Wprowadzenie
Wzorzec ten budzi wiele kontrowersji co do tego czym są te trzy komponenty. Popatrzmy do anglojęzycznej WIKI:
Model – Centralny komponent wzorca. Jest to dynamiczna struktura danych aplikacji, niezależna od interfejsu użytkownika. Bezpośrednio zarządza danymi, logiką i regułami aplikacji. W Smalltalk-80, model jest całkowicie pozostawiony programiście. W WebObjects, Rails i Django, model zazwyczaj reprezentuje tabelę w bazie danych aplikacji.
https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller
Jest to dominująca definicja w literaturze, zaś spory o to czym jest Model w architekturze MVC jak widać mają jedno główne źródło: jakiego frameworka używa osoba wchodząca w takie spory. WIKI Cytuje to opracowanie: https://medium.com/free-code-camp/simplified-explanation-to-mvc-5d307796df30, zawierające między innymi tę ilustracje wyjaśniającą o co chodzi:
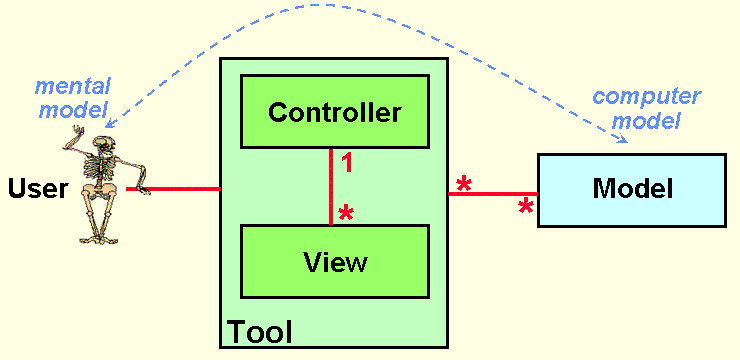
Z czym sie spotykamy
Popatrzmy na popularne “deweloperskie” artykuły:
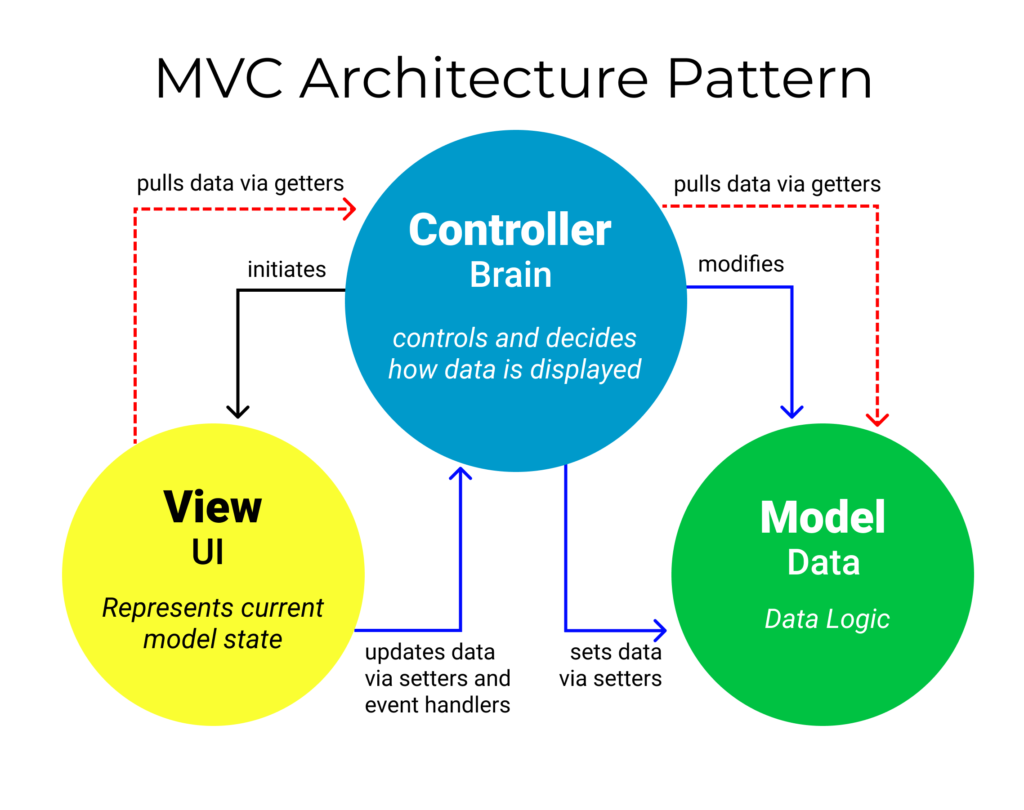
To klasyczna wersja bazująca na popularnym podejściu, mówiącym, że Model to dane a Controller to logika biznesowa a View to aktualny stan tej bazy danych. Autor wprost pisze: sets data via setters/getters (tak przy okazji set/get w klasach to jednak z najgorszych praktyk projektowania obiektowego: pobranie dowolnego dokumenty wymaga nie raz wywołania kilkudziesięciu operacji, łamiemy hermetyzację, itp.).
Powyższe to proste podejście znane ze starych strukturalnych narzędzi deweloperskich operujących trzema warstwami (np. Oracle Forms, JavaEE czy ASP.NET):
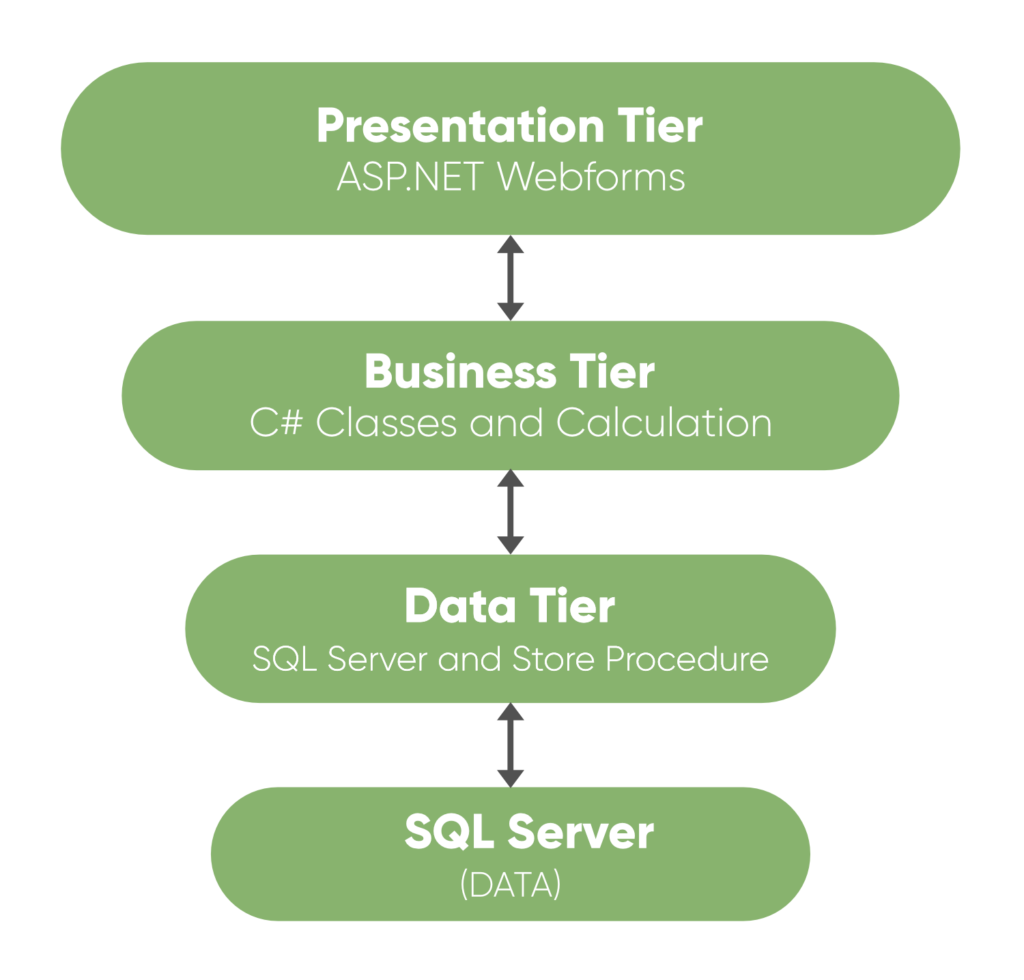
I warstwy te utożsamiane są odpowiednio z View (Presentation Tier), Controller (Business Tier) oraz Model (Data Tier). Baza SQL (relacyjna) to implementacja utrwalania. Podejście to nadal jest obecne w wielu frameworkach mających rodowody w latach 80/90 ubiegłego wieku.
Kolejnym błędem jest utożsamianie MVC z wzorcem BCE (Boundary, Control, Entity). Wzorzec ten ma swój rodowód oparty na polityce projektowania zorientowanej na odpowiedzialność klas [Wirfs-Brock, R., & McKean, A. (2006). Object Design: Roles, Responsibilities and Collaborations,. 88.]:
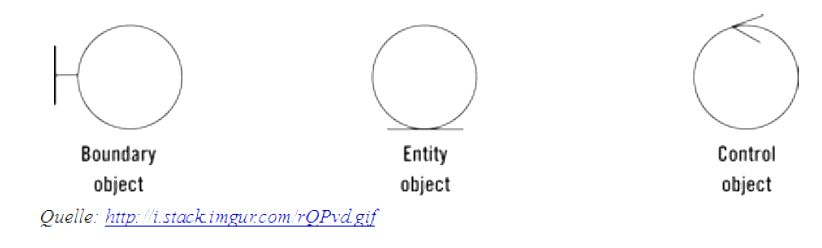
Istota tego wzorca to przyjęcie prostej zasady mówiącej, że klasa ma jedna wąską odpowiedzialność i są to trzy bazowe, alternatywne specjalizacje: interface (Boundary) zamykająca wejście do środka komponentu, logika (Control) realizująca przetwarzanie (przechowuje algorytmy i metody) oraz utrwalanie danych reprezentujących obiekty biznesowe (Entity). Czyli np. walidator formularza będzie klasą typu Control, a sam formularz (cały) będzie przechowywany w klasie Entity.
Popatrzmy teraz na to:
Autor używa tych symboli by pokazać trzy warstwy: GUI, logika, baza danych. Jeżeli jakiekolwiek aplikacje mają taką architekturę, są potężnymi monolitami.
Architektura heksagonalna
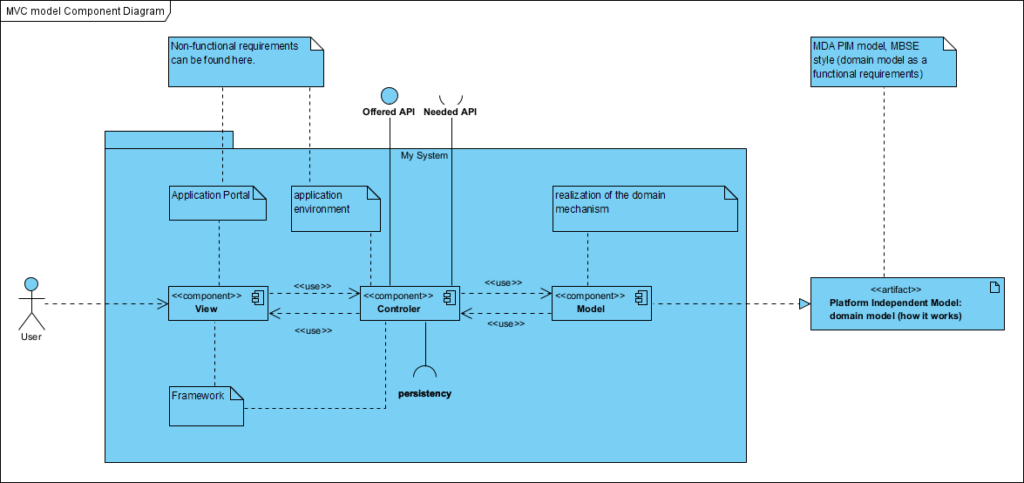
W 2005 roku Cocburn opisał podejście do architektury, które nazwał: Architektura heksagonalna [Cockburn, A. (2005, January 4). Hexagonal architecture. Alistair Cockburn. https://alistair.cockburn.us/hexagonal-architecture/]. Idea tego pomysłu polega na podziale kodu aplikacji na dwa obszary: Aplikacja, czyli cały i tylko kod realizujący funkcjonalność oprogramowania (w tym to jak i jakimi danymi zarządza) oraz reszta, czyli środowisko w jakim ten kod sie wykonuje (zwane kiedyś Run Time). To środowisko jest widziane jako adaptery (API) udostępniające pozafunkcjonalne elementy takie jak nośniki danych, usługi wysyłania odbierania komunikatów (SMS, email, itp.), dostęp do sieci Internet, usługi VPN, Interfejs użytkownika, drukarki itp. Schematycznie wygląda to tak:
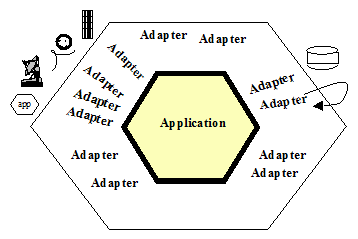
Bardziej precyzyjnie zobrazowano to na tym schemacie:
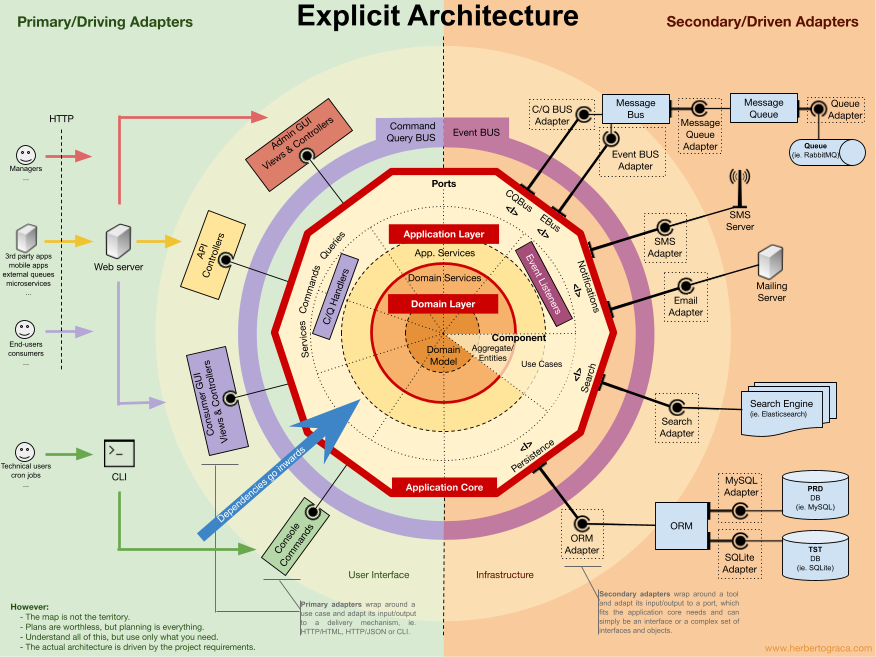
Co mamy na powyższym diagramie? Separacja trzech obszarów: kod realizujący dialog z człowiekiem po lewej (User Interface), kod funkcjonalność aplikacji w środku obramowany czerwona linią (Application Core) oraz kod realizujący wszelkie pozostałe pozafunkcjonalne usługi (Infrastructure). W tej kolejności były by to: V-M-C. Z uwagi (chyba na wygodę wymowy albo ważność tych elementów) piszemy MVC. Niektórzy autorzy w miejsce litery M wstawiają słowo Model (Domain Model).
Konsekwencje
W konsekwencji wyłania się podział działającej aplikacji na dwie zasadnicze części: komponent realizujący wymaganą funkcjonalność aplikacji oraz środowisko w jakim ten komponent funkcjonuje czyli biblioteki, sterowniki itp. ogólnie zwane adapterami:
Nie przypadkiem jedną z pierwszych prac dewelopera jest zestawienie “stosu technologicznego” czyli środowiska w jakim aplikacja (jak zostanie napisana) będzie się wykonywała.
Z innej perspektywy można to pokazać tak:
A teraz wyobraźmy sobie, że nasza aplikacja obejmuje obszar oznaczony turkusowym kolorem:
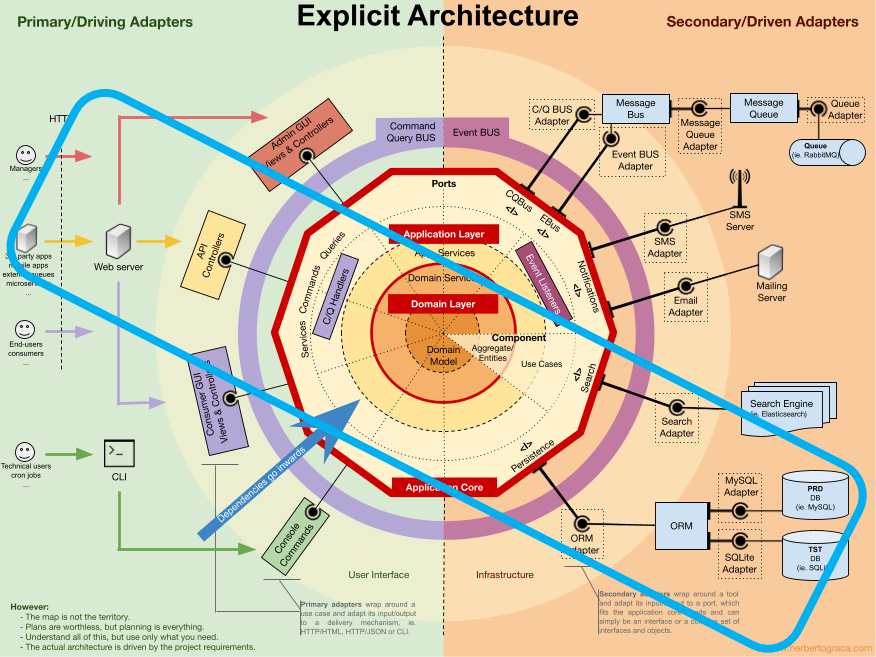
To jaki to jest wzorzec architektoniczny? Tak, nadal są w użyciu takie frameworki zwane “legacy architecture”. Nazywane czasami sarkastycznie “rozsmarowaniem logiki po całości”.
Podsumowanie
Tak więc architektura MVC to architektura całości działającej aplikacji gdzie Model to (makro)komponent realizujący jej funkcjonalności. Wzorzec BCE to polityka modelowania architektury komponentu na niskim poziomie (pojedyncze klasy/obiekty).
Ścisłe separowanie kontekstów i odpowiedzialności komponentów to kluczowa zasada metod obiektowych: hermetyzacja. Jakiekolwiek mieszanie odrębnych obszarów logiki i wymagań szybko doprowadza dowolny projekt do postaci monolitu.
Na koniec zacytuję ciekawy artykuł:
The products we build should never aim to reflect reality literally. The (physical) reality is unbound and infinitely complex – most of its details are just noise & distractions. We need its simplified, filtered version – these parts (/aspects) of the reality that are relevant in the current context. DDD calls it a “model”.
The failed promise of Domain-Driven Design
Warto także spojrzeć na opis w ang. WIKI:
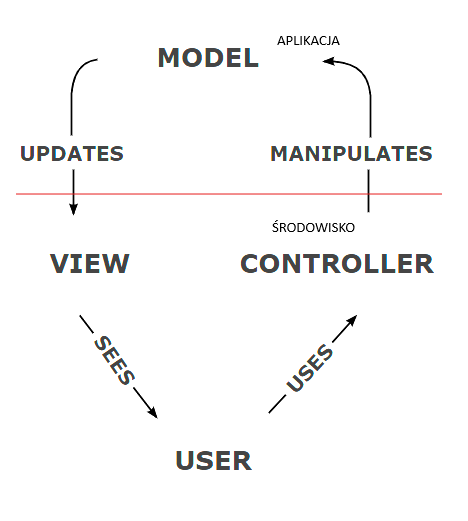
Opisany jako:
Model-widok-kontroler (ang. MVC) […] Elementy te to wewnętrzne reprezentacje informacji (model), interfejs (widok), który prezentuje informacje użytkownikowi i przyjmuje je od niego, oraz oprogramowanie kontrolera łączące te dwa elementy.
https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller
Warto tu przypomnieć, że “wewnętrzne reprezentacje informacji (model)” to nic innego jak dane i logika ich przetwarzania a nie “baza danych”. To dlatego niektórzy autorzy przywołują tu architekturę heksagonalną, która zakłada wydzielenie realizacji wymagań funkcjonalnych jako osobnego komponentu: to jest właśnie komponent Model.
Przykład
Etapy wytwarzania oprogramowania:
Umowa na wytworzenia oprogramowania to model przypadków użycia:
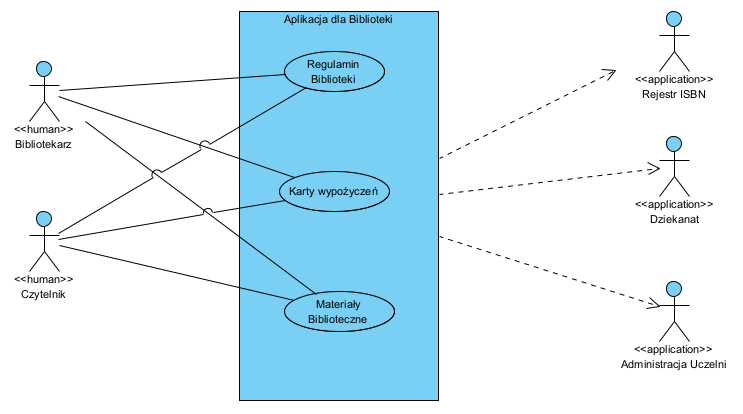
Prostokąt “Aplikacja dla Biblioteki” to cała działająca aplikacja. W projekcie jest to Model, bo pierwsze kluczowe założenie to: nie będziemy pisali kodu obsługującego sprzęt i standardowe elementy wejścia i wyjścia, bo to daje nam środowisko (system operacyjny i framework, itp.). Dlatego skupiamy się na zaprojektowania Mechanizmu działa aplikacji (zwana częścią dziedzinową).
Najpierw projektujemy architekturę HLD (High Level Design):
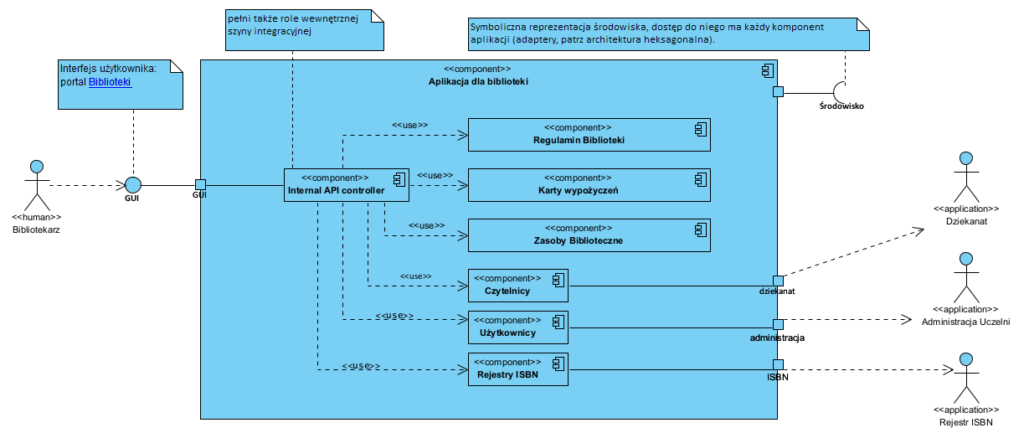
Na tym modelu mamy podział na komponenty, wewnętrzną integrację i integracją z innymi aplikacjami. Na tym poziomie głównym wzorcem są mikroserwisy i wzorzec saga. Na tym etapie podejmujemy decyzje, które komponenty kupujemy na rynku, a które tworzymy sami. Na tym poziomie testujemy także scenariuszy przypadków użycia. Np. wypożyczenie:
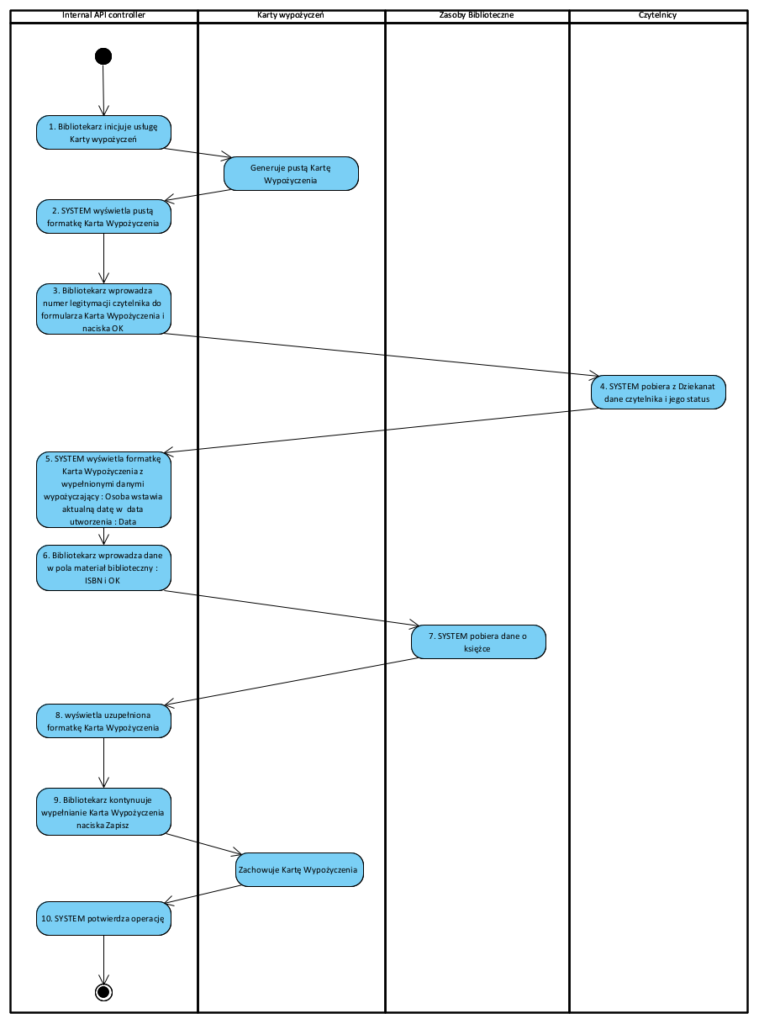
Kolejny krok to kolejne projektowanie każdego komponentu, który tworzymy sami. Przykład jednego z nich:
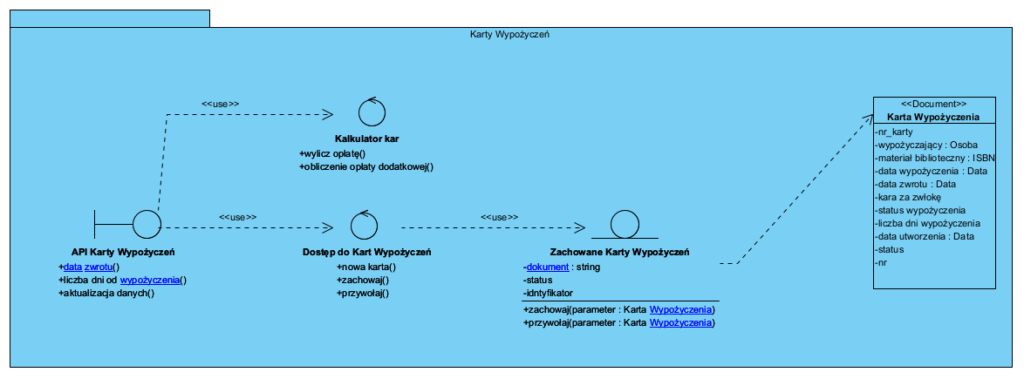
Na tym poziomie są bazowym wzorcem jest BCE oraz podstawowe wzorce: łańcuch odpowiedzialności, repozytorium, envelope.
Całość na każdym etapie testujemy (komunikacja, scenariusze) diagramami sekwencji. A gdzie tak popularne “diagramy klas”? Dane i ich logikę modelują formularze:
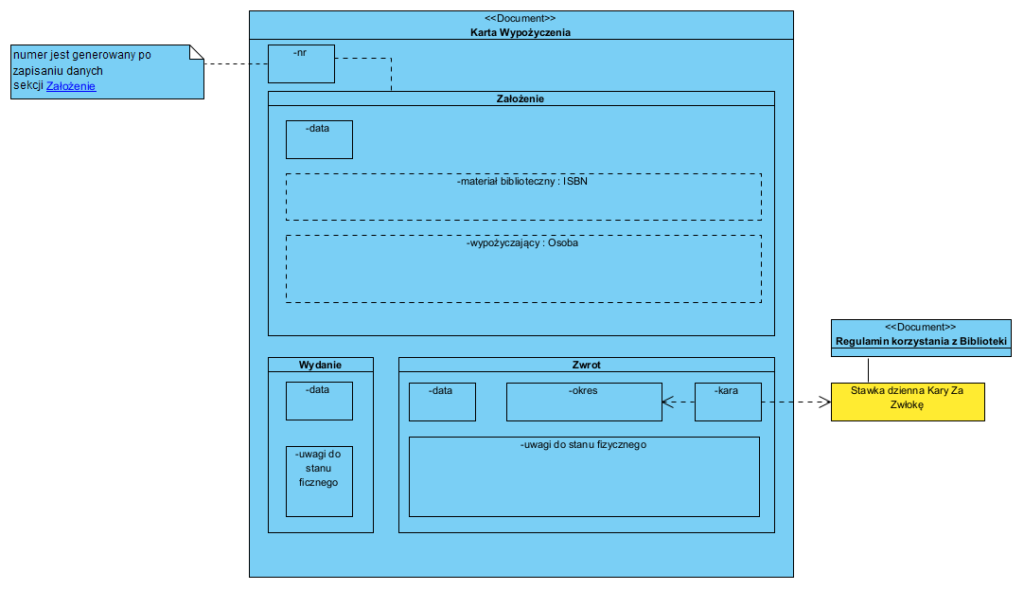
Jeżeli wymagane jest opisane metody (algorytmu) realizacji operacji obiektu, tworzymy algorytm:
Wszystko to powyżej realizuje komponent Model. Reszta to wymagania pozafunkcjonalne i infrastruktura (komponenty View i Controller). Aż tyle i tylko tyle.
Powyższa dokumentacja opisuje to jak to wszystko działa (cała logika biznesowa w jednym miejscu). Po wydruku będzie miała nawet tysiąc razy mniejszą objętość niż pełny wydruk kodu źródłowego jaki ona opisuje. Jest także niezależna od metod implementacji. Jak sądzisz czytelniku, co będzie czytane przez nowych członków zespołu, urzędnika Urzędu Patentowego czy inwestora przejmującego aplikację? Ja sądzisz, lepiej użyć notacji UML, która de facto zna cały świat czy jakiejś niszowej metody znanej niemalże tylko autorowi tych dokumentów?
A gdzie są mityczne diagramy klas pełne drzew dziedziczenia i kompozycji? Nie ma bo są bezwartościowe, a jeżeli faktycznie ktoś tak koduje, to są to mega kosztowne monolity…
Jeżeli Twój system lub jego projekt jest podobny do poniższego schematu, to znaczy, że Twój projekt jest jednak porażką…





Super materiał.
Z MVC jest totalny burdel. Nawet cytat z wiki jest nielogiczny, bo z jednej strony model ma logikę a z drugiej model to tabelki (ew. encje je odzwierciedlające w klasach). Czasem MVC jest architekturą aplikacyjną całej aplikacji, czasem tylko warstwy prezentacyjnej. Czym to skutkuje… W pierwszym podejściu kontroler zajmuje się wszystkim: walidacją, kontrolą przepływu pomiędzy widokami i logiką biznesową (bo encje anemiczne, bo tutorial do frameworka musi być dopasowany dla ludzi z dwucyfrowym iq). W drugim podejściu model jest modelem prezentacyjnym, kontroler zajmuje się kontrolą przepływu gui, a pod warstwą ui mamy osobne warstwy czy pierścienie hexagonu zależnie od poziomu złożoności logiki. Ale kiedy zajrzeć do materiałów z lat 80 to model nie musiał być anemiczny. Dalej mamy wariacje na temat MVC: MVVM, MVP, PAC itd, które próbują rozwiązać problem umiejscowienia i rodzajów logiki. A od tego mim zdaniem trzeba zacząć: jakie są rodzaje logiki? Kolejno od góry, czyli od intencji usera: walidacja syntaktyczna, walidacja biznesowa, logika procesu i jego stanu, logika integracjim logika flow ui, logika biznesowa: spójność zmiany stanu biznesu (nie procesu), obliczenia/transformacje, spójność zmiany danych. Więc pojawia się pytanie: w który rodzaj logiki angażuje się analityk? Na koniec pytanie o przykład z biblioteką, bo wygląda on na zorientowany na obieg dokumentów ale nie widać jakie są reguły dziedziny, które decydują jak te dokumenty obsługiwać. Coś jak wnioski w urzędzie: wnioski są api petenta aby nie znał domeny urzędnika. Ale wracając do pytania: kiedy wypożyczam książkę, to zmienia się stan zasobów biblioteki i zmienia się stan mojej karty bibliotecznej. Gdzie jest logika koordynujące te dwie zmiany?
Oczywiście, że z MVC jest “burdel” każdy dostawca frameworka “rozumie go po swojemu”. Jest dokładnie tak jak napisałeś, dlatego wielu ludzi “sięga do źródeł” abstrakcji.
Na to dodatkowo nakłada się bardzo ważny problem jakim jest przenoszalność aplikacji i dokumentowanie (w tym ochrona wartości intelektualnych). I tu pojawia sie “rozwiązanie”:
– to co kupujemy jako narzędzie i środowisko to “tool”, to dostajemy i używamy a nie tworzymy,
– jeżeli odseparujemy to co tworzymy od tego co dostajemy (środowisko), to wiemy co ewentualnie będziemy przenosić na inną platformę, do innego języka programowania (z tego co mówił A. Cockburn na jednym z niedawnych webinariów, to właśnie mu przyświecało gdy pisał doktorat o architekturze heksagonalnej)
– w konsekwencji dokumentacja całego systemu to TYLKO opis logiki ale całej czyli wraz z danymi (Model) i dołączona dokumentacja użytego środowiska.
Dlatego “z góry patrząc”:
– środowisko wykonawcze to Controller (sesje, wszelkie API do sprzętu, podawanie aktualnego czasu czy ID zalogowanego, itp)
– intepretowanie komunikatów z Modelu dla ludzi (wymiana treści) to View (i tu niekończące się dyskusje o pakowaniu logiki biznesowej do widoków)
– serce aplikacji (jej cała funkcjonalność) to Model, który można (powinno sie dać) w dowolnym momencie przenieść w inne środowisko.
“jakie są rodzaje logiki?”
1. dane są z “ludzkiej” perspektywy grupowane w dokumenty/komunikaty (formularze)
2. walidujemy pola tych formularzy
3. jeżeli są związki między polami (jednego lub wielu formularzy) są to reguły, a bywa, że złożone algorytmy
i to jest 100% logiki realizowanej przez Model. Reszta to pozafunkcjonalne problemy rozwiązywane po stronie infrastruktury.
Co w przypadku, kiedy mamy system z “głęboką” logiką, czyli dane z formularzyków, to tylko przekazanie małej ilości parametrów wejściowych. Pod spodem jest kilka razy więcej danych pobieranych z bazy i innych źródeł, masa logiki i odwołań do innych serwisów (dla utrudnienia zdalnych, które mają swole SLA, więc logika kompensacji dochodzi, biznesowej kompensacji). Słynne “kup teraz” na allegro. Czym wtedy będzie model wyrażony?
Głęboka logika to mity albo dramat. Dramat jest gdy wpakujemy logikę do infrastruktury, wtedy jest masakra.
1. formularze/komunikaty to i tak jedyna forma komunikacji
2. jedna SQL baza danych “pod spodem” to właśnie masakra logiki umieszczonej w infrastrukturze
dalej
3. dowolny system to skończona liczba “agregatów danych” i logiki komunikacji między nimi
4. wymiana danych między agregatami to sekwencje, z perspektywy systemu każde API (SLA nie ma tu nic do rzeczy) do zewnętrznego systemu to kolejny agregat
5. słynne “kup-teraz” to prosta realizacja natychmiastowego zamknięcia aukcji (status agregatu) i wystawienia faktury na bazie danych z tego agregatu (czyli kolejny agregat)
Model to całość tego co opisałem powyżej, reszta to infrastruktura, która nie powinna zawierać jakiejkolwiek logiki biznesowej.
Ok, to w przykładzie biblioteki, gdzie mamy zasoby biblioteki i karty. Co będzie agregatami, jak będą się komunikować i gdzie będzie logika zapewnienia, że zmienią się one spójne a wrazie gdyby nie (system rozproszony) to coś będziemy kompensować?
1. agregatem są: karta wypożyczenia, karta zasobu, karta czytelnika
2. agregaty z zasady sie między soba nie komunikują (to antywzorzec), to koordynator (Saga) czyta i zapisuje komunikaty z dziedzinowych komponentów zawierających agregaty
3. nadal nie wiem co to takiego ta mityczna kompensacja
4. to, że system jest rozproszony nie ma tu żadnego znaczenia.
powyższe masz pokazane w podsumowaniu artykułu.
Luz, ja wiem jak to zrobić na kilka sposobów:) Naprowadzam tylko na to, że trzeba dodać nowe klocki do tego mvc, bo niewiele z samego mvc da się ulepić. Rozproszenie ma znaczenie z powodu technicznego: niemożliwość założenie transakcji na kilka agregatów, co niestety wpłynie na biznes, bo fizyka, i trzeba to uwzględnić w procesie biznesowym, np. kompensując, czyli wycofując już poczynione kroki.
” trzeba dodać nowe klocki do tego mvc”
owszem, bo MVC to jedynie podział na najwyższym poziomie
“niemożliwość założenie transakcji na kilka agregatów”
nie ma takiej potrzeby gdy nie ma współdzielonej bazy pod spodem
“kompensacja”
jak wyżej
Bo generalnie to co widzę w wielu projektach, to najpierw z niewiadomego powodu powstaje jedna relacyjna baza danych, a potem cały zespół dzielnie walczy z jej wadami…
Nie to, że nie ma potrzeby przy kilku bazach danych. Nie ma takiej fizycznej możliwości (zakładam, że odrzucamy transakcje rozproszone). No i tu zaczynają się schody. Co jeżeli zapis do jednej bazy się powiedzie a do innej już nie?
“Nie ma takiej fizycznej możliwości (zakładam, że odrzucamy transakcje rozproszone). No i tu zaczynają się schody. Co jeżeli zapis do jednej bazy się powiedzie a do innej już nie?”
Jeżeli z góry zakładasz model relacyjny, setki połączonych tabel i kilometrowe Selecty to tak. Ale są inne możliwości, które tego nie wymagają. Bo Ty z góry zakładasz architektura pokazaną w powyższym tekście jak “rozsamrowaną”.
Nic z tych rzeczy, niech będą dwie bazy dokumentowe.
Dokumentowy to jest system przechowywania danych a nie “bazy jako takie”. W dokumentowym systemie zachowanie nawet bardzo skomplikowanej faktury nie jest żadnym “selektem z setka tablic” tylko prostym zachowaniem jednego stringu w jednym kroku do jednego atrybutu. Dlatego tu nie występują żadne problemu o jakich piszesz. Zapis także jest jednym krokiem, więc nie ma potrzeby żadnej kompensacji. Jeżeli tych faktur jest sto milionów, to i tak każda na swoje ID i możesz je bez problemu zapisać na dowolnej liczbie osobnych serwerów i nie ma z tym, żadnego problemu.
Te stringi nie nie niosą też żadnej logiki, więc nie ma tu żadnej kłopotliwej “płytkiej i głębokiej logiki”.
dobra, pass z mojej strony:)
Ogólnie, na koniec, subskrybentom tego wątku polecam np. tę prezentację na temat innej niż SQL/RDBMS formy zarządzania danymi: https://youtu.be/3GHZd0zv170?si=zU2utQD0k1v8lZDT