Wprowadzenie
Ontologia jako narzędzie tworzenia “modeli świata”, jest bardzo dobrym narzędziem do projektowania danych, zorganizowanych – w łatwe do zarządzania w bazach NoSQL – dokumenty. Niedawno napisałem:
Czy opracowanie ontologii jest łatwe? Nie, nie jest. Czy zła ontologia szkodzi? Tak, potrafi doprowadzić do fiaska projektu informatycznego.
źr.;: Ontologia czyli jak się to robi
Po co to wszystko? Obecnie często mówimy o Big Data, czyli o masowo gromadzonych danych. Ich gromadzenie wymaga opracowania struktury ich gromadzenia i zarządzania nimi, bez tego powstanie “stos nieskatalogowanych dokumentów”. Proces gromadzenia danych jest stratny, więc dane te można zgromadzić raz, przepisanie ich do nowej struktury jest możliwe tylko gdy nowa struktura jest prostsza (przepisywanie do identycznej nie ma sensu) więc każda migracja to utrata informacji. Innymi słowy: architekt danych, podobnie jak saper, myli się tylko raz.
Ontologia
Przypomnijmy definicję:
ontologia: lista pojęć i kategorii z jakiegoś obszaru tematycznego, która pokazuje związki między nimi
Generalnie, zgodnie z zasadą wyłączonego środka, każde dwa pojęcia mozna połączyć w zdanie albo generalizacją albo predykatem. Kolejna zasada: w poprawnej ontologii, wstawienie w zdaniu, w miejsce pojęcia, jego typu (specjalizacja), zachowuje prawdziwość tego zdania. Trzecia: zdanie tworzą także jedno pojęcie i predykat. Przykłady odpowiednio:
- jeżeli “ratler to rasa (typ) psa”
- a także “mały pies to także pies”
- oraz “pies szczeka na listonosza”
- więc “ratler szczeka na listonosza”
- także “mały pies szczeka na listonosza”
- oraz “pies szczeka”
Wszystkie powyższe zdania to zdania prawdziwe i sensowne w języku polskim. Są to zdania prawdziwe w sensie “tak sią (generalnie) dzieje, że… “, są to fakty jeżeli zdanie jest relacją. Patrz:
W The Philosophy of Logical Atomism Russell pisze: Jeśli mówię „Pada”, to to, co ja mówię jest prawdziwe przy pewnych warunkach pogodowych a jest fałszywe przy innych. Warunki pogodowe, które czynią moje stwierdzenie prawdziwym (lub fałszywym w innym przypadku), są tym, co nazywam faktem”
Modelowanie
Wśród wielu znanych metod modelowania ontologii jest OntoUML . Moim zdaniem ma pewne wady: autorzy wprowadzają pojęcie ‘event’ mające takie cechy jak początek i koniec (wartością tych atrybutów jest czas: timestamp). Uważam, że stwarza to pewien problem z klasyfikacją treści takiego komunikatu. Po drugie, jeżeli uznamy, że przestrzegamy zasady “nie lubimy pustych pól” (bazy danych nie zawierają pól/atrybutów bez wartości) to ‘event’ łamie tę zasadę, bo wartość zadeklarowanego pola “end event” będzie pusta do momenty zakończenia “zdarzenia”. Jednym z ciekawszych podejść do ontologii, jej modelowanie i integracją z modelami systemów (MDA, SysML, UML) opisali w swojej pracy Devedzic i inni z czego także tu korzystam.
W publikacji na temat klasyfikacji i jednoznaczności opisu opisywałem metodę dzielenia informacji wg. kontekstu, jakim jest sklasyfikowanie treści jako opisu obiektu (ten trwa w czasie) oraz faktu (nie trwa w czasie). Zdanie “Dom ma cztery okna i czerwony dach” jest prawdziwe mimo upływu czasu, zawsze będzie wypowiadane w czasie teraźniejszym. Zdanie “w Dom uderzył piorun” jest prawdziwe ale zawsze będzie wypowiadane w czasie przeszłym. Obiekty trwają w czasie, ich stan może się zmieniać: “Po przemalowaniu (fakt) dom ma zielony dach” (i to trwa). Wszystko to co trwa w czasie, jest ograniczane faktami, w szczególności fakt powstania rzeczy (obiektu) i fakt jego “zniszczenia”, w międzyczasie mogą mieć miejsce fakty zmieniające stan rzeczy (obiektu, np. zmiana koloru).
Generalizując: obiekty trwają w czasie zaś fakty nie. Początek i koniec trwania obiektu to dwa kluczowe fakty z “jego życia” (cykl życia obiektu) a nie “event” mający początek i koniec. W “życiu” obiektu mogą wystąpić inne fakty. Cechy obiektu to jego własności (kolor, waga i wiele innych itp.), cechami faktów są moment w czasie (time stamp) oraz to jakiego obiektu (obiektów) dotyczyły.

W systemach informacyjnych mamy do czynienia z gromadzeniem wiedzy o świecie oraz z gromadzeniem sprawozdań. Powyżej ontologia czyli pojęciowy model wycinka świata. Zdanie “pies szczeka na listonosza” a także “pies szczeka” to ogólna wiedza o psach. Zdanie “listonosz boi się psa” to ogólna wiedza o listonoszach. Sprawozdaniem było by tu zdanie: “mały pies, pudel, szczekał na listonosza od godzony 16:16 do godziny 16:18” (można by jeszcze podać adres).
Ontologia, jako językowy opis świata, to metamodel zdań opisujących pewną klasę obiektów i zdarzeń. Sprawozdanie mówiące, że konkretny pies, w określonym okresie czasu, szczekał na konkretnego listonosza (w konkretnym miejscu) to taka właśnie instancja (wystąpienie).
Projektowanie architektury danych
Jaką architekturę powinien mieć “dokument” będący treścią tego sprawozdania?
Poniżej trzy etapy analizy.
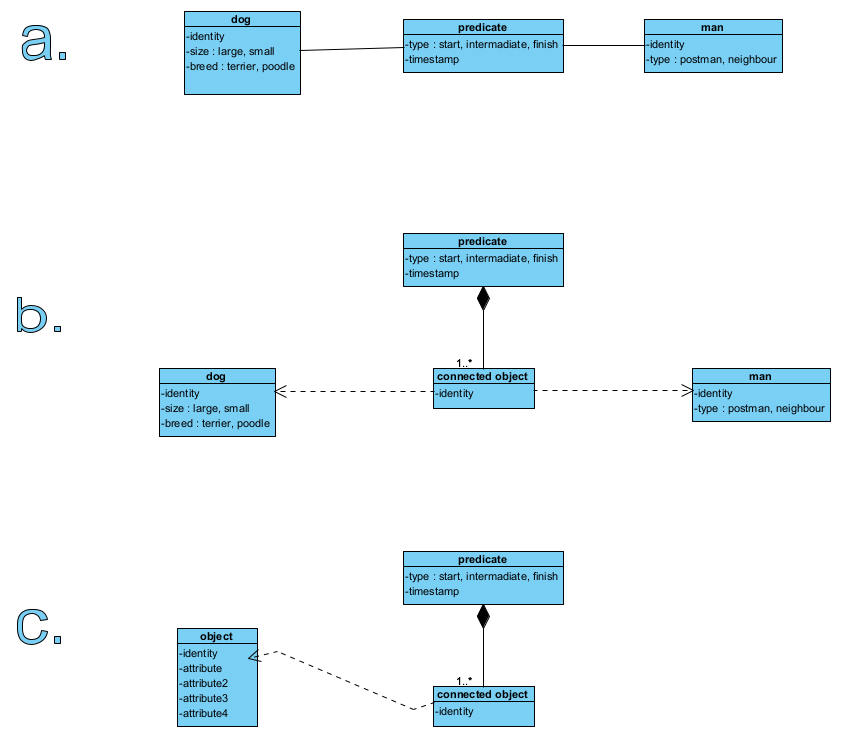
Ogólnie można powiedzieć, że predykaty (fakty zdaniotwórcze) dotyczą obiektów: zbieramy informacje (wiedzę) o tym, kiedy pies szczekał na ludzi, jaki pies i na jakich ludzi szczekał. To rysunek a. powyżej, możemy go nazwać koncepcją. Zapisanie takiej informacji wymaga zaprojektowania trzech repozytoriów: pies, człowiek, predykat. Powiązanie psa z człowiekiem jest zapisane jako atrybuty predykatu (rys. b.). To projekt architektury danych i logiki ich wiązania. Bardziej uniwersalny model pokazano na rys. c., wymagał by on uzupełnienia “bazą szablonów obiektów” (struktury agregatów opisujacych różne typy obiektów) z uwagi na to, że różne obiekty mogą mieć różne cechy. Tu pokazano je w uproszczeniu jako atrybuty, jednak realny projekt dziedzinowy były już bardziej precyzyjny i rozbudowany.
Powyższe można zapisać w bazie NoSQL, w w bazie grafowej obiekty były by węzłami a predykaty krawędziami. Detale obiektów mogą być agregatami w bazie dokumentowej.
Rola ontologii w projektach
Kluczową rolą i celem tworzenia ontologii jest wspólny słownik i zrozumienie pojęć. Ontologia pełni rolę centralnej współdzielonej przestrzeni pojęciowej (namespace) i wiedzy dziedzinowej (np. reguły biznesowe). Wszystkie systemy w organizacji (bardzo często od różnych producentów) mają – każdy swój – wewnętrzny i lokalnie spójny system pojęciowy (namespace). Jakakolwiek ich integracja (wymiana komunikatów między systemami) wymaga mapowania synonimów w komunikatach (nazwy pój, ich wartości, robi to adapter, bardzo często jest to implementowane jako szyna integracyjna ESB):.

Podsumowanie
Uważam, że ontologie nie wymagają skomplikowanych metamodeli takich jak ww. OntoUML czy bardziej skomplikowanych, opartych na rozbudowanych taksonomiach i modelu UFO .
Gromadzenie wiedzy to albo wiedza “generalna” opisująca świat (właściwa ontologia) albo sprawozdania (opisy), dla których ontologia jest metamodelem (ontologia tu, to metadane sprawozdań). Tak więc możemy powiedzieć, że gromadzenie wiedzy wymaga dziedzinowego (specyficznego dla dziedziny) modelu pojęciowego: ontologii. Na tej podstawie można zbudować model struktury danych. Pokazano, że obecnie najbardziej adekwatny do opisów byłby model dokumentowy, gdyż opisy obiektów będą skomplikowanymi agregatami o zmieniającej się w czasie strukturze, zależnej od typu obiektu, ale też odwzorowującej wiedzę o nim. Predykaty są znacznie prostsze i przechowywanie ich w postaci samych prostych metadanych wydaje się wystarczające. Całość tworzy sieć, w której węzły są obiektami a krawędzie faktami.
Biorąc pod uwagę ogromne ilości zbieranych danych oraz to, że “nie można sie pomylić”, modele SQL/RDBMS, z ich sztywnością i brakiem redundancji, wydają się nieadekwatne. Ontologie jako wiedza o istocie świata (np. w systemach sztucznej inteligencji) bardzo dobrze pasują do baz grafowych. Ogromne ilości danych sprawozdawczych doskonale pasują do baz dokumentowych. Wyzwaniem w projektach tego typu jest zbudowanie dziedzinowej ontologii, a potem zaprojektowanie agregatów (dokumentów) przechowujących dane sprawozdawcze. Przykładem takich agregatów są np. opisy zmieniających się produktów jako obiektów oraz faktury jako fakty dokonania transakcji ich sprzedaży (co, kto komu, za ile, kiedy). Zdanie “Jan sprzedał Krzysztofowi rower” to wiedza o tym, że pewien fakt (moment dokonania transakcji) połączył trzy obiekty: sprzedawcę, nabywcę, sprzedany produkt.
Dalsze prace
Dalsze prace prowadzone są w kierunku stworzenia ogólnej uniwersalnej metody analizy i projektowania systemów zarządzania informacją na bazie ontologii i struktur dokumentowych i wdrażanie ich w systemach zarzadzania informacją zarówno ERP jak AI.
Dodatek
Pojęcia klasy obiektów, klasyfikatora, wartości a także pojęcia reprezentującego obiekty, które mogę reprezentować wartość czego to zbiory, definicje elementów i elementy. Z elementów zbioru, za pomocą predykatów, mozna budować “zdania prawdziwe” czyli opisy. Poniżej ciekawa prezentacja o teorii zbiorów i rachunku predykatów. Bardzo ważna dla zrozumienia tego czym tak na prawde jest analiza pojęciowa.
Diagram faktów to także model “przepływu tokenów” w modelach językowych:
https://youtu.be/9vM4p9NN0Ts?si=SVD1-W51XZ7EJbbm
(Stanford CS229 I Machine Learning I Building Large Language Models (LLMs))




czy man może być zarówno typu postman i neighbour, ogólniej czy w modelu faktów specyfikacje typów muszą się wykluczać?
Generalnie pojęcia oznaczają ‘coś’, rozróżnianie ‘tych rzeczy’ wymaga definicji, a te muszę się wzajemnie wykluczać by to rozróżnienie było możliwe. Problem ‘postman i neighbour’ pojawia się zawsze, gdy ktoś próbuje stosować ‘proste dziedziczenie’ jako model taksonomii.
‘Postmen’ to zawód, ‘neighbour’ to nazwa formy relacji z otoczeniem, a to znaczy, że są to dwie taksonomie. Jest to dokładnie ten sam problem co klasyfikacja zwierząt w artykule o systemie dla weterynarza: człowiek jest jednocześnie ‘Postmen’ i ‘neighbour’ bo są to odrębne klasyfikacje (w UML i SBVR to się nazywa ‘generalisation set’, spec. UML, 9.7 Generalization Sets). Na diagramie powyżej: ‘pies’ jest jednoczenie i ‘terrier’ i ‘large’.
To jest coś (jedno pojęcie i jego kilka taksonomii), czego nie da się odwzorować wprost w bazie relacyjnej.
P.S. druga uwaga: w tym przykładzie ‘postman’ i “neighbour’ się wykluczają, bo w ‘domenie’ tego opisu (kontekst) listonosz i sąsiad to osobne osoby (w dziedzinie ‘na kogo szczeka pies’ sąsiad i ‘listonosz’ są innymi ludźmi). To, że sąsiad może wykonywać zawód listonosza to prawda, ale w innymi kontekście. Tu powiemy, że “pies szczeka i na listonoszy i na sąsiadów”.
Bardzo łatwo to osiągnąć w dokumentowych systemach zarządzania danymi, bo granica dokumentu (traktowanego jako agregat) separuje konteksty danych jakie są w nich zawarte. W modelu relacyjnym jest to nie do uzyskania co powoduje, że pewne funkcjonalności systemów opartych na jednej relacyjnej bazie są po prostu nie możliwe do uzyskania [https://martinfowler.com/bliki/BoundedContext.html].
Tu inny ładny opis:
https://youtu.be/zlFqjD2LKlE
Rachunek predykatów czy rachunek zdań to materiał wykraczający poza ten artykuł, jednak w kwestii budowania modeli pojęciowych pojęcie predykatu jako związku zdaniotwórczego wystarczy. Predykat to element aczácy dwa rzeczowniki (najczéciej czasownik), np.: sowa pies i listonosz to rzeczowniki (a konkretnie pojęcia będące nazwą czegoś). Aby powstał prawdziwe zdanie (mające sens) potrzebujemy elementy łączącego zwanego predykatem: pies ‘szczeka na’ listonosza.
Więcej tu:
Witold Marciszewski. (2003). Rachunek Predykatów słownik, składnia i semantyka. LOGIKA, 2002/2003. https://www.calculemus.org/lect/L-I-MNS/03/lim03.pdf
Dzień dobry panie Jarosławie. Interesuję się filozofią oraz logiką formalną (studiuję na wydziale filozoficznym). Szukając informacji na temat ontologii stosowanych natrafiłem na Pana interesujący blog, przedstawiający mało mi znane, bo praktyczne i biznesowe zastosowanie pojęć i konceptów, które od jakiegoś czasu z pasją poznaję. Chciałbym się spytać – czy polecałby Pan obraną przez Pana ścieżkę kariery (projektowanie systemów i struktur informacyjnych, analiza systemowej organizacji)? Czy w Pana przekonaniu specjaliści z tych dziedzin są rozchwytywani? Czy jest to lukratywna kariera? Z góry dziękuję za odniesienie się do moich pytań. Jestem wprawdzie przede wszystkim zainteresowany działalnością akademicką, ciekawi mnie jednak najzwyczajniej w świecie, czy wiedza i umiejętności, które rozwijam mogłyby, chociaż częściowo, dać mi możliwości w zakresie znalezienie pracy w dobrze płatnym sektorze komercyjnym. Dziękuję za uwagę.
Dobre pytanie ale obawiam, że rozchwytywani raczej nie są. Jednak są branże w jakich ma ta wiedza zastosowanie: duże zintegrowane systemy i tak zwane “centralne słowniki danych” (masterdata: głownie banki i ubezpieczenia, rejestry publiczne, archiwistyka). Ontologia się bardzo przydaje na etapie analiz jako dodatkowa wiedza, ale jako samodzielna dziedzina czy samodzielny “zawód” to troszkę jak by matematyk szukał “pracy w zawodzie”…
Oczywiście, zgadzam się z Panem i rozumiem, że teorię wyniesioną z działalności akademickiej [czy to filozofia, czy właśnie matematyka, o której Pan wspomniał, którą też studiowałem 🙂 ] zawsze należy uzupełnić konkretnymi umiejętnościami z danej branży. Ale skoro już mam okazję rozmawiać z osobą o dużym doświadczeniu w pracy IT oraz ogromnej wiedzy, nie mogę powstrzymać się od pociągnięcia wątku: jeśli nie ta konkretna działka, to jaka? Tak podchodząc czysto pragmatycznie – chodzi tu o stosunek między liczbą chętnych a faktycznie poszukiwanych – czyli nie 1 miejsce na 500 chętnych jak obecnie programista JAVA junior (hehe), tylko powiedzmy sektory, gdzie faktycznie “brakuje rąk do pracy” (mowa oczywiście o IT oraz pokrewnych, znanych Panu branżach). Nisza, która być może istnieje ale osoba z zewnątrz niekoniecznie wie o jej istnieniu. Z góry przepraszam za tak być może mało eleganckie postawienie sprawy (nie uwzględnienie czynników takich jak pasja, powołanie i tym podobne) – mowa tutaj jednak o przede wszystkim zaspokojeniu ciekowości (najprawdopodobniej i tak będę pracował głównie na uczelni).
Moim zdaniem ontologia to narzędzie a nie produkt. Innymi słowy: na rynku “raczej” nikt nie kupi “ontologii”, ale kupi “projekt systemu”, a ten będzie znacznie lepszy, gdy projektant będzie miał lepsze zrozumienie dziedziny jaką analizuje i projektuje, a tu ontologia bardzo pomaga. Idąc tym tropem, takie “zawody” jak analiza biznesowa, projektowanie systemów, analizy danych, systemy klasyfikacji treści (archiwistyka i pokrewne), to moim zdanie właściwe kierunki.