Wprowadzenie
Od czasu do czasu dostaję emaile rozpoczynające się od słów: “A tu programista i pisze inaczej”. Tym razem dostałem od czytelnika link do tekstu Diagramy klas UML https://web.archive.org/web/20240428033730/https://www.p-programowanie.pl/uml/diagramy-klas-uml).
Artykuł ten w zasadzie w całości jest lawiną nieprawdy o UML. Odniosę się do części dotyczącej notacji UML i powiązanych z nią fałszywych treści. Wszystkie cytaty pochodzą z ww. artykułu (inne oznaczono, źródłami).
Recenzja
Artykuł jest datowany na 30 września 2022. Aktualna wersja notacji UML 2.5.1 pochodzi z Grudnia 2017 roku, kluczowe zmiany: rezygnacja z podziału na Superstructure i Infrastructure, usunięcie pojęć dziedziczenia i agregacji od wer. 2.5.0 wydanej w 2015 roku.
Język UML jest językiem służącym do graficznego modelowania aplikacji oraz systemów. Najczęściej wykorzystywany jest do modelowania diagramów klas.
Kluczowe diagramy UML: diagram przypadków użycia, diagram komponentów, diagram klas, diagram sekwencji, diagram maszyny stanowej (patrz artykuł o ICONIX…). Same diagramy klas nie wiele wnoszą jako modele.
Na diagramie UML nie da się zawrzeć wszystkich informacji o danej klasie. Gdyby tak było, wtedy diagramy klas byłyby graficzną reprezentacją kodu – a tak nie jest. Jeżeli w diagramie klas nie ma jakiegoś składnika, to nie można zakładać, że takowy nie istnieje w modelowanej aplikacji.
Jest to nieprawda. Istniejący kod można automatycznie odwzorować jako diagramu UML bo diagramy klas reprezentujące kod SĄ jego projektem lub odwzorowaniem. To, że na diagramie UML nie ma jakiegoś składnika kodu jest możliwe: implementacja często zawiera detale języka programowania, istotne dla tej implementacji ale nie istotne dla mechanizmu działania aplikacji (np. specyficzne dla danego języka typy danych).
Każdy obiekt reprezentowany jest przez jeden prostokąt, w którym zawarte są jego składniki. W prostokącie może znajdować się nazwa elementu, nazwa elementu wraz z polami bądź wszystkie składniki, czyli: nazwa, pola i metody.
W UML klasa to nazwa. Klasyfikator to “prostokąt” zawierający: nazwę, atrybuty, operacje. Metody to algorytmy i procedury, operacje to nazwy pozwalające te procedury wywoływać. Atrybuty są opcjonalne.
Implementację interfejsu do danej klasy oznacza się pustym białym grotem strzałki, który znajduje się na końcu przerywanej linii.
Nie ma czegoś takiego w UML. Mamy związek generalizacji stosowany w modelach pojęciowych (poniżej po prawej) i związek realizacji wiążący specyfikację z jej realizacją (poniżej po lewej). Interfejs to po po prostu publiczne operacje klasy. Jeżeli chcemy możemy go wydzielić w postaci osobnej klasy (wzorzec fasada).

Powyższy rysunek: po lewej jest związek realizacji, po prawej dziedziczenie usunięte z UML w 2015 roku. Dziedziczenie nadal jest dostępne w tak zwanych obiektowo-zorientowanych językach programowania, jest to sposób na re-użycie kodu, bardzo szkodliwy z perspektywy architektury (np.: Inheritance Is Evil. Stop Using It).

Zależność oznacza “uzależnienie” bez podawania jego przyczyny. Nie ma “chwilowego używania”, jest “użycie” (wywoływanie operacji) i wtedy zależność ma postać:

Powyższy związek bywa nazywany “master – slave” (slave to komponent wywoływany) lub klient- serwer (klient wywołuje usugi serwera).
Standardowa asocjacja to ciągła linia bez strzałek i oznacza ona wyłącznie “jakiś związek” na modelach pojęciowych. W postaci pokazanej u autora jest obecnie praktycznie niewykorzystywana.
Nie ma czegoś takiego jak “agregacja częściowa” była w UML “agregacja” (pusty rombik na końcu linii i oznaczał “współdzielenie” ang. shared element) i została usunięta z UML w 2015 roku. Nie ma czegoś takiego jak “agregacja całkowita”, jest kompozycja (związek całość-część). W UML od 2015 roku nie ma związku dziedziczenia.
Asocjacja pokazana tak:

oznacza tak zwaną widoczność: klasa Karol może wywoływać klasę Firma (jest w jego zasięgu). Poprawna forma wyrażenia tego:
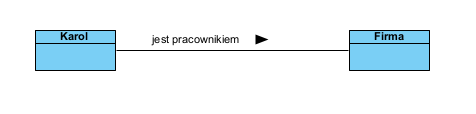
I jest to związek pojęciowy (słownikowy).
Dziedziczenie (ang.
inheritance) jest głównym filarem paradygmatu programowania obiektowego.
Dziedziczenie jest antywzorcem i nie jest “filarem” paradygmatu obiektowego:
Na diagramie klas UML możemy umieścić także klasę zagnieżdżoną. Jej symbolem jest puste kółko z czarnym krzyżykiem.
Diagram należy czytać w następujący sposób: klasa Silnik jest zagnieżdżona w klasie Samochód.
Nie ma w UML pojęcia “zagnieżdżenie”, jest “zawieranie się” i jest to kompozycja. Poprawna konstrukcja:

Związek zawierania:

służy to łączenia elementy grupującego z elementami grupowanymi. Jest używany na modelach PIM (ang.: Platform Independent Model, Model niezależny od platformy)
Podsumowanie
Niestety w sieci jest wiele podobnych tekstów pisanych przez koderów. Ich autorzy piszą nieprawdę wprowadzając swoich czytelników w błąd. Takie artykuły jak tu komentowany budują ogromną, niezasłużoną, niechęć do notacji UML.
Zapewne są konsekwencją cech języka programowania w jakim wyspecjalizował sie autor i dlatego często można spotkać określenie “myślnie kodem” wyjaśniające powstawanie takich artykułów. Jeżeli ktoś pisze i próbuje innych uczyć, to powinien sie skupić na tym co potrafi. Gdyby autor napisał artykuł o kodowaniu, zapewne byłoby ok. Niestety napisał artykuł o UML i modelowaniu, który to artykuł bardzo daleki jest od specyfikacji notacji UML i modelowania.
Autor nie podaje swoich danych ani źródeł tego co napisał: https://web.archive.org/web/20240404153739/https://www.p-programowanie.pl/prawa-autorskie, ani razy nie przywołał oryginalnej specyfikacji UML. To niestety częste na tego typu stronach z taką “wiedzą”.
Źródła
Object Management Group. (2017, December). Unified Modeling Language (UML) [OMG.org]. UML. https://www.omg.org/spec/UML/




ww. autor usunął dzisiaj swój artykuł, dostępna jest kopia: https://web.archive.org/web/20240428033730/https://www.p-programowanie.pl/uml/diagramy-klas-uml