, i ich znaczenia, są tak mocno ugruntowane w literaturze, że pozostaje jedynie używanie ich w pierwotnych znaczeniach, jakie nadano im prawie 20 lat temu (Philippe Kruchten, Rational Unified Process). Więcej na ten temat w artykule: ICONIX and Use Case Driven Object Modeling with UML.
Dużym problemem jest także migracja istniejących aplikacji z lokalnych baz danych w modelu relacyjnym do chmury NoSQL .
Metody
Wszystkie moje projekty badawcze są poprzedzane analizą pojęciową i metamodelowaniem. Dzięki temu każdy projekt analityczny jest obiektywizowany w maksymalnie możliwy sposób, zaś produkty projektowania odporne na zmienność środowiska. Ta odporność, bierze się stad, że prawidłowo opisane dane to określone zamknięte struktury danych wraz z ich kontekstem: dokumenty (formularze). Jeżeli uznamy, że nasz język (np. polski) się nie zmienia, a zmienia sie jedynie to co z jego użyciem opisujemy, to znaczy, że możliwe jest zapisanie i przetwarzanie informacji o świecie, i że nie opis ten (jego struktura) nie będzie wymagał zmian w przyszłości. Dane opisujące świat to zbiory pojęć stanowiące określone struktury (zdania, akapity, dokumenty) a nie pojedyncze słowa połączone relacjami . Trudna do przetłumaczenia na język polski nazwa dziedziny nauki: information science , to obszar wiedzy zajmujący się informacją i jej przetwarzaniem, co nie jest tożsame z przetwarzaniem danych (w języku polskim nazywane informatyka). Korzystam tu także z dorobku tej dziedziny nauki: są nią modele pojęciowe, ontologie i rachunek zdań (analiza i budowanie struktur dokumentów).
Rezultat
Ten opis to wstępna wersja, generalizacja doświadczenia zakończonych sukcesem implementacji i wdrożeń. Praktyka pokazała, że klasyfikując komponenty aplikacji, kierując się ich odpowiedzialnością , otrzymamy trzy kluczowe role komponentów: przetwarzanie, zarządzanie przetwarzaniem, przechowywanie. To ostatnie to przechowanie danych w “paczkach” zorganizowanych kontekstowo jako dokumenty . Z uwagi na to, że inicjatorem użycia usługi jest aktor “użytkownik”, obligatoryjnym elementem aplikacji jest interfejs użytkownika (GUI, Graphical User Interface). Opis ten można zobrazować tak (UML):
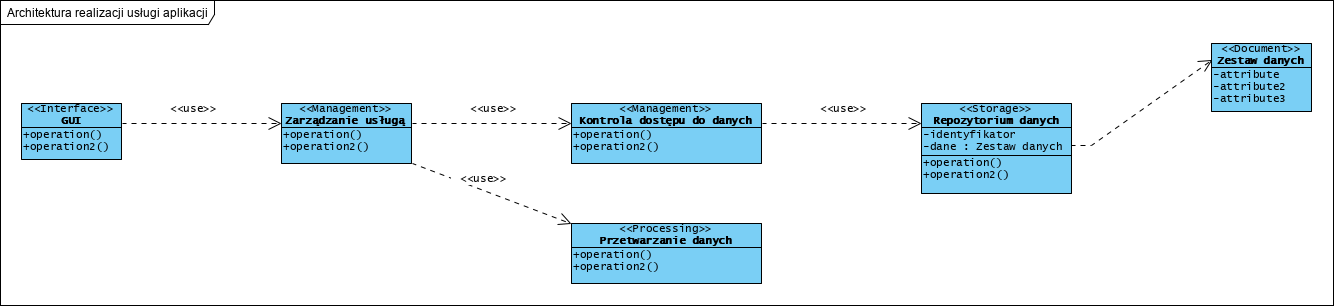
Tym co różni ten model od wzorca BCE jest rezygnacja z warstwowości (narzuconej kolejności wywoływania komponentów). Wzorzec BCE (poniżej) jest zorganizowany w “linię produkcyjną” z zakazem omijania jej elementów:
Wzorzec, który wstępnie nazwałem MPS, to przede wszystkim specjalizowane komponenty przetwarzające, których użycie jest zarządzane. Utrwalanie zostało całkowicie pozbawione przetwarzania: logika biznesowa jest w 100% realizowana w komponentach ‘processing’. To kluczowa zaleta takiego podejścia: niezależność od implementacji przechowywania. Z tego powodu w tytule dodałem słowo “chmura”, gdyż to czy jest to chmura prywatna czy publiczna nie powinno mieć tu znaczenia, i nie ma.
Wieloletnie doświadczenie projektowe nauczyło mnie także, że znane od lat podejście znane jako mikroserwisy, zakładające w usługach “własność lokalnej bazy danych”, stanowi takie samo ograniczenie jak “własne baza danych” w systemach monolitycznych, tyle że na nieco mniejszą skalę.
Opisane tu komponenty są częścią architektury całej aplikacji. Opierając się na założeniach MDA (Model Driven Architecture) oraz wzorcu architektonicznym MVC (Model, View, Controller) , można wstępnie tak zobrazować abstrakcyjną architekturę aplikacji:
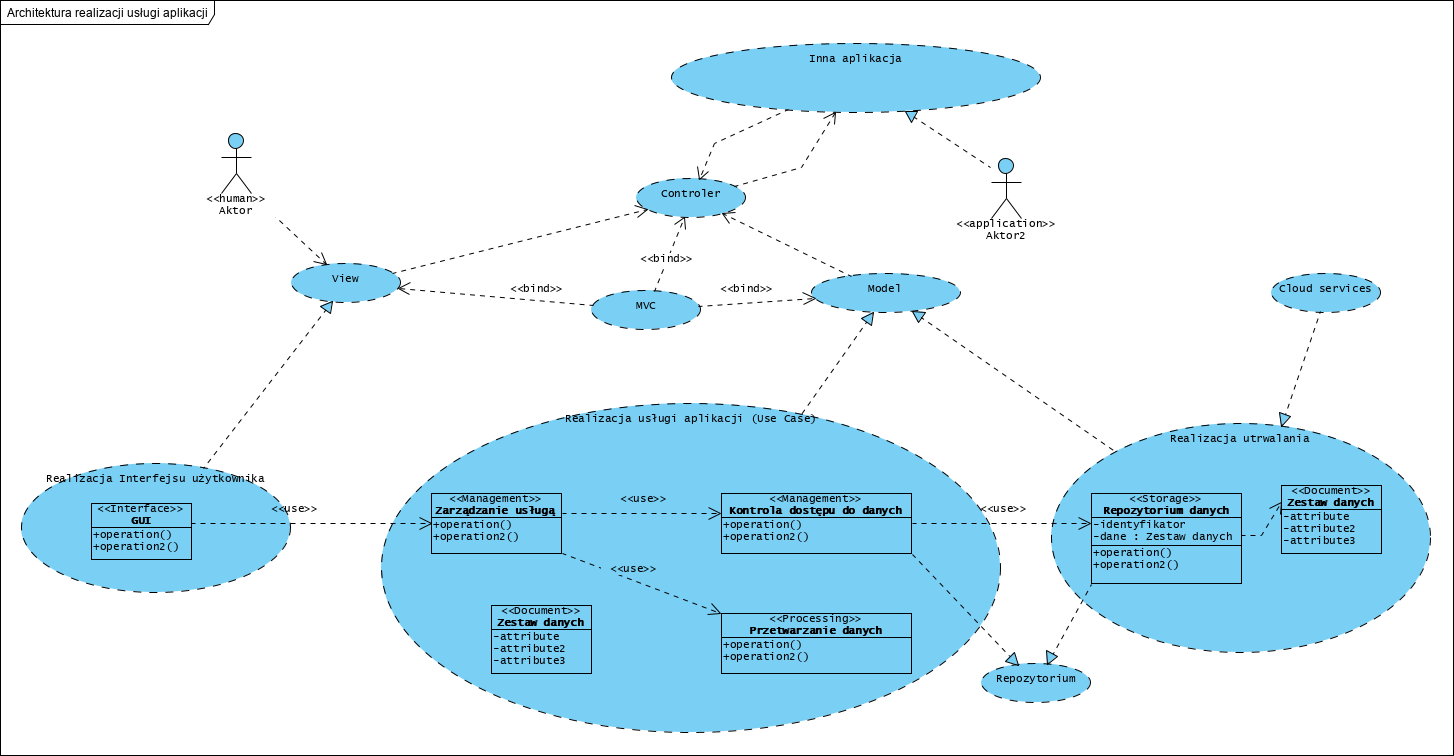
Dolna część diagramu to prezentowany na początku artykułu model PIM. Jednak po uzupełnieniu go o strukturę wzorca MVC mozna uznać, że: 1. GUI to realizacja komponentu View, 2. Model jest realizowany przez logikę reprezentowaną przez komponenty ‘Management’ oraz ‘Processing’, element ‘Document’ to nazwana struktura danych (formularz) stanowiący zawsze argument wywołań (pełni tu DTO: Data Transfer Object). Komponent ‘Storage’ to albo własny system utrwalania aplikacji (jej środowiska), albo API systemu utrwalania w chmurze prywatnej lub publicznej (patrz artykuł Repozytorium w chmurze). To dzięki temu migracja z lokalnej do publicznej chmury stanowi wyłącznie przeadresowanie wywołań i jednorazowe przeniesienie danych. Dość powszechnie stosowany wzorzec projektowy “repository” tu jest podzielony na dwie części: ‘Management’ Kontrola dostępu do danych oraz ‘Storage’ jako Repozytorium danych. To ostatnie to właśnie opisane wcześniej chmurowe repozytoria. 3. Controller to środowisko wykonawcze odpowiadające za komunikację z otoczeniem aplikacji, np. integrację z innymi aplikacjami: Aktor ‘application’.
Model PIM: to co należy zaprojektować, tworząc nową aplikację, jako wymaganie na etapie poprzedzającym implementację (czyli wybór technologii także), wygląda tu tak:

Oczywiście liczba poszczególnych typów komponentów zależy od konkretnego przypadku.
Po co nam takie wzorce? Przed wszystkim by mieć od czego zacząć, coś co u wielu autorów nazywa jest “starting point” (punkt wyjścia). Po drugie narzuca pewien porządek, oraz pozwala uzyskać podstawową cechę dobrego oprogramowania: aplikacja (jej architektura) jest otwarta na rozszerzenia i zamknięta na modyfikacje (patrz Open Closed Principle). No i po trzecie, stosowanie reguły mówiącej, że jeden komponent ma jedną dedykowaną rolę w systemie, bardzo ułatwia stosowanie dostępnych na rynku, gotowych komponentów (zarówno płatnych i opensource). Uzyskujemy także łatwość zarządzania licencjami (odseparowane komponenty to odseparowane prawa do nich, łatwo nimi zarządzać, a w razie konieczności zastąpić innymi). Warto tu podkreślić, że z perspektywy kosztów: od kosztów wytworzenia aplikacji, znacznie ważniejsze są koszty jej utrzymanie i rozwoju.
Podsumowanie i dalsze prace
Opisany tu wzorzec architektoniczny to wstępna propozycja uporządkowania architektury aplikacji. Wprowadzony tu element ‘Management’ to uogólnienie wzorca znanego jako “saga“. Jest to rozwiązanie problemu transakcyjności w systemach opartych na mikroserwisach i także systemach NoSQL, gdzie repozytoria nie realizują żadnej logiki, nawet tej odpowiedzialnej za spójność danych (co często jest wskazywane jako wada tych repozytoriów).
Dalsze prace są obecnie ukierunkowane na testy skuteczności tego wzorca w rozwiązywaniu problemów systemów, przetrzymujących dane w chmurach. Celem autora jest opracowanie metamodelu stanowiącego rozwiązanie problemów zarządzania dużymi, wielodziedzinowymi zbiorami danych.



Panie Jarku, Pana podejście jest bardzo podobne do tego, które opisuje Robert C. Martin w publikacji “Czysta architektura…”. Tak też Martin określa swój wzorzec. Różni Was jego sceptycyzm dotyczący podejścia usługowego. Pozdrawiam
Wiem, też czytałem. Wzorce usług są różne, dlatego “najwyższe kryterium” oceny podejścia to koszty w całym cyklu życia. Cały czas obracamy się w kręgu kosztów drukarki atramentowej: koszt wytworzenia i zakupu, czy łączny koszt wraz z pięcioletnią eksploatacją w określonych warunkach zmienności środowiska pracy. Martin traktuje bazę danych danych jak dawny “dżawowiec”, czyli jako monolityczny byt (zbiór encji). To dzisiaj najgorsze podejście. Wzorzec MVC to wbrew temu co on twierdzi, jest architektura, ale Model to nie “baza danych” a logika biznesowa CAŁA (dane i ich logika w określonym kontekście). W konsekwencji u niego usługa to wewnętrzna funkcja. W modelu usługowym usługa aplikacji to kontekst użytkownika a nie wnętrza systemu (Polecam publikacje o Use Case 2.0). Warto zwrócić uwagę, że poza nim (i jego uczniami) nikt inny nie krzewi jego pomysłów tezy (ja zaś w 100% cytuję literaturę rónych autorów). Pojęcie usług i komponentów ma swoją definicje od czasów Souzy i jego publikacji “Aplikacje komponentowe” (2003). Martin w swoich wystąpieniach najpierw redefiniuje te pojęcia (usługa itp.), a potem je zwalcza, ale zwalcza już inne, swoje pojęcia.