Wprowadzenie
Tym razem artykuł na temat pewnej ciekawej konstrukcji. Została ona opisana przez Rebekę Wirfs-Brock w 1999 roku . O komponentach wcześniej pisał już np. Souza .
Pomysł nie zdobył wtedy zbyt dużej popularności, jednak obecnie, w dobie wzorców opartych o mikroserwisy i mikro aplikacje, wraca do łask (patrz Architektura C4). Ja stosuję go już od dłuższego czasu (patrz: projektowanie zorientowane na interfejsy). Skróty HLD i LLD to odpowiednio: High-Level Design (projekt wysokiego poziomu) i Low-Level Design (projekt niskiego poziomu). Są to poziomy abstrakcji w modelu PIM. Jest to także opis stylu projektowania architektury systemu zorientowanego na interfejsy (architektura zorientowana na interfejsy).
Pakiet w UML
W notacji UML pakiety są elementem grupującym, zapewniają możliwość strukturyzacji i organizacji elementów modeli UML. Specjalnym typem pakietu jest właśnie model :

Pakiet, jako element grupujący elementy, może więc nie tylko reprezentować (oznaczać) abstrakcję komponentu, ale także grupować jego elementy w repozytorium projektu UML i opisywać ich strukturę: wraz zawartością może stanowić model.
Pakiet jako podsystem
Skorzystała z tego Rebeka Wirfs-Brock, proponując bardzo użyteczną konstrukcję:

Skoro więc pakiet może grupować “cokolwiek”, może więc w szczególności grupować elementy modelujące np. usługę aplikacji na poziomie specyfikacji i realizacji.
Standardowo w UML można, dla usystematyzowania modelu i struktury repozytorium, tworzyć konstrukcje jak poniżej:

Tu warto zwrócić uwagę na to, że zgodnie ze stylem projektowania zorientowanego na interfejsy, klasy na powyższym modelu także reprezentują interfejsy, realizacje ich operacji to mogą być metody tych klas, albo wywołania interfejsów złożonych komponentów.
Wirfs-Brock proponuje umieszczenie abstrakcyjnego interfejsu wewnątrz pakietu, który graficznie jest dedykowanym symbolem dla stereotypu ‘subsystem’, ta abstrakcją może być także ww. przypadek użycia:

Standardowy kształt reprezentujący pakiet na diagramach, został podzielony na obszary: operacje (abstrakcyjny interfejs), specyfikacja, realizacja. Główną zaletą tej konstrukcji, w porównaniu z “tradycyjną”, jest możliwość uporządkowania treści diagramu i struktury repozytorium, poprzez umieszczenie abstrakcji specyfikacji usługi wewnątrz pakietu, który reprezentuje także jej realizację (architekturę).
W przypadku gdy użyjemy tej konstrukcji do organizowania modeli usług aplikacji (przypadków użycia), wygląda to jak na diagramie powyżej. Konstrukcji tej można użyć z powodzeniem do innych wewnętrznych komponentów, dlatego mamy do dyspozycji dodatkową przestrzeń na pokazanie nazw operacji komponentu (pakiet, zgodnie z MOF, to także klasyfikator).
W projektach realizowanych od ogółu do szczegółu, korzystanie z tej konstrukcji jest to bardzo przydatną metodą, bo pozwala zadeklarować element modelujący komponent, a później wypełnić go treścią, zachowując od początku spójną, hierarchiczną strukturę projektu i repozytorium.
Przykład
Przykładowa struktura dla dwóch przypadków użycia wygląda jak poniżej:

Powyższy schemat obrazuje strukturę diagramów:
- diagram przypadków użycia to najwyższy poziom abstrakcji: specyfikuje umową jako listę wymaganych usług systemu,
- kolejny u góry po prawej jeden diagram, to model architektury wysokiego poziomu (HLD) tego systemu, gdzie każdy przypadek użycia to osobny komponent (np. mikroserwis) mający swoją implementację, taki model pokazuje także wewnętrzną integrację tych komponentów oraz ewentualną integrację z otoczeniem (inne systemy),
- każdy komponent, realizujący określony przypadek użycia, ma swoją odrębną wewnętrzną architekturę (LLD).
Powyższe stanowi prostą i skuteczną metodę porządkowania elementów modeli, zgodną z UML więc nie powinno być problemu z wykonaniem takiego diagramu, a jak widać niektóre narzędzia (tu Visual Paradigm) są do tego przygotowane. Jeżeli Wasze narzędzie nie oferuje dedykowanego pakietu w wersji proponowanej przez Wirfs-Brock, porządkowanie architektury z pomocą pakietów ułatwia modelowanie oraz zrozumiałość modeli i strukturę repozytorium projektu.
Rebecca Wirfs-Brok opisuje projektowanie pojedynczych komponentów (lub prostych aplikacji z jednym PU). Bardziej wyrafinowane przypadki opisałem w artykule Projektowanie czyli architektura kodu aplikacji. Poniżej jeden ze schematów skomentowanych w tym artykule:
Podsumowanie
Czy ma sens takie modelowanie? Dlaczego nie zacząć od razu kodować? W małym projekcie zapewne byłoby to przerostem formy nad treścią (ale nie zawsze!). Jednak większe projekty realizowane “od razu w kodzie”, mają ogromne problemy ze spójnością, separacją domen (dziedzina systemu i model pojęciowy ) oraz z podejmowaniem decyzji w jakiej kolejności i co ma powstawać, bo z zasady nie powstanie od razu cały system (patrz także recenzja książki: Marsz ku klęsce).
Do tego należy dodać typowe obecnie wymaganie biznesowe: nie chcemy i nie możemy czekać na ukończenie i oddanie całego systemu, chcemy mieć możliwość jak najszybszego usprawnienia pracy i rozpoczęcia korzystania z wybranych usług systemu. Pozostałe mogą być wdrażane w umówionej kolejności, wraz z upływem czasu. Więc na pewno nie może to być monolit.
Jest to możliwe pod jednym warunkiem: całość musi zostać podzielona na odrębne i samodzielne komponenty “pierwszego dnia projektu”. Innymi słowy: projekt zaczynamy zawsze od opracowania architektury całości systemu (HLD), a potem kolejno (iteracyjnie) dopracowujemy detale każdego komponentu (LLD) i dostarczamy je klientowi.
Kolejny powód do modelowania, szczególnie HLD, to integracja. Otóż, jeżeli uznać, że żadna aplikacja biznesowa nie działa samodzielnie, a zawsze jako element większej całości, to znaczy, że: żaden system “nie jest mały”, że jest zawsze częścią nadrzędnego systemu, systemu wspierającego całą organizację, jej dostawców i odbiorców, to znaczy, że
realnie zawsze modelujemy “duży system” lub jego integralną część.
To zaś oznacza, że zawsze należy wykonać (mieć) model HLD systemu całej organizacji. Bez tego nie jest możliwa analiza wpływu: na co w firmie ma wpływ ten “mały” system, który właśnie wdrażamy lub modyfikujemy.
Na koniec ciekawe zestawienie jak ewoluowało podejście do projektowania w latach 1990 – 2005. Manifest Agile (Manifesto for Agile Software Development) opublikowano w 2001 roku. Po tym czasie sygnatariusze manifestu, w swoich późniejszych publikacjach, zaczęli zwracać jednak uwagę na projektowanie architektury by unikać bałaganu w większych projektach.

Od 2005 roku te metody są doskonalone. Pojawiły się mikroserwisy, fala fascynacji pokazała, że nadmierne rozdrabnianie usług wprowadza chaos, lekarstwem mało być Use Case 2.0 . Pojawiają próby porządkowania mikrosewisów . Jednak chyba największy wkład w metody projektowania oparte na architekturze ma właśnie idea projektowania zorientowanego na role i odpowiedzialność klas .
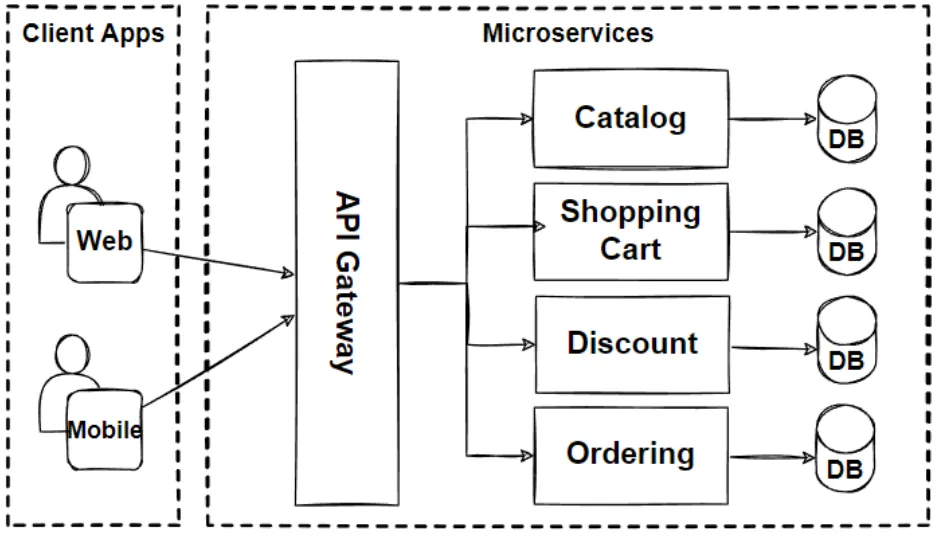
Warto też zwrócić uwagę, na ogromne podobieństwo systemu komponentów proponowanego Wirfs-Brock do Architektury C4 oraz mikroserwisów i “API Gateway” .
Dodatek: koniec wodospadów
Nadal bardzo często wielu autorów przypomina i krytykuje “wodospadowe” (waterfall) metody wytwarzania oprogramowania, słusznie wytykając im nieefektywność i nieadekwatność do aktualnej zmiennej sytuacji i potrzeb rynku. Podstawą tej krytyki jest teza, że analiza i projektowanie to żmudne, szczegółowe i długie projektowanie całego systemu. Była by to prawda, gdyby ten system miał być monolitem (zresztą decyzja o projektowaniu jednej relacyjnej bazy SQL dla całej aplikacji to właśnie decyzja o budowie monolitu).

Ale analiza i projektowanie to faktycznie nie musi być waterfall i monolit. Szybkie (można nawet powiedzieć, że zwinne) tworzenie oprogramowania, to analiza warstwy operacyjnej działania firmy i szybkie modelowanie komponentowej architektury całości aplikacji na poziomie HLD. Następnie iteracyjnie projektujemy szczegóły czyli architekturę (wnętrze) kolejnych komponentów (LLD) i zlecamy ich implementację. Całość jest przewidywalna, bo ma mamy obraz całości (HLD to także interfejsy między komponentami) i możliwa jest wycena fixed-price, kolejne kroki to, w ustalonej kolejności zależnej od potrzeb biznesowych Zamawiającego, implementacja i oddawanie do użytku kolejnych usługi aplikacji (komponentów):

Więc duży projekt i projektowanie poprzedzające wdrożenie to nie jest żaden monolit. Nie ma tu projektu żadnej centralnej bazy danych, nie ma projektowania detali całości na samym początku. Każdy komponent “żyje własnym życiem” czyli mamy mikroserwisy: Aplikacje webowe i mikroserwisy czyli architektura systemów webowych.
Ostatniego dnia projektu mamy działający system oraz jego pełną i aktualną dokumentację.


Polecam też niedawny wpis tu:
https://www.makeuseof.com/high-level-system-design-vs-low-level-system-design/