Kolejna bardzo dobra książka z obszaru projektowania obiektowego. Poprzednia pozycja tego autora (Agile Modeling. Effective…) traktowała o tym kiedy, co i po co modelować. Ta, to bardzo dobry kurs UML na przykładach. Tak, Scott Ambler (nie on jeden) uważa, że modelowanie (szkicowanie) i testowanie pomysłów jest tańsze i szybsze na tablicy (papierze) niż w od razu w postaci kodu (przypomnę, że jest on jednym z sygnatariuszy Agile Manifesto).
Ta książka to jeden z lepszych kursów metod obiektowych i UML jaki miałem w rękach. Kluczem jest rozdział o paradygmacie obiektowym, zrozumienie obiektywności i opis bazujący na pojęciach a nie kodzie. Większość autorów tego typu książek, to ludzie o programistycznym rodowodzie lub aktywni programiści, obiektowość postrzegają przez pryzmat tak zwanego re-użycia kodu i konstrukcji kompilatorów, co jest kompletnym nieporozumieniem, gdyż to języki programowania i kompilatory (lepiej lub gorzej) implementują paradygmat obiektowy a nie odwrotnie.
Ale nie był bym sobą, gdybym nie miał kilku uwag a raczej uzupełnień, gdyż należy zwrócić uwagę, że książka została napisana w 2004 roku (o jej popularności mogą świadczyć dwa dodruki w 2005 roku). Ale po kolei.
Kilka uwag ode mnie
Popatrzmy na poniższe pojęcia:
relationship – stosunek do, powiązanie z (Oxford Dictionary: the way in which two or more things are connected), (SJP powiązanie: wzajemna zależność przyczyn i skutków).
association – dołączenie, skojarzenie (Oxford Dictionary: a connection between things where one is caused by the other), (SJP związek: stosunek między rzeczami, zjawiskami itp. połączonymi ze sobą w jakiś sposób, asocjacja – automatyczne skojarzenie myślowe)
Jest wiele nieporozumień związanych z tymi pojęciami, ich angielskie i polskie tłumaczenia są blisko spokrewnione, dlatego warto tu sięgnąć do źródeł, czyli specyfikacji (https://www.omg.org/spec/UML/) a konkretnie do części Infrastructure specification. Tam w rozdziale 11.3 Classes Diagram, znajdziemy modele pojęciowe między innymi związków i dowiemy się, że asocjacja (association) dziedziczy po związku (relationship).
Popatrzmy na rodzaje powiązań między klasami:
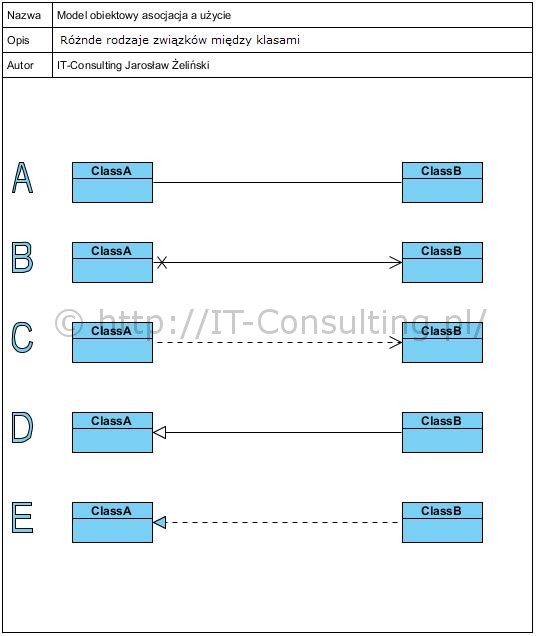
Zostały one uszeregowane od góry od najogólniejszego. Nie będę używał słowa “relacja” bo w języku polskim kojarzy się (a ja zastrzegam to w swoich dokumentacjach) z modelem danych, diagramem ERD (entity relationship diagram). Dlatego w UML mamy (jak wyżej):
A. asocjacja, najogólniejsza jej forma, oznacza powiązanie dwóch klas (w modelach pojęciowych jakiekolwiek),
B. asocjacja skierowana, semantycznie pokazuje kierunek tego związku, można to interpretować tak, że klasa A wie o istnieniu B, a klasa B nie wie o istnieniu A (słowo “wie” można rozumieć także jako “ma w sobie zapisana taką informację”),
C. związek użycia (kolejny rodzaj związku), semantycznie oznacza współpracę klas, tu klasa A korzysta z usługi (wywołuje operację) klasy B,
D. związek generaliza ji, semantycznie oznacza, że klasa B jest specjalną formą (specjalizacją) klasy A, lub że klasa A jest uogólnieniem klasy B, w modelu pojęciowym pojęcie A to uogólnienie pojęcia B (pies jest uogólnieniem ratlerka, lub ratlerek, jest szczególnym przypadkiem psa, konkretny Burek, jest instancją – wystąpieniem: obiektem – klasy ratlerek),
E. związek realizacji, semantycznie oznacza, że klasa B jest specyfikacją (sposobem wykonania, realizacji) abstrakcji jaką jest klasa A (np. interfejs jest realizowany konkretną klasą lub komponentem), realizacja to nie jest forma dziedziczenia, jak twierdzą niektórzy wykładowcy i trenerzy :(.
Asocjacja jest najogólniejszym związkiem (bez żadnych dodatków reprezentuje jakikolwiek związek). Warto też wiedzieć, że związki te są inaczej realizowane. Asocjacje, jako trwałe powiązanie klas (obiektów), to zapis w atrybucie klasy. Związki użycia to wywołania operacji. Związki generalizacji i realizacji są związkami abstrakcyjnymi.
Przypadki użycia
UML to także związki generalizacji na diagramach Przypadków Użycia (UC, ang. Use Case). Używanie ich jednak ma sens czysto pojęciowy, mimo to często widuje koszmarki nazywane nie raz “diagram aktorów”, gdzie np. podwładni “dziedziczą” po swoim przełożonym, co jest kompletną bzdurą. Menedżer rzadko ma umiejętności swoich podwładnych, dotyczy to nie raz także uprawnień (szef zespołu prawników nie raz nie ma uprawnić radcowskich czy adwokackich, żaden mój szef nie miał uprawnień do informacji tajnej a ja mam od 2004 roku, itp.).
Kolejnym koszmarem jest stosowanie diagramów UC do modelowania uprawnień. Generalnie uprawnienia kogoś do czegoś to reguła a nie statystyczne trwałe powiązanie (nawet jeżeli jest to reguła dająca komuś do czegoś prawo, jest to reguła a nie stały związek dlatego, że uprawnienia to coś co zawsze można odebrać).
UML to także związki <extend> i <include>, a służą one do modelowania re-użycia kodu (o czym wspomina także Ambler w tej książce). Stosowanie ich na diagramach UC na etapie analizy i specyfikowania wymagań jest także bzdurą, gdyż o jakimkolwiek re-użyciu kodu można mówić najwcześniej na etapie projektowania implementacji. Po drugie mając w planie wykonanie modelu wewnętrznej struktury aplikacji (diagramy klas i komponentów) modelowanie re-użycia kodu czy nawet re-użycia scenariuszy UC, jest pozbawione sensu, bo jest nadmiarowe i przedwczesne. W razie wątpliwości proszę podjąć próbę skojarzenia diagramów sekwencji z odpowiadającymi im włączonymi (include) przypadkami użycia.
Dwa słowa na temat tak zwanych Systemowych przypadków użycia. Nie są to żadne wewnętrzne UC. Z zasady UC to postrzegana z zewnątrz (przez aktora systemu) usługa systemu, można się spotkać z tym pojęciem (tu u Amblera także) ale w kontekście, takim że system w rozumieniu aplikacja, realizuje konkretne scenariuszowe cele użytkownika (aktora systemu). Innymi słowy usługą systemu jakim jest np. młotek (to prosty system, ma dwa elementy: obuch i trzonek :)) jest uderzanie, a wbijanie gwoździa, wybijanie szyby, uderzanie w dzwon itp. to konteksty aktora. Jednak z perspektywy definiowania aplikacji jest to jeden UC, ma jeden scenariusz: weź do ręki młotek, ustal miejsce uderzenia, uderz, jeżeli nie osiągnąłeś oczekiwanego rezultatu, powtórz.
Modelowanie tak zwanych “systemowych przypadków użycia” jest także pozbawione sensu, gdyż diagram UC nie służy do modelowanie wewnętrznej architektury systemu. Przypadki użycia to usługi aplikacji (pozycje w jej menu) i raczej jest jedna usługa np. “Konfiguracja” a nie Ustaw, Włącz, Wyłącz, Zmień, itp… Te celowe działania to treść modyfikowanego formularza.
Przypomnę, że książka ta powstała w 2004 roku (na co trzeba brać poprawkę czytając ją, pojawia się w niej dziedziczenie), w czasie gdy nie było jeszcze mowy o powszechnym użyciu notacji BPMN, a diagramy aktywności są dość ułomne i zarazem zbyt złożone do tego celu (o czym świadczy rosnąca stale popularność notacji BPMN i spadek popularności diagramów czynności do modelowania procesów biznesowych).
Niestety i w literaturze i w materiałach szkoleniowych, czy nawet dydaktycznych na uczelniach (o zgrozo) można się spotkać z takimi “antywzorcami” jak wyżej. Jednym z najbardziej kuriozalnych jest obecnie modelowanie danych z użyciem diagramu klas, nanosząc na nie np. jeszcze klucze główne (znalazłem coś takiego w pewnym podręczniku akademickim!). Niestety bardzo często autorzy tych materiałów, wykładowcy i trenerzy, zamiast korzystać ze źródeł, przepisują jeden od drugiego pogłębiając marazm w tej dziedzinie, a pierwowzorem wielu tych herezji są niestety materiały publikowane przez firmę SPARX (producent oprogramowania Enterprise Architect) jak choćby mój ulubieniec: czas jako Aktor systemu (co opisałem tu).
Na zakończenie
Tak więc książkę Scott’a Amblera gorąco polecam, analitykom szczególnie, programistom także.
The Object Primer 3rd EditionAgile Model Driven Development with UML 2Cambridge University Press, 2004 ISBN#: 0-521-54018-6 (Źródło: The Object Primer 3rd Ed: Agile Model Driven Development (AMDD) with UML 2)




Witam,
Tak się złożyło ze omawiana pozycja wpadła w moje ręce jakiś miesiąc temu. Generalnie zgadzam się z Twoją opinią o książce i o tym, że jednak trzeba brać pod uwagę datę jej wydania i nie traktować, jako wyroczni (szczególnie właśnie pod kątem wykorzystania tandemu BPMN i UML w obecnych czasach).
Właśnie w tym kontekście mam parę pytań. W sowim tekście piszesz:
“UML to także związki i , a służą one do modelowania re-użycia kodu (o czym wspomina także Ambler w tej książce). Stosowanie ich na diagramach UC na etapie analizy i specyfikowania wymagań jest także bzdurą, gdyż o jakimkolwiek re-użyciu kodu można mówić najwcześniej na etapie projektowania implementacji”
Osobiście przy modelowaniu Use Casów nie myślę o kodzie, a o ustandaryzowaniu pewnej sekwencji kroków. Główna zaleta jest tutaj ujednolicenie pewnych standardowych czynności dla końcowego użytkownika, za czym zgadzam się może iść w przyszłości ustandaryzowana realizacja. Dlatego jeśli w różnych miejscach systemu będzie potrzeba, aby użytkownik “wybrał osobę z listy pracowników “to stworzę taki use case i będę go “re-“używał w wielu miejscach, aby użytkownik, nie musiał wybierać tej osoby za każdym razem inaczej.
I w tym miejscu po raz kolejny przytoczę Twoje słowa:
“Modelowanie więc tak zwanych ?systemowych przypadków użycia? jest dzisiaj pozbawione sensu, szczególnie gdy poprzedzamy tworzenie modelu UC utworzeniem modeli procesów biznesowych. Na tych modelach będą właśnie czynności i kontekst użycia młotka.”
Nie mogę się zgodzić z taką opinią, szczególnie jeśli nie podałeś większej ilości informacji do jakiego poziomu szczegółowości będziesz modelował procesy biznesowe. Tylko CIM czy tez PIM?
Logicznym jest, że gdzieś granica sensowności użycia BPMNa się kończy i właśnie w tym miejscu zaczyna się obszar gdzie warto używać Use Caseów, scenariuszy lub/oraz diagramów aktywności, aby zaprojektować ten bardziej przyziemny poziom interakcji użytkownika z systemem.
Moim zdaniem proces biznesowy, który jak mówisz powinien nadać kontekst dla Use Casea, nie zawsze będzie to robić, ponieważ z perspektywy celu procesu biznesowego “wybór osoby z listy pracowników” jest małoistotnym krokiem w jednym z zadań (task) całego procesu i informacja o takich “szczególikach” tylko by zaśmieciła diagram procesu. Natomiast dla Use Casea jest już odpowiedni.
Obrazowo chodzi mi o taki przykład: Mamy proces, w którego skład wchodzi zadanie “Task A”. “Task A” jest realizowane przez “Use Case 1” (tutaj używamy relacji Trace aby “połączyć” BPMN i UML). Natomiast “Use Case 1” wywołuje (relacja include) jako jeden ze swoich kroków “Use Case wybór osoby z listy pracowników”. Zatem jeśli już, to “Use Case 1” nadaje kontekst dla elementarnej czynności: Twój młotek, mój wybór osoby.
PS. Dla większości początkujących programistów “re-użycie” kodu to jest jego dziedziczenie, co w wielu przypadkach powoduje więcej skutków ubocznych niż korzyści.
PS2. Copy-paste, lub jak to ktoś ładniej opisał “encapsulate and reuse” to też ponowne wykorzystanie kodu, dosłownie 😛
PS3. Z ciekawości zajrzałem na strony Sparxa, jakoś nie znalazłem przykładu aktora Czas. Może Sparx już zweryfikował swoje podejście?
Pozdrawiam serdecznie,
Paweł
Co do przypadków użycia:
– kolejny krok, po powstaniu/zadeklarowaniu przypadku użycia (PU), to opisanie scenariusza na diagramie sekwencji, jeżeli użyjemy “wyłączania części do re-użycia” to jak to pokażesz to na tych diagramach (sekwencji)?
– dobrze zaprojektowany PU nie dubluje innych :), co najwyżej pojedynczy krok scenariusza będzie się powtarzał w kilku PU ale tylko dlatego, że w modelu dziedziny będzie go realizowała ta sama klasa i jej operacje, ale żeby to wiedzieć musi być znana architektura, czyli na etapie PU to falstart,
– diagram PU to kluczowy i ostatni zarazem, zrozumiały dla zamawiającego materiał, nie poznałem “zwykłego i zdrowego człowieka”, który bez problemu “poprawnie rozumie” związki extend i include, wiec po co?
– model PIM to nie procesy biznesowe a już architektura, co do szczegółowości modeli procesów to robię to “po bożemu” czyli proces to co najwyżej “atomowa” konstrukcja “wejście, aktywność, wyjście” odpowiadająca jeden do jednego przypadkowi użycia rozumianemu jak w UML (stan początkowy i końcowy, aktywność dająca kompletny i wartościowy produkt aktorowi),
– na modelach procesów nie modeluje się “tego jak wypełnić nośnik danych” (formatkę) więc na modelu procesów nie powinien się pojawić krok ?wybór osoby z listy pracowników?, na diagramie UC będzie to raczej wymaganie pozafuknconalne: “łatwość wprowadzania danych”, a na makiecie (mock-up) dopiero prototyp: “opadająca lista pracowników”.
P.S. część tego co powyżej napisałem to przyjęta konwencja, ale definicja procesu biznesowego to jej część,
P.S. O aktorze-czasie między innymi tu: czytaj artykuł, co do SPARX’a, w EA wsadzili nawet przedefiniowany stereotyp dla aktora z zegarkiem jako twarzą ;), a tu masz na ich stronie kuriozum “aktor to event” którym może być czas…
Osobiście już dawno podziękowałem firmie SPARX i za ich “mądrości” i za ich produkt 😉
Dzięki za odpowiedź.
Jeśli chodzi o pierwszy punkt, to nie używam diagramów sekwencji do wizualizacji diagramów, z racji tego, że w mojej opinii są one zbyt trudne do zrozumienia dla “zwykłego zjadacza chleba” szczególnie, gdy mamy alternatywne przebiegi.
Osobiście wole używać diagramów aktywności, w momencie gdy mam w diagramie aktywności krok realizowany przez “includowany” PU, używam Call Behavior Action co pozwala mi zachować spójność syntaktyczna modelu (analogicznie jak w BPMN można w procesie odwołać się do podprocesu).
Zgadzam się z twierdzeniem, że ” diagram PU to kluczowy i ostatni zarazem, zrozumiały dla zamawiającego materiał”. Cieszę się, że wspomniałeś o konwencjach, ponieważ też ich używam. Osobiście podoba mi się podejście Volere, które mówi o Business Use Case i Product Use Case. Moja konwencja jest taka, ze BUC to jeszcze CIM, a PUC to już PIM. Dlatego w BUCach nie używam ani include ani extend, z racji tego aby opisane przypadki użycia były bardzo proste do zrozumienia dla laików. I tak w BUCach zdarza się duplikowanie pewnych kroków. Jednak PUCe, które niejako “realizują” i “uszczegółowiają” BUCe to już dokumentacja/projekt dla trochę innej kategorii interesariuszy, dlatego w nich pozwalam sobie na szersze wykorzystanie tego, co UML oferuje (include, extend).
Dalej piszesz “na modelach procesów nie modeluje się ?tego jak wypełnić nośnik danych? (formatkę) więc na modelu procesów nie powinien się pojawić krok ?wybór osoby z listy pracowników?” ? tak jak najbardziej się z tym zgadzam. Chyba nieprawidłowo odczytałeś mój przykład, bo to nie było moją intencja. Chodzi mi o to, że w artykule piszesz, że proces biznesowy nadaje kontekst użycia młotka, a ja uważam, że na ogół proces biznesowy jest (i powinien być) zbyt abstrakcyjny, aby ten kontekst jednoznacznie i dokładnie określić. Innymi słowy proces biznesowy “tworzenie rzeźby” i proces biznesowy “budowa altany” nie zawierają informacji jak trzymać młotek, która stroną uderzać i z jaką siłą ? bo to po prostu zbędne szczegóły na poziomie procesu.
Odnośnie Post Scriptum:
Co do IBMa to nawet nie chce mi się komentować, powiem tylko, że używałem trochę Rational Software Architect i mi wystarczy na całe życie 🙂
Co do Sparxa to faktycznie, nie zawsze traktują specyfikacje UML dosłownie i nie zamierzam ich bronić pod tym względem. Dla mnie EA ma wiele innych zalet ? ale to już inna dyskusja.
Natomiast, jeśli chodzi Ci o wzmiankę na stronie Sparxa, która podałeś “[Actors] There can also be events which are triggered without the involved parties (e.g. time events).” ? to musze przyznać, że ciekawie się to łączy z koncepcją “Business Event”, czyli bodźca wywołującego Business Use Case w Volere.
Polecam Ci książkę autorów podejścia Volere do analizy: Mastering the requirements process. Moim zdaniem jedna z lepszych książek o analizie biznesowej wydana w ostatnich latach. Nawet jeśli pewnie koncepcje Ci nie będą pasowały (bo masz już wyrobiony i dojrzały warsztat) to warto się zapoznać z tym podejściem.
Pozdrawiam
Diagram sekwencji jest jedynym, pozwalającym przetestować logiką aplikacji (także integracji). te diagramy nie są adresowane do użytkownika, to narzędzie analityka, uwiarygadniające projekt i jego logikę. Użytkownikowi pokazuję co najwyżej scenariusz UC w postaci wypunktowanej listy kroków dialogu aktor-system (diagramów aktywności też nie raz nie rozumieją:)). Co do diagramów aktywności są mało przydatne do dokumentowania scenariusz PU, gdyż tu należy pokazać komunikacje obiektów: wywołania ich operacji, czego nie robi diagram aktywności.
Diagram aktywności powstał w czasach gdy nie było BPMN, w zasadzie służy to opisowego modelowania “wewnętrznych procesów”, nie jest w stanie zastąpić diagramu sekwencji: wywołań obiektów i ich operacji.
Z prostoty UML i powodów opisanych w MDA nie używam UC inaczej niż w specyfikacji UML: UC to usługa aplikacji i nic innego. Owszem w latach 90-tych, stosowano w RUP diagram PU do modelowania organizacji (aktor i UC biznesowy), wtedy aktor to był np. Klient firmy, a “złożenie oferty” to by “przypadek użycia” tej organizacji, ale zarzuciłem całkowicie to podejście jakieś 10 lat temu bo w dokumentach powstawały niejednoznaczności i pojawił się BPMN. Obecnie z zasady stosuje jeden typ diagramu do konkretnych zastosowań, zgodnych semantycznie z UML/BPMN/BMM.
Proces biznesowy to łańcuch aktywności, każda ma stan początkowy i końcowy czyli wejście i wyjście, analogicznie jak przypadek użycia (OMG harmonizuje definicje pojęć w notacjach). W efekcie aktywność wbicia gwoździa wymaga użycia młotka, nadaje kontekst tej pracy. Inna aktywność, np. wybicie szyby także wymaga użycia młotka. Młotek zostaje użyty dokładnie w ten sam sposób (scenariusz przypadku użycia – usługi jaką świadczy młotek to zawsze uderzanie) ale kontekst wynika z procesu. Zbudowanie altanki to łańcuch aktywności mających swoje pośrednie skutki (produkty), to łańcuch podprocesów.
Rationale… cóż, też nie używam ;). Co do Volere, hm… nadbudowa, której nie uznaję bo moim zdaniem “prosty” UML/MDA wystarczy. Jestem zwolennikiem Brzytwy Ockhama :). Z tego samego powodu całkowicie odszedłem od pojęcia z poza UML jakim jest “Business Use Case” (j.w. RUP lat 90tych odszedł).
“Mastering the requirements process” znam, powstało gdzieś 1995 roku i są kolejne wydania (w 1995 r. nie było mowy o BPMN a UML raczkował), bazuje na koncepcji RUP Business Use Case i znanych z analizy strukturalnej funkcjach i danych. Tego typu metod jest dużo. Nie mam zaufania to metod opartych na analizie strukturalnej, preferuję MDA.
Fakt, że mam chyba “wyrobiony warsztat” :). Z każdym kolejnym projektem upraszczam go a nie rozbudowuję ;). Obecnie jest to w 100% zestaw OMG (BMM/BMM/BPMN/UML/SysML/SoaML), które OMG zharmonizowało (dokument core concepts …, np. elementarny proces bazujący na aktywności w BPMN to przypadek użycia o ile planujemy tę aktywność zawrzeć w zakresie wymagań wobec systemu – aplikacji). Opisane i wymagane w BABOK śladowanie to przejaw tego podejścia (n. wyprowadzanie UC z aktywności w procesach, mapowanie nośników danych BPMN na agregaty w modelu dziedziny z użyciem UML/Diagram klas itp.).
Generalnie można mieć określone swoje podejście i metody pracy, jest więcej niż jedna, jeżeli tylko dają dobre efekty to OK :). Ja preferują metody korzystające z możliwie najprostszych narzędzi, dla mnie to “pure UML” itp. Dzięki temu produkty są do wykonania w każdym narzędziu zgodnym z notacjami OMG i są wymienne (treści nie wykraczają poza standardy), nie stosuję metod objętych prawem autorskim (ryzyko opłat licencyjnych za produkty pracy i szkolenia itp.., z tego powodu całkowicie odszedłem od TOGAF/ArchiMAte), a niestety Volere (jak i inne podobne) jest chronione prawami autorskimi ich twórców (http://www.volere.co.uk/licensing).