Wprowadzenie
W kwietniu 2024 roku opisywałem API
Artykuł powyższy polecam osobom zainteresowanym stroną techniczną projektowania integracji i API. Dzisiaj odpowiem na problemy jakie zgłaszają prawnicy, czyli co jest przedmiotem umowy gdy przedmiotem tym jest mityczne API. (https://it-consulting.pl/2024/04/05/api-to-cos-innego-nie/)

Wtedy problemem była próba traktowania oryginalnego API systemu ERP jak dedykowanej aplikacji, czy odrębnego kodu (licencja na API). Problemem jest często także poprawne nazewnictwo tego “o czym mowa”, są to nieporozumienia (lub celowe działanie) wywoływane ukrywaniem architektury przez dostawcę oprogramowania. W między czasie trafiła się dzisiaj ciekawa, krótka dyskusja o API na “Anonimowy Czat“.
Dzisiaj na konferencji Kongres Cyfrowa Transformacja, miałem referat zatytułowany “Różne podejście do transformacji cyfrowej w obliczu długu technologicznego i systemów “legacy”” (które czasami nazywamy dinozaurem w serwerowni). Na konferencji opisywałem “cyfrową transformację” z systemem “legacy” i polecałem metodę, którą nazwałem “Opakowanie i powolna migracja”.
Opakowanie i powolna migracja
Jak są definiowane przestarzałe aplikacje, zwane z ang. “legacy systems”:
- Przestarzały system (ang. legacy system) to przestarzałe oprogramowanie i/lub sprzęt komputerowy, który jest nadal w użyciu. System taki nadal spełnia potrzeby, dla których został pierwotnie zaprojektowany, ale nie pozwala na rozwój. Taki system z reguły spełnia aktualne wymagania ale żadne inne, nie pozwoli także na współdziałanie z nowszymi systemami.
- Wraz z postępem technologicznym, wiele firm ma do czynienia z problemami spowodowanymi przez istniejące przestarzałe systemy. Mówi się, że system taki zamiast oferować firmom najnowsze możliwości i usługi – takie jak np. cloud computing, integracja z otoczeniem – utrzymuje firmę w biznesowej “skamielinie”, blokując rozwój lub bardzo podnosząc koszty tego rozwoju.
Co możemy zrobić? Do wyboru mamy:
- Wymiana na nowy
- Modyfikacja
- Opakowanie i powolna migracja
Wymiana na nowy to mała rewolucja. Modyfikacja jest już niemożliwa (patrz wyżej). Skutecznym sposobem “wyjścia” z przestarzałej aplikacji jest jej “opakowanie”, wybór nowej nowoczesnej i powolna (bez-rewolucyjna) migracja. Dlaczego akurat tak?
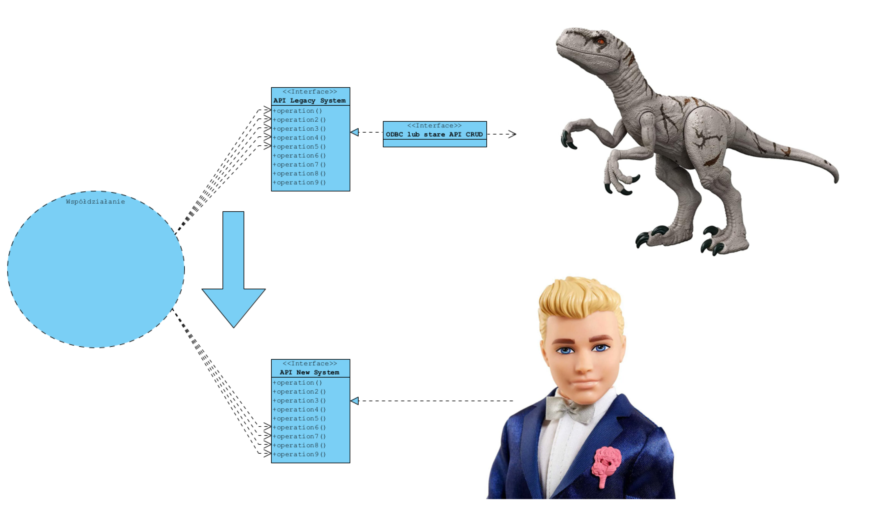
- Stare systemy mają bardzo często proste API zbudowane na poleceniach CRUD lub “wystawiają bazé danych” (dostęp z pomocą ODBC/SQL).
- Nowe systemy z reguły mają nowoczesne API realizujące złożone operacje.
Na czym polega “opakowanie i migracja”?
- Dla starego sytemu budujemy pośredniczący adapter (opakowanie) realizujący “nowoczesne API”.
- Iteracyjnie “przepinami” operacje ze starego systemu na nowy.
Schematycznie wygląda to tak:
Dobre i złe API
Kontynuując ten wątek postanowiłem najpierw opisać problem z API stanowiący ekspozycje tabel baz danych lub tak zwanych CRUD-ów (cztery operacje ang. Create, Retrieve, Update, Delete, czyli Utwórz, Przywołaj, Aktualizuj, Usuń) oraz budowę fasady, inteligentnego adaptera oferującego “inteligencje API”.
Praktyki projektowania znane z tak zwanych anemicznych modeli dziedziny (stare aplikacje odtwarzające w kodzie struktury relacyjnych baz danych: tabele i kolumny) są od wielu lat uznawane za antywzorce projektowe (Anemic domain model):
Ten wzorzec jest powszechnym podejściem w aplikacjach JavaEE, prawdopodobnie wspieranym przez technologie takie jak wczesne wersje Entity Beans EJB, a także w aplikacjach .NET zgodnych z architekturą Three-Layered Services Application, gdzie takie obiekty należą do kategorii “Business Entities” (chociaż Business Entities mogą również zawierać zachowanie).
Popatrzmy na popularny w sieci referat: Can Great Programmers Be Taught?, którego autorem jest John Ousterhout. Nas interesuje tu idea szerokości (liczba operacji) i głębokości (logika) interfejsu: dobry interfejs “hermetyzuje” maksymalnie wiele: jest wąski i głęboki. Dlaczego akurat taki jest lepszy? Bo mała liczba operacji interfejsu obiektu powoduje, że nie powstają silne i złożone zależności między tym obiektem a pozostałymi, korzystającymi z jego usług oraz ukrywa on w sobie (hermetyzuje) logikę korzystania z danych jakimi zarządza. Skorzystanie z takiego API jest łatwe i nie wymaga wiedzy dziedzinowego systemu z którego chcemy skorzystać:
Dlatego szczytem nieefektywności są tabele baz danych odwzorowywane jako klasy, ich pola jako atrybuty, a pobieranie i zapisywanie danych to kaskady wywołań operacji get/set dla każdego atrybutu (patrz: Why getters and setters are terrible), (wzorzec Active Table lub Active Record, patrz także: ORM anti-pattern series) . Nie ma tu żadnej logiki, ta wymaga implementacji po stronie pobierającego dane (skrypty transakcyjne), w osobnych klasach grupowanych często w drzewa dziedziczenia i kompozycji (patrz art. Dziedziczenie – anatomia trzydziestopięcioletniego błędu).
API czyli co?
API (Application Programming Interface), najczęściej jest definiowane jako:
zestaw reguł, protokołów i narzędzi, które umożliwiają różnym aplikacjom komunikację i wymianę danych między sobą. Interfejsy API działają jako pośrednik, definiując sposób, w jaki jeden program może zażądać usługi lub informacji od innego programu, bez konieczności znajomości wewnętrznego kodu drugiego. Na przykład, aplikacja pogodowa używa API do pobierania danych z serwera usługi pogodowej, który przetwarza żądanie i wysyła odpowiedź z powrotem do aplikacji.
Kluczowe jest tu stwierdzenie: “jeden program może zażądać usługi lub informacji od innego programu, bez konieczności znajomości wewnętrznego kodu drugiego“. Kluczowe cechy:
- Model klient-serwer: Aplikacja wysyłająca żądanie jest “klientem”, a aplikacja dostarczająca informacje lub usługę jest “serwerem”.
- Żądanie i odpowiedź: Klient wysyła żądanie do serwera, serwer przetwarza żądanie i wysyła odpowiedź klientowi.
- Standardowy format: Komunikacja odbywa się przy użyciu standardowego formatu, takiego jak JSON lub XML.
Generalnie “API serwera” to zestaw udostępnionych i udokumentowanych publicznych poleceń realizowanych przez ten serwer. Na poziomie projektowania mówimy, że API to operacje publiczne klasy (komponentu).
Płytkie szerokie vs Głębokie wąskie API
Popatrzmy na ten schemat z ww. prezentacji:
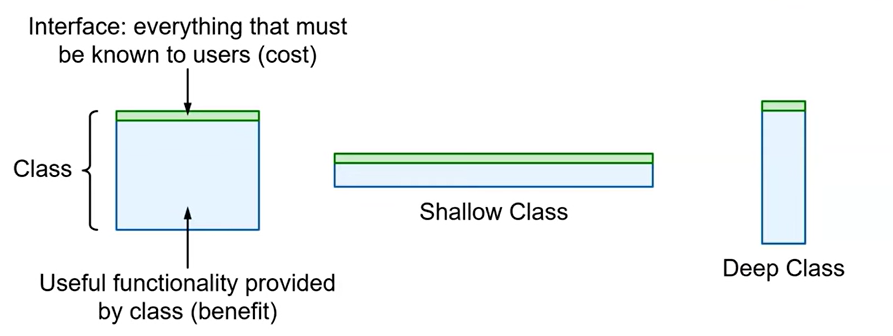
Nawiązując do ww. referatu i koncepcji profesora (John Ousterhout):
- liczba operacji kasy (jej interfejs) to jego “szerokość”,
- “zwężenie” interfejsu wymaga rozbudowania procedur czyli metod klasy, to jest “pogłębienie klasy”,
- wąski interfejs hermetyzuje logikę np. logikę biznesową,
- wąskie klasy podnoszą bezpieczeństwo korzystania z serwera i zmniejszają uzależnienie kodu aktorów.
Popatrzmy na ten diagram:
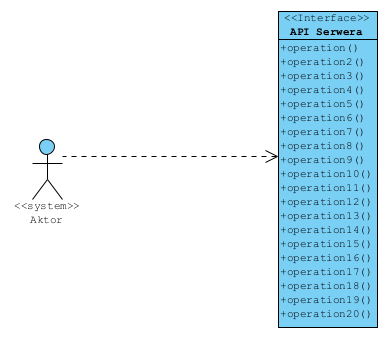
Mamy tu Aktora (aplikacja kliencka) oraz API Serwera (jakaś aplikacja, system ERP, sklep internetowy itp.). Pokazane tu API oferuje szereg prostych operacji (z reguły są to zestawy poleceń CRUD do wielu tabel lub atrybutów dokumentów). Aktor korzystający z takiego API musi posiadać wiedzę po co i w jakiej kolejności te operacje wywołać by uzyskać oczekiwany efekt, czyli po stronie aktora realizowana będzie procedura:
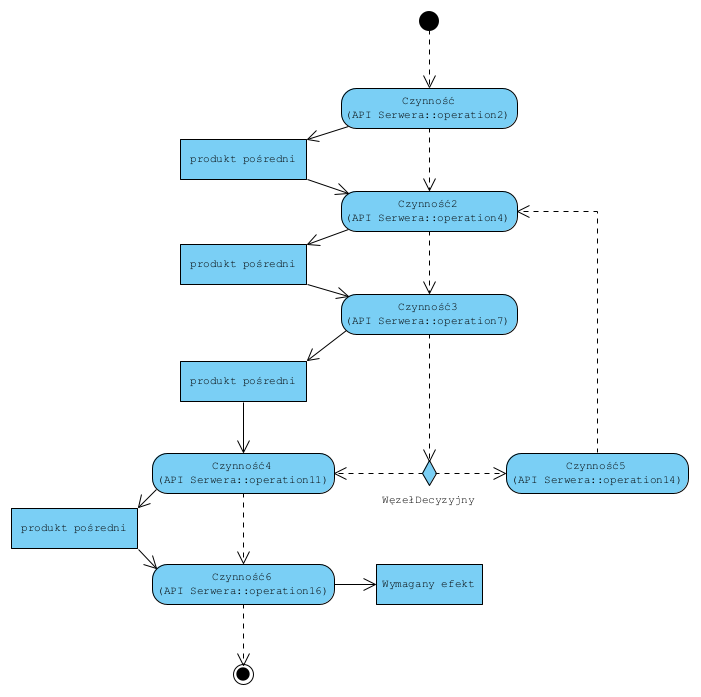
Problem w tym, że:
- aktor musi mieć wiedzę o tym “jak to zrobić” (ww. procedura).
- mając ograniczoną wiedzę o serwerze może to zrobić źle,
- zmiana API Serwera wymaga refactoringu wszystkich tych procedur.
Jak inaczej? Przede wszystkim budujemy adapter, który separuje (kod) Aktora od API Serwera:
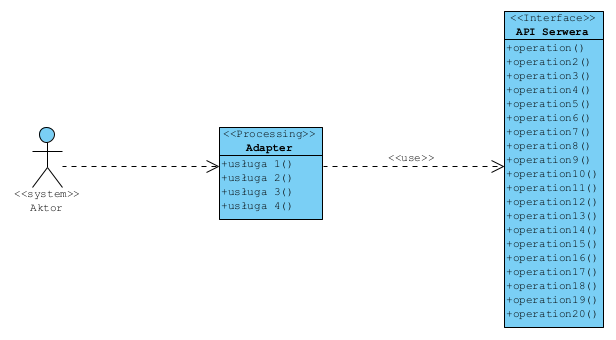
Pokazana wcześniej procedura (metoda) będzie ukryta (hermetyzacja) w tym Adapterze i widoczna jako jedna usługa (operacja) Adaptera (patrz także Anti-Corruption Layer (ACL)).
API jako model przypadków użycia UML
API (podobnie jak GUI) to przypadki użycia systemu. Jak to określa specyfikacja UML:
Przypadki Użycia są sposobem na określenie wymagań wobec systemów, tj. tego, co systemy mają robić [a nie jak]. Kluczowe pojęcia to Aktor, Przypadek Użycia i “przedmiot” specyfikowania. Każdy “Przypadek Użycia przedmiotu analizy” reprezentuje zachowanie systemu którego dotyczy. Użytkownicy i wszelkie inne systemy, które mogą wchodzić w interakcje z podmiotem, są reprezentowane jako jako Aktorzy. […] Przypadek Użycia jest rodzajem klasyfikatorem, który reprezentuje deklarację zestawu oferowanych zachowań. Każdy Przypadek Użycia to określone zachowanie, które system może wykonać na żądanie jednego lub większej liczby aktorów. Przypadek Użycia definiuje zachowanie systemu bez odniesienia do jego wewnętrznej struktury.
Projektując zmiany w systemie często specyfikujemy wymagania w postaci przypadków użycia. Dotyczy to także obszaru integracji, wtedy przypadek użycia to operacja na API:
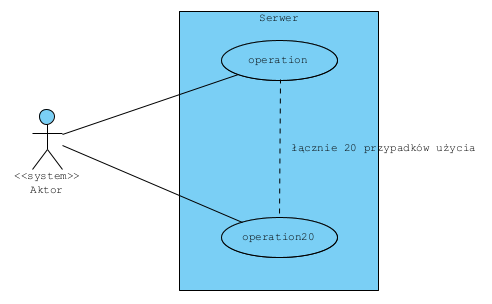
Taki diagram wydaje się nie mieć sensu i często jest to prawdą. Jednak możemy zażądać by aplikacja integrowana miała wąski i głęboki interfejs (API) i pokazać to tak:
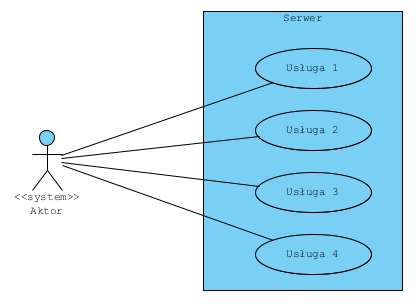
Wtedy pokazana wcześniej metoda będzie tu scenariuszem przypadku użycia.
Podsumowanie
A teraz wyobraźmy sobie, że mamy dinozaura, starą aplikację, której specyfikacja API wygląda jak ankieta u dentysty (powyższe API Serwera). Jest bardzo prawdopodobne, że te polecenia to pojedyncze linie kodu lub zapytania SQL do bazy danych RDBMS tej aplikacji. Integracja z resztą systemu IT organizacji będzie trudna i kosztowna w wykonaniu i utrzymaniu. Przepięcie ten aplikacji na nową też nie będzie łatwe (co na co przepinać?).
Jak inaczej? Żądamy od dostawcy (lub lokalnego administratora) napisania Adaptera. Procedury dla Adaptera (metody operacji) albo napisze nasz admin (być może twórca) starej aplikacji, albo dostawca aplikacji (generalnie warto żądać takiego Adaptera już na etapie specyfikowania wymagań na etapie zakupu, albo zlecić jego zbudowanie po wdrożeniu). W przypadku planowania migracji do nowej aplikacji musimy zdecydować kto taki adapter zaprojektuje i wykona wdrożenie. Niewątpliwie pozostawienie Serwera w stanie “as-is” będzie bardzo kosztownym w utrzymaniu dziedzictwem .
A od strony prawnej? Samo “wystawianie” API Serwera nie jest żadnym dodatkowym przedmiotem prawa autorskiego, ale może być objęte dodatkową licencją (np. w przypadku SAP). Adapter jako osobna dedykowana aplikacja to nic innego jak utwór, dedykowany produkt, i jak najbardziej chroni go prawo autorskie, by moze także jest chroniony jako know-how. Pozostaje zdecydowanie o tym komu zostanie zlecone jego zaprojektowanie.