Wprowadzenie
Najbardziej wartościową umiejętnością architekta nie jest pisanie kodu, lecz umiejętność projektowania systemów, w których kod można łatwo usuwać i podmieniać. […] Kluczem do sukcesu jest projektowanie jeszcze przed napisaniem pierwszej linii kodu, ze szczególnym naciskiem na możliwość łatwego usuwania i podmieniania komponentów. Wyznaczenie granic między modułami, określenie interfejsów i interakcji, a także przewidzenie potencjalnych obszarów zmian to fundament dobrej architektury. [źr.: Dobry kod to taki, który łatwo usunąć]
W 2017 roku napisałem referat na pewną konferencję naukową studentów. Artykuł dotyczył architektury kodu. Jedną z ilustracji była ta:
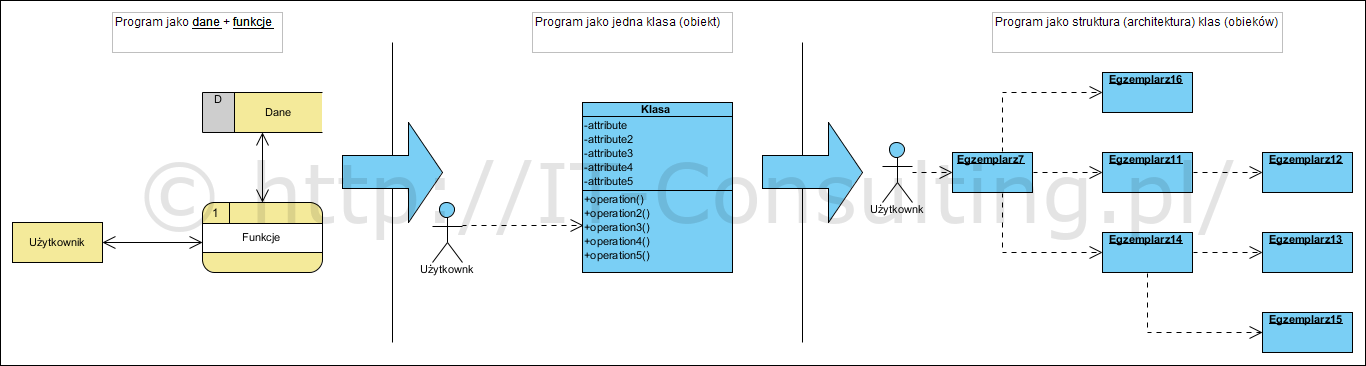
Artykuł kończyłem słowami:
Nie chodzi więc o to by podzielić oprogramowanie na “składowe, które łączą w sobie możliwość przechowywania danych oraz wykonywania operacji”. Chodzi o to by mechanizm, o dowiedzionej poprawności, zaimplementować w określonej wybranej technologii.Chodzi też o to by nie udawać, że programowanie jako “podzielone na obiekty” partie kodu, nadal korzystające z jednej wspólnej bazy danych, różni się czymkolwiek od “strukturalnego kodu”. Chodzi o to by kod programu faktycznie implementował określony (zbadany i opisany) mechanizm. (źr.: Architektura kodu aplikacji jako pierwszy etap tworzenia oprogramowania – Jarosław Żeliński IT-Consulting)
W 2021 roku opisałem Architektoniczne wzorce projektowe w analizie i projektowaniu modelu dziedziny systemu. Artykuł jest ukierunkowany na ich definicje i modelowanie. Tu kilka słów na temat tego “skąd się biorą i po co”.
Od wielu lat mamy do czynienia z dwoma akronimami: OOP i OOAD. OOP to Object-oriented Programming, OOAD to Object-oriented Analysis and Design. Popatrzmy na te definicje:
Programowanie obiektowe (OOP) to paradygmat programowania oparty na koncepcji obiektów, które mogą zawierać dane i kod: dane w postaci pól (często nazywanych atrybutami lub właściwościami) oraz kod w postaci procedur (często nazywanych metodami). W OOP programy komputerowe są projektowane poprzez tworzenie ich z obiektów, które wchodzą ze sobą w interakcje. Wiele z najczęściej używanych języków programowania (takich jak C++, Java i Python) jest wieloparadygmatowych i obsługuje programowanie obiektowe w mniejszym lub większym stopniu, zazwyczaj w połączeniu z programowaniem imperatywnym, programowaniem proceduralnym i programowaniem funkcjonalnym. (https://en.wikipedia.org/wiki/Object-oriented_programming)
oraz
Analiza i projektowanie obiektowe (OOAD) to techniczne podejście do analizy i projektowania aplikacji, systemu lub firmy poprzez zastosowanie programowania obiektowego, a także wykorzystanie modelowania wizualnego w całym procesie tworzenia oprogramowania w celu kierowania komunikacją z interesariuszami i jakością produktu. OOAD w nowoczesnej inżynierii oprogramowania jest zwykle prowadzone w sposób iteracyjny i przyrostowy. Wynikiem działań OOAD są odpowiednio modele analityczne (dla OOA) i modele projektowe (dla OOD). Intencją jest, aby były one stale udoskonalane i ewoluowały, napędzane kluczowymi czynnikami, takimi jak ryzyko i wartość biznesowa (https://en.wikipedia.org/wiki/Object-oriented_analysis_and_design)
Zakładam, że czytelnik dostrzega tę subtelną różnicę: OOP to implementacja, OOAD to analiza i projektowanie, która powinna poprzedzać tę implementację. OOAD jest całkowicie niezależna od narzędzi implementacji. OOP to języki programowania…
Problem złożoności kodu
O co cały ten ambaras? Kodu jest coraz więcej a logika aplikacji coraz bardziej skomplikowana. Teza, że można efektywnie kodować “z palca” od dawna jest utopią. Program komputerowy to seria instrukcji, które realizują procedury i algorytmy. jak jest ich kilkanaście to problemu nie ma, jak kilkadziesiąt czy kilkaset, to jest troszkę pracy (na ekranie komputera koder przeciętnie widzi 40 do 100 linii). Ale przeciętny średni czy duży system to dziesiątki i setki tysięcy linii kodu. Strukturalne programowanie (paradygmat) radziło sobie z tym tak, że program dzielono na podprogramy, czyli wydzielone części kodu mające nazwę i możliwe do wywołania po tej nazwie, nadal jednak był to “jeden kod”. Powstała idea, by te podprogramy uczynić samodzielnymi programami, które mogą się wywoływać między sobą. Powstała idea federacji samodzielnych prostych programów, każdy niezależny od siebie i samowystraczlany w swoim zakresie.
Tak naradziła się idea paradygmatu obiektowego opracowana przez Alana Kay’a . Istotą tego paradygmatu są samodzielne programy (obiekty) i komunikacja między nimi. Cechą tego paradygmatu jest hermetyzacja i wzajemna wymiana komunikatów, konsekwencją hermetyzacji jest polimorfizm: wynik pracy obiektu jest jego cechą czyli to co uzyskamy nie zależy od treści polecenia a od tego komu je wydamy.
Programowanie stało sie więc projektowaniem:
Programming is not solely about constructing software—programming is about designing software.
Projektowanie to pogrupowanie procedur i algorytmów w obiekty, opracowanie struktury tych obiektów oraz scenariuszy ich komunikacji. Rozbudowane system grupują te obiekty w komponenty dziedzinowe. To architektura LLD. Komponenty grupujemy w aplikacje. Nazywamy to architekturą HLD.
Proces analizy i projektowania realizuje analityk/projektant/inżynier oprogramowania.
Inżynierowie oprogramowania oceniają potrzeby klienta lub firmy w połączeniu z potrzebami użytkownika i konceptualizują rozwiązanie. (https://builtin.com/recruiting/software-engineer-vs-programmer)
Analiza potrzeb klienta bardzo często polega na opracowaniu modelu (mechanizmu) działania analizowanej organizacji. Tak powstaje model CIM organizacji. Na tym etapie określamy komu i do czego potrzebne jest oprogramowanie (a konkretnie komputer). Mając te potrzeby projektowane jest oprogramowanie. Jest to system: jego architektura oraz zagnieżdżone w niej procedury i algorytmy. To model PIM systemu. Jest on wymaganiem dla dewelopera:
Koderzy piszą kod i debugują błędy w programach i oprogramowaniu w oparciu o instrukcje od inżynierów oprogramowania. Są zaangażowani w pojedynczy etap cyklu rozwoju i koncentrują się na jednym komponencie naraz. (https://builtin.com/recruiting/software-engineer-vs-programmer)
Projekt PIM można zaimplementować w dowolnej technologii, w dowolnym języku programowania. Może istnieć wiele równoprawnych implementacji systemu:

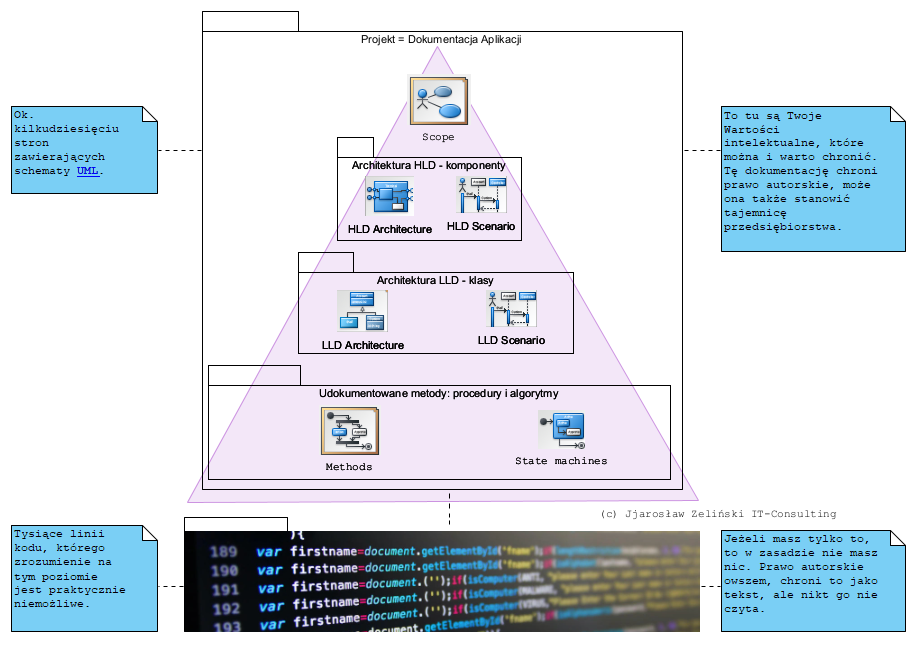
Dlatego przedmiotem ochrony coraz częściej nie jest kod (który kiedyś powstał od razu jako pierwszy) a projekt PIM. Sam kod źródłowy, a może to być kod w dowolnym języku programowania, jest traktowany coraz częściej jako narzędzie konfiguracji komputera, który jest uniwersalnym urządzeniem elektronicznym składającym się z procesora, pamięci i wyposażonym w wejścia i wyjścia takie jak klawiatura, ekran, porty komunikacyjne itp. . To czym on jest (mechanizm jaki realizuje) zależy od tego jak go skonfigurujemy, a narzędziem konfiguracji jest kod źródłowy (PSM/PSI), który de facto reprezentuje mechanizm opisany modelem PIM . Kod źródłowy to implementacja (wykonanie) produktu a nie projekt/model/opis produktu . Kod źródłowy nie jest dokumentacją produktu, jest produktem. Tak jak działający samochodów jest działającym samochodem a nie dokumentacją tego samochodu.
Ten artykuł opisuje powstawanie modelu PIM.
Obiektowo zorientowany system czyli co
Kowalski, posprzątaj pokój nr 15“Kowalski” to nazwa elementu systemu (obiektu), “posprzątaj” to rozkaz jaki mu wydaliśmy (operacja), “pokój nr 15” to parametr tego polecenia. Gdyby było prawdą, że istnieje tylko jedno pomieszczenie a polecenie sprzątania z zasady dotyczyło by sprzątania pomieszczeń, wystarczyło by:
Kowalski, posprzątajTak zwane dobre praktyki zalecają, by taki element systemu był wąsko specjalizowany. Innymi słowy element systemu powinien “służyć do jednej rzeczy” (co nie znaczy, że ma to być jedna operacja), która może być prosta do wykonania lub skomplikowana, ale “służy tylko do jednego” (nazywamy to wąskim interfejsem ).
Taki element systemu w językach zorientowanych obiektowo nazywamy obiektem, a jego definicję w kodzie źródłowym: klasą. Polecenie na jakie reaguje obiekt to “operacja”, a procedura lub algorytm uruchamiany tym poleceniem to “metoda”. Obiekt może mieć możliwość “pamiętania” jednej lub więcej “rzeczy”, nazywamy je (troszkę nieszczęśliwie) atrybutami. Obiekt to elementarny, niepodzielny element systemu. To co obiekt pamięta i co potrafi generalnie nazywamy cechami obiektu.
Problem w tym, że z perspektywy takiego języka (czyli także kodera) nie istnieje nadrzędny element grupujący obiekty by utworzyć nadrzędne elementy architektury: kod źródłowy to tylko klasy, definicje obiektów i metod, i nic ponad to. Te obiekty wywołują wzajemnie swoje operacje i formalnie każdy może wywołać każdy inny. W kodzie nie ma nadrzędnych elementów grupujących, aby je mieć trzeba je świadomie, celowo i sztucznie tworzyć (niektóre języki pozwalają na ograniczanie dostępu do operacji, które mogą mieć cechę: public, package, protected, private).
Wielka bryła błota
Niedawno mnie student zapytał, jak uniknąć spaghetti kodu zwanego nieraz “death-star architecture” lub “big ball of mud“. Na czym polega problem? Na tym, że mając grupę kilkuset klas i brak obrazu ich architektury, w zasadzie nikt nad tym nie panuje. Jeżeli ktoś zaczyna tworzenie aplikacji od razy od pisania kodu źródłowego, to w zasadzie taki spaghetti kod jest to nie do uniknięcia.
Co można zrobić? Jak ogarnąć setki a bywa, że tysiące obiektów? Tak jak kilka tysięcy ludzi (obiekty) mających swoje wąskie kompetencje i obowiązki. Dzielimy ich (rozsadzamy) na pokoje, te grupujemy w korytarze/działy, a te organizujemy jako budynki.
Co osiągamy? To, że wymuszamy uporządkowaną komunikację: najpierw idź do właściwego budynku (branża), potem do właściwego korytarza (dziedzina), potem pokój (typ sprawy) i w końcu konkretny specjalista coś zrobi. Wynik pracy wróci tą samą drogą.
Po co tak to “komplikować”? To proste: zarządzanie sprawami rzucając je na pożarcie setkom ludzi na płaskiej płycie lotniska jest po prostu nieefektywne. Dodatkowo wymaga obdarzenia każdego człowieka wiedzą co i kiedy ma zrobić oraz komu to przekazać. Jak dodamy do tego zmienność typów tych spraw, to mamy dramat zwany “death star”.
Z perspektywy systemu nazywamy to jego architekturą, a tę dzielimy na architekturę HLD (ang. High-Level Design, architektura wysokiego poziomu, “budynki, korytarze, pokoje”) i LLD (ang. Low-level design, czyli to co w “pokoju”).
Dlatego projektując nawet średniej wielkości system informatyczny złożony z jednej lub kilku aplikacji:
- najpierw projektujemy architekturę całego systemu zbudowaną z integrowanych aplikacji,
- potem komponenty architektury HLD każdej aplikacji,
- potem architekturę LLD każdego komponentu,
- teraz zlecamy kodowanie (implementację) każdego komponentu.
Czy to jest ten straszny wodospad i obowiązek zaprojektowania detali całości itp…? Nie, bo to nie jest monolit: mając HLD i pierwszy komponent, zlecamy jego kodowanie i oddanie do użytku. Następnie spokojnie doprecyzowujemy opisy i zlecamy kolejne komponenty, detale ustalamy ” na ostatni moment” przed zleceniem implementacji kolejnego komponentu. Typowa interacyjno-przyrostowa metoda tworzenia systemu.
Co osiągniemy ta metodą? Przetestowane (testujemy logikę już na etapie projektowania) i aktualizowane modele architektury oraz kod działający “od pierwszego razu”. A przede wszystkim BARDZO NISKIE koszty utrzymania i rozwoju.
Tworzenie dokumentacji kodu dopiero po osiągnięciu stanu, w którym on działa i został odebrany ma taki sam sens jak dokumentowanie gwiazdy śmierci dopiero po tym jak powstała.
Role, odpowiedzialność i współpraca
Jedną z najlepszych książek o dziedzinowej analizie problemu i projektowaniu oprogramowania napisała Rebecca Wirfs-Brock, która nadal aktywnie działa na rzecz inżynierii oprogramowania prowadząc szkolenia i warsztaty pod hasłem: Responsibility-Driven Software Development. Ta książka to:
Object Design: Roles, Responsibilities, and Collaborations, with Alan McKean. Addison-Wesley, 2003, ISBN 0-201-37943-0. (wersja Polska: ), First printing, November 2002.
Autorka tak definiuje kluczowe elementy projektu:

Aplikacja – zestaw współpracujących (mają interakcje) elementów (obiektów)
Obiekt – realizuje rolę (ewentualnie kilka ról)
Rola – realizacja określonego zadania, odpowiedzialność
Współpraca – interakcje między obiektami
Kontrakt – opis zasad współpracy
Co to znaczy? To znaczy, że przed kodowaniem należy dobrze przemyśleć to jak aplikacja złożona z wielu elementów na działać.
Architektura HLD i LLD
Co zaleca autorka w swojej książce? Wzorce architektoniczne i dobre praktyki. Podstawowa zasada: separacja obszarów odpowiedzialności. Tymi obszarami są: elementy odpowiedzialne za interakcje z ludzkim użytkownikiem (Presentation), elementy odpowiedzialne za realizacje usług aplikacji (Application Services), specjalizowane elementy wykonawcze (Domain Services), środowisko (Technical Services). U Wirfs-Brock wygląda to tak:
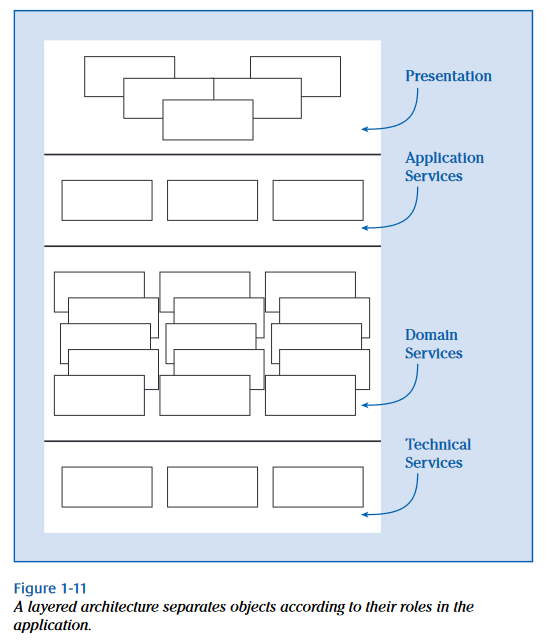
Wielu autorów używa pojęcia “warstwa” na wskazanie tych obszarów, jednak bywa to mylące bo tak zobrazowana architektura sugeruje “kanapkową” postać architektury co realnie nie mam miejsca. Popatrzmy jak to pokazują autorzy 20 lat po wydaniu książki Wirfs-Brock:
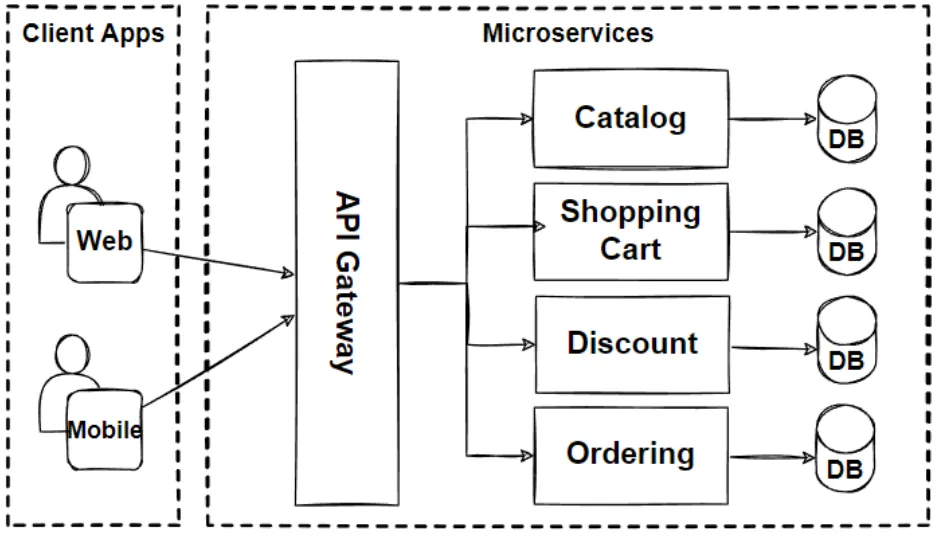
(https://medium.com/design-microservices-architecture-with-patterns/microservices-architecture-for-enterprise-large-scaled-application-825436c9a78a, Feb 17, 2023)
Jest to dokładnie to samo, tu pokazane poziomo. Czytelnikowi, w ramach ćwiczenia, zostawiam identyfikację “warstw” na powyższym diagramie.
Kolejna dobrą praktyką jest separacja aplikacji od środowiska w jakim sie ona wykonuje. U Wirf-Brock mamy warstwę nazwaną Technical services. Dla jasności pierwsze trzy warstwy Wirfs-Brock to aplikacja, ostatnia: Technical Services to właśnie środowisko. W w tam samym czasie, gdy wydano książkę Wirfs-Brock, doktorat obronił Alistair Cockburn (2003). Opublikował wzorzec architektoniczny, który nazwał Architektura Hexagonalna (obecnie zwana Porty i Adaptery):
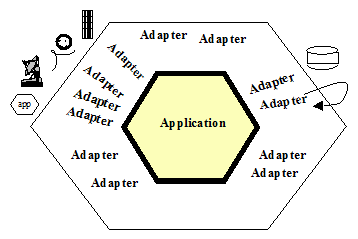
Jak widać Ten prosty diagram pokazuje dwa obszary: Aplikacja i Adaptery do środowiska. Po 20 latach autorzy nadal zalecają te architekturę:
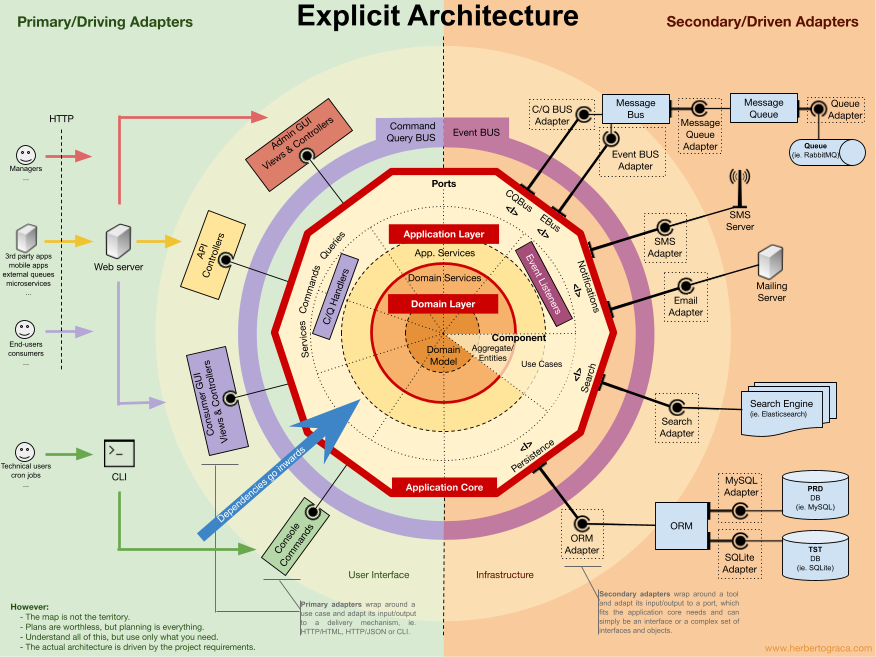
Środowisko aplikacji to system operacyjny, środowisko uruchomieniowe (standardowe biblioteki), adaptery do infrastruktury.
Powyższe to architektura heksagonalna, zawsze pokazywana z góry wygląda jak meksykaniń w kapeluszu, z boku wygląda tak”

Schematycznie wygląda to tak:
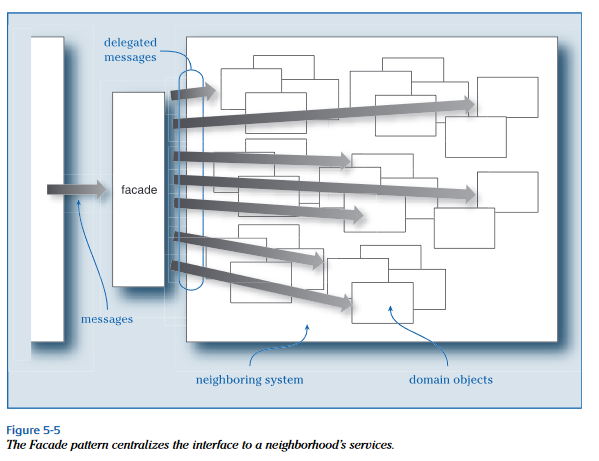
Fasada to komponenty realizujące scenariusze realizacji usług aplikacji. Są uruchamiane komunikatami z warstwy prezentacji (menu główne aplikacji). Komponenty, którymi zarządza Fasada to lokalne elementy dziedzinowe i zewnętrzne (integrowane) aplikacje (np. nasz system CRM pobiera dane podmiotów z GUS).
Projektowanie i testowanie architektury HLD polega na modelowaniu tych scenariuszy:
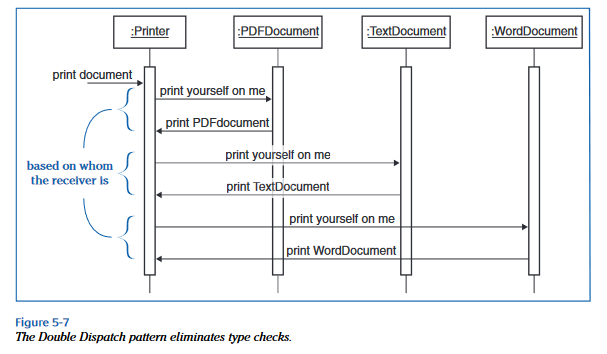
Powyższe to diagram sekwencji UML.
Po co nam architektura?
Generalnie do komunikacji oraz do zrozumienia. Projekty w obszarze inżynierii to dialog między interesariuszami projektu. Kluczowi interesariusze projektu to: sponsor, użytkownik, projektant, wykonawca. Dialog sponsor-projektant Wirfs-Brock pokazuje to jako analogię innej, najstarszej inżynierii, w następujący sposób:

Ogólnie dialog z interesariuszami pokazuje tak:

Rzecz w tym, by do interesariuszy mówi w języku dla nich zrozumiałym: makiety. Co do zasady interesariusze nie rozumieją kodu źródłowego, więc nie będą go czytali. Pokazanie im działające oprogramowania jest bardzo kosztowne. Wprowadzanie do niego zmian po uwagach jest także bardzo kosztowne. Pozostaje więc modelowanie i pokazywanie modeli.
Modelowanie kodu architektury LLD
Kodowanie i testowanie kodu to najkosztowniejsza część projektu dlatego należy je “odłożyć na sam koniec”. Co zamiast kodowania? Wirfs-Brock jest znana między innymi z metody wstępnej analizy obiektowej opartej na tak zwanych kartach CRC (ang. Class Responsibility Collaborator, Klasa, Odpowiedzialność, Współpracownik), która jest zaliczana do zwinnych metod projektowania.
Są to kartoniki, które mają trzy kluczowe pola: Nazwa, operacje (odpowiedzialność obiektu), nazwy innych obiektów wywoływanych z własnych metod. Poniżej prosty przykład:

Karty CRC mogą pomagać koderom, reprezentują obiekty (klasy), można je układać na stole lub tablicy. Mogą być pomocne jak etap poprzedzający kodowanie. Jednak nadal jest to poziom LLD a karty nie obrazują związków użycia. Podobnie jak w kodzie, trzeba się wczytywać w wywołania. Np. to co wygląda tak w postaci kart CRC:

To samo z użyciem UML:

Architektura HLD
Wyobraźmy sobie teraz , że tych klas jest nie kilka a kilkaset a w kodzie nie ma “kresek” i “strzałek”. Po prostu ktoś Wam ułożył kilkaset kart CRC jedna za drugą, jak kartki w książce (tak wygląda kod źródłowy, to jest dokument jak książka). I wyobraźcie sobie, że jest to opis systemu, opis jakiegoś mechanizmu działania czegoś. Np. ktoś opisał prozą wnętrze mechanicznego zegarka, a taki zegarek to tylko ok. 30 kółek zębatych.
Czy patrząc na działający zegarek można opisać go prozą? Można. A czy można od zera zaprojektować zegarek prozą? A to tylko zegarek. Wyobraź sobie czytelniku, że jest to samochód albo biurowiec w centrum miasta. I teraz sobie wyobraź, że ta proza to jedna długa procedura dla zegarmistrza lub budowniczego.
Jako ludzie używamy komputera a nie oprogramowania. Komputer (np. Wasz notebook lub smartfon którego używanie by przeczytać ten tekst) to urządzenie, w którym większość (ale nie wszystkie) kółek zębatych – mechanizm – zastąpiono procesorem, pamięcią i programem w tej pamięci . Komputer “odtwarza” (realizuje) mechanizm działania zegarka, systemu sterowania wtryskiem paliwa w silniku spalinowym, a także mechanizm zarządzania treścią faktur w szafach, czy mechanizm wyboru produktów w sklepie, zapłaty za nie i zlecania dostarczenia ich pod wskazany adres. Wyobraźcie sobie, że macie setki kart CRC i to jedyne wasze narzędzie na etapie projektowania tych systemów.
A teraz…
Jeżeli jednak zaczniecie myśleć o systemie jak o mechanizmie, to będzie możliwe jego projektowania od ogółu do szczegółu. Najpierw zastanowimy sie jakie usługi aplikacja ma świadczyć. Typowa usługa to konkretny dziedzinowy element (patrz także DDD i modelowanie dziedziny systemu w UML) np. faktura, karta produktu czy magazyn. W obecnej sytuacji firm i organizacji żadna aplikacja nie jest samotną wyspą, współpracuje z zewnętrznymi systemami. Wielodziedzinowy system będzie miał taką architekturę HLD:

Każdy z komponentów to raz kilka a raz kilkanaście klas, rzadko więcej (nie idziemy tropem niektórych podręczników mówiących, że każda operacja to osobna klasa, to bardzo zły pomysł). Każdy z komponentów to samodzielny element systemu i ma swoją własną wewnętrzną architektura LLD:

Takie podejście daje nam komfort zrozumienia działania całego systemu, bez względy na jego wielkość. Warto zwrócić uwagę, że nie modelujemy to w ogóle środowiska aplikacji. Dlaczego? Bo ono już istnieje! Środowisko dla projektanta jest tym samym co każda inna zewnętrzna aplikacja: korzystany z niego przez “porty i adaptery” (patrz wyżej architektura heksagonalna).
Całość w dowolnym momencie testujemy z użyciem diagramów sekwencji. A kiedy używamy diagramów aktywności? W większości przypadków nie ma takiej potrzeby. Sytuacje, w których wnoszą one wartość w dokumentacji to modele skomplikowanych algorytmów (patrz wyżej: metody operacji klas) lub poglądowe modele działania systemu (patrz Stosowanie diagramów aktywności w UML).
Dekompozycja funkcji Warnier/Orr diagram
Dość popularna jest tak zwana dekompozycja funkcji. Jest to strukturalna metoda opisu procedur w postaci drzewa. Znamy to także jako “mapy myśli”.
Inną, bardzo znaną w branży IT wersją tego podejścia jest Diagram Warniera/Orra (znany również jako logiczna konstrukcja programu/systemu), która jest rodzajem hierarchicznego schematu blokowego umożliwiającego opis organizacji danych i procedur. Metoda ta, opracowana w 1976 roku, pomaga w projektowaniu struktur programowych poprzez identyfikację wyników wyjściowych i wyników przetwarzania, a następnie pracę wstecz w celu określenia kroków i kombinacji danych wejściowych potrzebnych do ich wytworzenia. Poniżej przykład takiego modelu:

Metoda ta, nadal spotykana, ma jednak potężną wadę: tak tworzony system jest monolitem a rozpoczęcie implementacji oprogramowania jest możliwe dopiero po ukończeniu projektowania całego tego drzewa. Biorąc pod uwagą ścisłą wzajemną zależność wszystkich poziomów, każda ingerencja w tę strukturę jest ingerencją w całość. Dlatego oprogramowanie, gdzie kod ma taką strukturę, jest bardzo kosztowne w wytworzeniu i nie miej kosztowne w okresie utrzymania i rozwoju. Obiektowe i komponentowe metody projektowania architektury są właśnie lekarstwem na ten problem.
Podsumowanie
Modelowanie architektury przed kodowaniem to podstawowy etap pracy każdego projektanta i architekta. Pozwala szybko i niskim kosztem zrozumieć problem, rozwiązać go i podzielić pracę na członków zespołu koderów. Robert C. Martin (jeden z najbardziej znanych sygnatariuszy Agile Manifesto), pisze w swojej książce :

Projekt aplikacji z zasady jest także jej dokumentacją, gdy ona już powstanie. Zarzuty, że “przecież to się zmienia w czasie tworzenia” nie mają sensu, bo wprowadzanie zmian odbywa się najpierw na modelach (testowanie pomysłu) a potem dopiero w implementacji. Biorąc pod uwagę fakt, że testy modeli są o rząd, a nawet dwa rzędy, mniej kosztowne, tezy że metody agile dają efekty szybciej i taniej nie znajdują żadnego potwierdzenia a tu ani w praktyce.
agile: Odnoszący się do lub oznaczający metodę zarządzania projektami, stosowaną zwłaszcza do tworzenia oprogramowania, która charakteryzuje się podziałem zadań na krótkie etapy pracy oraz częstą ponowną oceną i dostosowywaniem planów.
“metody zwinne zastępują projektowanie na wysokim poziomie częstym przeprojektowywaniem”
(źr.: Dictionary Definitions from Oxford Languages)
Architektura LLD i struktura kodu to diagram klas UML:
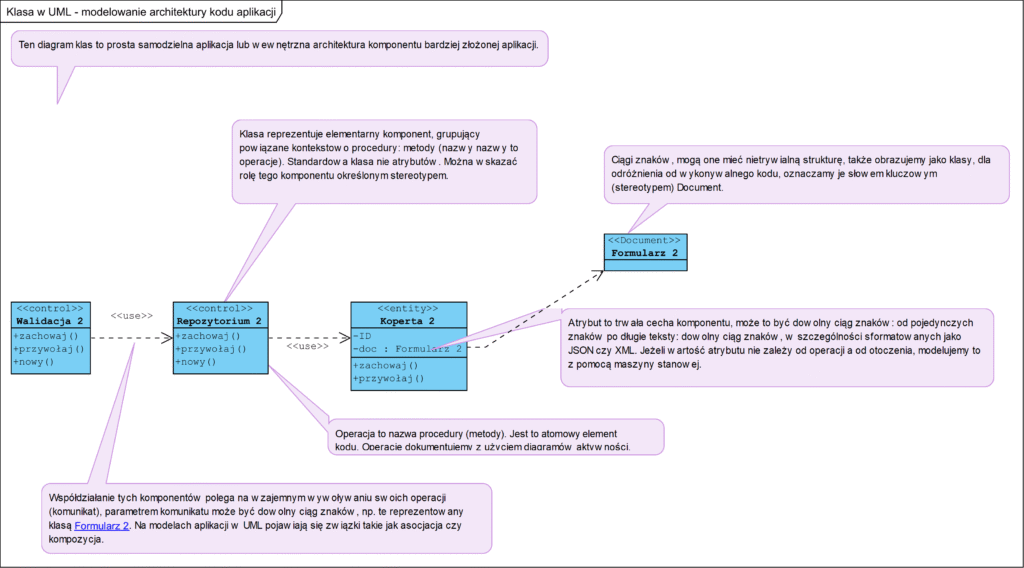
Jaki ma sens dokumentowanie kodu, który powstał jako pierwszy etap projektu? Powstanie dokumentacja setek klas i być może schemat ich współpracy, ale to nadal jest sterta kart CRC na płaskim stole nic nie mówiąca o podziale złożonego systemu na odrębne aplikacje i ich komponenty. Zrozumienie mechanizmu działania aplikacji nadal nie jest możliwe, do tego potrzebna jest architektura HLD.
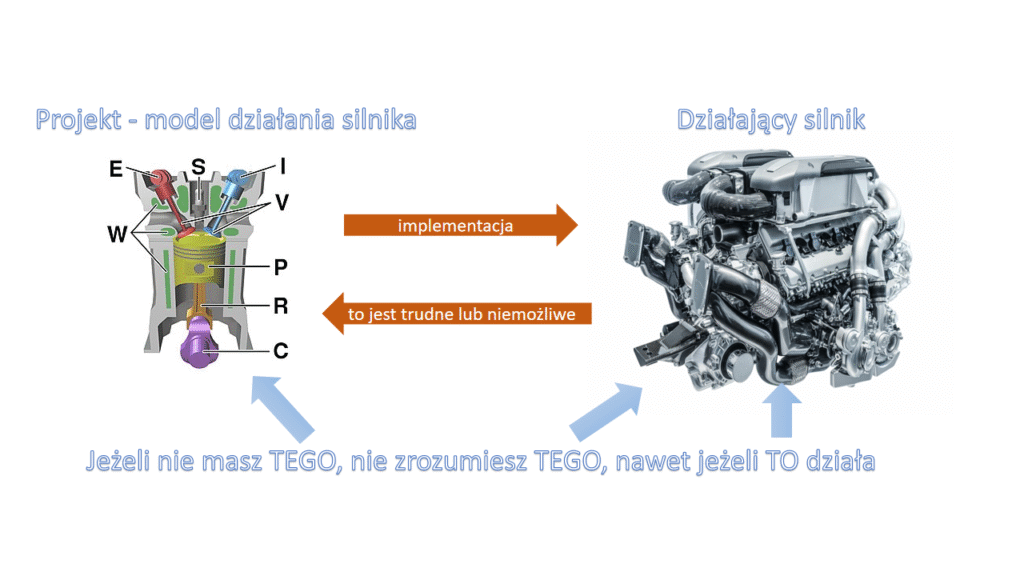
Książka Wirfs-Brock zawiera wiele przykładów, w kodzie ale także w UML. Polskie wydanie od dawna jest dostępne tylko w bibliotekach i antykwariatach, kolejne wydania oryginału są nadal do kupienia. Poniżej obrazowe wyjaśnienie tego, że model “w kilku słowach” wyjaśnia to czego nie powiedzą tysiące linii kodu, tego że “code first” nie ma większego sensu:
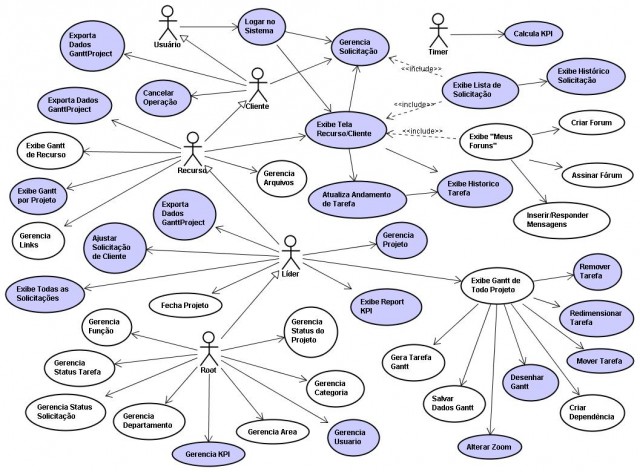
Na tle powyższej wiedzy, dostępnej od czasów powstania UML w latach 90tych, w 2018 rok “pojawia się” Simon Brown i jego Architektura C4, która w zasadzie jest ponownym odkryciem koła.



Wzorzec fasada to saga?
Nie, Fasada to interfejs hermetyzujący złożoną strukturę “za plecami” a Saga to wydzielenie i umieszczenie scenariusza pracy kilku komponentów (np. scenariusza przypadku użycia) w jednym miejscu, dzięki czemu eliminujemy wzajemne wywołania między komponentami dziedzinowymi. Dość często funkcję te realizuje jeden i ten sam komponent tak jak na jedynym z diagramów tu pod nazwą API Gateway.
Czy wobec tego fasada będzie pojedynczą klasą, która skupia w sobie wywołania metod innych komponentów (interfejsów)?
Z reguły tak (BTW: wywołujemy operacje, metoda to implementacja operacji), ale tu pojawia się także wariant z separacją interfejsów, wtedy takich fasad może być kilka.
Aktualizacja: dopisałem wstęp o OOP i OOAD.
Dodałem rozdział Problem złożoności kodu