W dniu 11.12.2020, udało mi się w końcu przeprowadzić prezentację on-line. Celem była prezentacja realizacji metody MBSE z narzędziem CASE (tu Visual-Paradigm) i jej efektów. Adresatem są zarówno analitycy, architekci oprogramowana jak i developer (programiści) jako ostateczny adresat dokumentu. Podobną prezentację prowadziłem wcześniej na Konferencji beIT 2020. Popularność tych prezentacji spowodowała, że całość przerodziła się w projekt badawczy.
Krótkie wprowadzenie
Wykonanie analizy i opracowanie takiego projektu (zakres taki jak ta biblioteka) to pracochłonność rzędu dwóch moich dni samodzielnej pracy z dokumentami źródłowymi (ma je każda działająca organizacja, start-up’y mają biznesplany). Kolejny etap to wybór developera i mój nadzór autorski nad jego pracami (dalszy komentarz na końcu artykuły).
Dla porównania efekty zastosowania metody opartej na przekazaniu projektu od razu developerowi (metoda zwinna): Library, DDD/Event-storming, jest to nawet kilkanaście dni pracy nie jednej osoby a całego zespołu. Projekt ten zawiera nadmiarowe elementy komplikujące kod, co podnosi koszty jego wytworzenia a potem utrzymania. Jest to typowy efekt tego typu metody pracy (nie komentowałem tu szerzej tego ale zainteresowanych proszę o porównanie tego z moją architekturą). Warto wiedzieć, że także sam fakt użycia relacyjnego modelu danych i zapytań SQL (plus ewentualne mapowanie ORM) znakomicie podnosi pracochłonność (czyli koszty) na etapie tworzenia oprogramowania, oraz wymusza także dodatkowe prace w późniejszych pracach rozwojowych (każda poważniejsza zmiana to migracja do nowego modelu danych i refaktoring całości). Baza danych będzie tu nawet kilkanaście razy bardziej skomplikowana niż w moim projekcie (tylko trzy dokumenty), korzystanie z niej także.
Architektura i wzorce projektowe
MVC
Projekt w prezentacji jest oparty na wzorcach projektowych:
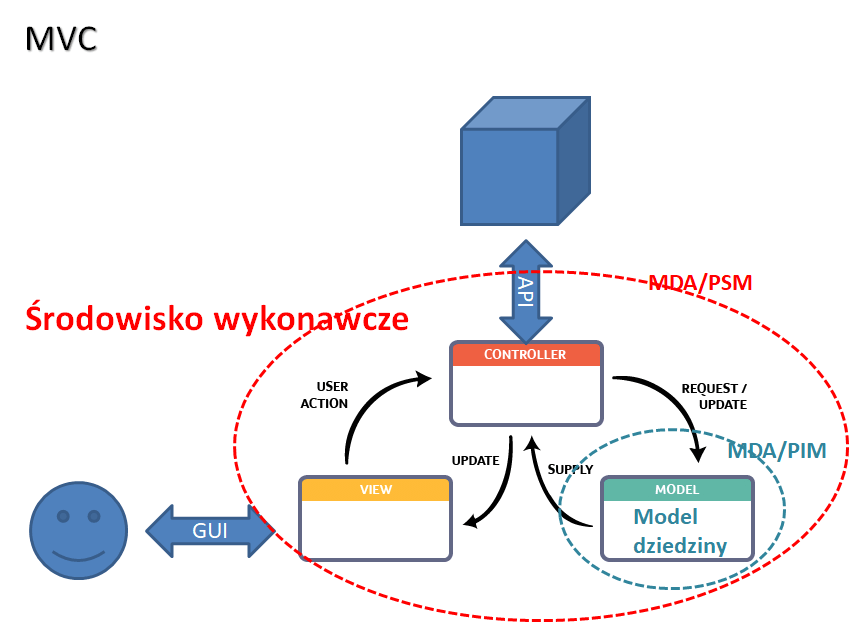
Skutki tego wzorca? Poniższy diagram obrazuje separację:
- Application Core (Model)
- User Interface (View)
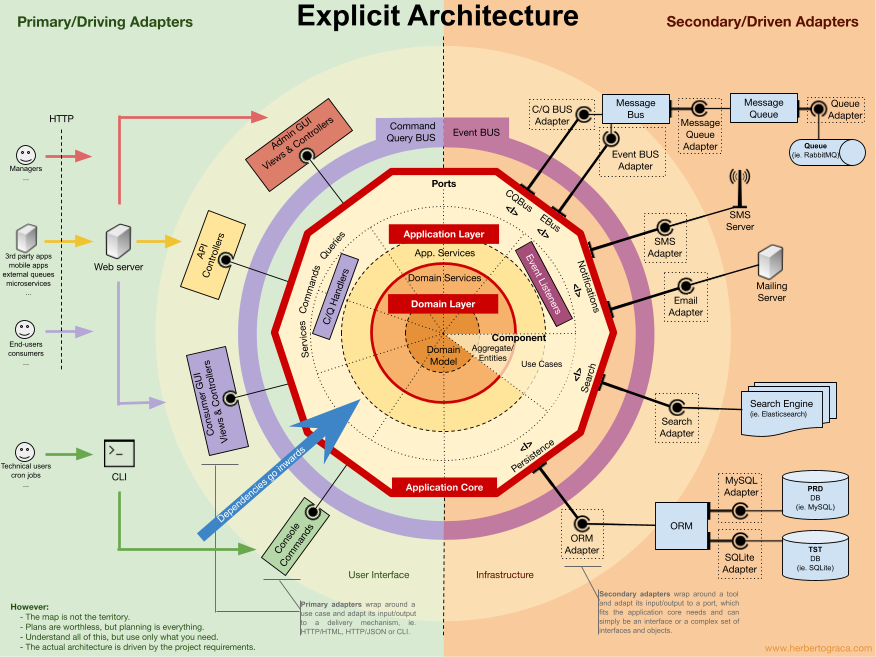
- Infrastructure (Controller) – jest to Aplikacja we wzorcu “porty i adaptery” (architektura heksagonalna):
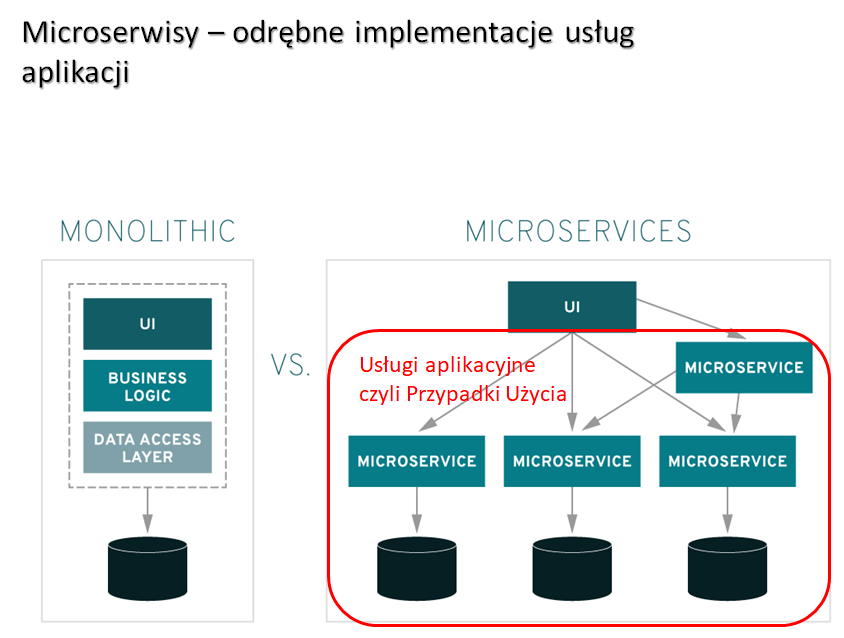
Mikroserwisy
(w literaturze przedmiotu, dla odróżnienia od technologii i środowiska wykonawczego mikroserwisów, stosowane jest także pojęcie “mikro aplikacji” (MicroApp)).
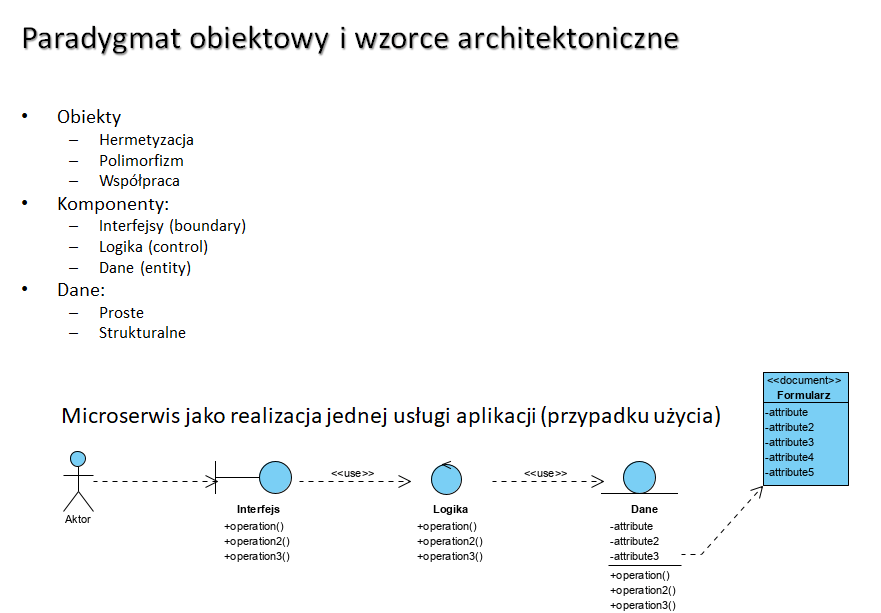
Paradygmat obiektowy
Obiektowo-komponentowa architektura na bazie wzorca BCE i dokumentowym modelu danych:
Prezentacja
Opis
W toku prezentacji pokazuję co robię, nie objaśniam użytych narzędzi, gdyż w tym przypadku nie było moim celem. Prezentacja ma dość duże tempo, celem była pokazanie metody MBSE i zalet pracy z narzędziem CASE.
Pokazałem kluczowe etapy pracy. Pierwszy to analiza tekstu źródłowego. Od wielu lat z powodzeniem stosuję metody pozyskiwania wiedzy o badanej organizacji oparte na “dowodach” (evidence-based analysis, ), czyli na faktach opisanych w dokumentach (prawo, wewnętrzne regulaminy, dokumenty operacyjne takie jak dowody księgowe, umowy, zamówienia, dokumenty przychodzące, itp.).
W czasie pokazu powstawał projekt oprogramowania dla Biblioteki. Podstawowe źródło wiedzy o tym jak działa biblioteka to Regulamin Biblioteki.

Na podstawie analizy tego tekstu powstał słownik kluczowych pojęć oraz tak zwany model pojęciowy, czy graficzna forma słownika (tu fragment):

Powstał model procesu biznesowego wypożyczeń:

z którego wiemy, że kluczowym dokumentem w tym procesie jest jest Karta Wypożyczenia (formularz, dane):

Po analizie procesu powstaje zakres projektu (wyrażony jako wymagane usługi aplikacyjne w notacji UML: przypadki użycia):
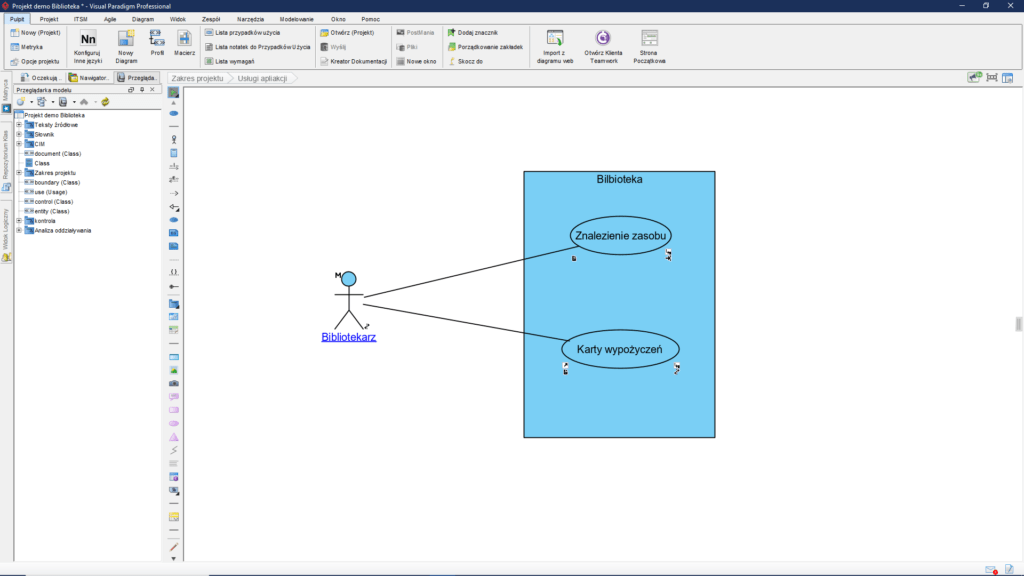
Jednym z kluczowych elementów jest scenariusz realizacji tej usługi, do jego opisu potrzebna jest jednak architektura realizacji usługi (model PIM):
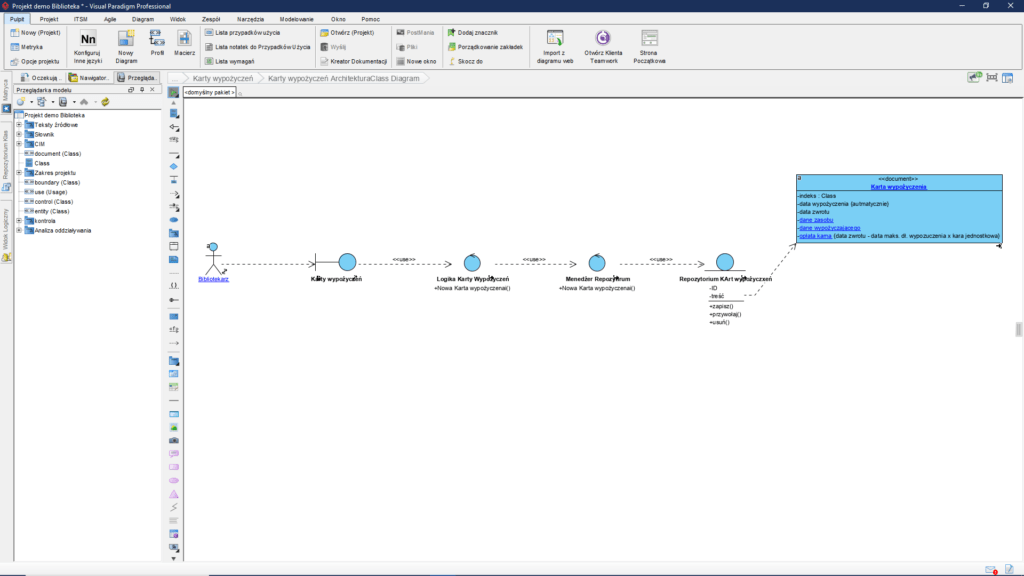
Na jego podstawie powstaje scenariusz:

Poniżej zapis prezentacji, na której pokazano jak powstały ww. elementy projektu. Na końcu zobaczycie także jak prowadzę zdalna komunikację i jak powstaje pełna dokumentacja całkowicie bez użycia oprogramowana biurowego.
Nagranie
UWAGA! Projekt jest aktualizowany, zawartość pliku do pobrania odbiega już nieco od powyższego.
Analiza biznesowa i projekt aplikacji – dokument do pobrania
W ramach prezentacji powstał dokument stanowiący produkt pracy analityka projektanta. Poniżej jego pełna wersja: Analiza biznesowa i kompletny projekt techniczny. Plik zawiera przykłady użycia diagramów BPMN i kluczowych diagramów notacji UML (dokument jest stale aktualizowany, jego obecna treść odbiega nieco od nagrania powyżej.
Celem projektu jest także porównanie
Np. uzyskanego efektu (czas i koszt uzyskania spełniającej wymagania aplikacji) z produktem metody “event storming”(eventstorming): https://github.com/ddd-by-examples/library. Inne miejsce do porównania: Język UML ? projekt sklepu komputerowego, materiał na PJWSTK Metody budowy diagramu klas.
Inny przykład do porównania:

Na wszelkie pytania do treści tej prezentacji i Raportu z analizy i projektowania, odpowiadam pod tym artykułem. Będą tu także publikowane anonse o udostępnieniu do pobrania aktualizacji plików projektu.
W 2013 roku, opublikowałem inny, bardzo prosty projekt gdy w szachy, wykonany identyczną metodą (w końcu mamy MDA i tego UML i BPMN od dawna), zapraszam do lektury: Plansza do gry w szachy czyli analiza i projektowanie.
Agile vs analiza i projektowanie
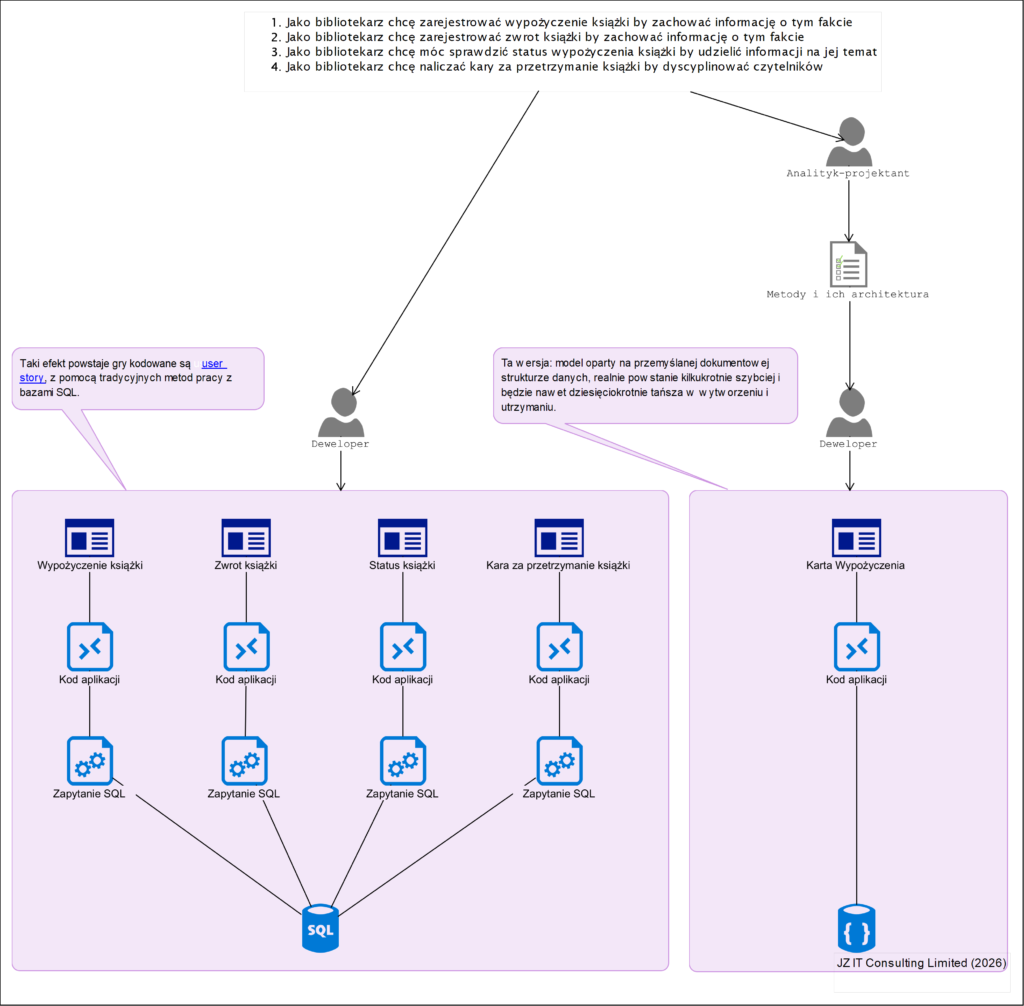

Ciężko przełożyć to na kod jednak lepiej jak ogarnięci deweloperzy przeprowadzą dobry event storming, potem znajdą domeny/poddomeny bounded contexty i ich mapę. Łatwiej jest znaleźć agregat jeśli jest jakaś złożonosc i tam zrobić DDD czyli w core domain na tym na czym się ma przewagę biznesową.
Na tym etapie jest to logika i bazowa architektura. Są kluczowe pojęcia i szablony formularzy. Jestem ciekawy czego tu konkretnie nie ma? Zakładam, że zestawienie środowiska developer wykonuje sam.
Dokument już zawiera więcej informacji dla developera.
@Jarek: Odpowiadając na pytanie “Czego tu nie ma” na pewno w trakcie analizy nie udało się odkryć kilku kluczowych pod-domen, np dostępności. Rzeczowniki pokazały “powierzchnię” – to jak rozumuje nieświadomy user, ale głęboki model (deep model u Evansa) jest nieodkryty i będzie “straszył” przez komplikację reguł… Tu więcej https://github.com/ddd-by-examples/library
Dokument jest na etapie rozwoju 🙂 (jest uzupełniany, bo faktycznie jest ubogi jeszcze). Czym tu jest “dostępność”? Jaką “powierzchnię”? Deep model ok, czyli co 🙂
Mam nadzieję, że wywiąże się tu jakaś dyskusja bo moim celem jest między innymi rozwiązanie problemu slangu developera. Znakomita większość moich klientów ma bardzo złe doświadczenia i wrażenia po “event stormingach” z developerami 😉 bo po prostu nie rozumieją ani pytań ani odpowiedzi ale płacą wiec siedzą ;). Ja zaś dostaję jakieś notatki po tych spotkaniach i też mam niemały problem.
To zaś: jest dokładnie tym czego chcę unikać czyli np. eventy: pobranie i zwrot książki. A osobiście stoję na stanowisku, że zwrot to przywołanie istniejącej już karty wypożyczenia i wstawienie daty zwrotu. Po event stormingu dostaję zawsze masę spisanych “akcji”, które tak na prawdę są klikaniem różnych pól tego samego formularza. Dlatego zawsze od razu jadę na makietach formularzy. Podobnie w kwestii reguł i zdarzeń: przetrzymanie książki to stwierdzenie faktu w momencie kontroli lub zwrotu, to sie samo nie robi :). Ale ciekawy jestem efektu. Lada moment kolejna wersja 🙂
Możemy to potraktować jako dyskusję porównującą te metody: “event storming: i “form (document) oriented design” 🙂
Pierwsze moje wrażenie z tego co podlinkowałeś to ogromna złożoność i liczba rzeczy, czytaj: mega pracochłonności samego tego warsztatu i zarzadzania jego produktem.. a Podejście zorientowane na dziedzinę i dokumenty, już po krótkim badaniu pojęciowym pokazuje, że operujemy wyłącznie opisem książki (zasób biblioteczny) i opisem faktu wypożyczenia (Wypożyczenie, albo Karta wypożyczenia). Kara za przetrzymanie to cecha Wypożyczenia (czas od daty wypożyczenia do daty zwrotu), i spokojnie można ja implementować później. Wszelkie uprawnienia to tylko reguły operujące na stanie sesji (kto zalogowany) i rodzaju dokumentu (np. Wypożyczenie jest edytowalny tylko gdy zalogowany jest bibliotekarz) i to reguła Bibliotekarz może nadpisać kartę wypożyczenia.
Całość 9dwa typy dokumentów) pakuję do bazy NoSQL i po krzyku. Logika aplikacji to dwa formularze, słowniki pól i reguły dla nich.
Nie ma tu żadnych “poddomen”, o ile pod pojęciem domena rozumiemy:
domain – an area of interest or an area over which a person has control:
– the domain of polymer science
– public and private domains
I tak jest rozumiana także u Evansa. Tak więc dostępność książki i jej wypożyczenie to nie są dwie domeny. Nie wiem co masz na myśli pisząc “Rzeczowniki pokazały ?powierzchnię?”. Głęboki model to wewnętrzna architektura realizacji usług i scenariusze z użyciem jej elementów: tu jest nawet dość dokładnie zamodelowana…
W tym co linkujesz “library/docs/” są niestety mało wartościowe wybiórcze konteksty użytkownika w stylu “new day started”…. co to jest???
To jest temat chyba na serię kilku, godzinnych rozmów na video. Trzeba by wziąć kilka kejsów i pokazać co robimy i dlaczego robmy. Rzucę kilka myśli, bo trzeba by ustalić wspólny kontekst aby móc dalej dyskutować.
Pierwsza rzecz to klasa problemu:
– czy robimy coś, co z góry wiadomo jak działa, ma działa tak samo, tylko w nowym systemie, bo nowy będzie lepszy (pytanie po co nowy, skoro ma działać tak samo)
– szukamy jak coś ma działać, walidujemy pomysły, ale nie chcemy robić tej walidacji kodem, bo to kosztuje czas (pieniądze teraz wszyscy mają na it;)
– odkrywamy jak działa jakieś legacy
To byłoby pierwsze założenie. Bo przykładowo tak jak piszesz “wstawienie daty zwrotu” to już sugerowanie jakiegoś rozwiązania. Że jest jakaś data i się ją wstawia. Ok być może modelując nowy biznes dojdziemy do takiej decyzji. Jeżeli modelujemy istniejący, in oni teraz wstawiają sobie jakieś tam daty gdzieś, to pytanie, czy zawsze, czy są inne sposoby dokonania zwrotu? A może nie chodzi o zwrot o powrót zasobu do puli dostępnych. A może zależy od kontekstu z jakiego patrzymy? Zwrot to pojęcie z kontekstu kar/reputacji klienta z dostępność to kontekst inwentarza? Czasem coś zachodzi w obu kontekstach a czasem tylko w jednym? To jest ten głęboki model. I nie oczekuję, że “zwykły user” mi takie coś poda na tacy, bo nie tego się od niego/jej oczekuje.
Modelowanie faktów, że coś tam wpisano do bazy, skończy się crudem… Czy to źle? Niekonicznie, jeżeli faktycznie chcemy cruda. Ale jak pojawi się potrzeba “task based UI” bo nikt nie będzie umiał obsługiwać UI crudowego to okaże się, że pod spodem mamy tylko model danych a nie biznesu.
Dalej co do tych formularzy… Jak zmienię formularz (bo np ux designer tak uzna, albo na telefonie mam mniej miejsca) to zmienia mi się model biznesu? Czy to tylko “wziernik” do systemu, jeden z wielu.
I jeszcze odnośnie tych crudów i modelowania formularzem: jak by wyglądał model takie np allegro? :PPP Tam jest guzik kup teraz i dugi zapłać. Pod spodem wg oficjalnych danych 1200 microservices i pewnie w sumie grubo ponad 1k ludzi w developmencie.
A dalej jak przejdziemy w architekturę rozwiązania i mocroservices. Jak zapewnić Single Source of Truth aby uniknąć antywzorców Feature Envy i Data Envy? Zrobimy te micro i się o każe, że każdy rozmawia z każdym. Nie ma żadnej autonomii w sensie: a) niezależne pracy zespołów i b) możliwości pracy części systemy mimo awarii/przestoju innych. Trze trzeba wziąć pod uwagę w analizie. Gdzie są źródła prawdy, gdzie komendy, które do nich trafiają? Jakie są główne pytania biznesowe, których źródła prawdy modelujemy?
Tutaj przykład: przytoczona przeze mnie “dostępność” – wdzięczny przykład, bo każdy biznes, który obraca jakimiś skończonymi dobrami (książki, hulajnogi, pokoje w hoteli itd) na tym stoi oraz często jest to źle zrobione 😛 Jest pytanie: czy książka jest dostępna? W sensie czy są jakieś egzemplarze danego tytułu? Co ma na to wpływ? Czy są wydane komuś, czy są planowane konserwacje, czy jest kolejka oczekujących. Jak sobie zrobimy naiwnie 3 mikroserwisiki, z których każdy ogarnia: wypożyczenia, konserwacje i rezerwacje to teraz każdy musi z każdym rozmawiać, aby wiedzieć jaka jest dostępność. No i mamy kolejną katastrofę architektoniczną….
Fakt, temat na długą dyskusję, dlatego ją tu prowokuję.
Co do zasady: nie łapiemy się za tworzenie oprogramowania jak wiemy komu i do czego ma służyć, dlatego kluczem jest opracowany spójny model procesu biznesowego, z którego od razu wiesz, że są tylko dwa dokumentu: Karta książki i Karta wypożyczenia.
Wstawienie daty zwrotu to nie sugerowanie rozwiązania a stwierdzenie faktu że tak to działa 🙂 (tu się kłania ontologia).
Na tym etapie pracy (projektowanie) z zasady trzymam się z daleka od bazy i SQL. Operują dokumentem. Jak ktoś nie nie potrafi zaprojektować systemu nie używają SQL to znaczy, że ewentualnie używa AMAZON lub AZUR co najwyżej jako hostingu…
Jak ja zaprojektuję treść formularza i jego logikę (czyli przetestuję że wszystko działa) o to UX może co najwyżej dorobić formatowanie i kolory, jak zmieni strukturę formularza to wyleci z projektu 🙂
Allegro (generalnie aukcje i sprzedaż) wbrew pozorom to kilka formatek i złożona lista reguł. Masz tam: Kartę produktu, Kate klienta, Kartę sprzedawcy, Koszyk, Kartę zamówienia, List przewozowy, Kartę płatności. Właśnie projektuję kolejny taki system…
Mikroserwisy to temat rzeka, ja się trzymam starej zasady, mikroserwis to samodzielny komponent realizujący określoną usługę, te zaś z reguły zarządzają dokumentami (ale nie zawsze). Jak każdy gada do każdego to jest to dramat projektanta :).
Określenie dostępności książki lub jej rezerwacji jest banalnie proste: w bibliotece operujemy ich egzemplarzami, bo każda ma unikalny numer indeksu. Model dziedziny, w którym masz książkę i jej ilość jako jej cechę (atrybut), jest chyba najgorszy z możliwych. 😉 Ja nie miewam takich katastrof ;).
Pytasz “? czy robimy coś, co z góry wiadomo jak działa, ma działa tak samo, tylko w nowym systemie, bo nowy będzie lepszy (pytanie po co nowy, skoro ma działać tak samo)”
Rzecz w tym, że w znakomitej większości ma właśnie działać tak samo: nadal tak samo liczymy kary, nadal tak samo kontrolujemy dostęp, nadal tak samo przyjmujemy i brakujemy zasoby, itp…. paradoksalnie oprogramowanie to co do zasady nie “coś nowego” a “coś wydajniejszego”. Oprogramowanie (komputer) to tylko szybsze i bardziej niezawodne narzędzie… Nawet jeżeli ludzie czegoś nie robią bez komputera, to nie dlatego, że nie wiedzą jak, a dlatego, że nie potrafią tak szybko liczyć…
Obawiam się, że “Feature Envy” to klasyka problemu SQL – Dane-w-bazie (oraz zbyt głęboko zagnieżdżanych, opasłych agregatów)… Dlatego ja zawsze mam dodatkowe atrybuty na określone wyliczone dane: np. klasyka w postaci obiekt DaneOsoby ma nie tylko atrybut data_urodzenia ale także atrybut wiek, dzięki czemu dość częste pytanie o wiek nie powoduje konieczności każdorazowego wykonania jego wyliczenia na podstawie daty urodzenia i aktualnej daty, wiek jest wyliczany raz w roku i zapisywany. Moim zdaniem “Feature Envy” to kluczowy efekt usuwania redundancji gdzie tylko się da. Zresztą od kilkunastu lat nie używam już modelu relacyjnego w projektach :).
A tu dramat, który widuję regularnie w tym co mi proponują developerzy (get/set dla każdego atrybutu) i lekarstwo:
https://martinfowler.com/bliki/TellDontAsk.html
dodano Regulamin Biblioteki oraz opis logiki wykonania rezerwacji książki, rozwiązuje to także wymaganie różnego rozporządzania egzemplarzami: np. osobne reguły dla jednego podpisanego egzemplarza.
Aktualizacja: dodano diagram aktywności obrazujący logikę realizacji aktualizacji Regulaminu Biblioteki
Dodano opis wymagań pozafunkcjonalnych.
Dodano poglądowe modele integracji.
jeżeli ktoś chce, może porównać z tym:
https://www.wiedzanaplus.pl/programowanie/33-uml/68-jezyk-uml-projekt-sklepu-komputerowego.html
Ktoś tu napisał: “Ciężko przełożyć to na kod”. Słysze to dość często. Na czym polega ta trudność?
Ciężko presuponuje, że jednak się da:) Faktycznie da się, ale np. ani żaden z moich ekspertów by się tego nie podjął. Powodem jest ryzyko niepowodzenia. To co na razie mamy opracowane, to sprowadzenie problemu do problemu klasy obieg dokumentu – uproszczony ale jednak. System wygląda jak zbieraczka danych (tych dokumentów) z formularzy. I ok, być może tak działa ten konkretny biznes. Wtedy typowy softwarehouse zrobi to crudem i praktykantami;) Ale z czasem pojawią się reguły, których tu nie widać. Nie wiadomo jak to modularyzować, na pewnie nie naiwnie vertical slice po procesach czy po rzeczownikach.
Bo ten (taki) system to zbieraczka danych, jak znakomita większość systemów. Logika ma dwa poziomy:
– prosty, polegający na walidacji treści pól (to ich definicje)
– dziedzinowy, czyli związki między wartościami pól tego samego lub odrębnych dokumentów
Np. mając pole Data wypożyczenia i Data zwrotu, oraz Wysokość kary (Regulamin) mogę napisać:
[kara za zwłokę] = jeżeli ([data zwrotu] – [data wypożyczenia]) > limit dni, to * [stawka dzienna za zwłokę]
to logika dziedzinowa. Dodam, że logika dziedzinowa to także taką jest zasada [data zwrotu] – [data wypożyczenia] >= 0
Tą metodą można opisać dowolną logikę na poziomie dokumentów i ich treści, całkowicie poza bazą.
Udostępniam plik PDF bezpłatnie w ramach rozwoju tej dyskusji.
(jeżeli ktoś z państwa ma problem z pobraniem plik to proszę o kontakt)