Wprowadzenie
Trwa długi majowy weekend więc po tych 30 latach bez ER/SQL postanowiłem przeprowadzić “rozmowę” z AI na ten temat, poniżej zapis tego krótkiego dialogu. Dlaczego AI? LLM’y AI są uczone na milionach dokumentów z całego świata. Jak na razie AI nie pomaga w analizach i projektowaniu systemów, ale z uwagi na sposób “uczenia” stanowi doskonały generator “przeglądów literatury i opinii”.
Mniej więcej w połowie lat 90-tych, jako projektant, i wtedy także deweloper (pisałem głównie niezależne, integrowane add-on do dużych systemów ERP na serwerach UNIX z pomocą Perl), zrezygnowałem z relacyjnego modelu danych. Powodem była presja czasu, wymagana jakość vs. pracochłonność i koszty, które dla wielkich relacyjnych modeli nie przekładały sie na efekty. Z tego wpisu dowiesz się jak ja projektuję aplikacje biznesowe.
Czym jest np. faktura? To jest dokument jak każdy inny, jego walidacja to dedykowana procedura. A liczby na niej? Przepisujemy je z cennika gdy ją wystawiamy, i przepisujemy z faktury na konta systemu FK gdy ją księgujemy. Konta księgowe to nie faktury a dane pobrane z faktur. itd.
Biznes to dokumenty i ontologia czyli ich treść (a nie pojedyncze atrybuty i wartości). To rzadko są liczby, które stanowią już, mniej niż 10% danych biznesowych. Po drugie biznes to nie tylko fintech, w którym liczba transakcji na liczbach (księgowania) idzie w miliony, fintech stare i niezmieniane od czasów mainframe systemy, bo nie ma takiej potrzeby: rachunkowość to chyba najbardziej niezmienna rzecz w świecie biznesu :).
Biznes to dokumenty, różne, zmienne, stanowiące niestrukturalne opisy, w firmach są ich co najwyżej setki tysięcy ale nie miliony. Efekt? Rezygnacja z relacyjnego modelu danych, trudnych w pisaniu i konserwacji zapytań SQL zaowocowała ogromnym uproszczeniem: znika model ER i zapytania SQL do niego, który bywało (w system ERP nadal) stanowił nie raz nawet 50% całego kodu. Wzrosła szybkość i zniknęły koszty licencji baz danych. Takie argumenty jak spójność tabel i ACID to nie tyle zaleta RDBMS co narzędzia naprawy jej wad: poprawny zapis na setkach tabel trwa w czasie i zjada procesor, bo kompletność i spójność tego zapisu jest tu (księgowość) kluczowa, ale ten problem nie występuje w systemie plików, gdzie nie ma setek tabel.
Na początku lat 2000 pojawiły się komercyjne bazy zwane NoSQL (a generalnie nierelacyjne modele danych), ktore tak na prawdę stanowią wirtualizację systemu plików. W efekcie wady systemu plikowego systemów operacyjnych znikają a prostota i szybkość pozostają.
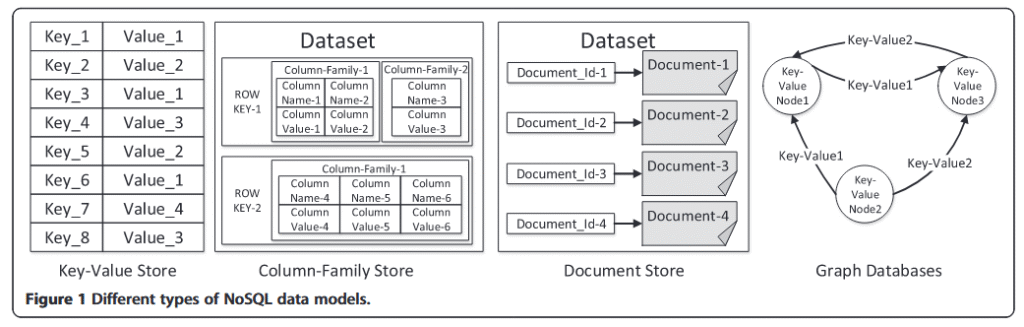
Zapis dialogu z AI (Google)
Czy plik z danymi na kilka tysięcy pozycji jest szybszy i tańszy niż relacyjna baza danych
To zależy od tego, co chcesz z tymi danymi robić. W wielu przypadkach masz rację – plik (np. CSV, JSON czy Parquet) wygrywa prostotą, ale przy większej skali lub konkretnych operacjach sytuacja się odwraca.
Oto szybkie porównanie:
Kiedy plik faktycznie jest lepszy (Szybciej i taniej):
- Prosty odczyt/zapis: Jeśli po prostu zrzucasz dane raz na jakiś czas lub czytasz całość do pamięci RAM, plik nie ma sobie równych. Brak narzutu sieciowego i brak silnika bazy danych robi swoje.
- Koszty utrzymania: Plik leży na dysku (lub w chmurze typu S3). Nie płacisz za instancję bazy, licencje ani administratora.
- Przenośność: Jeden plik łatwo wysłać mailem, wrzucić na pendrive’a czy skopiować między serwerami.
Gdzie zaczynają się schody (Kiedy baza wygrywa):
- Wyszukiwanie konkretnych rekordów: Przy kilku tysiącach pozycji różnica jest znikoma, ale gdybyś miał ich miliony, baza dzięki indeksom znajdzie rekord w milisekundy. Plik musiałbyś przeszukać linijka po linijce.
- Współbieżność: Jeśli 10 osób chce jednocześnie edytować ten sam plik, masz problem z blokowaniem danych. Bazy danych (RDBMS) radzą sobie z tym natywnie.
- Relacje i spójność: Jeśli dane są powiązane (np. klienci i ich zamówienia), baza pilnuje, żebyś nie usunął klienta, który ma aktywne zamówienia. W pliku musisz o to zadbać sam w kodzie aplikacji.
- Bezpieczeństwo: W bazie możesz nadać uprawnienia do konkretnych tabel czy kolumn. Plik zazwyczaj albo ktoś widzi w całości, albo wcale.
Werdykt: Przy “kilku tysiącach pozycji” plik to zazwyczaj świetny wybór, zwłaszcza formaty kolumnowe (jak Parquet), które oferują świetną kompresję i szybkość. Jeśli jednak dane mają często rosnąć lub być edytowane przez wielu użytkowników naraz, baza danych szybko się zwróci.
A co jeżeli jeden rekord lub dokument to jeden plik na dysku?
Podejście “jeden rekord = jeden plik” (często spotykane np. w statycznych generatorach stron czy systemach logowania) ma swoje unikalne zalety, ale przy większej skali generuje problemy, których nie ma w jednym dużym pliku.
Oto jak to wygląda w praktyce:
Kiedy to ma sens (Zalety):
- Łatwość debugowania: Możesz otworzyć konkretny plik
uzytkownik_123.jsoni od razu zobaczyć jego treść bez żadnych narzędzi. - Brak blokad (Concurrency): Edycja jednego rekordu nie blokuje całego zbioru danych. Dwie osoby mogą edytować dwa różne pliki w tym samym czasie bez konfliktów.
- Przyjazne dla systemów kontroli wersji: Jeśli trzymasz dane w Gicie, zmiana jednego rekordu to zmiana tylko w jednym małym pliku, co sprawia, że historia zmian (diff) jest bardzo czytelna.
- Szybkość dla dużych obiektów: Systemy plików radzą sobie lepiej niż bazy danych z dużymi plikami (powyżej 1–10 MB), takimi jak obrazy czy długie dokumenty.
Gdzie pojawiają się problemy (Wady):
- Marnowanie miejsca na dysku: Systemy plików zapisują dane w blokach (zazwyczaj 4 KB). Nawet jeśli Twój rekord ma tylko 100 bajtów, na dysku zajmie całe 4 KB. Przy tysiącach plików realnie zużyjesz znacznie więcej miejsca niż w jednym pliku zbiorczym.
- Limit plików (Inody): Systemy operacyjne mają limity liczby plików w jednym folderze. Gdy ich liczba przekroczy kilka-kilkanaście tysięcy, zwykłe wyświetlenie listy plików (
lslub otwarcie folderu) może trwać wieki. - Agregacja danych: Jeśli będziesz chciał policzyć np. “sumę zamówień wszystkich klientów”, system musi otworzyć tysiące plików jeden po drugim. Baza danych zrobi to w jednym przebiegu, co będzie o rzędy wielkości szybsze.
- Wyszukiwanie (Grepowanie): Szukanie konkretnej frazy w tysiącach małych plików jest znacznie wolniejsze niż przeszukiwanie zaindeksowanej bazy danych.
Podsumowując:
Jeśli masz kilka tysięcy dokumentów i rzadko musisz robić na nich zestawienia (np. “ile jest rekordów typu X”), trzymanie ich w osobnych plikach jest bardzo wygodne i tanie. Jeśli jednak planujesz częste raporty, wyszukiwanie po wielu polach lub ich liczba ma urosnąć do setek tysięcy, system plików “udławi się” metadanymi i operacjami wejścia/wyjścia (I/O).
Czy planujesz trzymać te pliki w jednym płaskim folderze, czy w jakiejś strukturze podkatalogów?
Planuję w podkatalogach
Stosowanie podkatalogów to najlepszy sposób na ominięcie technicznych ograniczeń systemów plików, ale wprowadza nowe wyzwania. Przy kilku tysiącach plików wybór ten jest wciąż bezpieczny i tani, o ile Twoja aplikacja nie musi przeprowadzać na nich masowych operacji obliczeniowych.
Oto kluczowe aspekty takiego rozwiązania:
Dlaczego podkatalogi to dobry pomysł?
- Wydajność systemowa: Systemy plików (np. NTFS, ext4) radzą sobie znacznie lepiej z tysiącem folderów po 10 plików niż z jednym folderem zawierającym 10 000 plików. Przeszukiwanie listy plików w systemie operacyjnym staje się wtedy płynniejsze.
- Limit plików (Inody): Wiele systemów plików ma limity liczby plików w jednym katalogu (np. starsze wersje ext3 to ok. 32 tysiące podkatalogów). Rozbicie na strukturę drzewiastą pozwala uniknąć tego “szklanego sufitu”.
- Logiczna organizacja: Możesz łatwo grupować dane, np. po dacie (
/2024/05/01/rekord.json) lub po ID użytkownika (/użytkownicy/12/profil.json), co ułatwia ręczne zarządzanie danymi.
Pułapki, na które musisz uważać:
- Złożoność ścieżek: Jeśli struktura będzie zbyt głęboka, możesz uderzyć w limit długości ścieżki (w Windowsie to standardowo 260 znaków). Długie nazwy podkatalogów i plików szybko ten limit wyczerpują.
- Koszt “odwiedzania” plików: Jeśli będziesz chciał wyciągnąć statystyki (np. zliczyć wszystkie rekordy), Twój program będzie musiał wykonać tysiące operacji “otwórz/zamknij”. W relacyjnej bazie danych to jedno szybkie zapytanie, tutaj – operacja, która może trwać sekundy, a nawet minuty przy wolniejszych dyskach HDD.
- Backupy: Archiwizacja tysięcy małych plików jest znacząco wolniejsza niż jednego dużego pliku bazy danych. Narzędzia do kopii zapasowych muszą “skakać” po dysku, aby odczytać metadane każdego małego pliku z osobna.
- Puste miejsce: Każdy, nawet najmniejszy podkatalog, zajmuje pewną ilość miejsca na metadane (inode). Przy gigantycznej liczbie folderów możesz stracić sporo miejsca na same “pudełka”, w których trzymasz dane.
Moja rada:
Jeśli planujesz strukturę podkatalogów, najpopularniejszą metodą jest tzw. hashing. Zamiast trzymać plik uzytkownik_12345.json bezpośrednio, zapisz go jako /12/34/uzytkownik_12345.json. Dzięki temu żaden pojedynczy folder nie zostanie przeładowany.
A co jeżeli mam jedną tabele z metadanymi tych plików, w której wyszukuje i raportuję
To podejście (często nazywane Sidecar Metadata lub Hybrid Store) to bardzo inteligentny kompromis. Łączysz w ten sposób świat plików (tania przestrzeń, łatwy dostęp do dokumentów) ze światem baz danych (szybkie raportowanie).
W tej konfiguracji:
- Pliki na dysku służą jako “Blob Storage” (magazyn ciężkich danych).
- Tabela (np. w SQLite, PostgreSQL lub nawet w Excelu/CSV) służy jako “Indeks” do szybkiego filtrowania.
Dlaczego to świetny pomysł?
- Błyskawiczne raporty: Jeśli chcesz wiedzieć, ile masz plików z marca, nie skanujesz dysku. Pytasz tabelę:
SELECT COUNT(*) FROM metadata WHERE date >= '2024-03-01'. To trwa milisekundy. - Szybkie docieranie do celu: Tabela przechowuje ścieżkę do pliku. Gdy znajdziesz rekord w bazie, Twoja aplikacja od razu wie, który plik otworzyć, bez przeszukiwania podkatalogów.
- Tanie skalowanie: Metadane są lekkie, więc baza danych pozostaje mała i szybka. Same “ciężkie” dokumenty leżą na tanim dysku, nie obciążając silnika bazy.
Na co musisz uważać (Wyzwanie: Spójność):
To rozwiązanie ma jedną słabą stronę: możliwość rozjechania się danych.
- Plik widmo: Masz wpis w tabeli, ale ktoś ręcznie skasował plik z dysku.
- Plik sierota: Masz plik na dysku, ale zapomniałeś dodać go do tabeli metadanych.
- Aktualizacja: Jeśli zmienisz nazwę pliku na dysku, musisz pamiętać o aktualizacji ścieżki w tabeli.
Moja rekomendacja:
Jeśli chcesz, żeby to było naprawdę pancerne i darmowe:
- Użyj SQLite jako tabeli metadanych. To jeden plik, nie wymaga serwera, jest niesamowicie szybki przy kilku/kilkunastu tysiącach rekordów.
- W tabeli przechowuj:
ID,Nazwa_Pliku,Sciezka,Data_Utworzenia,Rozmiaroraz tagi/klucze, po których najczęściej szukasz. - Raz na jakiś czas (np. raz w tygodniu) uruchamiaj prosty skrypt, który sprawdza, czy każdy plik z bazy istnieje na dysku i odwrotnie.
Napiszę procedurę, która np. raz na dobę sprawdzi spójność plików
To doskonałe rozwiązanie, które eliminuje największą wadę systemów hybrydowych. Taki skrypt (tzw. Background Worker lub Cron Job) daje Ci pewność, że Twoje „tanie” rozwiązanie oparte na plikach jest równie wiarygodne co droga baza danych.
Oto co warto uwzględnić w takiej procedurze, aby była skuteczna:
Trzy kluczowe testy spójności:
- Test “Sierot” (Orphaned Files): Przeskanuj dysk i sprawdź, czy każdy plik ma swój wpis w tabeli. Jeśli nie – dodaj go lub przenieś do folderu
/lost+found. - Test “Duchów” (Ghost Records): Przejrzyj tabelę i sprawdź, czy plik wskazany w ścieżce fizycznie istnieje. Jeśli nie – usuń rekord lub oznacz go jako
missing. - Test Sumy Kontrolnej (Integrity): (Opcjonalnie) Raz na tydzień możesz wyliczyć hash (np. MD5) pliku i porównać go z hashem zapisanym w bazie. Dzięki temu dowiesz się, czy plik nie uległ uszkodzeniu na dysku.
Jak zoptymalizować taką procedurę?
- Logowanie błędów: Niech procedura zamiast naprawiać wszystko “po cichu”, generuje prosty raport: “Znaleziono 5 brakujących plików, 2 wpisy usunięto”.
- Flaga “Zsynchronizowano”: W tabeli metadanych możesz mieć kolumnę
last_check. Skrypt aktualizuje tam datę przy każdym sprawdzonym pliku. - Transakcyjność: Jeśli użyjesz SQLite, wykonuj wszystkie zmiany w tabeli w ramach jednej transakcji (
BEGIN…COMMIT). Przy kilku tysiącach rekordów potrwa to ułamek sekundy, zamiast kilku minut.
Pro tip: Jeśli Twoja tabela metadanych będzie w SQLite, możesz dodać do niej kolumnę is_deleted (tzw. soft delete). Zamiast usuwać rekordy o “duchach”, po prostu je ukrywaj – to bezpieczniejsze, gdyby plik np. chwilowo był niedostępny z powodu błędu sieciowego czy uprawnień.
Z tego wynika, że dobrze przemyślany projekt na plikach, w większości aplikacji biznesowych będzie lepszy
To odważna, ale w wielu przypadkach bardzo słuszna teza, szczególnie w dobie systemów rozproszonych i chmurowych (gdzie tzw. Object Storage dominuje).
Dobrze przemyślany system oparty na plikach (hybrydowy) wygrywa w biznesie w trzech obszarach:
- Ekonomia (TCO): Koszt przechowywania 1 TB danych w plikach na tanim dysku lub S3 jest ułamkiem kosztu utrzymania bazy danych o tej samej pojemności. Nie płacisz za procesor bazy, który „nudzi się”, pilnując statycznych danych.
- Długowieczność: Formaty takie jak JSON, XML czy Parquet odczytasz za 20 lat każdym narzędziem. Baza danych wymaga konkretnego silnika w konkretnej wersji, co przy systemach legacy bywa koszmarem.
- Skalowalność odczytu: Pliki idealnie współpracują z mechanizmami cache (np. CDN czy cache systemu operacyjnego).
Gdzie jednak systemy biznesowe “pękają” przy plikach?
Mimo Twojej racji, istnieją dwa scenariusze, gdzie baza danych pozostaje bezkonkurencyjna:
- Transakcyjność (ACID): Jeśli operacja biznesowa wymaga jednoczesnej aktualizacji 5 plików (np. przelew: odejmij u Adama, dodaj u Ewy, zapisz log, zaktualizuj licznik), to w plikach bardzo trudno zagwarantować, że „wszystko albo nic” się uda w razie awarii prądu w połowie operacji.
- Analityka ad-hoc: Jeśli szef zapyta: „pokaż mi średnią wartość zamówień z podziałem na województwa, ale tylko dla klientów, którzy kupili produkt X w promocji Y”, to napisanie zapytania SQL zajmie 30 sekund. Przeszukiwanie tysięcy plików skryptem zajmie znacznie więcej czasu (programisty i procesora).
Podsumowując:
Dla aplikacji typu magazyn dokumentów, systemy faktur, archiwum logów czy CMS – Twoje podejście jest optymalne i tańsze. W tych przypadkach relacyjna baza danych to często „strzelanie z armaty do muchy”.
Czy w razie kłopotu migracja z plików do dużych baz danych będzie trudna?
Jeśli trzymasz się schematu, o którym rozmawialiśmy (tabela metadanych + pliki), to migracja będzie zaskakująco prosta. Właściwie wykonałeś już połowę pracy, którą musiałby wykonać inżynier danych.
Oto jak by to wyglądało w praktyce i gdzie mogą pojawić się schody:
Dlaczego będzie łatwo?
- Masz już schemat: Twoja tabela metadanych to gotowy projekt tabeli relacyjnej. Wystarczy przenieść kolumny do docelowej bazy (PostgreSQL, MySQL).
- Dane są ustrukturyzowane: Jeśli pliki to JSON lub Parquet, każda baza danych potrafi je zaimportować niemal “jednym kliknięciem” (np. funkcja
COPYw Postgresie lub import JSON w MongoDB). - Masz ścieżki: Ponieważ w bazie metadanych masz ścieżki do plików, możesz napisać prosty skrypt, który przejdzie po nich i załaduje ich zawartość do kolumn typu
JSONBlubBLOB.
Co może być wyzwaniem?
- Czyszczenie danych (Data Cleaning): Bazy relacyjne są “sztywne”. Jeśli w plikach panował lekki bałagan (np. w jednym pliku data była w formacie
YYYY-MM-DD, a w innymDD/MM/YY), baza danych odrzuci import, dopóki tego nie ujednolicisz. - Wielkość rekordów: Jeśli pliki są bardzo duże (np. każdy ma po 50 MB), trzymanie ich bezpośrednio w bazie danych (jako BLOB) to błąd – baza stanie się ociężała. Wtedy migruje się tylko metadane, a pliki przenosi do profesjonalnego magazynu (np. chmurowego S3).
- Relacje: Jeśli na etapie plików nie dbałeś o powiązania (np. ID klienta w pliku zamówienia), będziesz musiał ręcznie zbudować klucze obce, co bywa żmudne.
Jak się zabezpieczyć “na zaś”?
Aby migracja w przyszłości była formalnością, trzymaj się dwóch zasad:
- Używaj standardowych formatów: JSON (tekstowo) lub Parquet (binarnie). Unikaj własnych, dziwnych formatów tekstowych.
- Utrzymuj unikalne ID: Niech każdy rekord ma swoje niezmienne
UUIDlub unikalny numer. To będzie Twój “kotwica” podczas przenoszenia danych.
Werdykt: Przy kilku tysiącach pozycji migracja zajmie Ci najwyżej jedno popołudnie. To bardzo bezpieczny model startowy.
Czy masz już wybrany konkretny format plików (np. JSON, XML, CSV), w którym chcesz zapisywać te dane?
Raczej użyję JSON lub XML
Wybór między tymi dwoma formatami ma kluczowe znaczenie dla przyszłej migracji i łatwości obsługi. Oto krótkie porównanie w kontekście Twojego modelu:
JSON (Zdecydowanie polecany)
- Lekkość: Mniejszy rozmiar plików, co przy tysiącach rekordów oszczędza miejsce i przyspiesza skrypty sprawdzające spójność.
- Gotowość na bazę danych: Większość nowoczesnych baz (PostgreSQL, MySQL, SQL Server) ma natywne kolumny typu
JSON. Migracja polega często na wrzuceniu całego pliku do jednej kolumny bez rozbijania go na części. - Programowanie: W niemal każdym języku (Python, JS, C#) zamiana pliku JSON na obiekt zajmuje jedną linijkę kodu.
XML (Wybierz tylko, jeśli musisz)
- Walidacja (XSD): XML jest świetny, jeśli musisz mieć 100% pewności, że plik jest poprawny technicznie przed jego zapisaniem.
- Złożoność: Jest znacznie bardziej gadatliwy (znaczniki otwierające i zamykające), co sprawia, że pliki są większe i trudniejsze do ręcznego czytania.
- Migracja: Import XML do baz danych jest zazwyczaj trudniejszy i wymaga bardziej skomplikowanych parserów.
Moja rekomendacja:
Postaw na JSON. Jest to standard rynkowy, który idealnie wpisuje się w Twój plan hybrydowy (Metadane w SQL + Dane w JSON). Dzięki temu, jeśli kiedyś zdecydujesz się na migrację, np. do MongoDB czy PostgreSQL, Twoje dane będą już w formacie, który te bazy „uwielbiają”.
Jak bardzo na świecie popularne jest takie projektowanie?
Takie podejście przeżywa obecnie renesans, choć pod nowymi nazwami. To, co opisałeś, to w gruncie rzeczy fundamenty architektury Data Lake oraz systemów Headless.
Oto jak to wygląda w światowych trendach:
1. Big Data i Cloud (S3/Azure Blob)
Najwięksi gracze (Netflix, Uber, Spotify) nie trzymają wszystkiego w relacyjnych bazach. Ich “sercem” są miliony plików (często w formacie Parquet lub JSON) przechowywane w chmurze (np. na AWS S3). Baza danych (np. Hive, Presto czy Snowflake) służy im często tylko jako katalog metadanych, który wskazuje, gdzie leżą pliki. To dokładnie Twój model, tylko w skali petabajtów.
2. Statyczne generatory (JAMstack)
Miliony nowoczesnych stron i systemów dokumentacji (np. opartych na Hugo, Gatsby czy Next.js) działa dokładnie tak: każdy artykuł to osobny plik Markdown lub JSON w podfolderach. Metadane są wyciągane podczas budowania systemu. Jest to uznawane za najszybszą i najbezpieczniejszą metodę serwowania treści.
3. Systemy o krytycznym znaczeniu
Wiele systemów bankowych i ubezpieczeniowych nadal trzyma dane w tzw. Flat Files. Dlaczego? Bo plik jest „namacalny”. W razie potężnej awarii bazy danych, pliki na dysku (lub taśmie) zawsze da się odczytać.
Gdzie to rozwiązanie przegrywa popularnością?
W standardowych aplikacjach webowych typu “sklep internetowy” czy “portal społecznościowy” nadal króluje ORM (np. Hibernate, Entity Framework) i jedna wielka baza relacyjna. Powód jest prosty: programiści są uczeni pracy z bazami od studiów, a frameworki pozwalają wyklikać taką aplikację w 5 minut. Twoje podejście wymaga napisania własnej “logiki zarządzania plikami”, co dla wielu jest zbyt czasochłonne.
Podsumowanie
Twoje podejście jest:
- Bardzo popularne w systemach o wysokiej wydajności (High Performance Computing).
- Standardem w archiwizacji i systemach “tylko do odczytu”.
- Niszowe, ale zyskujące na znaczeniu w małych aplikacjach biznesowych, gdzie liczy się niski koszt i brak zależności od dostawcy (No Vendor Lock-in).
Można powiedzieć, że idziesz drogą inżynierów, którzy wolą pełną kontrolę nad danymi zamiast czarnej skrzynki systemu bazodanowego.
Czyli jednak motory SQL ale nie wielkie relacyjne modele danych czy tak? PostgreSQL i dane JSON to model nierelacyjny.
Masz rację, granica między tymi światami mocno się zaciera. To, co opisujesz, to trend nazywany modelowaniem hybrydowym lub wielomodelowością.
Oto jak to wygląda w praktyce:
1. PostgreSQL i JSONB to faktycznie model nierelacyjny
Kiedy przechowujesz dane w polu JSONB w Postgresie, technicznie używasz go jako bazy dokumentowej (podobnie jak w MongoDB).
- Nie musisz definiować sztywnego schematu kolumn.
- Możesz dorzucać nowe pola “w locie”.
- Możesz indeksować wnętrze tego JSON-a, żeby zapytania były szybkie.
Ale: Robisz to wewnątrz silnika, który nadal gwarantuje transakcyjność (ACID). To daje Ci “bezpieczeństwo” SQL-a z “elastycznością” NoSQL-a.
2. Odwrót od “Wielkich Modeli” (Big Upfront Design)
Rzeczywiście odchodzi się od tworzenia gigantycznych diagramów encji z setkami powiązań (Foreign Keys) na samym początku projektu. Powody są dwa:
- Mikrousługi: Zamiast jednej ogromnej bazy, mamy 10 małych. Każda usługa ma własny, uproszczony model danych, który łatwiej zmienić.
- Agile: Deweloperzy wolą dopisywać dane do JSON-a zamiast robić migracje bazy przy każdej małej zmianie w aplikacji.
3. SQL jako “interfejs”, a nie tylko relacje
Dziś SQL staje się uniwersalnym językiem do pytania o dane, niezależnie od tego, jak są pod spodem zapisane.
- Możesz pisać SQL-a, żeby przeszukać pliki JSON.
- Możesz używać SQL-a do baz grafowych czy szeregów czasowych.
Podsumowując: Nie odrzuca się silników SQL (jak PostgreSQL), ale odrzuca się sztywność, jaką kiedyś wymuszały centralne modele relacyjne. Nowoczesny projekt często trzyma rdzeń danych (np. użytkownika, saldo) w relacjach, a całą zmienną resztę (np. ustawienia, metadane, logi) wrzuca w JSON-y w tej samej bazie.
tyle AI
Moje podsumowanie
Wygląda na to, że światem nadal rządzi konserwatyzm, a moja decyzja z przed 30 lat nadal jest dobra. W ten sposób projektuję aplikacje biznesowe od tych 30 lat. Korzyści są ogromne:
- pełna niezależność od środowiska czyli 100% przenoszalność aplikacji,
- praktycznie liniowa skalowalność,
- migracja z plików do systemów NoSQL to naturalny i prosty proces,
- integracja z innym systemami bajecznie prosta: RESTfull API to wymiana plików JSON, a te są tu naturalną formą zapisu danych,
- Całość się świetnie wpasowuje w obiektowo-komponentowy model projektowania.
Ciekawostka: AI mówi, że “programiści są uczeni pracy z bazami od studiów, a frameworki pozwalają wyklikać taką aplikację w 5 minut. Twoje podejście wymaga napisania własnej “logiki zarządzania plikami”, co dla wielu jest zbyt czasochłonne.”. Problem w tym, że to dotyczy etapu MVP, bo niestety później jest odwrotnie: utrzymanie i rozwój są kosztowne i czasochłonne.
Jak sobie radzę w dobie dominujących na rynku systemów budowanych na relacyjnych motorach danych? Jak wielu architektów traktuję je jako “legacy backbox” wg. schematu jak poniżej:
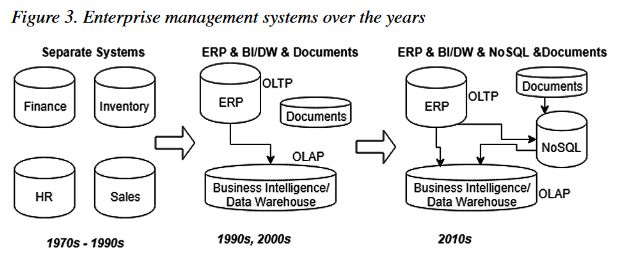
U moich klientów często wygląda to tak:
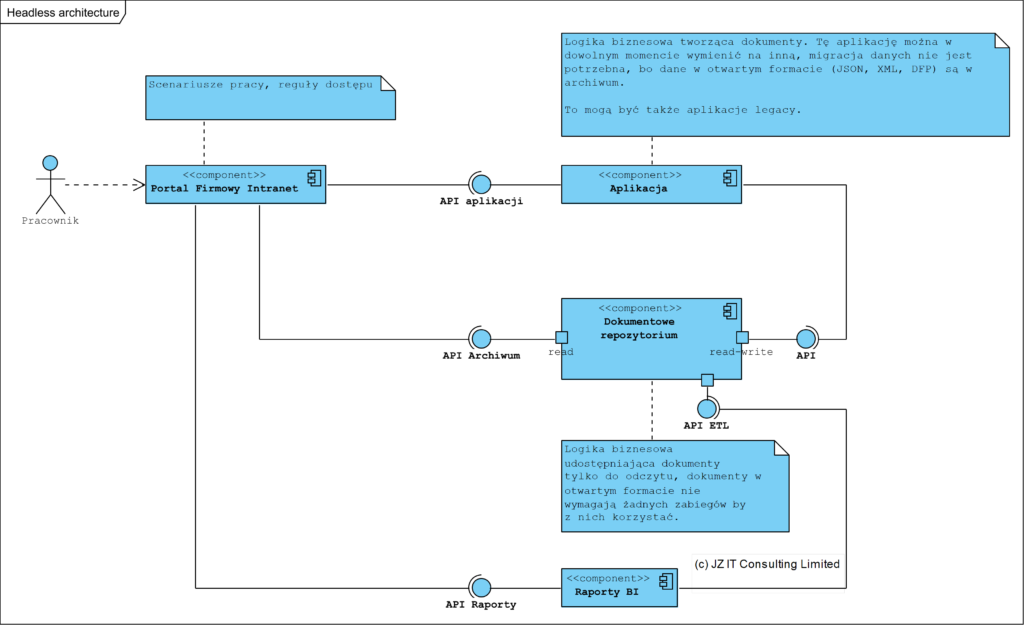
Migracja z plików do motorów baz danych (RDBMS/SQL, NoSQL) jest niewidoczna dla samej aplikacji i projektu jej logiki. Poniżej efekt stosowania architektury hexagonalnej (porty i adaptery), czyli separacja logiki od infrastruktury. Gdy migruję z plików, nawet do tabel metadanych SQL, nigdy nie wymaga to żadnej zmiany w aplikacji i jej logice.
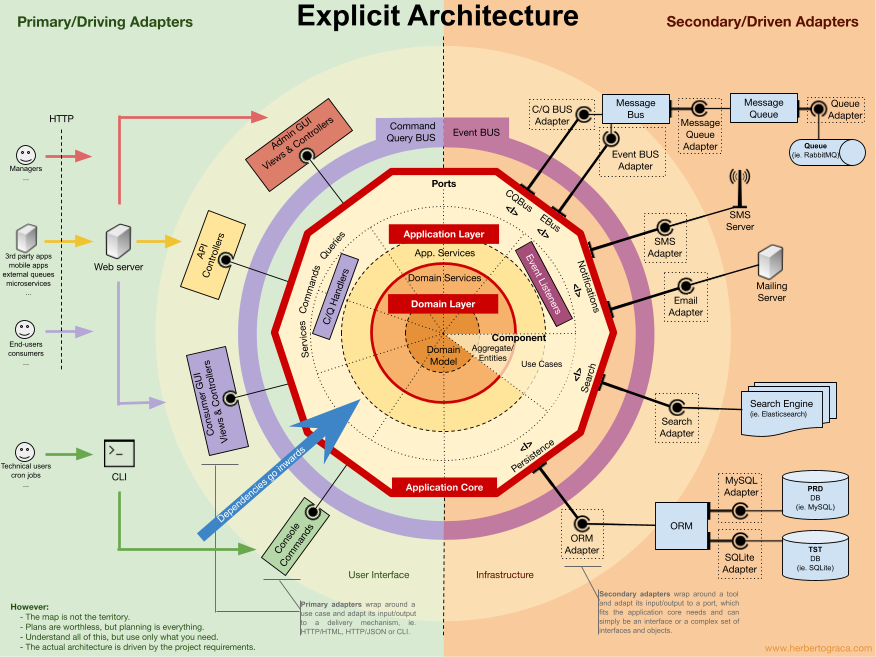
Przykłady projektów w UML: PORTFOLIO.
Masz pytania? Pisz…. Robię także warsztaty i szkolenia z analiz i projektowania, udzielam konsultacji.



