Wprowadzenie
Tym razem artykuł na temat typów związków między elementami w modelach systemów. Modele tego typu to hierarchiczna struktura mająca kilka różnych perspektyw, poziomów abstrakcji i poziomów dekompozycji. Do tego dochodzą fizyczne i logiczne powiązania między elementami oraz fakt, że każdy system to określone “materialne” elementy ułożone w hierarchiczną strukturę. Każdy system składa się ze skończonej liczby elementów o skończonej liczbie typów.
Na to wszystko nakłada się struktura wymagań na system, oraz konieczność wykazania zgodności projektu systemu z tymi wymaganiami .
Bardzo często jestem pytany o to, jak organizować repozytorium projektu w narzędziu CASE. Jak modelować systemy i zarządzać tymi modelami, wiedząc, że fizyczna struktura może być tylko jedna? Ten tekst to uzupełnienie artykułu Modelowanie architektury HLD i LLD usług aplikacji ? modelowanie podsystemów.
UWGA! Nie należy mylić pojęć “relacja” i “związek”. Relacja to stały związek miedzy “czymś a czymś”, jest to pojęcie matematyczne, stosowane także w teorii relacyjnych baz danych (relacja to trwałem połączenie tabel). Związek (asocjacja) to pojęcie znaczeniowe z obszaru logiki i rachunku zdań. Fundamentem notacji UML jest pojęcie “klasyfikator” (definicja elementów zbioru zorientowana na cechy elementów) i “klasa” (nazwa tego zbioru) oraz instancja klasy (element, obiekt zbioru) (patrz UML 2.5.1. rozdz. 9 Classification ). Tak więc powiemy, że “pies korzysta z budy (po to by się schronić)”, zarówno “pies” jak i “buda” to klasy (ogólne nazwy). Słowo “korzysta z” to związek pojęciowy (asocjacja) tworzący poprawne i prawdziwe zdanie z tych dwóch pojęć (nazw) czyli predykat. Konkretne obiekty to “Azor” i “buda w zagrodzie Nowaków”. Ale nie powiemy tu, że jest jakaś “relacja” psa do budy lub odwrotnie. Zdanie “istnieje relacja między komponentem Licznik dokumentów a komponentem Repozytorium Dokumentów” jest niepoprawne, między innymi z tego powodu, że co do zasady elementy systemów są “luźno powiązane” a nie “trwale połączone” (komponenty można kupić osobno i w dowolnym momencie wymienić każdy z nich na inny). Tu kolejna uwaga: nie należy sankcjonować ograniczeń posiadanych narzędzi CASE, jeżeli jakieś narzędzie nie pozwala tworzyć poprawnych modeli, sugeruję zmienić narzędzie, naginanie zasad do ograniczeń narzędzia to ślepa uliczka, bo taki model staje się niewalidowalny i niemożliwy do wymiany z innymi narzędziami (a powinny).
Więcej o teorii systemów obiektowych, o pojęciach klasy, klasyfikatora i instancji klasy w tekście: Obiektowy model systemu.
Założenia
Czym jest struktura modelu systemu? Tak na prawdę mamy trzy odrębne struktury:
- struktura pojęć w modelu pojęciowym,
- struktura deklarowanych typów elementów,
- struktura systemu zbudowanego z konkretnych, nazwanych elementów ww. typów.
(Uwaga! Każdy z powyższych diagramów to diagram klas, więc zadanie: “narysuj diagram klas dla projektu” nie ma większego sensu).
Pierwsza struktura to słownik pojęć wraz ze związkami pojęciowymi (ten diagram klas, w notacji SBVR, nosi nazwę diagramem faktów). Kolejna struktura to deklaracja “typów klocków”, czyli typów elementów systemu (z nich budujemy architekturę). Trzecia struktura to dopiero opis konstrukcji zbudowanej z klocków określonego typu (architektura systemu). Widać to np. na przysłowiowych już meblach z IKEA: mamy spis elementów oraz rysunek złożeniowy. Na pierwszym są typy elementów (tu także ich ilości w paczkach), na drugim złożenie czyli konstrukcja (architektura konkretnej szafy). Domyślnym słownikiem jest ten w jakim napisano tę instrukcję, np. język polski.
Skoro zaś mowa o narzędziach CASE, to do zilustrowania omawianych związków użyjemy notacji UML. Notacja UML nie narzuca tu niczego, co często jest wskazywane jako jej wada (niewiele rzeczy można w UML walidować). Jednak już w profilu UML, jakim jest notacja SysML (System Modeling Language ), wyżej opisana “dyscyplina” modelowania jest narzucona. Omówię też przykłady dla notacji eEPC i BPMN. Warto pamiętać, że UML i BPMN to notacje, które łączy wspólny metamodel jakim jest MOF (Meta Object Facility).
Typy związków w UML
Taksonomia związków
W notacji UML, uznawanej obecnie za standard notacyjny w obszarze modelowania systemów, mamy trzy podstawowe typy związków: związki pojęciowe (predykaty czyli związki zdaniotwórcze), związki strukturalne oraz związki reprezentujące zależności między elementami modelu :

Repozytorium projektu systemu (jego struktura) odwzorowuje wyłącznie związki strukturalne. Pozostałe związki można zobrazować tylko na diagramach lub w postaci macierzy zależności (przypominam, że od roku 2015, czyli od wersji 2.5. notacji UML, nie mamy w UML związku dziedziczenia ani agregacji).
Dobrą praktyką jest tworzenie zawsze trzech podstawowych modeli: model pojęciowy, deklaracje typów oraz właściwy model systemu, który zbudowany jest z elementów określonego typu, a których nazwy są pobierane z modelu pojęciowego (ze słownika). W notacji SysML model systemu (Internal Block Diagram) jest modelem podległym modelu deklaracji typów (Block Definition Diagram) .

Z uwagi na odrębność modelu pojęciowego (słownika) i modelu struktury systemu (nadal jest bardzo wiele nieporozumień z określeniem tego co to jest model dziedziny w UML), słownik jako model pojęciowy i swoista konstrukcja, modelowany z użyciem diagramu klas, opisano osobno w specyfikacji notacji SBVR (Semantics of Business Vocabulary and Business Rules) .
Po lewej stronie pokazano widok diagramu (modelu) pojęciowego w repozytorium narzędzia CASE. Jak wspomniano związki inne niż strukturalne (a związek generalizacji nie jest związkiem strukturalnym a pojęciowym) można pokazać wyłącznie na diagramie lub w macierzy zależności, dlatego struktura pojęć w repozytorium jest płaska, ale diagram obrazujący taksonomię ma strukturę drzewa (patrz wyżej). Poniżej związki generalizacji pokazane w postaci macierzy:
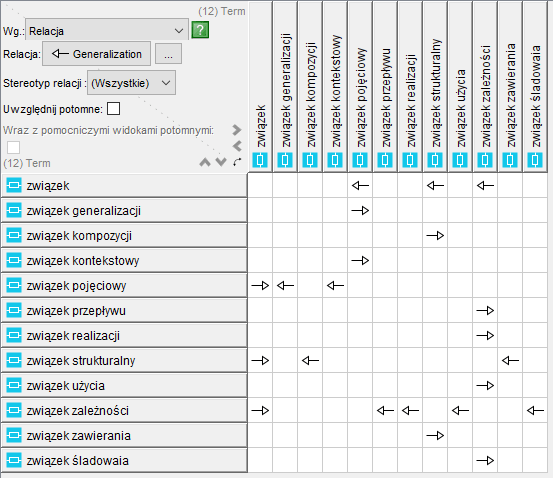
Jak widać w tym przypadku forma macierzy jest trudniejsza w percepcji, pokazanie drzewiastej struktury taksonomii na diagramie jest efektywniejsze.
Związki logiczne i zawieranie
Zupełnie inna sytuacja pojawia się gdy chcemy pokazać (zweryfikować ich spójność i kompletność) związki użycia (‘use’) czy śladowanie (‘trace’). Są to związki logiczne np. pomiędzy aktywnościami na modelach procesów biznesowych a przypadkami użycia (model przypadków użycia) lub związki pomiędzy wymaganiami na system a elementami systemu realizującymi te wymagania. Mogą to być związki jeden do jednego, jeden do wielu jak i wiele do wielu. Te związki efektywnie pokazujemy na macierzach jak wyżej.
Niektóre narzędzia CASE (np. Visual Paradigm) pozwalają łączyć logicznie dowolne elementy struktury modelu (np. śladowanie wymagań) związkami logicznymi, bez potrzeby ich odwzorowywania na diagramach, takie związki są budowane jako własność “referencji do” (jest to cecha elementu diagramu, a nie związek obrazowany na diagramie), a ich zilustrowanie i kontrolę w dowolnym momencie można sprawdzić generując macierz analogiczną do powyższej.
Na koniec omówimy związki kompozycji, złączenia (connection) i zawierania.


Prawdopodobnie część czytelników jest zaskoczona związkiem “złączenia”. Otóż linia ciągła w notacji UML -asocjacja – na modelu pojęciowym oznacza związek pojęciowy zwany predykatem. Jednak na modelu struktury systemu jest to opis (związek) “konstrukcji” (connection). Powyższe (diagram) czytamy:
- Klasa 2 jest częścią składową Klasy 1
- Klasa 3 i Klasa 4 są ze sobą (trwale) połączone
- Klasa 5 jest zawarta w Pakiecie (dwie równoprawne formy zobrazowania), mini-grafika po lewej to widok tego związku w repozytorium. Dlatego często pakiet jest nazywany jest kontenerem, gdyż sam z siebie nie służy do niczego poza grupowaniem (nie ma ani atrybutów ani operacji, ma jedynie nazwę i ewentualnie stereotyp, MOF 2.5.1. rozdz. 8.3 Using Packages to Partition and Extend Metamodels ) oraz UML v.2.5.1. rozdz. 12 Packages .
Np. opisując samochód powiemy, że silnik i koła są częścią samochodu, ale nie powiemy, że koła są częścią silnika ani, że silnik jest częścią kół, powiemy jednak, że “są one połączone ze sobą”:
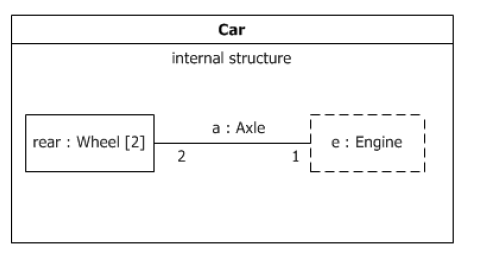
Jednak powiemy też, że silnik kręci kołami, bo “connector” też ma określony “kierunek działania” (jest to związek inwariantny).
I tu bardzo ważna rzecz: nie ma w UML związku “dekompozycji” ale w repozytorium jest to obrazowane tak samo jako zawieranie się. Przykład:

Powyższy diagram to diagram komponentów UML obrazujący komponent i jego interfejs oferowany (architektura HLD). Ten komponent został w detalach opisany jako dekompozycja (diagram klas):

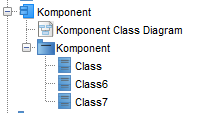
Powyższy diagram to diagram klas obrazujący architekturę LLD Komponentu. Dokonano tu także pewnego zabiegu porządkującego: elementy architektury Komponentu umieszczono w pakiecie o nazwie Komponent, pakiet ten jest produktem przekształcenia Komponentu w pakiet o nazwie Komponent (związek śladowania określany jako ‘transit to’). Po pierwsze porządkuje to widok w repozytorium, po drugie w repozytorium separuje od siebie elementy różnych komponentów (widok repozytorium rys. po prawej).
Innymi słowy, można powiedzieć, że dekompozycja oznacza, że nadrzędny (w modelu) element dekomponowany jest na elementy składowe, a te dla porządku umieszczamy w osobnym kontenerze.
Komponent jest tu szczytem swojej hierarchii, dekompozycja, czyli jego wewnętrzna architektura, została pokazana na diagramie “Komponent Class Diagram”, jest na nim pakiet Komponent (kontener) oraz zawarte w nim klasy reprezentujące wewnętrzne elementy jego architektury. Gdyby nie było pakietu (kontenera) Komponent, klasy będące elementem jego architektury “mieszałyby się” z klasami innych komponentów w repozytorium, co w dużych projektach utrudnia zarządzanie modelem i korzystaniem z niego.
Związki w modelach procesów
Związki logiczne (przepływy i asocjacje) opisałem w Notacja EPC i Notacja BPMN. Tym razem skupimy się wyłącznie na dekompozycji i grupowaniu.
eEPC
Notacja eECP nie operuje pojęciem kontenera co jest jej poważną wadą (nie ma narzędzia do grupowania elementów takich jak pule i tory) można jednak użyć dekompozycji. Dwa diagramy eEPC:

W repozytorium wygląda to tak:

BPMN
W specyfikacji BPMN zaś czytamy:

Tak więc pule i tory to kontenery służce do grupowania aktywności (przypominam, że związki logiczne i artefakty nie są partycjonowane).

Poniżej prosty model procesu:
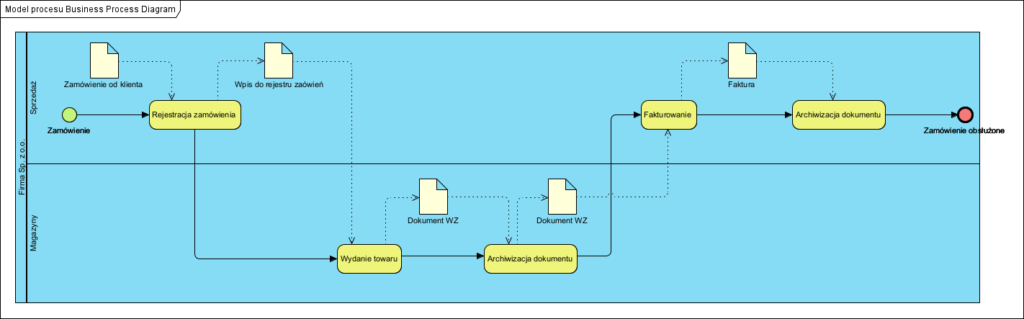
W repozytorium wygląda to tak:

Tu mała “ciekawostka” i od razu wyjaśnienie. Na początku napisano, że formalnie budujemy: strukturę typów elementów oraz strukturę systemu zbudowanego z konkretnych elementów ww. typów. Na powyższym diagramie czynność ‘Archiwizacja dokumentu’ pojawia się dwukrotnie: archiwizacji podlega i Faktura i Dokument WZ. Jest to więc taka sama procedura wykonywana w dwóch różnych działach. Oznacza to, że w repozytorium raz deklarujemy czynność ‘Archiwizacja dokumentu’ i możemy jej używać wielokrotnie, na różnych diagramach w różnych pulach i torach, gdy tylko prawdą jest, że pojawia się w jakimś procesie aktywność ‘Archiwizacja dokumentu’.
UWAGA! W rozbudowanych projektach warto najpierw deklarować aktywności (reprezentują one procedury) a potem dopiero używać ich na diagramach. Takie deklaracje (nowe elementy) można tworzyć bezpośrednio w repozytorium (jako np. bibliotekę) lub na specjalnie zadeklarowanym diagramie (podobnie DataObject jako dokumenty i ich bibliotekę). Poniżej przykład takiego podejścia:


W VP domyślnie, utworzenie nowego elementu np. tworząc diagram (ale można to zrobić bezpośrednio w repozytorium), stanowi jego deklarację w modelu (VP oznacza to znakiem “M” jako Master), każde kolejne użycie tego elementu to jego kolejne zobrazowanie (VP oznacza to znakiem “a” jako auxiliary). Identycznie wygląda to w każdym innym modelu (np. UML). Dlatego repozytorium modelu to właśnie deklaracje typów i ich hierarchia, diagramy to widoki i właściwe modele, budowane z elementów zadeklarowanych w repozytorium elementów modeli. Dekompozycja w BPMN będzie wyglądała analogicznie jak pokazana dla eEPC.
Podsumowanie
Korzystając z narzędzi CASE warto ich używać z pełnym zrozumieniem mechanizmu ich działania i zrozumieniem notacji jakiej się używa. Każde zaniedbanie, nieumiejętne lub wręcz niewłaściwe używanie związków na diagramach, prowadzi do chaosu i braku czytelności. Konsekwencją są niespójność i brak możliwości jej kontroli. Niestety niektóre narzędzia mają repozytoria zbudowane na relacyjnym modelu i nie pozwalają np. umieszczenie dwóch takich samych elementów na jednym diagramie. Moja sugestia: zmień narzędzie.
Warto wiedzieć, że opisane tu związki mają sens i nabierają znaczenia dopiero w określonym kontekście (obecnie diagramy w UML czy BPMN to kontekstowe widoki elementów hierarchii typów elementów). Do tego ten sam symbol może mieć inne znaczenie w innym kontekście, np. ciągła linia prosta jest związkiem pojęciowym na modelu pojęciowym (predykat: “pies” śpi w “budzie”), albo jest złączeniem (connector) na modelu struktury (koła samochodu są połączone z napędem).
Jeżeli jednak modelujemy architekturę oprogramowania zorientowaną obiektowo/komponentowo, gdzie komponenty nie są z sobą trwale połączone a jedynie wywołują się wzajemnie, to używanie złączenia (ciągła linia) na tych diagramach na nie ma żadnego sensu. Ma jednak sens zgrupowanie określonych elementów w pakiecie, dla pokazania granicy komponentów czy modułów, i ich zawartości w repozytorium.



Po kilku pytaniach, uzupełniłem artykuł o źródłowe informacje o pakietach, konteneryzacji i partycjonowaniu.
O związkach w UML wspominałem także tu: https://it-consulting.pl/2015/07/08/the-object-primer-3rd-ed-agile-model-driven-development-with-uml-2-i-moje-trzy-grosze-o-uml/