Wprowadzenie
Ukazała się książka Prawo w IT. Praktycznie i po ludzku . Jako, że profesjonalnie zajmuję się tak zwanym IT, a z prawem dotyczącym IT mam ogromne doświadczenia jako biegły (ale prawnikiem nie jestem), ta książka od razu po wydaniu wylądowała się na moim biurku. Jak tylko zacząłem czytać zapadła decyzja: napisze recenzję. Czytam bardzo dużo, ale recenzuję (tu na blogu) książki bardzo dobre lub bardzo szkodliwe.
Autor książki, Szymon Ciach (profil LinkedIn: “Attorney-at-law | Counsel @Osborne Clarke Poland | IT & Data”.), profil na Cybergov.pl:
Patron medialny książki ITwiz.
Szymon Ciach
Counsel, Kancelaria Osborne Clarke Poland
Prawnik specjalizujący się w obszarze technologii oraz regulacji rynku finansowego. Posiada szerokie doświadczenie w przygotowywaniu i negocjowaniu umów IT (m.in. umowy wdrożeniowe, utrzymania i rozwoju systemów informatycznych, outsourcingu IT), zarówno na rzecz zamawiających, jak i dostawców. Jest ekspertem w zakresie wdrażania usług chmury obliczeniowej oraz outsourcingu IT w sektorze finansowym. Współtworzył standard wdrażania chmury obliczeniowej w bankowości “PolishCloud 2.0”, w roli Koordynatora Grupy Prawnej przy Związku Banków Polskich. Doradza również w budowie nowych modeli biznesowych na styku finansów i technologii (FinTech), w szczególności w zakresie wykorzystania technologii rozproszonego rejestru (DLT, blockchain). Absolwent WPiA Uniwersytetu Jagiellońskiego, członek Okręgowej Izby Radców Prawnych w Warszawie. Rekomendowany prawnik w sektorze TMT w Polsce (Legal 500 EMEA 2023). (https://cybergov.pl/prelegenci/szymon-ciach/)
Kluczowe pojęcia
W rozważaniach o znaczeniach pojęć od wielu lat kluczem jest tak zwany trójkąt semiotyczny, nazywany także trójkątem Ullmanna . Poniżej wersja tego trójkąta opisana w publikacji Towards a model for grounding semantic composition .
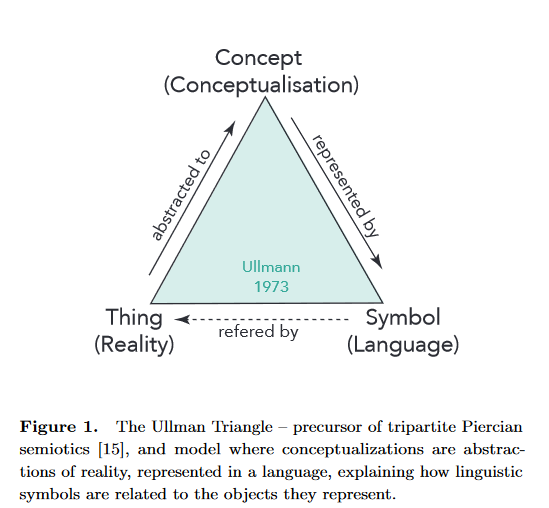
Mamy tu pojęcia Concept (ang. pojęcie, myśl, abstrakcja), Symbol (ang. symbol, znak, reprezentacja, litera oraz słowo z nich zbudowane), Thing (ang. określony przedmiot, sprawa, zdarzenie, coś a także coś do zrobienia) .
Odnosząc się do pojęć z dziedziny information science (pojęcia informatyka czy technologie informatyczne odnoszą się nieprecyzyjnie do tego co literatura naukowa nazywa w j. ang. information science oraz information technology).
Owszem, Słownik Języka Polskiego (SJP) podaje:
informatyka: «nauka o tworzeniu i wykorzystywaniu systemów komputerowych»
informacja 1. «to, co powiedziano lub napisano o kimś lub o czymś, także zakomunikowanie czegoś», 2. «dział informacyjny urzędu, instytucji», 3. «dane przetwarzane przez komputer»
dane 1. «fakty, liczby, na których można się oprzeć w wywodach» 2. «informacje przetwarzane przez komputer»
Tak więc mamy jednak rozróżnienie, które wielu autorów dostrzega .
Trójkąt semiotyczny, w odniesieniu do omawianych terminów, można więc przedstawić tak:
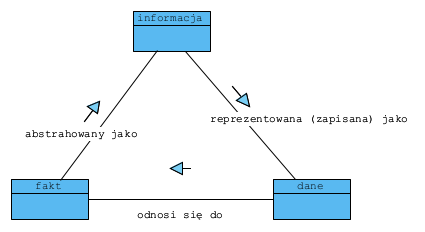
Jeśli mowa o „informacjach”, to obejmują one to, co powiedziano lub napisano o kimś lub o czymś, zakomunikowanie czegoś, także dane przetwarzane przez komputer – tak definiuje je Słownik języka polskiego. Informacje pochodzą z wyselekcjonowania danych tak, aby były użyteczne dla odbiorcy, niosą ze sobą jakiś sens i mają znaczenie dla człowieka.
Model pojęciowy omawianej dziedziny:
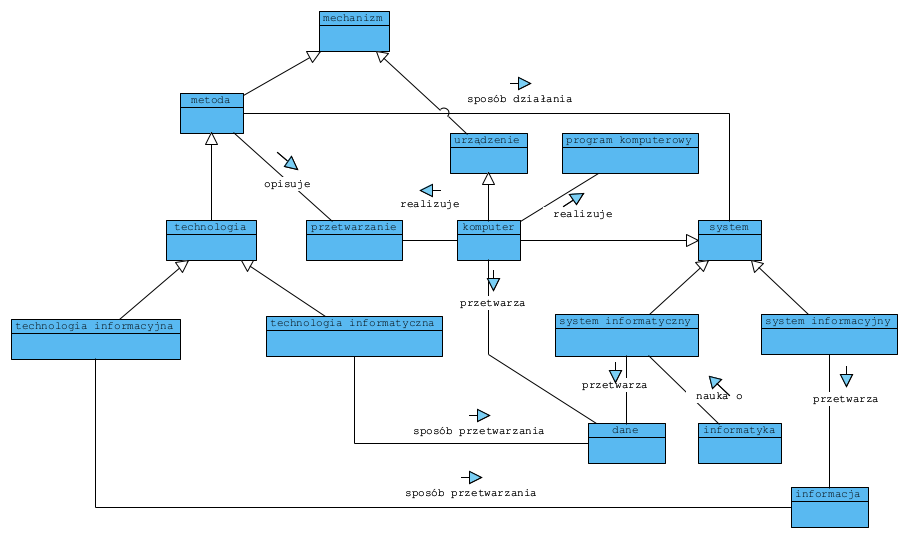
Model pojęciowy (ontologia) to model pozwalający zbudować i przetestować system pojęciowy. Definicje pojęć z powyższego modelu:

Cechą poprawnego modelu jest wzajemne wykluczanie się definicji pojęć oraz istnienie typów czyli specjalizacji. Definicja pojęcia to klasyfikator a rzeczy, które spełniają tę definicje to zbiór (taki jak w matematyce) . Poprawny dziedzinowy model pojęciowy (przestrzeń nazw) na diagramie Venna byłby modelem, w którym zbiory obiektów (things) są styczne i żadna granica zbioru nie przecina innej. Inną wersją testu poprawności jest prawo wyłączonego środka: “jeżeli coś jest czymś, to nie jest niczym innym” . Specjalizacja (typ) to podzbiór:
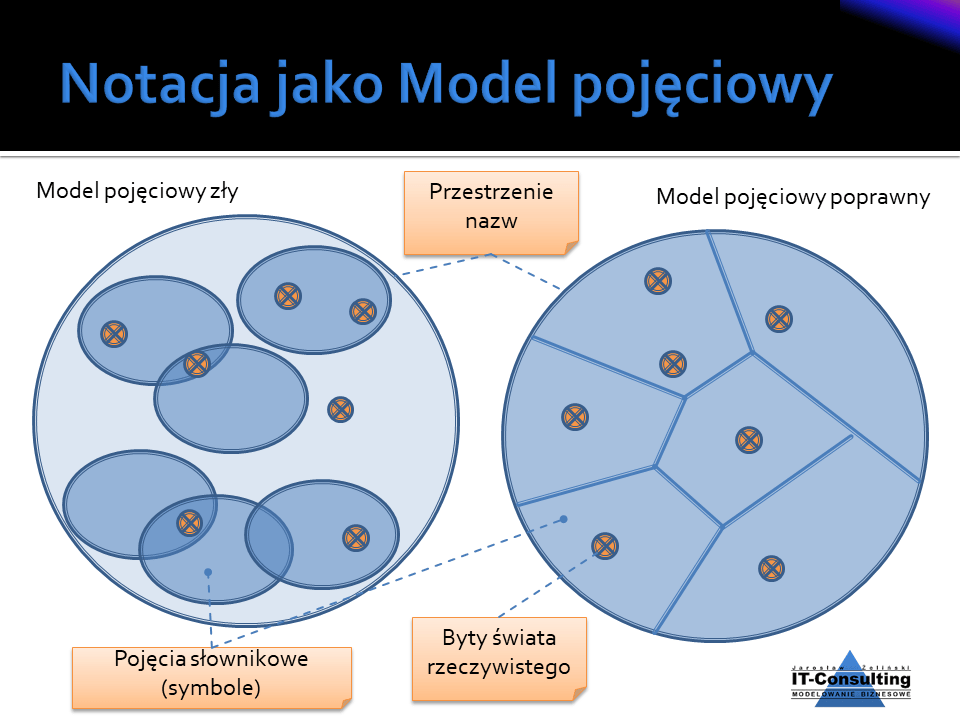
Na tym tle pojęcie technologie informatyczne mają sens, pojęcie technologie informacyjne w zestawieniu z tym, że informacja to jest to co zrozumiał człowiek, dotyczy wyłącznie procesów myślowych, czyli np. procesów wnioskowania czy “liczenia w pamięci”. Potocznie możemy sobie pozwalać na utożsamianie pojęć dane i informacje, ale w opracowaniach eksperckich, czy wręcz naukowych, już nie .
Autor pisze, że (str. 22)
“dane reprezentują fakty i same w sobie nie mają znaczenia. Natomiast informacje to dane, które przez interpretacje odbiorcy nabierają znaczenia…”.
Niestety takie podstawienie sprawy jest nielogiczne i pozbawione sensu. Ullmann i Eco jasno wykazują (trójkąt semiotyczny): dane to utrwalone znakami zapisy, a informacja to jest to co człowiek zrozumiał poznając je. Tak więc fakty (opis tego co zaszło) to informacja dla człowieka i dane jako utrwalone znaki i symbole. Zwracam uwagę, że encyklopedia w języku chińskim to na pewno dane, jednak niosą one informacje wyłącznie dla ludzi znających język chiński.
Jeżeli, jak pisze autor (str. 23), w kontekście prawnym pojęcia dane i informacje są używane jako synonimy to jest kardynalny błąd tych, którzy to czynią. Co ciekawe w następnym akapicie sam autor pisze, że konieczne jest “odróżnienie informacji od danych”.
Autor wplata znienacka pojęcie przepływu danych, ale nie wyjaśnia co ma to pojęcie wspólnego z danymi, ich ochroną i przetwarzaniem. Fakt zbierania danych osobowych nie jest przepływem danych, a co najwyżej ich utrwalaniem: ktoś informacje o sobie zapisuje (utrwala) w określonym formularzu na papierze lub ekranie komputera. Dostęp (człowieka) do danych to także nie jest przepływ danych. O przepływie danych możemy mówić wyłącznie wtedy, gdy są kopiowane z jednego nośnika na innych nośnik. I nie należy tego mylić ani utożsamiać z przepływem informacji (patrz encyklopedia w języku chińskim).
Stos technologiczny
Ten aspekt systemu informatycznego opisałem w artykule Sprzęt, środowisko, aplikacja, mechanizm. Tu zwrócę jedynie uwagę na kluczowe elementy. Autor prezentuje taką tabelę:

Autor definiuje “stos technologiczny” jako
sposób na opisanie opisanie zestawu technologii i narzędzi informatycznych mających jakiś wspólny mianownik
Autor nie podaje źródła tej kuriozalnej definicji. Najczęściej spotykaną definicją jest (trudno wskazać autora, Google pokazuje dziesiątki stron na to hasło):
stos technologiczny to zestaw elementów budujących stronę internetową lub aplikację. Są to język programowania, frameworki, systemy baz danych, biblioteki front-end i back-end oraz aplikacje połączone za pośrednictwem interfejsów API.
Po pierwsze stos technologiczny to nie aplikacja, ale ona oraz jej środowisko. Generalnie ten stos to sprzęt, sterowniki i szeroko pojęte oprogramowanie:
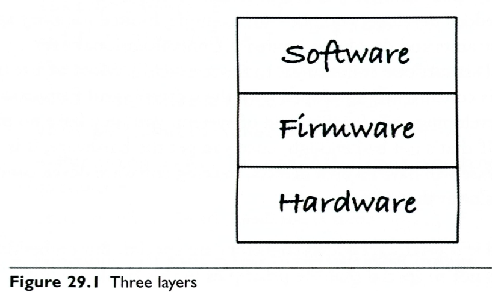
Jednak na użytek ochrony wartości intelektualnych w postaci oprogramowania (“Software”) dzielimy je (oprogramowanie) na odrębne aplikacje (SJP, aplikacja: komputerowy program użytkowy). Dlatego to co nazywamy stosem technologicznym przyjmuje bardziej skomplikowaną postać, bo pokazany tu Software to “frameworki, systemy baz danych, biblioteki front-end i back-end oraz aplikacje połączone za pośrednictwem interfejsów API”, i nie zapominajmy o systemie operacyjnym. O potrzebie separacji kodu aplikacji pisałem też w artykule Kastomizacja…
Duża nieprawda to dane jako osobna warstwa i to że są na szczycie tego stosu, bo jest odwrotnie: dane są na nośnikach a te, to hardware. Po drugie system operacyjny, oraz każda aplikacja, zarządza swoimi danymi niezależnie, więc nie są to “jedne dane”.
Autor stawia tezę, że dane to “podstawowy zasób świata IT” a zapomniał, że to za co płacimy najwięcej to aplikacje (np. system ERP) a nie dane. Po drugie często same dane na nośnikach są niemalże bezwartościowe bez logiki (procedury i algorytmy) ich przetwarzania.
Jak widać, dane są zawsze “na dnie” i NIGDY na szczycie “stosu”. Autor na str. 29 pisze, że pojęcie aplikacja stosuje się zamiennie z pojęciem system informatyczny co jest nieprawdą (patrz wyżej, model pojęciowy i stos technologiczny).
Na stronie 44 autor pisze o “środowisku informatycznym”. Najwyraźniej zapomniał czym jest stos technologiczny: TO jest właśnie to środowisko.
Nie miałem tu ambicji i nie było moim celem punktowanie wszystkich błędów, generalnie moim zdaniem cały rozdział Wprowadzenie to pasmo nieprawdy lub złych uproszczeń. Tytuł tego rozdziału to “Świat IT okiem prawnika”, jeżeli to prawda (tak prawnik rozumie IT) to jest to dowód na to, by prawnicy pozostali przy prawie, a inne informacje pozyskiwali, tak jak Sąd: od biegłych.
Umowy IT
Autor wprowadza pojęcie “Umowy IT” i z jednej strony sam stwierdza, że to umowy których przedmiotem są “technologie informacyjne”, zapominając że sam wskazywał na różnice między systemami informacyjnymi a informatycznymi. Pamiętajmy, że “technologią informacyjną” jest także system znaków drogowych na drogach…
Nie przypadkiem na całym świecie mamy prawo karne i cywilne. Sprzęt komputerowy i oprogramowanie to jedne z wielu możliwych przedmiotów umowy cywilno-prawnej. Pamiętajmy, że prawo autorskie i tajemnica przedsiębiorstwa dotyczy szeroko-pojetej treści. To czy jest nią kod źródłowy czy treść trylogii Władca Pierścieni nie ma żadnego znaczenia. Przedmiot zamówienia to (powinna być) treść załącznika do umowy i nie jest to praca dla prawnika (za wyjątkiem umowy z prawnikiem na usługę prawniczą).
Autor pisze, że programy komputerowe podlegają ochronie jak utwory literackie. Owszem, jeżeli ten kod rozumiemy jako tekst (znaki). Niestety mamy także pojęcie “informacja”, np. o mechanizmie naliczania upustów w programie lojalnościowym, i tu ochronie (tajemnica przedsiębiorstwa) podlega mechanizm naliczania upustu, bez względu na formę jego wyrażenia (o ile jest zrozumiała dla czytelnika), a mogą to być schematy blokowe i wzory matematyczne (patrz artykuł Prawo autorskie i wartości niematerialne – analiza systemowa oraz Ochrona wartości intelektualnych i know-how w organizacji – Poradnik). Ten mechanizm można zaimplementować w dowolnym języku oprogramowania, więc będą to “różne teksty o tym samym”. Co to znaczy? To znaczy, że TREŚĆ zeznania świadka morderstwa, jest tą samą treścią bez względu na to czy została utrwalona (dane) w języku francuskim czy języku Aborygenów.
Autor wprowadza pojęcie “Umowy wdrożeniowej”. Nie mam pojęcia po co, skoro to czy dana praca jest wdrożeniem czegokolwiek czy nie jest, jest skutkiem przedmiotu pracy a nie jej nazwy.
Autor pisze o modelu kaskadowym ale opisał ten model jak za czasów komputerów mainframe z lat 70tych ubiegłego wieku: każdy etap dotyczy całego systemu, co w dobie systemów zintegrowanych i komponentowych po prostu nie jest prawdą (patrz artykuł Integracja systemów ERP jako źródło przewagi rynkowej).
W rozdziale Umowy na inne usługi IT autor napisał (str. 195), że “Umowa na usługi programistyczne to najprostsza prawna forma współpracy w zakresie wytwarzania lub rozwoju oprogramowania”. Jak to przeczytałem, to pomyślałem od razu o prawach autorskich, o których autor pisał wcześniej, o różnych formach wyrażenia oprogramowania, o tym, że mamy licencje i przekazanie praw majątkowych, o tym, że stos technologiczny to aplikacja i biblioteki. Usługi programistyczne, a szczególnie ich produkt, to – patrząc na mediacje i spory w sądach – jedna z najtrudniejszych dziedzin w IT i w prawie. Kastomizacja systemu ERP czy dedykowane oprogramowanie napisane z użyciem określonego języka programowania i jego bibliotek, to labirynt. Gdy czytam jak prawnik pisze, że to “najprostsza umowa” to krew mi zamarza.
Komentarz

Opisałem wybrane, “ciekawsze” w moim subiektywnym odczuciu, elementy tej książki. Jednak cała ta książka, poza treściami stricte dotyczącymi prawa (a takich jest tam bardzo mało) spowodowała, że czytając tę książkę czułem się jak bym czytał książkę dobrego aktora piszącego swoje wyobrażenia o stolarstwie, bo “scena to deski”.
Opisanie wszystkich wad tej książki zajęło by wiele czasu i stron tekstu, bo niemalże każdy jej rozdział zawiera treści wymagające skomentowania lub wręcz wadliwe. Dlatego z uwagi na charakter i objętość bloga (staram się czas potrzebny na przeczytanie jednego postu nie przekraczał 20 minut) ograniczyłem się kilku wybranych wad, które w moich czynią tę książkę nieprzydatną dla osoby poznającej branżę, a osoba mająca stosowną wiedzę zareaguje podobnie jak ja: odłoży i nie wróci do niej.
Jako osoba, która widziała niejedno nieszczęście wdrożeniowe, nie tylko jako biegły w sądzie, zawsze będę powtarzał: prawnik, który projektuje systemy IT nigdy, nie będzie odpowiadał za ich nieudane wdrożenia, bo nawet gdy na etapie negocjacji umowy ma coś do powiedzenia, to Sąd nigdy nie powoła prawnika jako biegłego w sporze o przedmiot wdrożenia IT. Szanowni Państwo, pamiętajcie o tym, bo to co ja widzę w umowach i w dokumentach sądowych to na prawdę dramat.
A moja rekomendacja? Cóż, odradzam tę książkę prawnikom, korzystając z niej zrobią krzywdę swoim klientom. Prawnikom polecam raczej Logika dla prawników . Branża IT? To tym bardziej nie jest książka dla Was.
Polecam także artykuł Wzorcowe klauzule w umowach IT oraz Przed Tobą wdrożenie systemu IT czyli Polemika z poradami prawników.
Prawnicy, bądźcie prawnikami i uczcie się od sędziów: do zagadnień z poza prawa powołujcie w swoich projektach biegłych (ekspertów).
To co najbardziej zastanawia to fakt, że Rada Naukowa Polskiego Towarzystwa Informatycznego (PTI) przyznała tej książce Nagrodę II stopnia w konkursie na Najlepszą Książkę Informatyczną 2025.


