Wprowadzenie
W artykule o aplikacjach webowych, ponad rok temu, pisałem:
Generalnie kluczową cechą micro-serwisów, czyniącą z nich tak zwaną zwinną architekturę, jest całkowita wzajemna niezależność implementacji poszczególnych usług aplikacyjnych. (źr.: Aplikacje webowe i mikroserwisy czyli architektura systemów webowych).
Przy innej okazji pisałem o wzorcach:
Wzorce projektowe to bardzo ważna część ??zawodu? analityka i architekta oprogramowania. […] Generalnie wzorce są to skatalogowane standardy i dobre praktyki . (Obiektowe wzorce projektowe )
Szkolenia dla analityków poprzedzam ankietami przed szkoleniowymi, jak do tej pory żadna nie zawierała pytań o wzorce projektowe: ani tego że są używane ani tego, że są celem szkolenia, niemalże każdy deklaruje albo, że używa UML lub, że chce zacząć używać UML, nawet gdy są to programiści. Zauważyłem, że wzorce projektowe w świadomości analizy biznesowej i projektowania (OOAD) “nie istnieją”. Wśród programistów, jeżeli jest spotykana, to wiedza o wzorcach przydatnych w tworzeniu bibliotek i narzędzi, często też powielane są wyuczone stare i złe praktyki programistyczne rodem z lat 60-tych (np. praktyki SmallTalk, patrz dalej).
Z drugiej strony od wielu lat znane są techniki MDA (Model Driven Architecture) czy MBSE (Model Based System Engineering), które w różnych formach, ale jednak wskazują, że najskuteczniejsza forma wyrażania wymagań wobec rozwiązania to projekt architektury i logiki dziedzinowej (model) działania aplikacji . O projektowaniu poprzedzającym implementację pisze sie od dość dawna, metody obiektowe i dobre praktyki znane są od lat .
Autorzy BABoK praktycznie od początku istnienia tego wydawnictwa, zwracają uwagę na tak zwaną “białą skrzynkę”, czyli wymagania wyrażone w postaci wewnętrznej struktury produktu, wskazując, że to znacznie skuteczniejsza metoda definiowania wymagań wobec rozwiązania, niż tak zwana “czarna skrzynka”, czyli tradycyjne, i jednak mniej skuteczne, wymagania wyrażone tylko jako cechy funkcjonalne i poza-funkcjonalne. Pamiętajmy, że adresatem wymagań jest zawsze dostawca produktu!
Wzorce jako aksjomaty
Jednym z częstych problemów a nauce i inżynier jest mylenie pojęć aksjomat i dogmat. Zajrzyjmy do słownika (SJP i WSJP):
aksjomat: w logice założenie, które przyjmuje się bez dowodu w systemie dedukcyjnym, jedno z podstawowych pojęć logiki matematycznej, od czasów Euklidesa uznawano, że aksjomaty to zdania przyjmowane za prawdziwe, których nie dowodzi się w obrębie danej teorii, są to założenia przyjmowane w ramach umowy; twierdzenie, które przyjmuje się bez dowodu i z którego wyprowadza się pozostałe twierdzenia jakiejś teorii.
dogmat: twierdzenie przyjmowane za pewne i prawdziwe jedynie na mocy autorytetu osoby, która je wygłasza; twierdzenie przyjęte bezkrytycznie za pewne bez względu na brak stwierdzenia jego prawdziwości
Na czym polega kluczowa różnica? Aksjomat to założenie przyjęte i uznane poprzez zgodne przyjęcie go bez dowodu, dogmat to założenie narzucone bez uzasadnienia jako niepodważalne z mocy autorytetu.
Np. prawa człowieka to aksjomat: wszyscy (no istotna większość) się zgadzamy, że jako ludzie mamy prawo do życia i równego traktowania. Z tego, w demokratycznych krajach, wywodzimy Prawo. Typowym dogmatem są religie religie i ich zasady narzucane przez Kapłanów. Uwaga! Aksjomat można odrzucić, zaś dogmatu odrzucić nie wolno.
Bardzo ważna rzecz: aksjomaty i dogmaty nie wykluczają sie z zasady: np. Prawo, po jego ustaleniu, jest dogmatem z zasady z mocy Prawodawcy, jednak w krajach demokratycznych Prawo to także aksjomat (przyjęty w Parlamencie).
Jak to odnieść do inżynierii? Dobre praktyki i wzorce projektowe, zaliczane do PIM (ang. Platform Independent Model), to aksjomaty, gdyż stosowanie ich wynika z uznanej woli ich użycia a nie z narzuconego obowiązku (oczywiście można nie używać, aksjomat można odrzucić). Frameworki to dogmaty, gdyż ich wybór narzuca określone konstrukcje bez możliwości ich odrzucenia. Modele PSM (anf. Platform Specific Model) są dogmatyczne. Np. wybór JavaEE/SE (dawniej EJB) lub .NET narzuca anemiczny model dziedziny (źr WIKI).
Wzorce projektowe to przyjęte jako sprawdzone i zalecane, na bazie doświadczenia, uzgodnione konstrukcje architektoniczne. To tak zwane dobre praktyki. Ich stosowanie zapewnia niższe koszty utrzymania i rozwoju oprogramowania. Można by powiedzieć, że oprogramowanie, w którym zastosowano sprawdzone wzorce projektowe, jest “zwinniejsze” w tworzeniu i utrzymaniu. Typowym aksjomatem w inżynierii jest unikanie monolitycznych konstrukcji na rzecz konstrukcji komponentowych.
Kluczowe definicje
Architektura oprogramowania to podstawowa organizacja systemu wraz z jego komponentami, wzajemnymi powiązaniami, środowiskiem pracy i regułami ustanawiającymi sposób jej budowy i rozwoju[IEEE Std 1471-2000, 2007]. Opis architektury oprogramowania (ang. Software Architecture Description) postrzegany jest jako platforma porozumiewania się wszystkich osób zaangażowanych w proces wytwórczy systemów informatycznych.
Generalnie wzorzec projektowy (ang. design pattern) w inżynierii jest powszechnie definiowany jako: uniwersalne, sprawdzone w praktyce rozwiązanie. Kolejnym ważnym pojęciem jest polityka. Z perspektywy sposobu postępowania, słownik języka polskiego definiuje politykę jako: “zręczne i układne działanie w celu osiągnięcia określonych zamierzeń”.
Polityka (polityki) to pojęcie ogólniejsze niż wzorzec. Wyraża ona generalne zasady, te zaś dopiero implikują stosowanie określonych wzorców. Pozostaje ostatnie już ważne pojęcie: paradygmat: jest to przyjęty sposób widzenia rzeczywistości w danej dziedzinie, doktrynie itp. Np. polityką jest umowa (wymaganie), że stosujemy wzorce a paradygmatem to, że dowolną architekturę budujemy z niezależnych i samodzielnych mniejszych, współpracujących elementów.
Paradygmat obiektowy projektowania oprogramowania to przyjęcie założenia, że oprogramowanie to współpracujące obiekty (komponenty). Kluczową cechą obiektu jest to, że nie ujawnia on swojej wewnętrznej budowy (hermetyzacja) a jedyną formą współpracy obiektów jest ich reagowanie na wzajemnie przekazywane bodźce (wywołania, obiekt ma określone zachowania, więcej w artykule: paradygmat obiektowy). Reakcja na bodziec i wynik tej reakcji zależy od obiektu a nie od bodźca (polimorfizm: np. szyba i dzwon inaczej reagują na identyczne uderzenie młotkiem).
Definicja paradygmatu obiektowego jest praktycznie tożsama z ogólniejszą definicją, jaką jest definicja pojęcia ‘system’: zespół logicznie powiązanych, współpracujących elementów . Wielu autorów dodaje do tej definicji “w określonym celu”, co uważam za nadużycie, gdyż pojęcie cel oznacza czyjeś świadome działanie, zaś to, że otaczający nas świat można opisać (model) jako system, nie wynika z tego, że ktoś go celowo tak stworzył.
Na koniec definicja pojęcia pryncypium: najważniejsza dla kogoś lub dla czegoś zasada albo wartość.
Wzorce projektowe czy polityki tworzenia architektury?
Podstawową, moim zdaniem, zasadą świadomego zachowania jest jego celowość. Jeżeli więc stosujemy (jakieś) wzorce projektowe to należy określić cel ich stosowania.
Nie ma sensu stosowanie jakichkolwiek wzorców dla samego faktu ich stosowania, ale ich świadome stosowanie obniża ryzyko projektu i poprawia jego jakość.
Podstawowym celem inżynierii jest projektowanie rozwiązań, a ich kluczową, poza-funcjonalną, cechą są koszty utrzymania i rozwoju.
Wzorce projektowe to przede wszystkim dobre praktyki obniżające koszty utrzymania i rozwoju.
Postaram się pokazać (postawić tezę), że generalnie chodzi o pewne określone polityki projektowania architektury oprogramowania, a skupię się na specyfice modeli PIM .
Wzorce w literaturze
Literatura na temat wzorców projektowych jest bardzo bogata, myślę że czytelnik łatwo do niej dotrze (patrz mój artykuł cytowany na początku). W tym tekście skupię się na bardzo ważnym aspekcie tych wzorców, jakim jest model dziedziny systemu jako obszar ich stosowania.
Znakomita większość wzorców projektowych opisywanych w literaturze, dotyczy obszaru Control i View architektury MVC. Stosowanie ich w obszarze Model jest bardzo częstym zjawiskiem wśród programistów. Powielanie praktyk znanych z zaleceń C++ czy SmallTalk jest wręcz złym pomysłem (patrz podsumowanie). Czego więc powinni nauczyć się analitycy-projektanci? Tylko tego co wpływa na koszty utrzymania i rozwoju funkcjonalności systemu.
Środowiska wykonawcze (biblioteki, frameworki) zmieniają się dość wolno. Upgrade środowiska ma miejsce co kilka lat. Zmiany w funkcjonalności oprogramowania wspierającego zarzadzanie zachodzą w takt zmian prawa i rynku: nawet kilka razy w ciągu roku. Dlatego właśnie decyzje o zastosowaniu technik i wzorców projektowych należy podejmować w kontekście tego czy projektujemy: implementację logiki biznesowej czy środowisko aplikacji. To drugie stawia wyłącznie wymagania takie jak wydajność i niezawodność oraz kompatybilność.
Oprogramowanie biznesowe (mechanizm realizacji logiki biznesowej) ma nie tylko długi cykl życia ale i bardzo burzliwy.
Dlatego do realizacji Modelu Dziedziny (komponent realizujący logikę biznesową) wymagane jest inne podejście niż do realizacji wymagań poza-funkcjonalnych.
OCP jako miernik jakości architektury
Jedną z kluczowych cech architektury spełniającej powyższe, ekonomiczne, wymagania jest zasada OCP (Open-Closed Principle): oprogramowanie jest otwarte na rozszerzenia, ale zamknięte na zmiany. Oznacza to, że projektant będzie mógł (powinien móc) dodawać kolejne funkcjonalności do klasy (komponentu, systemu), ale nie będzie edytował obecnych już funkcji w sposób, który wpływa na istniejący pozostały kod, który z niego korzysta. Zasada ta jest częścią zestawu zasad zwanych SOLID, są wśród nich także: zasada pojedynczej odpowiedzialności klas (oznacza jeden kontekst a nie jedną operację), zasada segregacji interfejsów (to konsekwencja poprzedniej zasady) . Autor tej publikacji, na podstawie swoich badań, pisze:
Zgodnie z moimi badaniami i punktami, które omówiliśmy powyżej, wniosek jest taki, że nie ma [nie są stosowane] żadne konkretne zasady i regulacje w projektowaniu oprogramowania. Warto zauważyć, że projektowanie jest stylem, jednak nie wszystkie style przebadałem. Zaobserwowałem, że projektanci stosują różne podejścia, np. ta sama agencja Narodów Zjednoczonych raz stosuje opisane zasady a raz nie. Nadal nie ma żadnych zasad ani wskazówek, które stosowane były by we wszystkich przypadkach, chociaż, są próby sformalizowania “dążenia doskonałości”.
Moje wieloletnie obserwacje potwierdzają powyższe spostrzeżenia: wzorce i metody są od lat znane, jednak rzadko są stosowane. Warto tu zwrócić uwagę na fakt, że mamy rok 2021 a o wzorcach mówimy od początków metod obiektowych. Pozostaje pytanie: nie są powszechnie stosowane bo nie są dobre, czy nie są stosowane bo wiedza o nich jest nadal mało rozpowszechniona. A może są inne powody? Moim zdaniem wiedza ta jest powszechnie dostępna, ale nie jest popularna. Po drugie promowanie zwinności (czyli droga na skróty) skutkuje także ograniczaniem prac analitycznych i projektowych w początkowym etapie procesu tworzenia oprogramowania, i tu upatruję głównego powodu małej popularności wzorców: wymagają etapu analizy i projektowania. Analiza i projektowanie podnosi planowane koszty wytworzenia, ale praktyka okazuje nie jest prawdą, że wydłuża czas do pierwszego uruchomienia. Nie jest tajemnicą, że pierwszy etap (jego koszt) często decyduje o wyborze dostawcy, jednak mści się to wielokrotnie na etapie utrzymania i rozwoju.
Jaką wartość wnosi stosowanie wzorców? Pojawia się następujący tok uzasadnienia ich użycia:
- wyznacznikiem jakości oprogramowania są koszty w całym jego cyklu życia, a nie tylko na etapie wytwarzania i wdrażania,
- kluczem staje więc zasada OCP: oprogramowanie jest otwarte dla rozszerzenia, ale zamknięte na zmiany, co w konsekwencji pozwala na uzyskanie liniowego (zamiast wykładniczego) wzrostu łącznego kosztu rozwoju aplikacji: ponosimy koszt realizacji nowej potrzeby, bez dodatkowego kosztu aktualizacji (refaktoryzacja) już używanego,
- w konsekwencji zamiast monolitu, stosujemy architekturę komponentową (np. mikro serwisy, micro aplikacje),
- podstawową jednostką projektowania i rozwoju staje się Usługa Aplikacji modelowana w UML jako Przypadek Użycia (np. patrz Use Case 2.0),
- z uwagi więc na to, że każdy przypadek użycia to odrębny, separowany komponent, mający swój własny cykl życia, wymagający także utrzymania i rozwoju, wymienione zasady (wzorce projektowe) stosujemy także do projektowania jego wewnętrznej architektury.
System to jego architektura oraz zachowanie (struktura i reakcja całości na bodźce). Dlatego mówiąc o wzorcach projektowych, mówimy o wzorcach architektonicznych i o wzorcach zachowania. W tym opracowaniu skupię się głównie na wzorcach architektonicznych, o wzorcach (zasadach) zachowania wspomnę.
Architektura oparta na wzorcach – po kolei
Umowa na zakres czyli jakie usługi – Orientacja na Przypadki Użycia
Na tym etapie podejmujemy decyzję ‘Co i dla kogo aplikacja ma robić’ (a nie JAK).

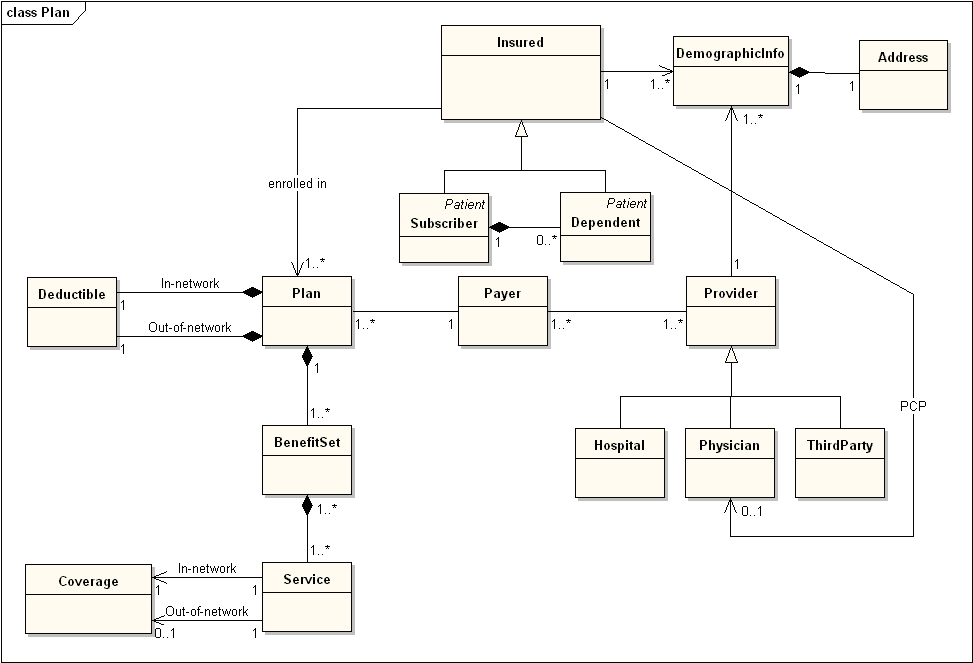
Diagram Przypadków Użycia to diagram pomocniczy w UML . Celem jego tworzenia jest zawarcie umowy na to co ma powstać (usługi) i dla kogo (aktor), czyli komu i do czego ten system ma służyć.
Bardzo ważne: tu wymaganiem biznesowym (usługa aplikacyjna) jest to CO chce uzyskać Aktor Systemu a nie to JAK to będzie realizowane. Decyzja JAK jest decyzją projektanta rozwiązania, decyzja CO jest ustaleniem celu tworzenia oprogramowania. Usługa z perspektywy Aktora, to opis reakcji Systemu (skutek).
Zachowanie bardzo często dokumentujemy, początkowo nieformalnie, w postaci procedury tekstowej (np. wypunktowana lista kolejnych kroków). Kolejny etap to iteracyjno-przyrostowa formalizacja opisu zachowania z pomocą diagramu aktywności lub sekwencji .
Diagram aktywności to początkowo idea wzajemnej komunikacji komponentów, potem algorytmy i mechanizmy. Diagram sekwencji pokazuje już wzajemną komunikację komponentów w postaci wywoływanych operacji interfejsów (na diagramach aktywności także można to pokazać, jednak diagram sekwencji jest tu znacznie łatwiejszy do percepcji).
Prostokąt “Aplikacja” na powyższym schemacie, to “czarna skrzynka” reprezentująca tę aplikację czyli oprogramowanie, które ma powstać. Czy reprezentuje cały przyszły kod? Nie, na tym etapie projektowania mówimy wyłącznie o logice dziedzinowej .
Architektura hexagonalna i wzorzec Model View Controler (MVC)
Podstawowym założeniem jest tu separacja dziedzinowego mechanizmu działania Aplikacji od środowiska w jakim działa . Mozna to zobrazować tak:
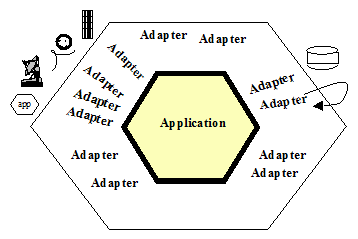
Środowisko wykonawcze aplikacji staje się coraz bardziej wyrafinowane, obecnie można je zobrazować np. tak:
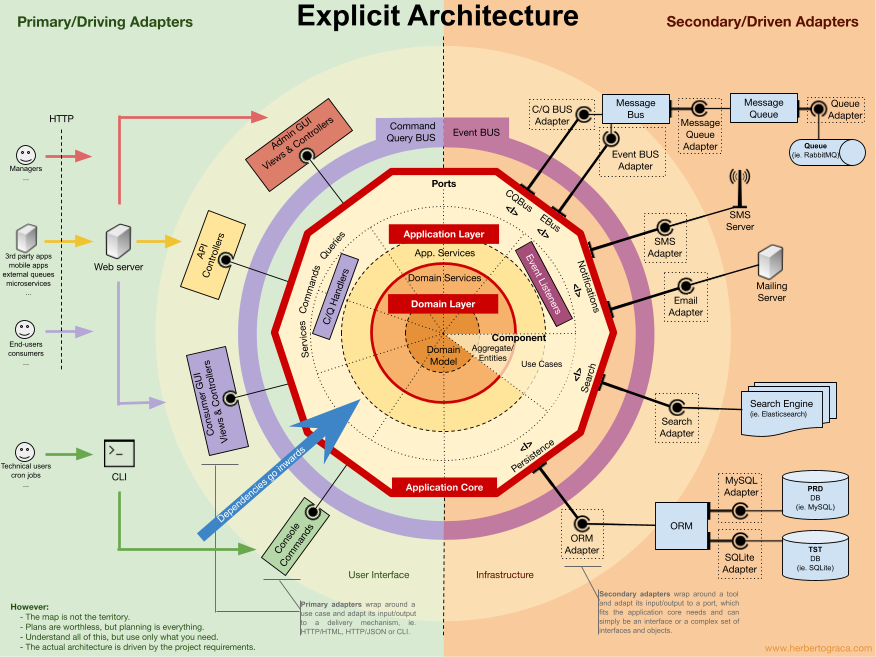
Na diagramie powyżej wyróżniono trzy obszary:
- Application Core (centralny obszar otoczony czerwonym wielokątem).
- User Interface (obszar po lewej stronie oznaczony kolorem zielonym).
- Infrastructure (obszar po prawej stronie oznaczony kolorem pomarańczowym).
Powyższe odpowiada wzorcowi MVC, odpowiednio: Model, View, Controller. Projekt, w którym ma powstać aplikacja to “tylko” obszar oznaczony czerwonym wielokątem, to co jest poza nim “istnieje” już jako systemy operacyjne, sterowniki, biblioteki, inne systemy dziedzinowe. Dlatego jednym z najbardziej fałszywych opisów MVC jest ten mówiący, że Model to (tylko) “model danych”, a Controller to (tylko) “reguły biznesowe”.
Idąc tropem procesu MDA w dalszej części opisana zostanie architektura Modelu czyli mechanizmu działania aplikacji.
“Architektura wysokiego poziomu” aplikacji
Tak zwaną architekturę wysokiego poziomu (ang. HLD, High Level Design) budujemy już na bazie wzorca mówiącego, że usługi aplikacji implementujemy jako odrębne komponenty, separujemy je także od reszty otoczenia. Idea ta nosi nazwę mikroserwisów i jest znana od dość dawna, jeden z najpopularniejszych chyba, znanych mi, schematów blokowych pokazuje to tak:
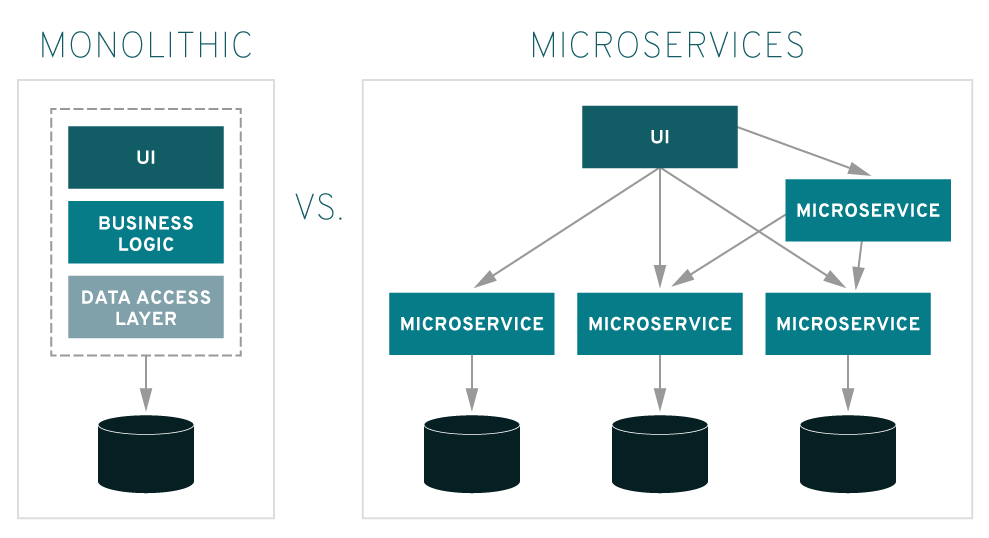
Warto tu podkreślić, że komponenty realizujące usługi aplikacje nie komunikują się między sobą. Więc nasza Aplikacja powinna mieć np. taką wewnętrzną architekturę:

Komponenty realizujące Usługi Aplikacji są integrowane z użyciem API Koordynatora, zaś zewnętrzne usługi są z zasady izolowane Adapterem. Na tym poziomie prosta sytuacja może wyglądać tak:
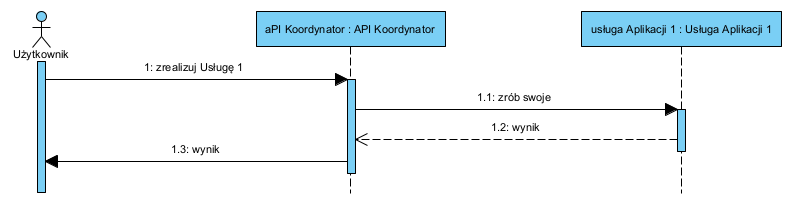
Mamy tu prosty przypadek, gdy usługa aplikacji nie wymaga żadnej wymiany danych między komponentami dziedzinowymi.
Jednak może się zdarzyć, że realizacja jakiejś usługi będzie wymagała wymiany danych między tymi komponentami. Wtedy taki dialog może wyglądać np. tak:
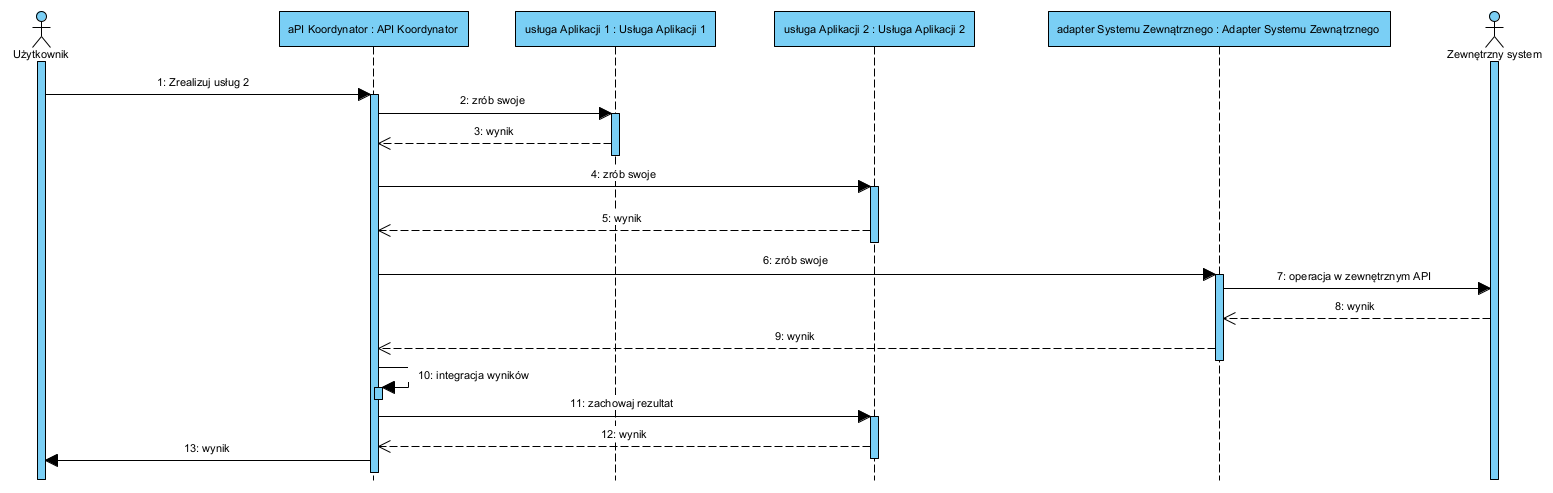
Powyższy diagram obrazuje dwa wzorce: SAGA, czyli cała sekwencja integracji, jako scenariusz, jest sterowana z jednego dedykowanego do tego komponentu . Dzięki temu poszczególne komponenty nie muszą “wiedzieć” niczego o sobie na wzajem.
Komponent Adapter to brama separująca aplikację od jej otoczenia. Zewnętrzne aplikacje (np. integrowane, świadczące usługi itp.) mają API ustalone przez ich producenta, mogą sie też zmieniać w czasie, na co nie mamy żadnego wpływu. Z tego powodu autorzy często stosują tu zamiennie lub łącznie nazwę tego wzorca: adapter/gateway.
Dlatego dobrą praktyką jest:
- separowanie ich od lokalnej naszej logiki aplikacji (hermetyzacja naszego kodu),
- transformacja wywołań cudzego API i zwracanych wyników, to postaci optymalnej z naszego punktu widzenia,
- polimorfizm czyli wywoływanie komponentów, tak że wynik zależy nie od nazwy polecenia a od tego jaki komponento zostanie wywołany.
Korzyści z tego podejścia:
- kupione na rynku komponenty gotowe (COTS, ang. commercial off the shelf) łatwo włączyć bo mają tylko jeden styk z aplikacją,
- wymiana komponentu na inny to także tylko ingerencja w API lub napisanie adaptera,
- integracja z zewnętrznymi aplikacjami nie wymaga ingerencji w pozostałe komponenty, wymaga co najwyżej adaptera.
Wewnętrzna architektura komponentu realizującego usługę aplikacji
Jest to tak zwana architektura niskiego poziomu (LLD, ang. Low Level Design). Na tym poziomie projektujemy logikę realizacji usługi.
BCE
Już w latach 90-tych powstał wzorzec BCE (ang. Boundary, Control, Entity). Był wykorzystywany w ramach dość ciężkiej metodyki RUP (Rational Unified Process) oraz lekkiej, zwinnej, zwanej ICONIX . To były początki orientacji na komponenty i przypadki użycia . Podział na komponenty oraz wzorzec (zasada) projektowania zorientowany na odpowiedzialność klas/komponentów, były kolejnym zestawem dobrych praktyk .
Poniżej ilustracja z książki Scotta Amblera (sygnatariusz Agile Manifesto):
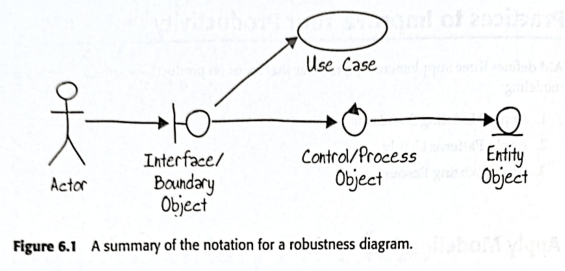
Nazwa Robustness diagram, to coś co można tłumaczyć jako “bazowy model architektury” do dalszych prac projektowych (rodzaj fundamentu na tym poziomie projektowania). Wzorzec ten to umowa, że dowolny komponent (klasa) może realizować: albo funkcję interfejsu (boundary), albo realizować określoną logikę dziedzinową (control), albo realizować funkcję utrwalania dziedzinowych danych (entity). Dla ułatwienia szkicowania, przyjęto że każdy z tych typów odpowiedzialności będzie miał dedykowany symbol, ikonę (jak na rysunku powyżej). Istotne jest także to, że symbole te nie przewidują pokazywania atrybutów, a jedynie operacje. Obecne narzędzia CASE pozwalają na pokazanie atrybutów, ale w początkowych etapach analiz i projektowania nie ma takiej potrzeby, np. istotne jest to, że istnieje taki byt jak faktura, ale absolutnie nie jest istotne to ile ma on atrybutów i jakie one są. Liczy się jedynie to, że faktura to “treść opisująca transakcję kupna-sprzedaży).
Łańcuch odpowiedzialności
Powyższy diagram to także prezentacja wzorca “Łańcuch odpowiedzialności” . Wzorzec ten bazuje na zasadzie pojedynczej odpowiedzialności oraz założeniu, że nie pomijamy żadnej z nich. Efektem jest kaskada (łańcuch) odpowiedzialności: komponent Boundary odpowiada wyłącznie za dialog z Aktorem (interfejs), komponent Control odpowiada wyłącznie za realizację logiki biznesowej (sterowanie), komponent Entity odpowiada wyłącznie za utrwalanie danych (pierwotnie były to obiekty DAO: ang. Data Access Object, stanowiące sobą zapytania SQL do relacyjnych baz danych).
Repozytorium
Jest to model projektowania, zakładający, że “dane nie wiedzą komu wolno je czytać” co ogromnie upraszcza ich strukturę. Schematycznie, korzystając z wzorca BCE, można to przedstawić tak:

Komponent nazwany “Kontrola dostępu do dokumentów” to Repozytorium. To komponent, który separuje dane od reszty aplikacji, i jako jedyny zawiera także reguły dostępu do nich. Ten komponent to także jedyny interfejs do danych, więc dodatkowo pełni rolę adaptera: zmiana miejsca przechowywania danych wymaga jedynie zmiany adresacji w tym komponencie.
Ważne: repozytorium nie tworzy nowych obiektów, a jedynie je przechowuje (patrz dalej: fabryki). Komunikacja między Kontrola dostępu a Dokument zachowany odbywa się na bazie wzorca publish/subscribe .
Envelope – koperta
Zachowany dokument może być dowolnym komunikatem XML, JSON itp. Jak pokazano w części opisującej architekturę heksagonalną, nie interesuje nas na tym etapie projektowania fizyczny model danych. Wiemy jednak, że mogą one mieć nietrywialną strukturę. Zakładamy także, że komunikacja między komponentami polega na wymianie (tych) komunikatów, które mogą być dowolną “paczką danych”, którą to paczkę (np. jako ciąg znaków XML lub JSON) można zachować w całości jako wartość atrybutu komponentu Entity .

Obiekty Entity z zasady nie realizują żadnej logiki biznesowej, zachowują jedynie dane, mają wyłącznie operacje zapisz/przywołaj, tworzone i usuwane są przez poprzedzające je komponenty realizujące logikę usługi lub przez dodatkową usługę, gdy zajdzie taka potrzeba. Ewentualne dodatkowe atrybuty służą tu wyłącznie do indeksowania .
Fabryki i metody wytwórcze
Tworzenie nowych obiektów to temat wielu dyskusji. Jednak najczęściej pojawia teza mówiąca, że obiekt jednak nie tworzy się sam. Druga teza to: repozytorium (patrz wyżej) nie tworzy obiektów, które jedynie przechowuje. One powstają poza nim. Więc gdzie? Jedynym miejscem, w jakim znajdziemy kompetencje do tworzenia nowych obiektów, jest miejsce w którem jest wiedza o tym czy są poprawne. Po trzecie: czym jest komunikat (treść)? Może być obiektem określonej klasy, ale czy musi? Czy np. faktura powinna być obiektem określonej klasy, czy może jednak wystarczy, że jako treść (bo to jest określona treść) umieścimy ją w “kopercie”?
Poniżej scenariusz tworzenia nowego dokumentu:
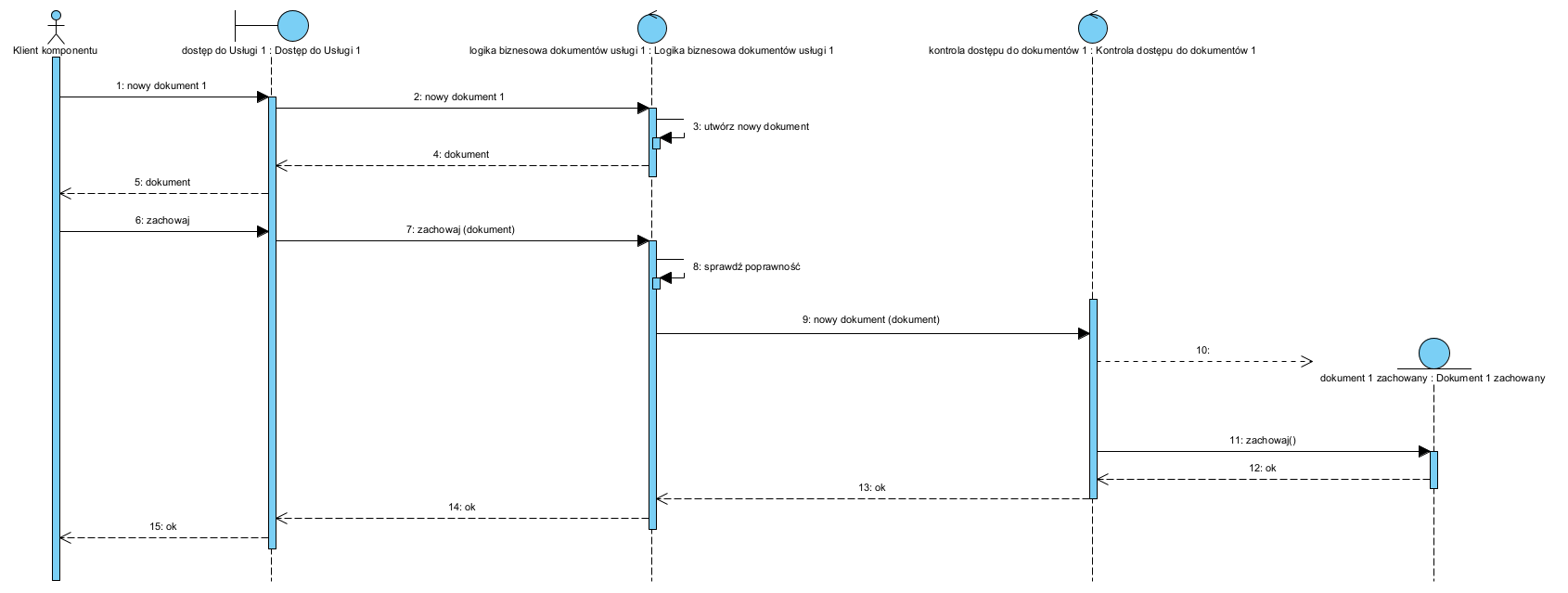
Tu widać wszystkie zalety opisanych wzorców:
- logika tworzenia i walidacji treści jest w jednym miejscu,
- repozytorium dostaje poprawne dokumenty i nie przechowuje żadnej logiki ich tworzenia ani sprawdzania,
- repozytorium nie tworzy dokumentów a jedynie miejsce do ich przechowania, dlatego może być implementowane dowolnie, nawet jako system plików,
- bez uszczerbku dla logiki aplikacji dane mogą być w dowolnym momencie wyniesione do “chmury”.
Architektura realizująca powyższe wygląda tak:

Agregat jako model danych
Agregat to drzewiasta struktura.
Naturalną formą zarządzania informacją są dokumenty a nie “relacyjne bazy danych”.
Relacyjny model danych opracował Edgar Codd w 1970 roku, jego celem i kluczową zaletą jest mechanizm spójności i transakcyjności zbioru danych (ACID). Model ten niestety jest bardzo nienaturalny z perspektywy dokumentów: w modelu relacyjnym ich po prostu nie ma. Warto pamiętać, że:
“Information Science includes two fundamentally different traditions: a “document” tradition concerned with signifying objects and their use; and a “computational” tradition of applying algorithmic, logical, mathematical, and mechanical techniques to information management. Both traditions have been deeply influenced by technological modernism: Technology, standards, systems and efficiency enable progress. Both traditions are needed. Information Science is rooted in part in humanities and qualitative social sciences. The landscape of Information science is complex. An ecumenical view is needed.” [Nauka o informacji obejmuje dwie zasadniczo różne tradycje: tradycję “dokumentową”, zajmującą się opisywaniem obiektów i ich wykorzystaniem, oraz tradycję “obliczeniową”, polegającą na zastosowaniu technik algorytmicznych, logicznych, matematycznych i mechanicznych do zarządzania informacją. Obie tradycje znalazły się pod głębokim wpływem modernizmu technologicznego: Technologia, standardy, systemy i wydajność umożliwiają postęp. Obie tradycje są potrzebne. Nauka o informacji jest częściowo zakorzeniona w naukach humanistycznych i jakościowych naukach społecznych. Krajobraz nauki o informacji jest złożony. Potrzebne jest spojrzenie ekumeniczne.]
Dlatego są obszary, w których model relacyjny sprawdza sie doskonale (obliczenia) i obszary, w których nie sprawdza się wcale (dokumenty). Poniżej struktura hipotetycznego dokumentu. Poziom zagnieżdżeń treści może tu być dowolny:
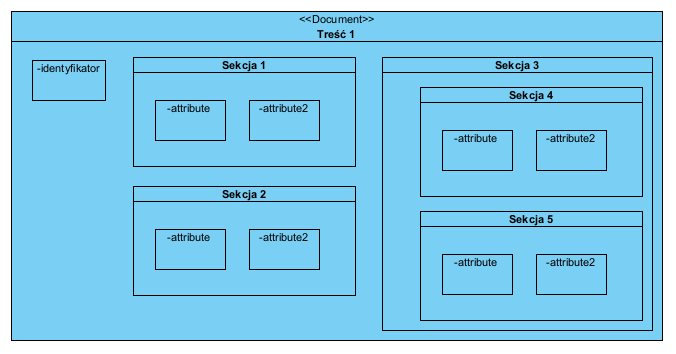
Jeżeli założymy, że powyższe to struktura pliku XML/JSON to jej złożoność nie ma znaczenia, bo zawsze jest to płaski tekst (string). Powyższa struktura wyrażona jako prosty diagram klas w UML wygląda tak:

Powyższe jest typowym agregatem: tożsamość niesie korzeń tej struktury, pozostałe jej elementy nie muszą mieć tożsamości, gdyż można do nich dotrzeć bez problemu znając tożsamość agregatu. Agregat sam dla siebie jest przestrzenią pojęciową, podobnie jak wewnętrzne sekcje. Dlatego atrybuty w różnych sekcji mogą mieć takie same nazwy.
Zaletą korzystania z agregatów jest łatwość manipulowania nimi i zarządzania ich cyklem życia. Dane nigdy nie są “rozsiane”. Bardzo dużym błędem jest ich mapowanie na relacyjne struktury tabelaryczne, gdyż to praktycznie niszczy wszystkie korzyści z ich stosowania (patrz: The One Question To Haunt Everyone: What is a DDD Aggregate? – Thomas Ploch – DDD Europe 2022).
Agregat i jego stan vs. status
To kolejny temat budzący wiele emocji. generalnie:
…stan obiektu to jego cecha, status obiektu to opis niebędący cechą tego obiektu.
źr.: Kiedy maszyna stanowa a kiedy jednak status?
Innymi słowy stan obiektu, jako jego cecha, jest zapisany jako wartość jednego z jego atrybutów. Status obiektu, jako informacja o nim, musi być zapisany poza nim. Np. kolor elewacji budynku to jego cecha, to będzie wartość atrybutu opisującego ten budynek. Jednak zadłużona hipoteka tego budynku nie jest jego cechą, jest osobną informacją dotyczącą tego budynku. Faktura od momentu jej utworzenia, jest niezamienialną treścią. Np. saldo jej opłacenia nie może być cechą faktury, to stan konta księgowego, przechowującego saldo tej faktury.
Agregat to mniej lub bardziej złożony opis faktu lub obiektu, ale nie nośnik jakiejkolwiek logiki opisującej ten obiekt lub fakt. Powyższe wzorce właśnie to realizują: logika biznesowa jest poza repozytorium przechowującym agregaty w “kopertach”. Agregat to treść przechowująca opis, koperta to miejsce na zapisanie aktualnego statusu tego co opisuje agregat umieszczony w tej kopercie.
A co z Domain Driven Design (DDD)?
No właśnie, co z DDD? W swojej książce z 2003 roku Evans opisuje pewne podejście do architektury. Opisał je schematycznie tak:

Evans deklaruje tu:
- przywiązanie do projektowania opartego na modelowaniu (ang. Model Driven Design, MDD), ale to praktycznie to samo co MDA rodem z OMG.org i UML.
- izolacje dziedzinowej części od reszty (isolate domain), ale to nic innego jak opisana architektura heksagonalna,
- Smart UI – ale to nic innego jak wydzielenie View w MVC,
- Services – ale to elementy logiki Control w opisanej BCE,
- Entities – ale to nośniki tożsamości w BCE o tej samej nazwie,
- Repositories – ale to opisany wyżej znany z innych źródeł wzorzec, to także element logiki Control w opisanej BCE,
- Agregates – ale to wzorzec opisany wcześniej ,
- Value Object – ale to pozbawiony tożsamości obiekt klasy Value opisany wcześniej w UML,
- Factory – ale to kolejna usługa (Control w BCE), mająca jedynie określony kontekst, niczym innym się nie wyróżnia.
O związkach BCE z DDD pisał także Petter Holmström .
Niewątpliwym wkładem Evansa jest zwrócenie uwagi na to co nazwał “Ubiquitous language”:
Używając języka opartego na tym wzorcu, zbliżamy się do modelu, który jest kompletny i zrozumiały, składający się z prostych elementów, które łączą się w celu wyrażenia złożonych pomysłów.
E.Evans
…
Eksperci dziedzinowi powinni sprzeciwiać się używaniu w projekcie pojęć, które są niezgodne ze słownictwem danej dziedziny, zaś programiści powinni to uszanować by nie powodować niejednoznaczności lub niespójności, które prowadza do nieporozumień.
NoSQL i dokumenty
Prawie 20 lat temu pojawiły się bazy danych zwane NoSQL (Not only SQL). Porównania pokazują też, że bazy NoSQL (np. dokumentowe) oferują znacznie szybszy dostęp do danych . Porównania pokazują, że czas zapisu i dostępu do złożonych dokumentów w bazach NoSQL jest nawet o trzy rzędy (tysiąckrotnie!) krótszy niż w bazach SQL .
Model relacyjny to sztywna struktura i po utworzeniu jest praktycznie niezmienny. Niestety w obecnych czasach stabilna na wiele lat struktura danych to praktycznie fikcja. Po drugie udział danych strukturalnych w ogólnej ilości zbieranych danych stale spada, ocenia się, że obecnie dane strukturalne to <10% ogółu zebranych danych (wiedzy). Dokumenty biznesowe, ich struktura, zmieniają sie wraz ze zmianami prawa i modeli biznesowych, czyli nie raz nawet częściej niż raz w roku. Dlatego oparcie się na dokumentowych wzorcach jest obecnie znacznie skuteczniejsze, mikroserwisy zresztą z zasady wykluczają monolityczne relacyjne bazy danych (integracja poprzez współdzielenie danych).
Rezygnacja z modeli relacyjnych znakomicie upraszcza etap analizy i projektowania, co widać np. w opisie architektury heksagonalnej jako wzorca (motory baz danych są częścią infrastruktury a nie dziedziny systemu).
Notacja UML od lat doskonale wspiera “nieesqelowe” metody projektowania oprogramowania, w tym dokumentowe (w szczególności XML) struktury danych . Warto zaznaczyć, że UML nie służy do modelowania danych w modelu relacyjnym!
Dane, biznesowe w szczególności, są organizowane w struktury dokumentowe, jak wskazano powyżej, jest to ich naturalna postać (więcej na ten temat w artykule Struktury formularzy jako forma wyrażania wymagań).
Jak widać dane i ich struktury (dokumenty) są całkowicie oddzielone od metod ich tworzenia, korzyści z takiego podejścia opisuje Evans w DDD, rekomendacje takie można znaleźć u wielu innych autorów .
Projekt aplikacji nie wymaga żadnego SQL i relacyjnego modelu. Na etapie projektowania na pewno nie, a na etapie implementacji obecnie coraz częściej także już nie.
Architektura usługi to dość prosta struktura. Każdy konkretny przypadek użycia (usługa aplikacji) może być nieco inny, ale ogólna idea zastosowania zasad: łańcuch odpowiedzialności (nie pomijamy żadnego komponentu w drodze od aktora do dokumentu), repozytorium (interfejs do kolekcji obiektów biznesowych), i nowe zachowania, to nowe a nie zmienione, komponenty zorientowane na role. Całość daje bardzo przydatny zestaw tylko kilku wzorców na etapie analizy i projektowania modelu dziedziny systemu (komponent realizujący logikę biznesową, czyli wymagania funkcjonalne, to Model Dziedziny Systemu) .
W realnym projekcie każda klasa miałaby oczywiście operacje. Tu tego nie pokazywałem by nie komplikować diagramów. Przykład realnego projektu wykonanego wg. powyższych reguł opisałem w artykule Inżynieria oprogramowania z użyciem narzędzia CASE ? przykładowy projekt. Szczegóły omawiam na szkoleniach: Analiza obiektowa i projektowanie logiki oprogramowania z użyciem notacji UML.
Podsumowanie
To co opisano to architektura komponentowa znana od ponad 20 lat . Orientacja na odpowiedzialność klas znana od 2003 roku, książka Rebeki Wirfs-Brock jest cyklicznie wznawiana . Także w 2003 roku, w duchu powyższych zasad, Eric Evans opisał wzorzec Domain Driven Design .
Problemem jaki dostrzegam, jest uproszczona edukacja na studiach, zrównująca projektowanie obiektowe z programowaniem z użyciem języków obiektowych. To co nazywamy programowaniem obiektowym (OOP) jest często definiowane na bazie cech języka C++:
- Wszystko jest obiektem
- Każdy obiekt jest instancją klasy
- Każda klasa ma klasę nadrzędną
- Wszystko dzieje się przez wysyłanie wiadomości
- Wyszukiwanie metod używa łańcucha dziedziczenia
I to niestety jest kluczowe źródło wielu problemów. Punkt 3. jest jedną z najgorszych i najkosztowniejszych praktyk w obszarze modelu dziedziny, uzależniających definicje klas od siebie (łamanie kluczowej zasady jaką jest hermetyzacja). Punkt 5 jest w zasadzie martwy, bo metody albo są znane bo wymagane interfejsem, albo nie wiemy, że są (kosztowne, osierocone elementy kodu w wielu systemach). Dziedziczenie z zasady łamie hermetyzację (współdzielenie elementów kodu, przypominam, że dziedziczenie usunięto z UML w 2015 roku).
Tak więc paradygmat obiektowy to po prostu komunikujące się, hermetyczne, obiekty i tak projektujemy. Klasy to wyłącznie definicje obiektów w kodzie źródłowym, i tak kodujemy (UWAGA! Kod programu wyrażony w języku obiektowym to metamodel działającego programu!).
Typowymi popularnymi i złymi praktykami są umieszczanie metod kreacyjnych w ich klasach bazowych czy pobieranie i zapisywanie wartości atrybutów poleceniami get/set-atrybut. Szkodliwość tej drugiej praktyki opisał Fowler w DTO . Fowler jest autorem jednej z najpopularniejszych na świecie pozycji o wzorcach projektowych, mającej już kilka wznowień i aktualizacji .
Jak pokazano, analiza i projektowanie DOSKONALE obywa się bez SQL i relacyjnych modeli danych (nie używam ich na etapie analizy i projektowania od ponad 15 lat i nie jestem w tym osamotniony na świecie). Problem jaki stwarzają usilnie projektowane i realizowane “systemowe relacyjne modele danych” jest znany od dekad:

Odejście od tej praktyki (modele danych i SQL od samego początku analizy i projektowania) pozwala projektować aplikacje niezależnie od metod implementacji, zrozumiałe dla interesariuszy. Projekt rozwiązania na tym etapie (przed wyborem dostawcy) z zasady powinien abstrahować od implementacji (jest to model PIM, niezależny od platformy implementacji). Dzięki czemu cała dokumentacja, jeżeli zostanie napisana językiem i słownictwem interesariusza (patrz DDD), może być zrozumiała dla niego.
No i na koniec: chmurowe systemy utrwalania danych często nie operują językiem SQL i relacyjnym modelem danych, więc pora w końcu zapomnieć o SQL i relacyjnie zorganizowanych danych na etapie analizy i projektowania. Zresztą dużych transakcyjnych systemów, niekorzystających z SQL i relacyjnego systemu organizacji danych, jest bardzo dużo, nie tylko sklep Amazon.
Tak więc poniższe bazgroły nie są “modelem dziedziny systemu”:
Lista wzorców wykorzystana w artykule
- BCE (Boundary, Control, Entity) – projektowanie zorientowane na odpowiedzialność klas: B – pośredniczenie pomiędzy aplikacją a jej otoczeniem, C – realizacja logiki dziedzinowej, E – utrwalanie,
- agregat – przechowywanie danych w zwartej, hermetycznej, hierarchicznej struktury (np. jako dokument, np. JSON, XML),
- saga – zarządzanie scenariuszami (sekwencje, procedury) z jednego miejsca,
- łańcuch odpowiedzialności – kaskadowe przekazywanie wywołań od interfejsu komponentu do danych z użyciem polimorfizmu,
- repozytorium – separowanie (hermetyzacja) danych i dostępu do danych od reszty aplikacji,
- micro serwis (lub mikro-aplikacja) – implementacja każdej usługi systemu jako odrębnego komponentu,
- adapter – izolowanie i uniezależnianie wewnętrznych komponentów aplikacji od jej otoczenia,
- envelope – przechowywanie danych (agregat) w indeksowanych prostszych obiektach,
- publish/subscribe – komunikacja np. pomiędzy obiektem kontrolującym dostęp do danych a nośnikami tych danych (entity) metodą wywoływania ich po ID,
- wszystkie powyższe praktycznie dotyczą także integracji aplikacji.
Dostępny jest warsztat, na którym może w praktyce poznać te wzorce i przećwiczyć ich stosowanie w praktyce: ZAPRASZAM. Wzorce DDD i BCE wykonane w UML: Dokumentacja DDD.


Uzupełnienie literatury.