
Ten artykuł jest adresowany do wszystkich. Biznes (prawnicy także) może przekonać się, że oprogramowanie można narysować i zrozumieć. Analitycy i programiści, że to możliwe, a deweloperzy, że nikt im nie odbiera pracy a raczej pomaga.
Wprowadzenie
W dzisiejszym świecie inżynierii największą wartość mają czas i zasoby. Czas to jak najszybsze oddanie rozwiązania (produktu) do użytku (szybka komercjalizacja), zasoby to koszt jakim się to odbędzie. Kluczem są koszty: “time to market”, tu kosztem jest opóźnienie komercjalizacji (niezrealizowane przychody), kosztem jest także samo powstawania oprogramowania. Praktycznie od początku inżynierii oprogramowania zależność kosztów od dyscypliny i etapu pracy się nie zmienia, wygląda to jak poniżej:
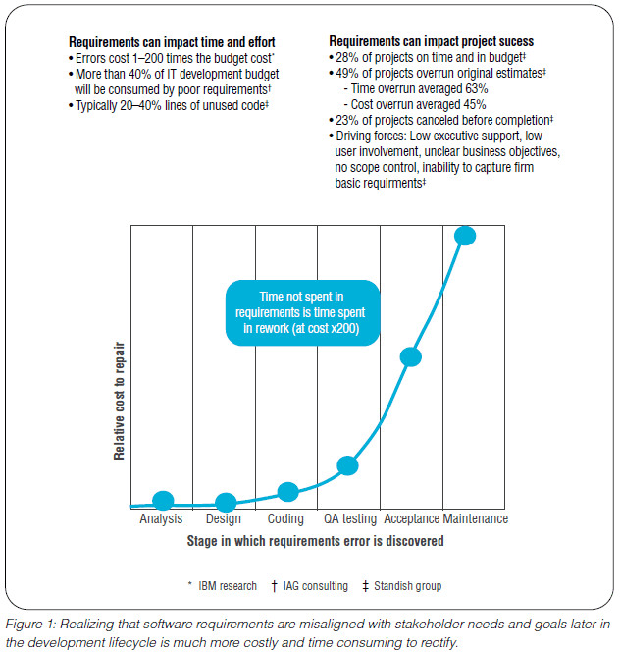
Od samego początku prac nad oprogramowaniem tak naprawdę rozwiązujemy problemy: począwszy od problemów z odkryciem co tak naprawdę jest rozwiązaniem problemu (a problem trzeba najpierw zidentyfikować), przez problemy związane z właściwym zaprojektowaniem rozwiązania (algorytmy, architektura kodu), do problemów wyboru technologii i implementacji. Patrząc od końca: pomyłki są bardzo kosztowne dla organizacji (sponsor projektu). Development (kodowanie i testy) to praca zespołów ludzi, są bardzo kosztowne. Najtańsza jest tu praca (etap) analityka-projektanta, to jednak także czas (pamiętamy “time to market”).
Tak więc “waterfall” nie wchodzi w grę. Praktyka jednak pokazuje, że rozpoczęcie od razu od kodowania nie rozwiązuje żadnego problemu bo złe pomysły są i będą, korygowane dopiero na etapie kodowania generują bardzo duże koszty. Lekarstwem jest odejście o monolitycznej architektury na rzecz samodzielnych komponentów, czy wręcz mikroserwisów (jednostki implementacji to pojedyncze przypadki użycia UML, tu rozumiane jako niezależne mikro-aplikacje ). Dlatego optymalne wydaje sie podejście: 1. analiza, 2. projektowanie HLD: komponenty, 3. iteracyjne projektowanie LLD komponentów i ich development. Osiągamy ważną rzecz: najdroższe zasoby: development, dostają do implementacji przemyślane rozwiązanie, nie tracimy czasu i środków na kolejne prototypy w kodzie.
MDA czyli cykl życia aplikacji
Ponad 10 lat temu organizacja Object Management Group opublikowania specyfikacje MDA (Model Driven Architecture, architektura zorientowana na modele ). Opisuje ona proces od analizy, przez modele rozwiązania, aż do jego implementacji. Proces ten wygląda tak:
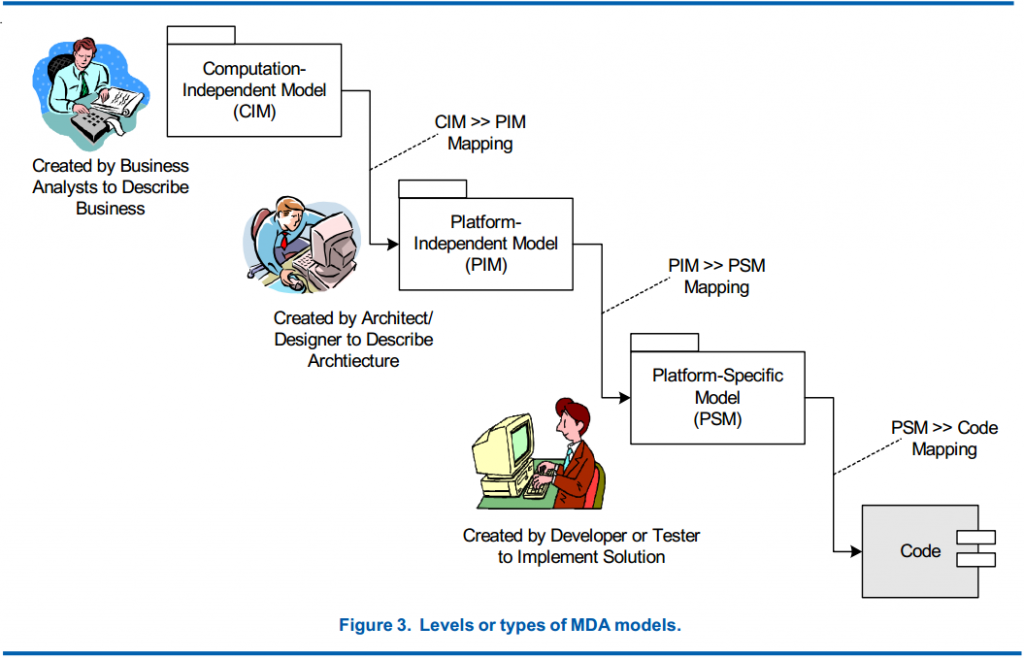
Czy to jest waterfall (technika wodospadowa)? To zależy od zaprojektowanej architektury oprogramowania. Jeżeli będzie to funkcyjny monolit budowany na centralnej relacyjnej, bazie danych (RDBMS) to będzie to waterfall. Jeżeli jednak będzie to komponentowa architektura zorientowana na micro aplikacje (micro serwisy), będzie to zwinna, iteracyjno-przyrostowa, implementacja i rozwój, gdyż na podstawie modelu PIM (także polityka podziału na komponenty i usługi) wykonywane są przyrostowo i niezależnie od siebie, kolejne implementacje usług aplikacji (PSM->Code). Tak więc wszystko rozstrzyga się na poziomie modeli PIM. PIM (Platform Independent Model) to projekt oprogramowania niezależny od technologii (czyli także od użytego języka programowania).
Mikro-serwisy
O mikro-aplikacjach pisałem nie raz, tu tylko przypomnienie:
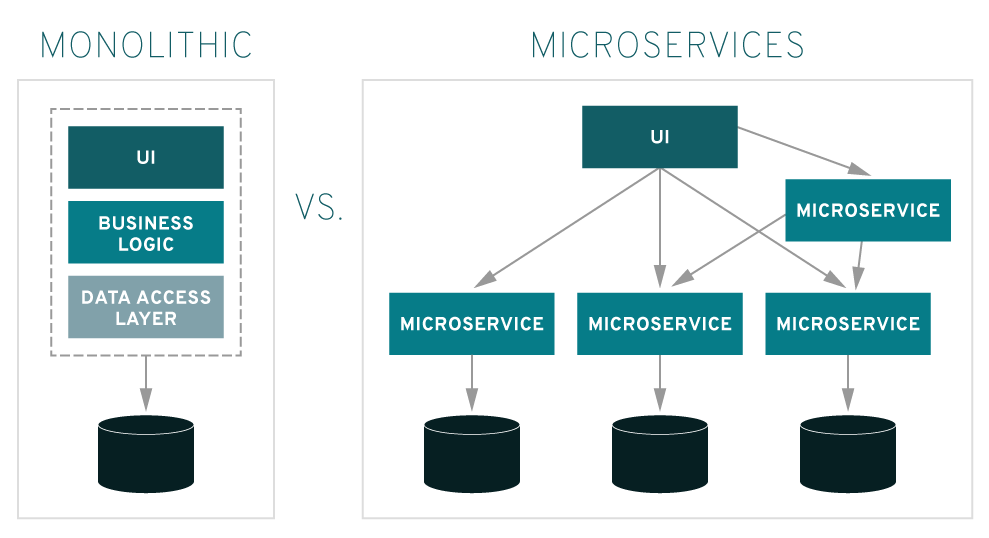
Tak więc wszystko zależy od architektury, zwinność także. Po prawej stronie (diagram powyżej) pokazano ideę podziału aplikacji na niezależne komponenty, każdy z własnym repozytorium (bazą danych). Komponenty te można developować i oddawać do użytku w dowolnej kolejności .
Program to abstrakcja rozwiązania, określony kod to jedna z wielu możliwych implementacji
Złożoność systemów rośnie z każdym rokiem. Oprogramowanie (komputery) jest częścią coraz większej ich liczby. Development jest najkosztowniejszą fazą wytwarzania oprogramownia, dlatego coraz znowu częściej poprzedza się go projektowaniem czyli “tworzeniem programu jako logiki” . Nie da się “z marszu” napisać tysięcy linii kodu, nie popełniając błędów w kodzie czy na poziomie samej architektury i logiki działania.
Tworzenie systemów zawierających oprogramowanie obejmuje wiele poziomów abstrakcji, prowadzących od wymagań do kodu. Posiadanie abstrakcyjnych koncepcji pomaga zdefiniować kod i upewnić się, że komponenty oprogramowania zachowują się w oczekiwany sposób. Istnieje luka, która nie może być wypełniona przez zwykłe metody programowania, ale która może być wypełniona, jeśli programowanie jest wspierane przez odpowiednie ramy modelowania.
Program komputerowy może zostać wyrażony z pomocą kodu, ale także, w sposób równoprawny, “z pomocą schematów blokowych, algorytmów i wzorów matematycznych” (http://www.ipblog.pl/2017/03/programy-komputerowe-co-podlega-ochronie/). Zgodnie z powyższym i z MDA mamy:
Przykład czyli programujemy obrazkowo
Zakres projektu
Opracujemy program wspierający proces obsługi klientów przychodni weterynaryjnej. Wygląda on tak:

Jak widać nie jest specjalnie wyrafinowany: Jeżeli potrzebna jest wizyta ze swoim pupilem u weterynarza, umawiamy termin, przychodzimy na wizytę, opuszczamy przychodnie z receptą i zaleceniami. Faza analizy i opracowania architektury została opisana w artykule Projekt aplikacji. Tu skupimy się na “programowaniu”.
Od kilku już dekad w podręcznikach inżynierii oprogramowania nadal można spotkać sentencję:
algorytmy + struktury danych = programy
Poza technologią i paradygmatami, nic sie nie zmieniło. To znaczy, że bez względu na architekturę, paradygmat i język programowania, ‘programy’ to ‘algorytmy + struktury danych’. Innymi słowy: programowanie to projektowanie algorytmów i struktur danych, dalej jest już tylko implementacja (kodowanie) tych programów.
Każdy “program” to deklaracja zmiennych + działania na nich. Może to być poprzedzone pobraniem tych danych i zakończone zwróceniem danych (parametrów). Można to (fragment programu prezentowana jako “czynność” w UML) wyrazić pseudokodem:

Lub w formie bardziej przystępnej dla laika, “obrazkowej”:
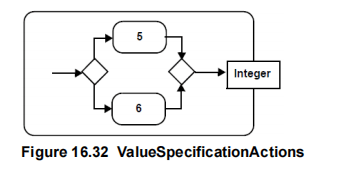
Od początków “człowieczej biurokracji” standardową formą przechowywania danych są formularze, czy szerzej rzecz ujmując, dokumenty. W roku 1972 Codd opublikował swoja pracę, w której opisał relacyjny model danych, jednak celem było zarządzanie zbiorami danych a nie “informacją” . Powstało wiele implementacji tego modelu i niestety model ten zdominował branże. W czasie gdy powstawał liczyła się optymalizacja tych zbiorów od strony objętości (to był główny czynnik kosztowy). Jednak po latach okazało się, że:
Relacyjny model danych jest nieelastyczny. Cechuje się precyzyjnie zdefiniowaną strukturą danych, która jednak bardzo ją ogranicza. Musimy zdefiniować stałą strukturę jak kolumny i wiersze tabel oraz określić ich relacje, co jest później trudne do zmiany. Ponadto, jeśli dziedzina pojęciowa jest głęboko zagnieżdżona, użycie modelu relacyjnego dla niej będzie wymagało wielu tabel i złączeń. Relacyjne bazy danych mają słabą skalowalność poziomą. Mogą być skalowane w pionie poprzez dodanie większej ilości zasobów, takich jak procesor i pamięć RAM. Ale nie mogą być skalowane poziomo, tzn. łączyć wielu maszyn i tworzyć klastrów. Wynika to z wymagań dotyczących spójności. Baza danych zorientowana na dokumenty rozwiązuje niektóre z tych problemów, z którymi boryka się baza danych w modelu relacyjnym.
Główną wadą relacyjnego modelu danych w systemach biznesowych jest zapisywanie danych w postaci współdzielonych znormalizowanych struktur pojęciowych, pozbawionych redundancji, co powoduje, że dane są pozbawione kontekstu , a w konsekwencji model ten nie sprawdza się w systemach zarządzających dokumentami i ich treścią.
Dokumenty biznesowe (dowody księgowe ale także umowy, oferty i wiele innych) to złożone agregaty danych, więc zapytania SQL do tabel relacyjnych (do ich zapisu i odczytu) to bardzo złożone struktury kodu, powodujące że tak zorganizowane bazy szybko stają się niewydajne (zasoby takie jak procesor i RAM są ograniczone a skalowanie poziomie RDBMS jest niemożliwe). Dodatkowo dokument, w sensie fizycznym nie może być generowaną dynamicznie strukturą (zapytania SQL do bazy relacyjnej), bo jest wtedy tylko wirtualnym chwilowym bytem, nie stanowi także dokumentu w sensie prawnym (Kodeks Cywilny), nie da się też zarządzać jego cyklem życia.
To powoduje, że od 20 lat mamy możliwość korzystania z baz zorientowanych na dokumenty (bazy NoSQL). Struktury danych bardzo łatwo i efektywnie można projektować od razu jako szkielety dokumentów: agregaty :

Powyższy diagram to klasyczny agregat, który z innej perspektywy wygląda tak:
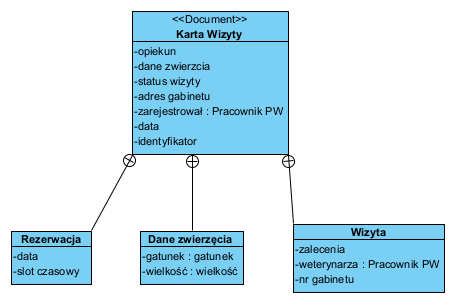
Powyższe łatwo zapisać jako jedna strukturę XML (lub JSON) i zachować jako wartość jednego atrybutu obiektu . Każdy element tego agregatu (atrybut) ma adresowalną unikalną postać, np. data planowanej wizyty:
Karta Wizyty.data := 22-10-02
Karta Wizyty.Rezerwacja.data := 22-10-16Gdzie nazwa dokumentu jest początkiem ścieżki (nazwy dokumentów-agregatów muszą być unikalne). Dzięki temu atrybuty, jako typy danych, definiowane są raz (np. tu data), zaś kontekst nadaje im położenie w strukturze dokumentu. Powyższy przykład to dwie różne daty: data dokonania rezerwacji (data założenia Karty wizyty) i data samej wizyty. Tu 2 października umówiono sie na wizytę w dniu 16 października. Ale typ ‘data’ definiujemy raz, nie musimy definiować tylu dat ile jest ich rodzajów (data_rezerwacji, data_wizyty, itp…)
Tą metodą jednym prostym krokiem pobieramy dane z takiego agregatu , następnie opisujemy jakie operacje mają zostać na nich wykonane, wynik zwracamy jako ten sam agregat (wyliczono wartości pustych atrybutów, zwracamy wypełnione) lub inny agregat (wynik wyliczeń to nowy formularz/agregat) i możemy go np. przekazać innemu komponentowy do utrwalenia, lub zwrócić jako wynik do pokazanie na ekranie (patrz także starszą formę wzorca envelope: DTO).
Przykładowy opis tworzenia nowej karty wizyty:
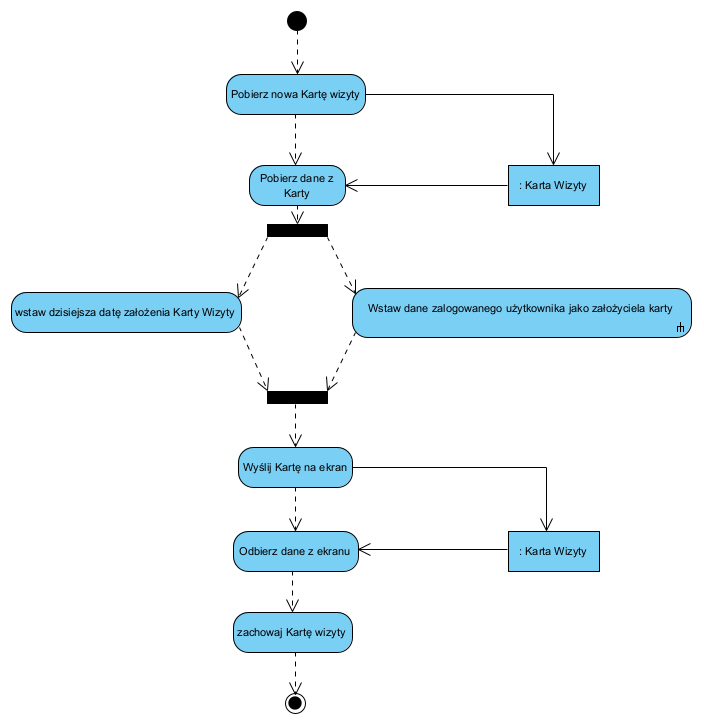
Tak więc zaprojektowanie aplikacji, przetestowanie spójności i kompletności logiki jej działania, przed kodowaniem jest nie tylko możliwe ale i pożądane, pomijam, że odbywa sie znacznie mniejszym kosztem i szybciej (praktyka pokazuje, że powyższe na diagramach jest o ponad rząd wielkości szybsze i tańsze niż praca od razu na kodzie).
Podsumowanie
Od początku inżynierii oprogramowania wiadomo, że programowanie to nie koniecznie kodowanie. Już na studiach najpierw “rysowałem” oprogramowanie a potem dopiero kodowałem to np. w Fortranie. Powód zawsze był ten sam: prace koncepcyjne są wielokrotnie tańsze na schematach blokowych niż na żywej maszynie. Ten sam program można było zawsze uruchomić na różnych komputerach, konieczny był jedynie wybór właściwego języka dla danej maszyny. Owszem, można “od razu w kodzie”, jest to jednak najbardziej nieefektywna metoda tworzenia oprogramowania. Wbrew potocznemu postrzeganiu manifestu agile, opisane tu schematy blokowe to nie jest “nadmiarowa dokumentacja” a “istota działania systemu”. Po drugie ani urząd patentowy w USA, ani europejski sąd w sprawie ochrony know-how, nie będzie analizował kodu źródłowego tylko jego sformalizowany opis.
Jak definiujemy role?
CZYM ZAJMUJE SIĘ INŻYNIER OPROGRAMOWANIA?
https://builtin.com/recruiting/software-engineer-vs-programmer
Inżynierowie oprogramowania oceniają potrzeby klienta lub firmy w połączeniu z potrzebami użytkownika i metodycznie konceptualizują i wyrażają rozwiązanie.
CZYM ZAJMUJE SIĘ PROGRAMISTA?
https://builtin.com/recruiting/software-engineer-vs-programmer
Programiści piszą kod i debugują błędy w programach i oprogramowaniu na podstawie instrukcji od inżynierów oprogramowania. Są zaangażowani w pojedynczy etap cyklu rozwoju i koncentrują się na jednym komponencie naraz.




Problem z tym, że czasem ta “pomoc” programistom kończy się jak niedźwiedzia przysługa. Źle zakreślone granice mikroserwisów, modułów czy obiektów. Źle bo naiwnie i zbyt dosłownie “zebrane wymagania”, bez analizy – tylko czym jest ta analiza? Weźmy na tapet przykład z kartą wizyty. Przedstawiony model, to bardzo dobry model prezentacyjny (view model, read model, projekcja). Ale zrobienie z tego agregatu DDD to suma wszystkich antywzorców jak nie robić DDD czy nawet object oriented. Budując na tej podstawie system, która da się rozbudować czy skalować skończymy z katastrofą. Dlatego wypowiem się w obronie programistów, nie chodzi o strach o “odbieranie pracy”, bo tej jest po kokardkę ale o jej dokładanie przez błędne modele, które i tak trzeba robić od nowa samemu albo później wszystko przerabiać.
“Problem z tym, że czasem ta ?pomoc? programistom kończy się jak niedźwiedzia przysługa.” to zawsze działa w obie strony.
Pojęcie agregatu to problem wielu sporów: “agregacja” rozumiana jako obiekty połączone związkiem kompozycji, czy “hierarchiczna struktura danych” wyrażona jako JEDEN DOKUMENT (XML, JSON, itp.). Obserwując implementacje i ich skutki, katastrofą jest pierwsze rozumienie. Dlatego od 20 lat bazy dokumentowe (agregat danych jako jeden dokument) dają znacznie lepsze wyniki. Jeżeli mam do czynienia z poprawianiem po błędnych modelach, to w 100% są to dokumenty zachowywane jako relacyjne modele danych wydłubywane zapytaniami SQL po setki znaków na każde takie zapytanie. DDD zaś absolutnie niczego tu nie narzuca: entity to płaska struktura a agregat to drzewiasta. Jak ktoś implementuje drzewiastą strukturę danych jako kaskadę deklaracji zagnieżdżonych klas, a potem na to nakłada jeszcze ORM by zapisać to w relacyjnym (płaskim, pozbawionym redundancji) modelu to to jest mega katastrofa ;).
Jakość oprogramowania ma jeden miernik: koszty całego cyklu życia.
“Budując na tej podstawie system, która da się rozbudować czy skalować skończymy z katastrofą.”
Tak (takie agregaty) powstała aplikacja obsługująca wnioski o dofinansowanie projektów polonijnych z całego świata. Zmienność treści wniosków (wniosek to ww. opisany agregat) to dokumenty od kilkunastu stron do kilkuset, i co roku inna definicja struktury wniosku. Projekt wg. powyższego opisu i metody powstał w miesiąc, a implementacja w 5 miesięcy, łącznym kosztem ok. 0,5 mln zł. Konkurencyjne oferty: Java Spring + SQL/RDBMS opiewały na ponad 10 mln, jako co najmniej roczny projekt. Mój projekt był udokumentowany tak, że w ciągu pięciu lat kod był przejmowany dwukrotnie przez kolejne firmy a beneficjant do dzisiaj ma prawa majątkowe do całości. Analogicznie powstała z mojej ręki aplikacja zarządzająca pracami wydziały śledczego Żandarmerii Wojskowej w całej Polsce. efekty podobne do powyższych. Obie się doskonale skalują, pierwsza bezboleśnie została przeniesiona do chmury AZURE. Żadna, w toku rozwoju, nie wymagała migracji danych.
Paradygmat obiektowy to nie “dziedziczenie i łączenie danych i funkcji w obiekty” a “współpracujące obiekty cechujące sią luźnymi powiązaniami, hermetyzacją i polimorfizmem”.