Artykuł ma dwie części. Pierwsza część jest adresowana do kadr zarządczych, cały artykuł (obie części) do osób zajmujących się projektowaniem rozwiązań.
Wstęp
Mamy ogólnoświatową sieć Internet, aplikacje lokalne i w chmurze, aplikacje naszych kontrahentów i aplikacje centralnych urzędów. Wszystkie one współpracują i wymieniają dane, czyli są zintegrowane. Dlatego integracja stała się cechą każdego systemu informatycznego.
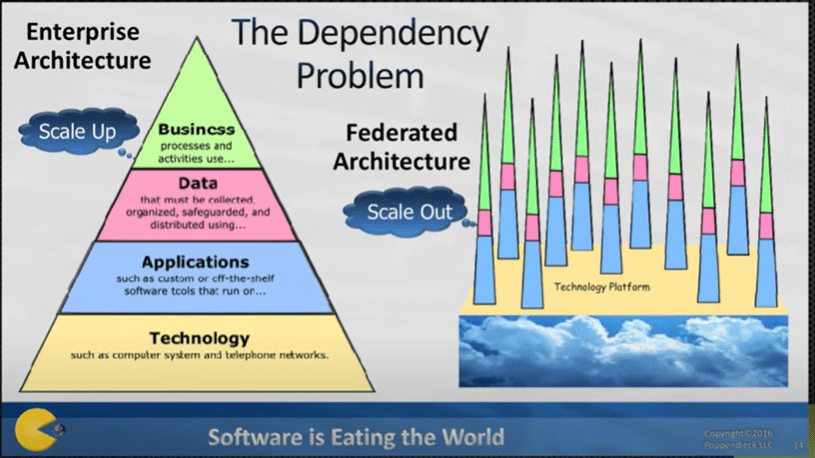
Wyjątkowo na początku (poniżej) umieszczam cały ten ciekawy referat, można bo pominąć i czytać dalej, jednak jeżeli ktoś chce poznać przewidywania z roku 2016 i ma czas, polecam (teraz lub później):
Obecnie kluczowym pytaniem jest: Jak zintegrować, a nie: Czy zintegrować.
Pogodzenie się z tym, że świat systemó ERP już nigdy nie będzie tak prosty jak w czasach mainframe’ów, czyli jednej centralnej aplikacji, jest nieuniknione.
Czym jest obecnie integracja? To wymiana danych a nie ich współdzielenie: dane z urzędem wymieniamy, dane z kontrahentem wymieniamy, nie współdzielimy żadnych danych z tymi podmiotami, każdy ma swoje własne, bezpieczne bazy danych, i to wszystko ładnie działa! Idea zbudowania wszystkich funkcjonalności jako zintegrowanej aplikacji na jednej współdzielonej bazie danych w czasach obecnych jest utopią. Taką samą jak hipotetyczna centralna baza danych dla wszystkich sklepów internetowych, firm kurierskich i banków, a one są jednak zintegrowane: one wymieniają dane a nie współdzielą!
ERP to (ang.) Enterprise Resource Planning czyli Planowanie Zasobów Przedsiębiorstwa. To system wykorzystywany przez firmy do zarządzania i integrowania ważnych elementów ich działalności. Ale kto powiedział, że to ma być monolit od jednego producenta?
Nadal spotykam pejoratywne określenia “system pointegrowany” jako krytykę budowy systemu ERP z komponentów i integracji jako wymiany danych. Autor tego określenia najprawdopodobniej nadal żyje w świecie mainframe.
Chociaż dostawcy systemów ERP oferują aplikacje dla przedsiębiorstw i twierdzą, że ich zintegrowany system jest najlepszym rozwiązaniem, wszystkie moduły w jednym systemie ERP rzadko kiedy są najlepsze z najlepszych.
https://www.gartner.com/en/information-technology/glossary/best-of-breed
Integracja tak, ale czy to ma być jedna wspólna baza danych?
Po pierwsze dane mają różne konteksty, a ich znaczenie zależy od konkretnego kontekstu i miejsca użycia:
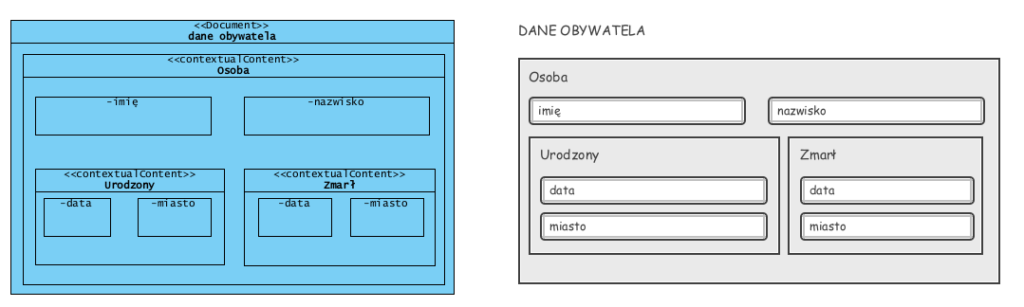
Powyżej zobrazowano dane i ich kontekst. Data może być datą urodzin lub datą śmierci i nadal jest to data. Osoba może być obywatelem w państwowym rejestrze, ale może być pracownikiem, klientem itp.. Opis osoby (struktura danych) nie zmienia się mimo zmiany jej roli. W rejestrze obywateli data, jako pole (powyżej), nawet taka sama, może tu występować wielokrotnie (tego samego dnia może się wydarzyć niezależnie wiele różnych rzeczy). Jednak ta sama data, jako wartość w rejestrze będącym kalendarzem, musi być unikalna: tu występuje tylko jeden raz. Czyli kalendarz i rejestr np. aktów urodzenia nie może być “jedna bazą”.
Jak widać powyższej, to dokument i struktura dokumentu, nadaje kontekst danym przechowywanym w polach (dokument, jego sekcja). Takiej struktury, naturalnej z perspektywy językowej i biznesowej, nie da się mapować na, pozbawiony redundancji, model relacyjnej bazy danych. Zapisanie tego dokumentu w modelu relacyjnym typowego ERP wymaga stworzenia dodatkowych tablic, a odtworzenie z nich dokumentu wymaga skomplikowanego zapytania SQL do tej bazy (nie w niej dokumentów a jedynie dane). W bazach relacyjnych NIE MA żadnych dokumentów, są wyciągnięte z nich, i pozbawione kontekstu, dane. Ich zapis i pobranie wymaga skomplikowanych (czytaj kosztownych w utworzeniu i konserwacji) zapytań SQL.
Powyższy dokument, bez żadnego problemu: bez utraty kontekstu i bez mnożenia typów dat, zapiszemy jako kompletny formularz, np. w formacie XML w dokumentowej bazie danych .
Wspólna baza danych jest z zasady jednokontekstowa, więc pewnych informacji, jako niezależnych informacji, po prostu nie da się tak przetwarzać. To dlatego praktycznie nie jest możliwe zbudowanie jednego uniwersalnego systemu ERP z jedną centralną relacyjną bazą danych, ale możliwe jest łatwe zbudowanie dowolnego systemu w postaci kilku zintegrowanych, dziedzinowych komponentów. Problem ten opisał i wyjaśnił w 2014 roku M.Fowler:
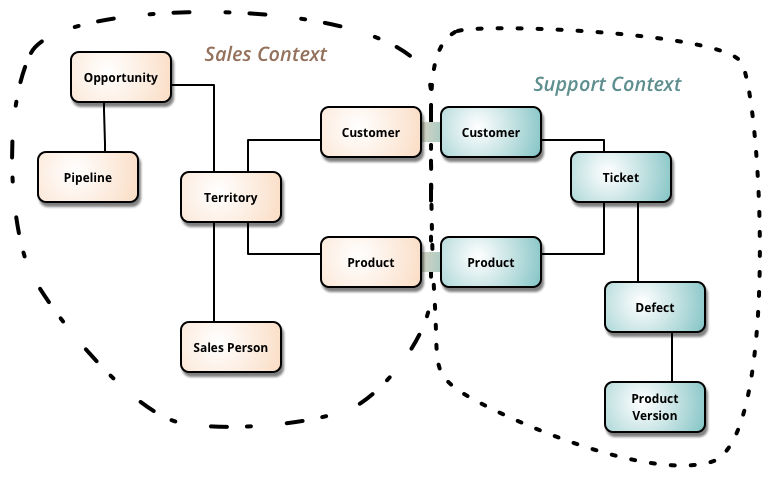
“Sales Context” oraz “Support Context” to dwa różne konteksty przetwarzania tych samych danych: Customer i Product w kontekście systemu sprzedaży (np. CRM) to unikalne, często aktualizowane, zapisy w bazie tego komponentu. Jednak w kontekście zgłoszeń serwisowych są to wyłącznie atrybuty Zgłoszeń serwisowych, jako fakty historyczne, są niezmienialne w przyszłości. Zbudowanie takiego systemu w postaci dwóch odrębnych i zintegrowanych komponentów będzie proste. Zbudowanie go w oparciu o jedną współdzieloną, relacyjną bazę danych, będzie bardzo kosztownym wyzwaniem, a w przyszłości nie będziemy mogli tych obszarów oddzielić od siebie, np. gdy firma podzieli sie na dwie specjalizowane spółki (co jest dość często obecnie).
Bardzo duża wadą systemów transakcyjnych, budowanych na jednej centralnej bazie relacyjnej, jest ich malejąca wydajność ze wzrostem liczby użytkowników i ilości zapisanych danych. Wady tej nie mają systemy komponentowe i systemu budowane na dokumentowych bazach danych typu NoSQL (patrz dlaczego).
Referencyjny model procesów biznesowych
Czasy monolitów się skończyły, i nawet jeżeli planowane jest wdrożenie “jednego ERP”, już nigdy nie będzie to jedyna aplikacja w firmie. Coraz częściej zakres wdrożenia monolitycznego systemu ERP ogranicza się do obszaru nazywanego “back-office” czyli do księgowości i administracji (procesów wspierających). W 1985 roku M.E.Porter (rok 1985 to pierwsze wydanie Strategii Konkurencji ) opisał tak zwany wewnętrzny łańcuch wartości firmy. Graficznie zobrazował go tak:
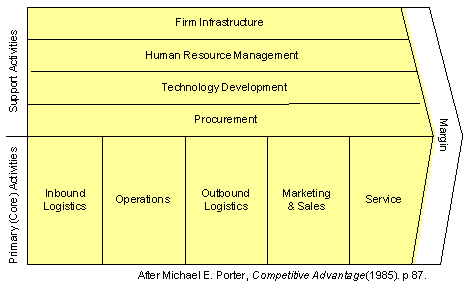
Powyższy diagram nadal stanowi klasykę procesowego podejścia do zarządzania i struktury grupowania procesów biznesowych (patrz Cambridge). Jest to standardowy, bazowy szkielet modelowania procesów biznesowych wewnątrz organizacji (starting point). Procesy biznesowe (czyli także aktywności jako ich wewnętrzna część) zostały tu podzielone na dwie podstawowe grupy: wspierające (suport activities) i operacyjne (primary activities, core).
Pomiędzy grupą procesów wspierających i operacyjnych jest zasadnicza różnica: zmienność i zależność od prawa i standardów. Procesy wspierające są w znacznej mierze regulowane prawem, stanowią standardy zarządzania, normy proceduralne (normy ISO itp.). Ten obszar nie buduje przewagi rynkowej, tu marża powstaje jako wewnętrzna sprawność (obniżanie kosztów).
Procesy operacyjne (core) to kluczowy łańcuch budowy marży. To tu powstaje przewaga rynkowa: jakość produktów i usług. To tu są wdrażane standardy branżowe. Tu jest właśnie dzisiejsza granica między ERP (procesy wspierające, zasoby), a aplikacjami dziedzinowymi (WMS, MES, APS, WorkFlow, e-Commerce i wiele innych). Próba uczynienia z nich wszystkich modułów jednego systemu, współdzielącego dane w jednej bazie danych, jest praktycznie awykonalna (patrz powyższe M.Fowler). Tym bardziej, że częstotliwość zmian w każdym obszarze jest inna, a dziedzinowe systemy np. wspomagania produkcji to zupełnie inny obszar specjalizacji niż np. księgowość czy kadry (to dlatego zupełnie inne firmy specjalizując się w dostarczaniu oprogramowania dla tych dziedzin).
Właśnie głównym powodem tego podziału, i tego że linia tego podziału jest między administracją a działalnością operacyjną, jest zmienność. Gdyby porównać między sobą firmy z różnych branż, to okaże się, że obszar procesów wspierających to stabilny obszar administracji, gdzie rotacja kadr jest mała, a ewentualna zmiana miejsca pracy nie zależy od branży i nie wymaga przekwalifikowania.
Obszar operacyjny to dedykowane dziedzinowe działania, nacechowane specyfiką konkretnej branży i specjalistami “z dziedziny…”. To dlatego na rynku jest tak wiele dziedzinowych aplikacji, które powstały do zarządzania specyfiką określonych działań w określonej branży. Nie przypadkiem nazywamy te aplikacje “systemami branżowymi”.
Firma produkcyjna to z reguły najbardziej skomplikowany mechanizm, system ERP stanowi tu jedynie czubek całego systemu:
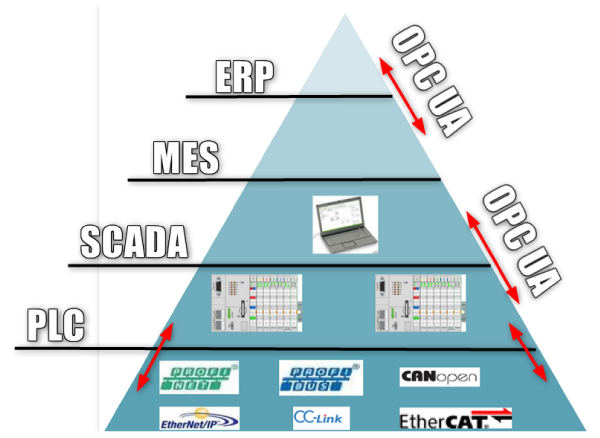
W efekcie, dzisiejsza sprawna firma (organizacja) będzie miała “standardowy ERP” wdrożony w obszarze procesów wspierających, oraz – zintegrowany z nim – zestaw dedykowanych, branżowych aplikacji.
Integracja jako wymaganie
Ta część jest adresowana do każdego kto modeluje integracje systemów IT (lub chce się tego nauczyć).
W 2014 artykuł o integracji kończyłem słowami:
Dedykowane dziedzinowe aplikacje coraz częściej są wdrażane etapami zamiast jednego dużego ERP. Taka integracja nie jest wbrew pozorom kosztowna, kosztowny jest brak stosowania dobrych praktyk i wzorców, które warto poznać. Zwinność działania dzisiejszych firm na rynku to wymóg a nie opcja. Zwinność taka to nie jeden duży ERP (monopol jednego usługodawcy), to kilka zintegrowanych, dedykowanych niezależnych aplikacji , wdrażanych bez kastomizacji (wybieramy najlepszy produkt w danym momencie). Ich (aplikacje dziedzinowe) wymiana na inne, przy dobrze wykonanej integracji, to jest proces, który nie generuje monstrualnych kosztów każdorazowej analizy i przeróbki całości IT (kolejnej kastomizacji jednego ERP) w firmie.
(źr.: Wymagania pozafunkcjonalne – integracja – Jarosław Żeliński IT-Consulting)
Modelowanie integracji opisywałem nie raz (patrz wyżej cytowany artykuł): należy udokumentować architekturę (komponenty i ich powiązania), dokumenty operacyjne (jako agregaty danych), oraz scenariusze opisujące metody osiągania oczekiwanego efektu. Scenariusze dokumentujemy diagramami sekwencji, a zalecane parametry wywołań to właśnie ww. agregaty reprezentujące dokumenty (implementowane jako JSON lub XML). Taka postać modeli jest doskonała do testów integralności, jednak bardzo często pojawia się potrzeba przekazania w specyfikacji wymagań jednego określnego API, jako wydzielonej perspektywy, i tu przychodzi z pomocą możliwość stworzenia dedykowanego diagramu klas, którego celem jest udokumentowanie wyłącznie określonego API (np. wymaganego lub ustalonego w toku wdrożenia).
Trochę technologii czyli REST API
“Przenoszenie Reprezentacji Stanu” (ang. Representational state transfer: REST) jest metodą komunikacji, która definiuje zestaw wymagań przy tworzeniu usług sieciowych. Usługi sieciowe, które są zgodne z REST, zwane także usługami sieciowymi RESTful Web Services (RWS), zapewniają interoperacyjność między systemami komputerowymi, tak sieci Internet jak i wewnątrz sieci jednej organizacji. Usługi RWS umożliwiają systemom (integrowanym aplikacjom) wzajemny dostęp do danych w formie tekstowej i manipulację nimi, za pomocą jednolitego i predefiniowanego zestawu bezstanowych operacji. Całość nazywamy stylem budowy architektury, jest on w pełni zgodny z obiektowym i komponentowym, zorientowanym na interfejsy, podejściem do projektowania systemów, a kluczową zasadą jest tu hermetyzacja i wąska odpowiedzialność komponentów. Podstawowe wzorce architektoniczne wykorzystywane przy projektowaniu integracji to Saga, Łańcuch odpowiedzialności i Repozytorium.
Dzięki bezstanowemu protokołowi i standardowym operacjom, systemy budowane w oparciu o RWS uzyskują dużą wydajność, niezawodność i możliwość rozwoju poprzez ponowne wykorzystanie komponentów (hermetyzacja), które mogą być zarządzane i aktualizowane bez wpływu na system jako całość, nawet podczas jego działania.
Ograniczenia architektoniczne czyli wymagania wobec architektury
REST definiuje 6 wymagań (to jego główne cechy) architektonicznych.
1. Architektura usługobiorca-usługodawca
Zasadą stojącą za ograniczeniami usługobiorca-usługodawca (inne spotykane nazwy to: klient usługi i usługodawca, klient-serwer, client – service provider), jest separacja kontekstów. Oddzielenie zadań związanych z interfejsem użytkownika od zadań związanych z logiką biznesową i przechowywaniem danych poprawia przenośność interfejsów użytkownika na wielu platformach. Poprawia to również skalowalność poprzez uproszczenie komponentów (kilka prostych zamiast jednego złożonego). Być może najbardziej znaczące dla sieci Internet (i dla sieci w ogóle) jest jednak to, że separacja ta (hermetyzacja) pozwala komponentom rozwijać się niezależnie, bez wpływu na pozostałe, pozwalając w ten sposób na istnienie różnorodności tak w sieci Internet, jak i w sieci lokalnej organizacji, pozwala na współistnienie wielu różnych i niezależnych domen i zasobów. Hermetyzacja to także niezależność od typów danych: przekazywane dane to wyłącznie ciągi znaków (string), ich typy muszą być uzgodnione po obu stronach (JSON) lub zdefiniowane (XSD/XML) i mogą być inaczej zdefiniowane w każdym z podsystemów (np. w jednym systemie będzie to np. typ “date” w bazie relacyjnej, a w innym ciąg znaków i maska walidacji).
2. Bezstanowość
Komunikacja usługobiorca-usługodawca jest ograniczona tym, że żaden kontekst usługobiorcy nie jest przechowywany u usługodawcy pomiędzy żądaniami. Każde żądanie od dowolnego usługobiorcy zawiera wszystkie informacje niezbędne do obsłużenia żądania. Stan sesji jest przechowywany zawsze po stronie usługobiorcy (patrz wzorzec projektowy Saga). Stan sesji może być przekazany przez usługodawcę do innej usługi, takiej jak baza danych, aby utrzymać trwały stan przez pewien czas i umożliwić uwierzytelnienie, ale wtedy stanowi on (stan jako nazwa) takie same dane jak pozostałe przekazane. Usługobiorca zaczyna wysyłać żądania, gdy jest gotowy do przejścia do kolejnego kroku (nowego stanu). Reprezentacja każdego stanu aplikacji zawiera odnośniki, które mogą być użyte następnym razem, gdy klient zdecyduje się zainicjować przejście do takiego stanu.
Kluczową cechą tej architektury jest także to, że usługodawca (serwer) nigdy sam nie wywołuje usługobiorcy (klient)!
3. Zdolność buforowania (cache)
Podobnie jak w sieci WWW, usługobiorca i pośrednicy mogą buforować odpowiedzi. Odpowiedzi muszą zatem, w sposób ukryty lub jawny, określać się (być oznaczone) jako buforowalne lub nie, aby zapobiec otrzymywaniu przez usługobiorcę nieaktualnych lub niepoprawnych danych w odpowiedzi na kolejne żądania. Dobrze zarządzane buforowanie częściowo lub całkowicie eliminuje niektóre interakcje usługobiorca-usługodawca, dodatkowo poprawiając skalowalność i wydajność.
4. Warstwy pośrednie
Usługobiorca zazwyczaj nie może stwierdzić, czy jest połączony bezpośrednio z serwerem końcowym, czy z pośrednikiem po drodze. Oznacza to, że usługobiorca nie wie, czy rozmawia z pośrednikiem (system pośredniczący, np. proxy), czy z właściwym usługodawcą (patrz wzorzec architektoniczny Łańcuch odpowiedzialności). Jeśli więc pomiędzy usługobiorcą a usługodawcą zostanie umieszczone proxy lub load balancer, nie będzie to miało wpływu na komunikację i nie będzie konieczności aktualizowania kodu usługobiorcy lub usługodawcy. Serwery (usługi) pośredniczące mogą poprawić skalowalność systemu poprzez umożliwienie równoważenia obciążenia i zapewnienie współdzielonych pamięci podręcznych. Ponadto, bezpieczeństwo może być dodane jako dodatkowa warstwa pośrednia dla usług sieciowych, by wyraźnie oddzielić logikę biznesową od logiki (reguł) bezpieczeństwa. Np. wydzielenie warstwy kontroli dostępu do danych, wymusza np. wdrażanie polityki bezpieczeństwa (patrz wzorzec architektoniczny Repozytorium). Wreszcie, oznacza to również, że usługodawca (serwer) także może wywoływać wiele innych serwerów w celu wygenerowania odpowiedzi dla usługobiorcy (klienta).
5. Kod na żądanie (opcjonalnie)
Serwery usługodawcy mogą tymczasowo rozszerzać lub dostosowywać funkcjonalność usługobiorcy (klienta), przesyłając mu zwrotnie kod wykonywalny: na przykład skompilowane komponenty, takie jak aplety Java, lub skrypty po stronie przeglądarki WWW, takie jak JavaScript (to dotyczy aplikacji internetowych działających w przeglądarce WWW, a nie integracji systemów, przykład w dalszej części).
6. Jednolity interfejs
Jednolity interfejs definiuje komunikację pomiędzy usługobiorcą i usługodawcą. Gdy programista zapozna się z jednym ze zdefiniowanych interfejsów API, powinien być w stanie zastosować podobne podejście do innych interfejsów API, które musi wykonać.
Polecenia HTTP REST
W REST informacje po stronie serwera są traktowane jako zasób, do którego mozna uzyskać dostęp w jednolity sposób za pomocą URI (Uniform Resource Identifiers) i protokołu HTTP. Metody GET, POST, PUT i DELETE są standardowo używane w architekturze integracji opartej na REST. Poniższy schemat zawiera objaśnienie tych metod:
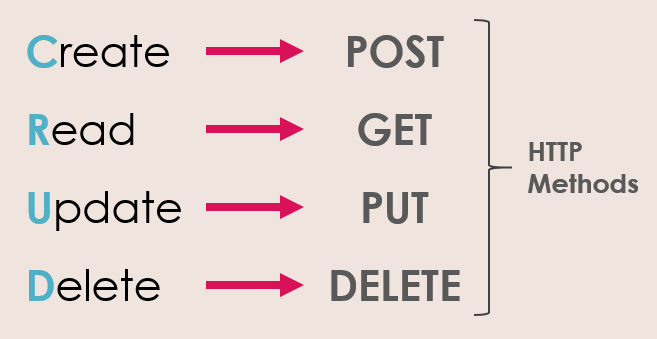
Warto wiedzieć, że zamiast PUT można użyć PATCH, jest to uproszczenie aktualizujące wyłącznie zmienione atrybuty obiektu, więcej tu: REST API ? POST vs PUT vs PATCH.
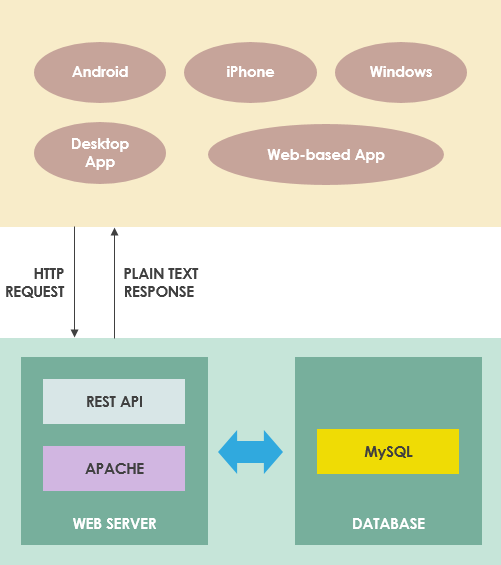
Jak to działa w sieci?
REST pozwala także na obsługę żądania dostępu do zasobów internetowych i manipulowania nimi przy użyciu jednolitego i predefiniowanego zestawu reguł. Interakcja w systemach internetowych opartych na REST odbywa się poprzez internetowy protokół HTTP (Hypertext Transfer Protocol). Na system Restful składają się:
- Żądający zasobów (obsługi) klient (usługobiorca).
- Posiadający te zasoby i udostępniający je serwer.
Np.:
Modelowanie REST API
Standardowa konstrukcja UML
W UML interfejs to na diagramie klas UML klasa oznaczona stereotypem ‘interfejs’, operacje tej klasy to operacje tego interfejsu. Na diagramie komponentów klasa interfejsu jest reprezentowana tylko jako nazwa i zobrazowana symbolem zwanym “lizak” i “kieliszek”, pokazano to poniżej:
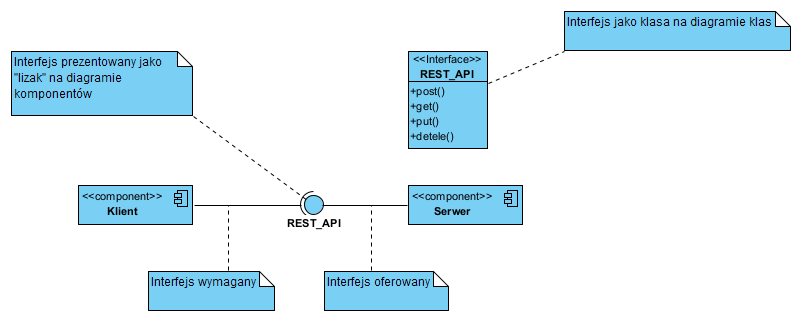
Na powyższym diagramie pokazano dwa komponenty: Klient (żąda usług) i Serwer (świadczy usługi). Przepływ danych może być w dwie strony: polecenie get do Klienta oraz polecenia create i update do serwera, jednak inicjowane są one z zasady przez komponent Klient (usługobiorca wywołuje operacje usługodawcy). Konstrukcja z lizakiem jest stosowana na Diagramie Komponentów. Na diagramie klas interfejs REST_API pokaże się (zostanie zobrazowany) jako klasa o stereotypie ‘interface’.
W repozytorium modelu “lizak” REST-API oraz klasa REST_API to ten sam element. W rzeczywistości są to np. trzy diagramy:
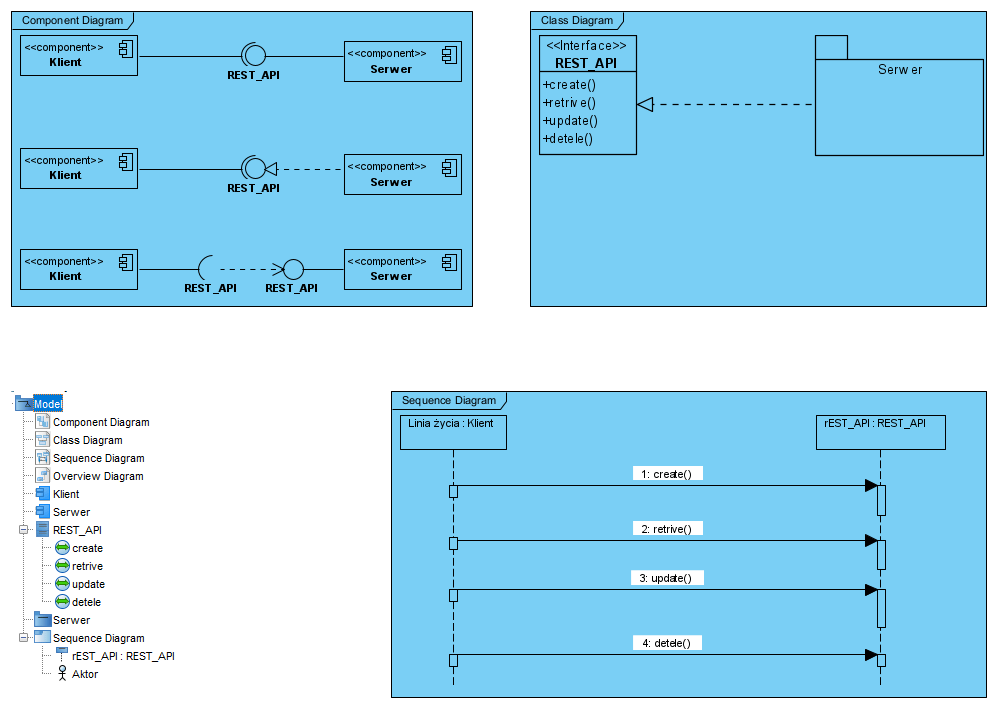
Diagram interakcji UML pokazuje wywołania operacji interfejsu REST_API (przypominam, że linie życia na diagramie interakcji reprezentują obiekty klas a nie klasy).
Aby opisać porty stosujemy Diagram Struktur Złożonych UML (Composite Structure Diagram), komponent/klasyfikator z portami WE i WY:
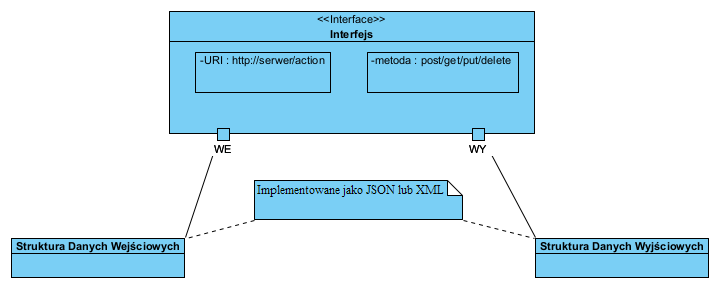
Modelowanie REST API z pomocą Visual Paradigm
Niektóre narzędzia CASE pozwalają na wykonanie dedykowanej dokumentacji API, w sposób pozwalający także, w razie takiej potrzeby, na wygenerowanie szkieletu kodu i jego dokumentacji.
Producent narzędzia CASE Visual Paradigm dostarcza powyższą konstrukcję jako predefiniowaną klasę: dodatkowy stereotyp “zasób REST”, nadając mu dedykowany symbol (profil REST). Tak to opisuje producent na swojej stronie:
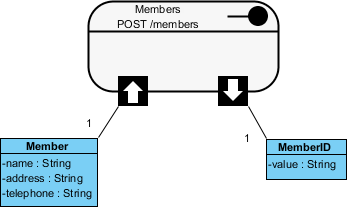
Wywołanie API jest podstawowym elementem usługi sieciowej, i powinno być zgodne z REST. Jest to obiekt zawierający URI, metodę żądania http, powiązane parametry oraz specyfikację żądania/odpowiedzi. Każdy z zasobów REST reprezentuje konkretną usługę dostępną na ścieżce określonej przez jego właściwość URI. Dlatego, jeśli chcesz modelować wiele usług, należy narysować wiele zasobów REST. (źr.:: How to design REST API – Visual Paradigm)
Z perspektywy modelowania jest to nadal standardowy diagram klas UML, jedynym dodatkiem jest specjalizowany symbol stanowiący abstrakcję interfejsu oferowanego. Wymienjony “zasób REST” to właśnie opisana abstrakcyjna klasa, zobrazowana jak na rysunku powyżej. Poniżej przykładowy efekt czyli dokumentacja API z użyciem powyższej metody:

Np. Bardzo prosta komunikacja (interfejs oferowany przez ERP, lub interfejs wymagany):
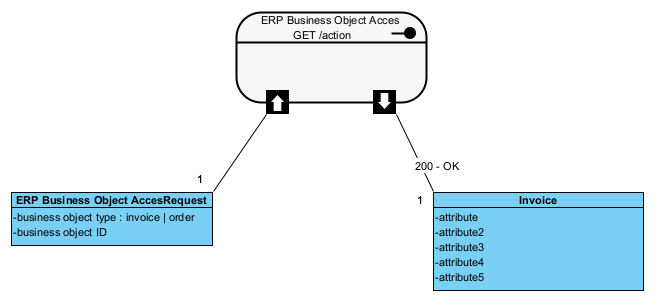
Na powyższym diagramie po lewej mamy prosty klasyfkator pokazujący, że możliwe jest żądanie Faktury lub Zamówienia na podstawie typu i numeru ID dokumentu. Po prawej stronie (uproszczenie) zwrócona, jako wynika żądania, faktura. Jeżeli nasz projekt zawiera detaliczną specyfikację faktury jako agregatu, odpowiedzią byłby ten właśnie agregat, np. agregat w postaci XML znany z dokumentacji JPK lub faktury ustrukturyzowanej (patrz także: Dokument jako wymaganie).
Bardzo ważna uwaga praktyczna: projektowanie integracji, jako wymiany danych, należy realizować w oparciu o kompletne dokumenty (zestawy danych): na API żądamy “Faktury VAT” i po jej otrzymaniu “u siebie” wyciągamy z niej np. “Wartość brutto”. Nie tworzymy (nie żądamy od serwera) API i usługi “Podaj wartość brutto Faktury VAT()” bo to: drastycznie uzależnia od siebie komunikujące się aplikacje, ogromnie podnosi koszty implementacji i testowania, wymaga powtarzania całej tej pracy po każdej zmianie lub aktualizacij serwera, wymaga dedykowanych operacji dla każdej zintegrowanej aplikacji u kontrahenta .
Integracja, szczególnie aplikacji pochodzących od różnych producentów, bardzo często wymaga mapowania danych (tłumaczenie). Wtedy najefektywniejsze jest budowanie adapterów integracyjnych, co chroni nas przez bardzo kosztownym modyfikowaniem (kastomizacji) systemów integrowanych:
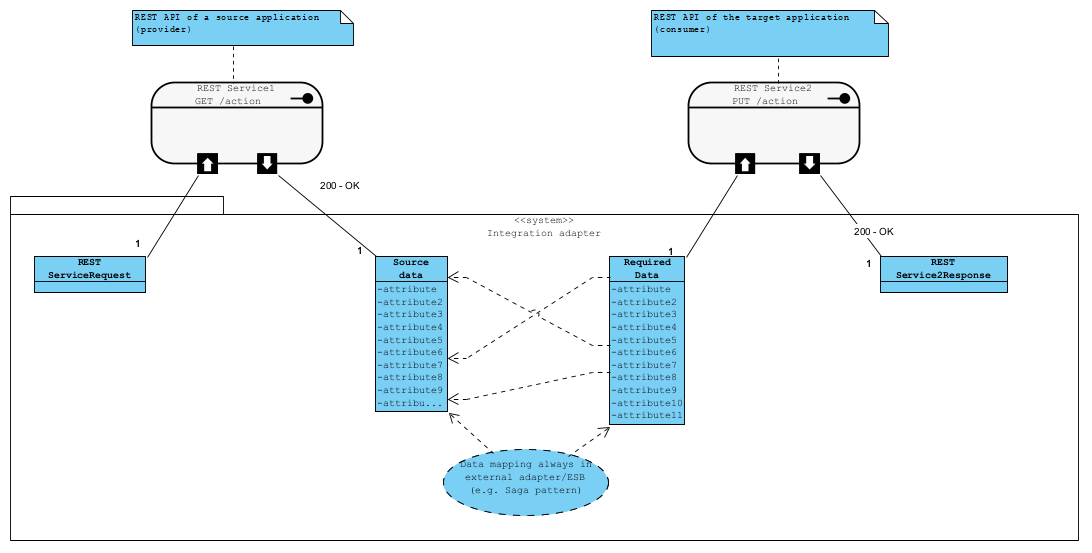
W mniejszych wdrożeniach budujemy je jako proste dedykowane aplikacje, większe wdrożenia mogą wymagać szyny integracyjnej (ang. ESB, Enterprise Service Bus)
Modelowanie interakcji
Powyższe statyczne modele architektury pokazujemy także z perspektywy interakcji użytkownika z systemem, między systemami i między komponentami systemu.
Podsumowanie
Tak więc pogodzenie się z integracją jako wymaganiem jest nieuniknione. Podobnie jak pogodzenie się z tym, że czasy jednej centralnej aplikacji w firmie i centralnej bazy danych, też odeszły do lamusa. Mamy ogólnoświatową sieć Internet, aplikacje lokalne i w chmurze, aplikacje naszych kontrahentów i aplikacje centralnych urzędów. Wszystkie on współpracują, wymieniają dane. To dlatego integracja stała się jednym z obligatoryjnych wymagań każdego systemu informatycznego.
A po co ta dokumentacja? Pełni identyczną rolę jak dobrze zaplanowana trasa podróży: wszystko to co można sprawdzić na mapie przed podróżą pozwoli uniknąć kosztownych niespodzianek w jej trakcie. To znaczy także, że można przekazać to jako wymaganie.
Poniżej prezentacja pokazująca zalety podejścia Design First, czyli najpierw projektujemy integracje a potem dopiero piszemy kod i implementację.
Dwa słowa porównania: monolit vs. pakiet aplikacji dziedzinowych
Wiele razy słyszałem o wadach systemów “pointegrowanych”… No to porównajmy:
| Etap | System monolityczny | Zintegrowane aplikacje dziedzinowe |
|---|---|---|
| Zakup | jedna licencja na całość (monopol dostawcy; vendor lock-in) w jednej umowie, rozłożenie kosztów w czasie, to raty za jeden produkt, wdrożenie musi się zacząć od modułów finansowych, | dobieramy na rynku to co jest akurat potrzebne, możliwe rozłożenie w czasie kosztów i wdrożenia, dowolna kolejność wdrażania modułów, brak monopolu jednego dostawcy |
| Wdrożenie | zawsze całość z uwagi na jedną współdzieloną bazę danych, system albo jest wdrożony w całości albo nie działa poprawnie, każde dostosowanie to ingerencja w całość (współdzielone dane) | nie ma przymusu wymiany już posiadanego systemu FK, zamiast kastomizacji, dobierane są najbardziej pasujące komponenty na rynku, zmiana strategii wdrożenia możliwa na każdym etapie |
| Utrzymanie i rozwój | każda zmiana to zawsze ingerencja w cały system, co generuje duże koszty i czas przy każdej modyfikacji, upgrade oznacza praktycznie powtórzenie czasu i kosztu wdrożenia, a często także i migrację danych | ingerujemy wyłącznie w jeden z kilku elementów systemu, taka zmiana nie przenosi się na inne aplikacje i obszary działania firmy, zmiana strategii firmy może wymagać wymiany komponentu ale nigdy ingerencji w cały system |
| Ryzyko | nieudane wdrożenie dotyczy z zasady całości systemu czyli całej firmy, przyszłe ewentualne wydzielenie spółki zależnej wraz z częścią systemu IT nie jest możliwe | nieudane wdrożenie dotyczy wyłącznie jednego modułu, czyli jednego obszaru firmy, przyszłe ewentualne wydzielenie spółki zależnej wraz z częścią systemu IT nie stanowi problemu |
| Podsumowanie | Mało elastyczny, ryzykowny, bardzo kosztowny cykl życia, nie wymaga projektowania. | Bardzo elastyczny, znacznie tańszy w utrzymaniu i rozwoju, wymaga dużych wiedzy i doświadczenia od projektanta. |
I uwaga: żaden monolityczny system ERP i tak nie obejmie całości przedsiębiorstwa, elektroniczna wymiana danych z kontrahentami i instytucjami państwowymi jest obecnie wymagana, więc integracja jest i tak nieunikniona.
Robot i Saga czyli jak integrować
Załóżmy, że mamy sytuację jak poniżej:
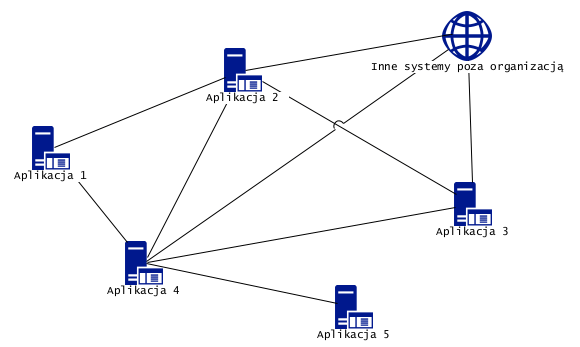
Szkic pokazuje hipotetyczne pięć aplikacji i wymianę danych (linie) między nimi oraz z otoczeniem (wszystkie organizacje teraz wymieniają dane z otoczeniem, w tym z Urzędem Skarbowym).
Standardowe aplikacje oferują API jako Interfejs Oferowany (lista usług, które można wywołać), czyli można od nich czegoś żądać. Problem w tym, że ktoś musi to żądanie wysłać. Czy żądanie może wysłać sama z siebie inna aplikacja? Owszem, pod warunkiem że ma taką możliwość (a ma rzadko), lub że dodamy jej (kastomizacja) taką możliwość. Robi się to na poziomie kodu (kastomizacja) lub na poziomie bazy danych (tak zwane trygery). W efekcie powstaje, pokazana poniżej, struktura wzajemnych wywołań, których nic nie koordynuje (każda aplikacja sama, w sobie znanym momencie, inicjuje żądanie wobec innej).
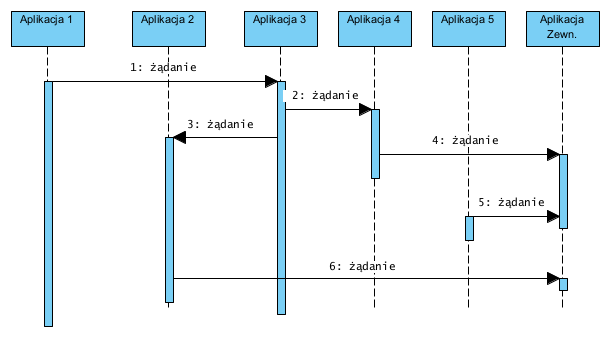
Efekt jaki powstaje to: tak zwany hazard, polegający na tym, że nic nie panuje nad kolejnością tych wywołań. Taki hazard powoduje błędy lub zawieszenia się komunikacji. Próby walki z nim polegają na sztucznym wstawianiu czasu oczekiwania, lub wymuszaniu określonego terminu wywołania. Koszty integracji to koszt tych prac kastomizacyjnych razy liczba aplikacji wymagających tej kastomizacji, całość jest czuła na każdą zmianę takiej sieci bo np. modyfikacja lub wymiana jednej z aplikacji, potencjalnie wymaga reorganizacji całej komunikacji. To tylko część problemów, gdyż bardzo często integracje nadal są realizowane metodą bezpośredniego dostępu do danych (i wtedy faktycznie są bardzo kosztowne) jak pokazano poniżej:
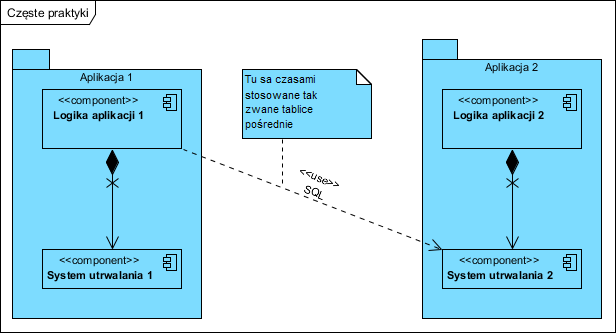
Szkodliwość podejścia pokazanego powyżej jest podwójna: pomijamy logikę biznesową w oprogramowaniu Aplikacja2, kastomizujemy oprogramowanie Aplikacja1. Kastomizacja to duży dodatkowy koszt, ryzyko destabilizacji obu aplikacji (bardzo często się to zdarza) i bardzo często powtarzanie tych prac jest konieczne po każdym upgrade (więcej w artykule Wymagania pozafunkcjonalne ? integracja). Taka integracja i jej wady są często używanym argumentem dostawców monolitycznych systemów ERP, jednak teza, że integracja polega na współdzieleniu danych to właśnie demagogia tych dostawców.
Popatrzmy teraz na poniższy szkic:
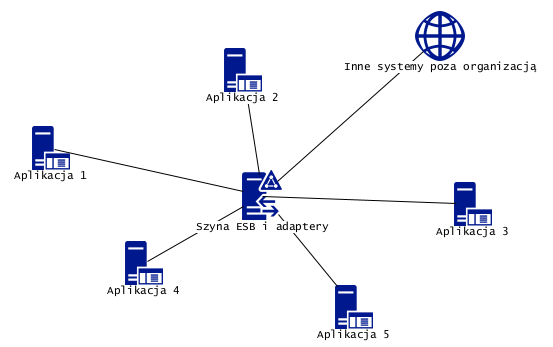
Korzyści: nie musimy kastomizować aplikacji bo np. ESB ma wbudowany mechanizm projektowania wywołań API, ESB izoluje od siebie serwery aplikacji: są one hermetyzowane za pomocą adapterów (budujemy je np. używają ESB lub jako samodzielne elementy aplikacji), więc zmiana konfiguracji aplikacji, lub jej wymiana na inną, wymaga jedynie ingerencji w jej adapter. Zastępujemy całkowicie indywidualne integracje z aplikacjami kontrahentów jednym centralnym węzłem integracji (to także forma hermetyzacji lokalnej sieci). W efekcie poszczególne aplikacje nie wymagają żadnych prac kastomizacyjnych, nie dochodzi do opisanych destabilizacji i hazardu, każda wymiana danych jest bezpieczną transakcją kontrolowaną przez ESB zgodnie z wzorcem Saga . Poniżej przykład z użyciem ESB i wzorca Saga:
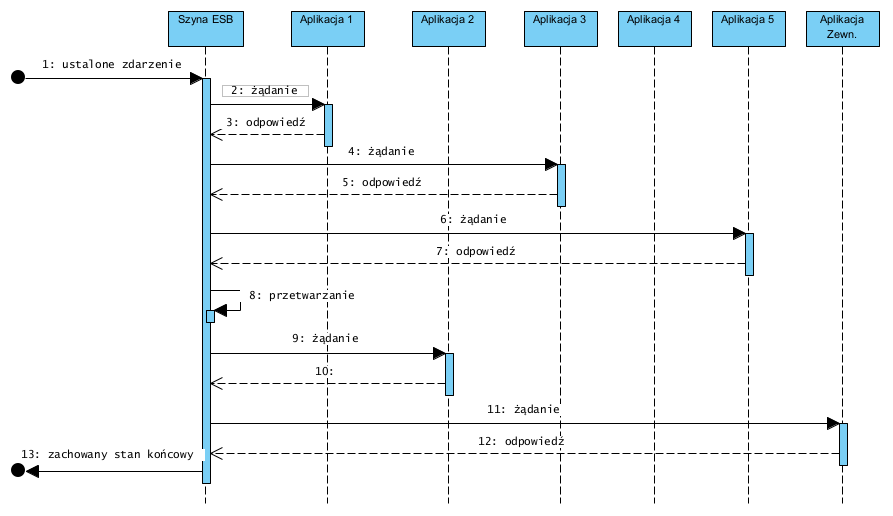
Wyżej opisane podejście ma także dodatkową ogromną zaletę: dostawcy poszczególnych aplikacji nie muszą ze sobą niczego uzgadniać ani negocjować, co bywa długie i bardzo kosztowne. Mogą być wybierani niezależnie od siebie, w różnym czasie, i nie zakłócają wzajemnie swoimi pracami wdrożeniowymi zachowania innych aplikacji. To efekt separacji aplikacji: żadna nie współdzieli danych bezpośrednio z inną, ma miejsce tylko wymiana danych na poziomie logiki tych aplikacji (polecam także ten artykuł: Przegląd wzorców integracyjnych)
Czy to niebezpieczne? Co będzie gdy uszkodzi się serwer ESB? Obecnie zabezpieczenie jego dostępności jest znacznie tańsze (redundancja) niż budowanie i utrzymanie wielu łączy integracji “każdy z każdym”. Warto też zwrócić uwagę na to, że może to być (ESB) usługa chmurowa, więc jej wysoka jakość i dostępność będzie często tańsza niż własny zasób.
Jak Budujemy logikę integracji? To opisałem w artykule Wzorce projektowe… integracje realizujemy na bazie wzorca SAGA , czyli budujemy skrypty realizujące wywołania (pobranie i wysłanie danych) w ustalonej kolejności i w ustalonym czasie.
A Roboty? Słynne i modne ostatnio Roboty to właśnie te skrypty realizujące scenariusze integracji na szynie ESB, znane od kilku dekad .

Nieco więcej o wzorcach integracji
Polecam także stronę autora: https://www.enterpriseintegrationpatterns.com/index.html




Na pewnym forum w mediach społecznościowych, padło pytanie o “robotyzację procesów” i o to co to za nowa technologia. Musiałem nieco rozczarować pytającego, bo odpisałem: nie jest to nic nowego poza nową nazwą. To co teraz modnie nazywamy robotami, to niewielki program (microservice) realizujący określony scenariusz zbudowany na bazie wzorca saga, integrujący aplikacje z użyciem REST API.
Interesujący opis projektowania REST API także tu: https://swagger.io/resources/articles/best-practices-in-api-design/
Ciekawy artykuł o wzorcu SAGA:
https://medium.com/javarevisited/what-is-saga-pattern-in-microservice-architecture-which-problem-does-it-solve-de45d7d01d2b
Przydatny artykuł o REST API
https://medium.com/@shubhadeepchat/best-practices-for-good-rest-api-design-b5fae9a62c86
The Crucial Role of Software Integration in Preventing ERP Failures:
https://www.panorama-consulting.com/the-crucial-role-of-software-integration-in-preventing-erp-failures/
Aktualizacja opis integracji i dodanie prezentacji YT.
Krótki zwięzły opis dla projektantów
https://medium.com/@bubu.tripathy/best-practices-for-designing-rest-apis-5b1809545e3c
Taka ciekawostka:
1. raport obejmuje 10 systemów ERP
2. systemy te powstały w: 1972, 1983, 2002, 1975, 1998, 1977, 1981, 1972, 2008, 1986.
Tylko dwa nazwał bym “nowoczesne”. Nie podaję nazw bo nie jest moim celem ich promowanie (raport jest do pobrania za darmo, tam są pełne informacje). Informacje w raporcie nie zawierają opisu architektury, jednak pewną wspólną cechą tych systemów jest to, że zawierają “zintegrowane najlepsze praktyki branżowe i procesy biznesowe” co znaczy tylko tyle, że ta logika jest wbudowana w model danych.
Firmy te często podkreślają, że idą z duchem czasu i są to zawsze “najnowsze technologie”, owszem, ale model danych i monolityczną architekturę mają z czasów gdy powstawały… Najnowsza technologia to taki trik marketingowy typu “a my mam blockchain”! Owszem, zamontowany do stodoły z przed połowy wieku.
Oldemeyer, J. (2023). Top 10 ERP Systems Report. Panorama Consulting Group.
Czy te systemy są złe? Nie, one są dedykowane do kontekstu, celu, branży dla jakiej pierwotnie powstały, ale są też ogromnie skomplikowane. To znaczy, że należy RYGORYSTYCZNIE przestrzegać metod ich wdrażania zalecanych przez ich producentów:
1. Analiza procesów biznesowych firmy (dodam, że koniecznie wraz z analizą ontologii i struktur dokumentów biznesowych!), oraz ich zmiana jeśli okaże się że podniesienie efektywności jest możliwe (a po wielu latach stagnacji firm, prawie zawsze można).
2. Analiza fit-gap systemu ERP i tych modeli.
3. Zakreślić zakres wdrożenia ERP: tylko to co pasuje w 100% i nic ponad to! Kastomizajca (ingerencja w kod i bazę danych) jest kluczowym powodem porażek ich wdrożeń.
4. Dla brakujących funkcjonalności poszukać na rynku dziedzinowych rozwiązań i zintegrować z ERP, lub zaprojektować i wykonać add-on (dedykowany i integrowany moduł w środowisku deweloperskim ERP).
Kto to powinien zrobić?
ad.1. to robimy przed wyborem systemu ERP
ad.2. to robi dostawca ERP na etapie składania oferty
ad.3. to robi dostawca ERP wybrany na bazie powyższego (najmniejsza luka fit-gap)
ad.4. projektantem całości powinna być zawsze osoba, która wykonała analize (pkt.1.) i ma kompetencje i doświadczenie do wykonania pkt. 4. oraz nadzoru nad całością, ta osoba powinna pracować po stronie Zamawiającego! Implementację robi dostawca ERP, ale prawa autorskie do add-on zostają przy Zamawiającym bo to jego know-how.
Potrzebujesz więcej informacji? Zapraszam.
Czy dokumentacja API wykonywana jest dla każdego “lizaka” na diagramie diagramu komponentów (architektura HLD) czy tylko w przypadku adaptera?
Chodzi mi o to czy jeśli mam diagram komponentów, który przedstawia portal dostępowy (orkiestrator), wyspecjalizowane komponenty oraz komponent adaptera, to interfejsy (“lizaki”) mamy między
– orkiestratorem a wyspecjalizowanymi komponentami
– orkiestratorem a adapterem
– adapterem a “światem”.
I pytanie jest czy dla każdego z tych związków robimy dokumentację API czy tylko dla ostatniego elementu?
Niestety API urosło do mitu, a jest to po prostu publiczny, oferowany interfejs komponentu/klasy. Tak więc API to nic innego jak przypadki użycia (każda operacja to osobny use case) tyle, że tu aktorem jest inna aplikacja a nie człowiek.
Adapter to prosty separujący komponent, którego logika sprowadza się mapowania jednego zestawu operacji na inny (ale może to wymagać także przekształceń po drodze). Na diagramie:
– lizak to co do zasady interfejs (zestaw operacji serwera, klasa), “kieliszek” to to samo ale z perspektywy klienta,
– każdą operację API dokumentujemy tak samo jak przypadek użycia: stan początkowy, końcowy, scenariusz i logikę jaka przekształca stan początkowy w końcowy.
Rzecz w tym że REST jest bezstanowy, więc w zasadzie operacje API to osobne kroki ewentualnego większego scenariusza (orkiestracja) i tu pomaga diagram sekwencji opisujący te orkiestrację. BTW: ja osobiście nie lubię słowa “orkiestracja” (kiepska kalka z angielskiego) wolę “scenariusz”, pojęcie z wzorca SAGA.
Co do scenariuszy:
– praca z GUI: tu pracą (scenariusz) kieruje człowiek, scenariusz pracy z aplikacją to jego wola/wybór,
– praca z API: tu scenariusz musi być gdzieś zapisany po stronie klienta, dlatego tworzymy szyny ERB, adaptery itp.. one realizują ten scenariusz.
Pojęcie “dokumentacja API” ma dwa konteksty:
– instrukcja użytkownika (to udostępniamy zawsze)
– model implementacji (to udostępniamy o ile nie jest tajemnicą przedsiębiorstwa)
“I pytanie jest czy dla każdego z tych związków robimy dokumentację API czy tylko dla ostatniego elementu?”
Dokumentuje wszystkie operacje 😉 na “lizakach” i scenariusze integracji (które są zarazem testami).
Gorąco polecam tu tę książkę:
https://it-consulting.pl/2022/07/11/interface-oriented-design/
“Dokumentuje wszystkie operacje ? na „lizakach” i scenariusze integracji (które są zarazem testami).”
Innymi słowy jeśli działamy zgodnie z wzorcem SAGA i mamy interfejsy między poszczególnymi komponentami, to tworząc dokumentację intefejsów (chodzi mi tutaj o ten diagram, który VP udostępnia z metodami POST/GET/itd), to dokumentujemy w kontekście scenariuszy jakie chcemy zrealizować?
Wzorzec SAGA zakłada, że nie ma żadnej bezpośredniej komunikacji między integrowanymi komponentami (lub aplikacjami). Wszystkim zarządza osobny “koordynator”. Na tym schemacie tym koordynatorem jest “gateway”. To ten koordynator ma “zapisane” i realizuje je, scenariusze przypadków użycia. Nie ma znaczenia czy ten schemat pokazuje wnętrze aplikacji, czy integracje różnych osobnych aplikacji, zasada jest taka sama.
Rodzi się jeszcze kolejne pytanie odnośnie mapowania danych i dokumentowania RESTa.
Mam system 1 i system 2.
System jeden swoją metodą get chce listę faktur od systemu 2.
Z perspektywy systemu 1 jest to request i response, a z perspektywy systemu 2? Niby wciąż request, ale jednak jakoś to trzeba pokazać. Nawet zakładając, że nie modelujemy całego Świata, a tylko to co jest nasze, to wciąż pozostaje to pytanie. To a propos modelowania API gdy to my pytamy. Co w przypadku gdy to my jesteśmy odpytywani? GET z naszej strony to POST z strony providera i vice versa?
“System jeden swoją metodą get chce listę faktur od systemu 2.”
Co to znaczy? System 1 to klient Systemu 2, System 1 nie ma “metody get”, on wywołuje ją na API serwera: Systemu 2.
Po drugie jest to raczej kiepski pomysł by dwa serwery nawiązywały dialog bo tu to wymaga ingerencji w kod System 1.
“System 1 to klient Systemu 2, System 1 nie ma „metody get”, on wywołuje ją na API serwera: Systemu 2. ”
Innymi słowy dokumentując API patrzymy z perspektywy providera?
Co jeśli to nasz system jest providerem?
Generalnie API to oferowany interfejs (zestaw operacji) i jest to cecha serwera (dostawca usługi, to jej provider).
Jeżeli mówimy o dokumentacji, to o jaką dokumentację chodzi:
– opis tego jakie usługi i jak realizują operacje dostępne na API danego serwera
– opis tego jak zintegrowano dwa systemu, czyli co się po kolei musi wydarzyć między nimi (scenariusz dialogu) bo osiągnąć określony efekt
bo to nie jest to samo:
– kierownica i pedały pod nogami kierowcy to API samochodu
– interakcje między kierowcą a samochodem, to scenariusz co kiedy nacisnąć, by dojechać samochodem do pracy
Po dalszą pomoc zapraszam tu: https://it-consulting.pl/seminaria/
“Generalnie API to oferowany interfejs (zestaw operacji) i jest to cecha serwera (dostawca usługi, to jej provider).”
Innymi słowy wyspecjalizowane komponenty aplikacji (faktury, klienci, itd) są providerami, a portal dostępowy jest klientem?
Ogólnie tak.
Zatem jeśli wyspecjalizowane komponenty aplikacji (faktury, klienci, itd) są providerami, a portal dostępowy jest klientem, to jeśli na diagramie architektury HLD mamy per komponent dodane interfejsy oferowane, a na diagramach architektury LLD (diagramy klas per komponent), które są wykonane zgodnie z wzorcem BCE + wzorzec łańcuch odpowiedzialności, to podpinając pod interfejs oferowany komponentu X na diagramie architektury HLD powinniśmy “podpiąć”
a. diagram reprezentujący dokumentację REST API, które to będzie wywoływało metody klasy o stereotypie boundary, który jest elementem architektury LLD komponentu X.
albo….
b. klasę o stereotypie boundary, który jest elementem architektury LLD komponentu X.
?
https://it-consulting.pl/seminaria/