Wprowadzenie
Od lat, podczas audytów i szkoleń, spotykam się z “dziwnymi diagramami” tworzonymi w celu… no właśnie. Ale po kolei…
Najpierw przypomnę, bardzo tu pomocne, pojęcie architektury korporacyjnej, która – śledząc literaturę przedmiotu – jest modelem (dokumentacją) wiążącym model biznesowy organizacji z jej zasobami informacyjnymi i infrastrukturą służącą do zarządzania informacją. Posiadanie takiego modelu ma sens nie tylko po to by, wiedzieć “co mamy” czy opisać wymagania na to czego “jeszcze nie nie mamy a potrzebujemy mieć”. Model taki pozwala analizować posiadane zasoby, ale także ocenić ich wpływ na działanie organizacji, wzajemny wpływ, przewidzieć reakcje systemu na nowe bodźce (lub awarie).
W artykule opisującym proces modelowania “od biznesu do projektu logiki systemu” opisałem przechodzenie od modelu procesów biznesowych, przez przypadki użycia do modelu dziedziny systemu (lub komponentów w przypadku złożonych systemów jak w artykule Przypadki użycia i granice systemu). Nie będę więc w tym miejscu powtarzał tych treści, ale pokaże przykłady.
Opisywane tu podejście wymaga przyjęcia standardowych definicji pojęć proces biznesowy i przypadek użycia oraz usługa systemu (tak zwana pragmatyka modeli, powinna być zawsze dołączona do dokumentów analizy). Dwie ostatnie są w UML praktycznie tożsame z procesem biznesowym (A use case is the specification of a set of actions performed by a system, which yields an observable result that is, typically, of value for one or more actors or other stakeholders of the system – czynność lub ich seria dająca jako efekt produkt mający wartość dla aktora, źr. UML 2.4.1. 16.3.6 UseCase). W efekcie zestaw diagramów opisujących organizację z jej systemem informacyjnym, tworzą Architekturę jak poniżej:

Usługa systemu (jego przypadek użycia) może wspierać jeden lub wiele różnych procesów biznesowych, jednak na poziomie procesów elementarnych (tych których już nie dekomponujemy), jeden proces “elementarny” może być wspierany wyłącznie jednym przypadkiem użycia (bo na tym poziomie powstaje jeden produkt). Przykładem jednej usługi wykorzystywanej w kilku procesach może być przypadek zwany CRUD (Create, Retrieve, Update, Delete, czyli Utwórz, Przywołaj, Aktualizuj, Usuń), taka usługa (przypadek użycia typu CRUD) może wspierać procesy: tworzenia, aktualizacji (w tym zmiany statusu) i usuwania dokumentów.
Usługi są realizowane przez określone komponenty (aplikacje), które są instalowane na konkretnych platformach. Z uwagi na to, że komponenty mogą współpracować (wymieniać między sobą dane) mają udokumentowane interfejsy.
Jak pokazać, które komponenty są wykorzystywane w określonych procesach?
Teraz przyszedł moment, w którym pojawiają się często niestandardowe diagramy “wymyślane” w celu “jakiegoś sposobu” na pokazanie związków pomiędzy biznesem (procesy biznesowe) a komponentami oprogramowania. Poważną wadą tych pomysłów jest przede wszystkim to, że są niestandardowe. Po drugie wymagają “ręcznego” wytworzenia, są pracochłonne, mnożą się dodatkowe strony dokumentacji, podnoszą jej złożoność i pogarszają zrozumiałość całości.
Jak sobie z tym poradzić? Tu nieocenione są właśnie dobre pakiety oprogramowania CASE. Poniżej prosty przykład:
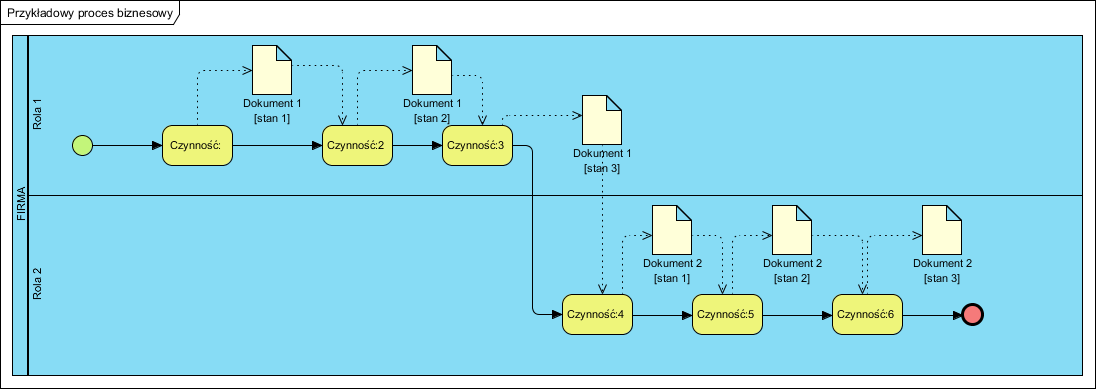
Model procesu biznesowego (proces składa się z elementarnych procesów, każdy ma produkt):
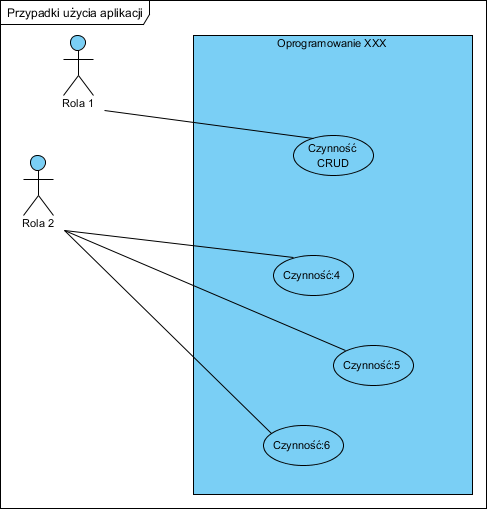
Model przypadków użycia (zachowano nazwy z modelu procesów dla orientacji):
Przykładowa realizacja (scenariusz) wybranego przypadku użycia (na poziomie komponentów, tu celem jest specyfikowanie interfejsu czyli wywołań jednego komponentu przez drugi):

Jak teraz sprawdzić i pokazać związki pomiędzy procesami, przypadkami użycia aplikacji (usługami systemu) i komponentami (aplikacjami)? Zamiast tworzyć nowe sztuczne i niestandardowe diagramy znacznie lepiej jest pokazać to w formie macierzy nie psując np. modeli procesów nieformalnymi zapisami o systemach:
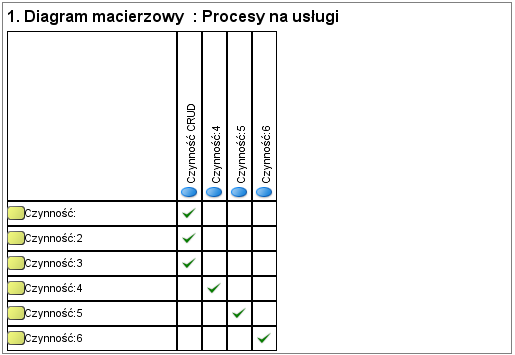
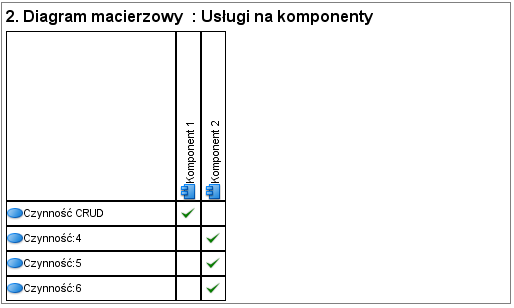
Gdyby potrzebne były bardziej wyrafinowane analizy zależności, możemy stworzyć, zamiast dwuwymiarowej macierzy, taki diagram:
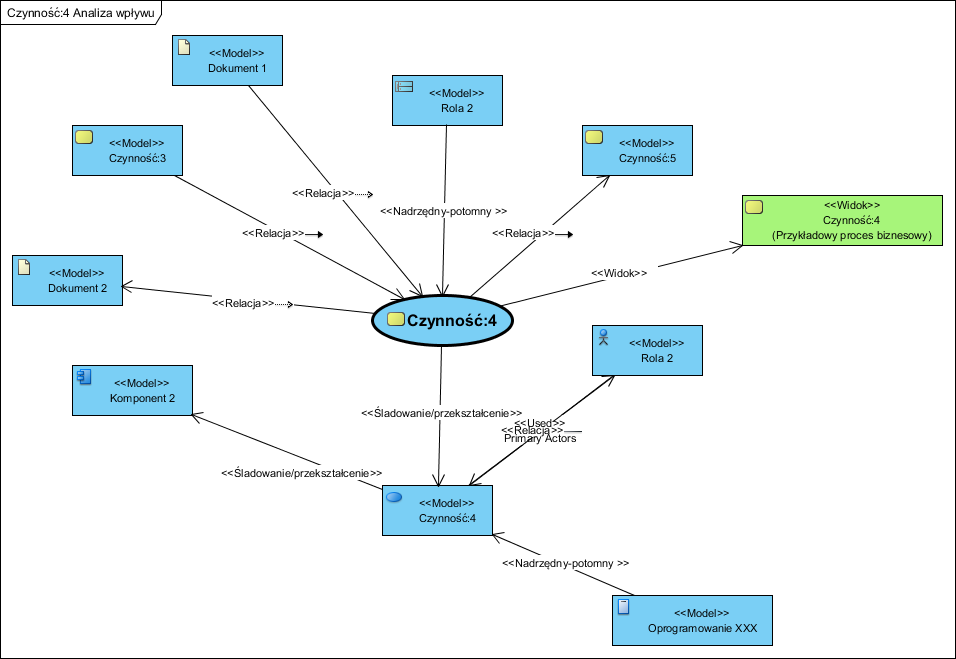
I teraz sedno czyli co nam daje dobre narzędzie CASE? otóż powyższe macierze (takie i każdą inną) oraz model analizy wpływu, są generowane i aktualizowane automatycznie. Wystarczy opracować standardowe modele w BPMN i UML jak powyżej, wskazać związki pomiędzy elementami jako ich parametry (nie trzeba do tego celu tworzyć sztucznych diagramów) i skorzystać z możliwości automatyczne dokumentowania tych związków.
Uzupełnieniem powyższych modeli może być mapowanie dokumentów z diagramów procesów biznesowych na klasy (agregaty) reprezentujące je w oprogramowaniu (komponenty). Tu niestety nie widzę sensu mapowania na “dane w bazie danych” bo celem jest dokumentowanie miejsca przechowywania informacji (komponent) a nie implementacji (baza RDBMS, która jest jedną z wielu możliwych implementacji utrwalania).
Ważne jest by narzędzie bardzo dobrze wspierało specyfikacje notacji oraz metody weryfikowania spójności modeli takie jak śladowanie, podległość modeli, zależności “parent-child” i zagnieżdżanie.
Narzędzia CASE to monopol
Niedawno ktoś mnie zapytał o to czy używanie narzędzia CASE zamyka nas w bańce (ecosystem) jednego dostawcy narzędzia. Po pierwsze diagramy z MIRO, draw.io, Lucidchart czy PlantUML z zasady nie są wymienialne z innymi narzędziami. te narzędzia na pewno zamykają użytkownika.
Dobre narzędzia CASE używają formatu XMI (OMG.org) oraz XPDL (WfMC) do wymiany modeli. W efekcie możliwa jest migracja z bardzo małymi stratami … ale pod jednym warunkiem: modele nie łamią składni notacji .
Ogólnie koncepcja wymiany modeli wygląda tak:
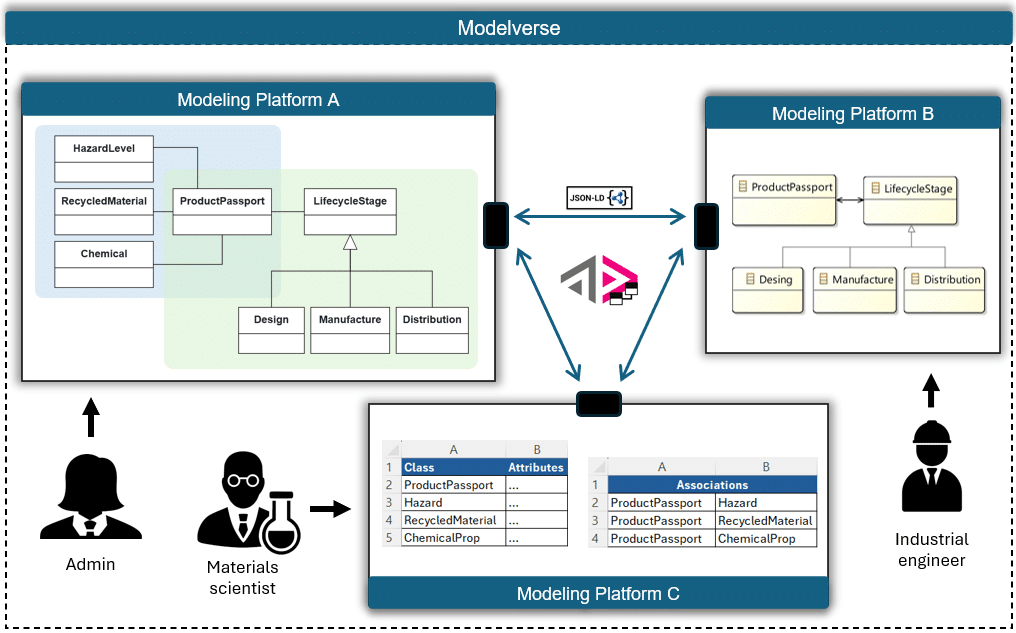
Inny ciekawy artykuł na ten temat: INTEGRATION OF THE MDA APPROACH IN DOCUMENTORIENTED NOSQL DATABASES, GENERATION OF A PSM MODEL FROM A PIM MODEL .
Podsumowanie
Dobrym podsumowanie niech będzie wyjaśnienie Simona Browna (deweloper, znany autor publikacji z obszaru inżynierii oprogramowania, pomysłodawca architektury C4, https://c4model.com/tooling#diagramming-vs-modelling):
Diagramowanie a modelowanie
Krótka uwaga na temat diagramowania i modelowania, ponieważ jest to największa decyzja, jaką trzeba podjąć w odniesieniu do narzędzi. Model C4 może być używany niezależnie od tego, czy używasz narzędzia do diagramowania czy modelowania, ale istnieją pewne interesujące możliwości, gdy przechodzisz od diagramowania do modelowania.Diagramowanie
Jako branża preferujemy tworzenie diagramów (np. Visio, draw.io, Lucidchart, PlantUML, Mermaid itp.) zamiast modelowania (np. Sparx EA, Archi, IcePanel, Structurizr itp.), głównie dlatego, że bariera wejścia jest stosunkowo niska i jest postrzegana jako znacznie prostsze zadanie. Istnieje jednak kilka poważnych problemów związanych z używaniem takich narzędzi do tworzenia diagramów architektury oprogramowania:
- Językiem domeny narzędzi do tworzenia diagramów są “pola i linie”, co oznacza:
- Nie mogą udzielić żadnej pomocy ani zweryfikować twoich diagramów.
- Nie można wysyłać zapytań do diagramów (np. “pokaż mi wszystkie zależności komponentu X”).
- Nie mogą zapewnić żadnej pomocy ani walidacji diagramów.
- Nie można wysyłać zapytań do diagramów (np. “pokaż mi wszystkie zależności komponentu X”).
- Ponowne użycie elementów diagramu odbywa się poprzez kopiuj-wklej – jeśli zmienisz nazwę pola, musisz zmienić jego nazwę na każdym diagramie, na którym się pojawi.
- Wiele narzędzi do tworzenia diagramów ma formaty danych, które są trudne do rozróżnienia, co utrudnia korzystanie z nich na przykład w połączeniu z pull requestami.
Modelowanie
Za pomocą narzędzia do modelowania tworzysz niewizualny model architektury oprogramowania (pojedynczą definicję wszystkich elementów i relacji między nimi), a następnie tworzysz różne widoki (które stają się diagramami) na tym modelu. Wymaga to nieco więcej rygoru, ale problemy można rozwiązać – narzędzia do modelowania mogą intepretować semantykę tego, co próbujesz zrobić, zapewnić dodatkową pomoc, a zmiana nazw elementów / relacji jest łatwa.
(Artykuł powstał z użyciem oprogramowania Visual-Paradigm Agilian, pakiet ten ma moduł do prowadzenia analiz wpływu i zależności).