Wprowadzenie

W 2021 roku, w artykule Transformacja Cyfrowa a dziedzictwo IT pisałem:
Aby transformacja cyfrowa była w ogóle możliwa, musimy przenieść te dane (treści, informacje) z papieru „do komputera”, w sposób nieniszczący obecnych możliwości i pozwalający na tworzenie nowych.
Trzeba też zniwelować posiadany dług technologiczny. Dług technologiczny to posiadane dziedzictwo, to zapóźnienie, to pozostawanie w tyle za trwającym postępem technologicznym. Dług taki ma bardzo wiele firm
https://it-consulting.pl/2021/11/21/cyfrowa-transformacja-a-dziedzictwo-it/
W tym tekście poruszam pokrewny temat jakim jest zabezpieczenie się, bo kluczowe pytanie brzmi: co zabezpieczyć mając “wszystko w wersji elektronicznej”?
Bardzo często jestem pytany o to jak się zabezpieczyć kupując lub zamawiając oprogramowanie. Wielu prawników zaleca depozyt kodu źródłowego.
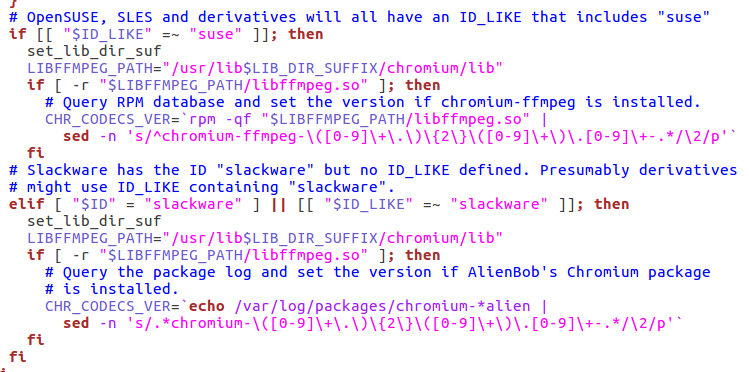
Powyżej zdjęcie po prawej to przykładowy fragment takiego kodu. Kto zrozumiał?
Często czytam:
Depozyt kodu źródłowego – niezawodny sposób zabezpieczenia systemu IT
https://szolajski.com/depozyt-kodu-zrodlowego-niezawodny-sposob-zabezpieczenia-systemu-it/
albo:
Depozyt kodu źródłowego (ang. software escrow) jest jednym z najlepszych środków ochrony przed skutkami upadłości producenta oprogramowania.
https://pbrd.pl/#:~:text=Depozyt%20kodu%20%C5%BAr%C3%B3d%C5%82owego%20(ang.,prawn%C4%85%20i%20techniczn%C4%85%20takiego%20procesu.
albo to samo inna kancelaria (skopiowali treść cudzej strony?) :
Depozyt kodu źródłowego (ang. source code escrow) jest jednym z najlepszych środków ochrony przed skutkami upadłości producenta oprogramowania.
https://axteon.pl/depozyt-kodu/depozyt-kodu-%C5%BAr%C3%B3d%C5%82owego/
Takich ofert kancelarii prawnych jest wiele. Niestety bywa to kosztowne i jest to bardzo złe rozwiązanie, bo w zasadzie przed niczym nie zabezpiecza. Depozyt kodu źródłowego jest jedną najbardziej bezwartościowych metod ochrony. Dlaczego?
- Są to setki tysięcy linii kodu, nie raz bardzo niskiej jakości, napisanego niechlujnie przez różnych ludzi (rotacja pracowników dewelopera).
- Bywa że celowo utrzymywana jest jego niska zrozumiałość (by utrudnić innym jego zrozumienie: vendor lock-in).
- Wiele aplikacji nadal jest pisanych z użyciem relacyjnych baz danych (setki połączonych tabel) i języka SQL, więc wraz z tym kodem należało by mieć także detalicznie opisaną strukturę tych tabel i zapisane (ich treść) wszystkie zapytania SQL użyte w tym kodzie, a także detaliczny opis środowiska tej bazy danych.
Zrozumienie mechanizmu działania aplikacji tylko na bazie jej kodu źródłowego, struktury tabel baz danych i zapytań SQL do tej bazy, graniczy z cudem i zajmuje nie raz lata (z reguły bywa droższe niż zakup nowego oprogramowania). To pomysł na poziomie tezy, że można zrozumieć jak działa samolot robiąc mu zdjęcie RTG.
W 2012 napisałem artykuł: Sprzedam Ci prawa do kodu czyli wielka ściema. Niedawno napisałem tekst: Mechanizm działania vs model systemu vs diagram. Ten artykuł to kontynuacja w kontekście tego co należy chronić.
Jedynym skutecznym sposobem zabezpieczenia się, jest posiadanie archiwum dokumentów, które przetwarzała ta aplikacja oraz dokumentacji opisującej mechanizm (architekturę, algorytmy, procedury) realizacji funkcjonalności tego oprogramowania.
Metoda
Standardowo stosuję idealizację i modelowanie zarówno w pracy naukowej ja i w projektach komercyjnych. Dlatego tu także opiszę model architektury systemu informatycznego, jako idealizację takiej architektury, a potem posługując sie nim, przetestuję ideę depozytu kodu źródłowego.
Czym jest system i po co go mamy czyli co to jest komputer
Jest to kluczowe pytanie na jakie trzeba sobie odpowiedzieć. Popatrzmy:
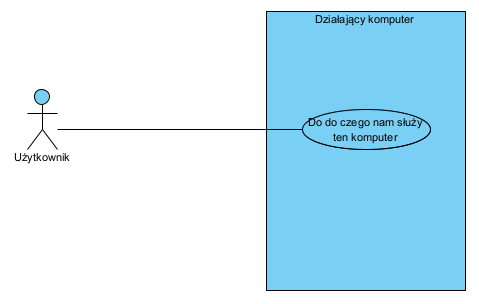
Kluczowy fakt: my jako ludzie używamy komputera a nie kodu źródłowego. To znaczy, że sam kod źródłowy to nie jest to, czego używamy. Kod źródłowy to fragment “systemu”:
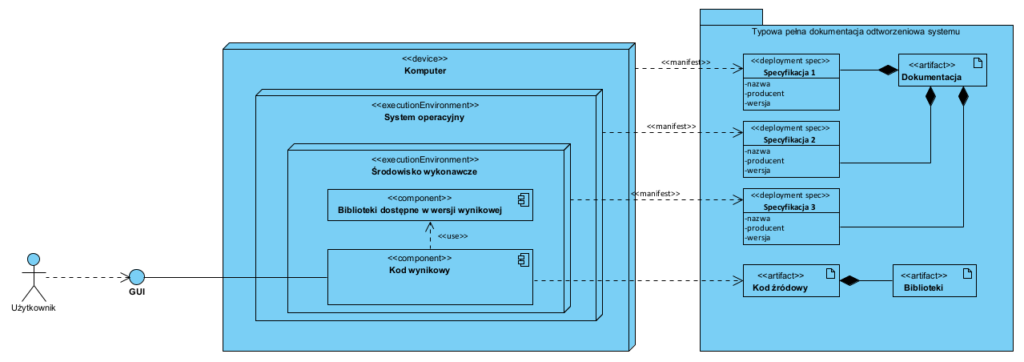
Patrząc na powyższy diagram łatwo zauważyć, że sam kod źródłowy, bez pozostałych elementów, jest w zasadzie bezwartościowy. Co z tego że mamy mityczny kod źródłowy, skoro możemy mieć poważny problem z pozyskaniem pozostałych elementów wymaganych do tego, by nasz Działający Komputer odtworzyć? Czego tak na prawdę używamy używając komputera? Używamy określonego mechanizmu przetwarzania danych. Za Słownikiem Języka Polskiego: mechanizm to sposób, w jaki coś powstaje, przebiega lub działa.
Co więc tak na prawdę należy udokumentować i chronić? Opis mechanizmu działania naszego komputera. Problem w tym, że mając wyłącznie kod źródłowy jesteśmy w trudnej sytuacji bo nadal zrozumienie tego mechanizmu wymaga “inżynierii wstecznej”, jedyna różnica to ta, że materiałem źródłowych jest nie kod maszynowy a kod w określonym języku programowania, co niestety niewiele poprawia sytuację:
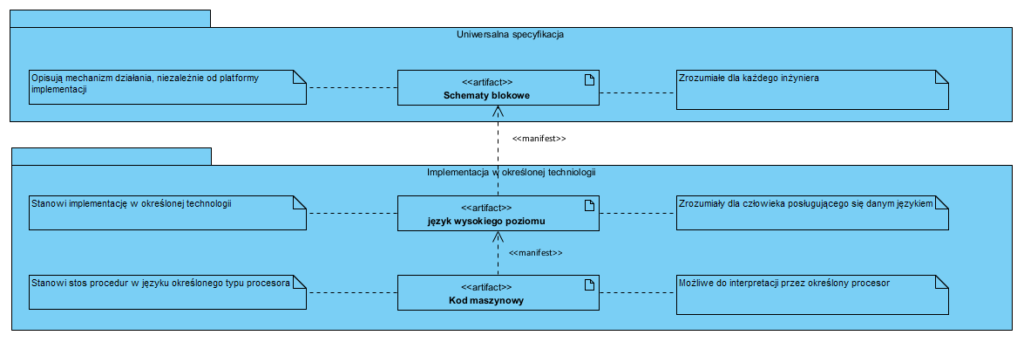
Kolejne kluczowe pytanie to: Co jest celem zakupu komputera? Otóż celem jest “to do czego on nam służy” a nie “on sam jako taki”.
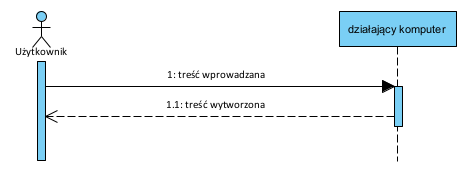
Cała nasza działalność, do której używamy komputera, to wprowadzanie danych i uzyskiwany efekt. Bardzo często komputer to także archiwum historii naszych “dokonań” (przy okazji prosze zwrócić uwagę na to, że obecnie nie ma znaczenia gdzie on faktycznie stoi bo liczy się komunikacja).
Co faktycznie należy chronić
Kolejne ważne pytanie: czy produkty naszej pracy, nasz dorobek, który powstał z użyciem tego komputera, jest dla nas dostępny bez Tego komputera? Jeżeli nie, to brak tego komputera nie tylko powoduje, że nie mamy narzędzia pracy, to także przepadek całego dorobku jaki powstał z jego pomocą. Jeżeli ten Komputer przechowuje dane w postaci czytelnej tylko dla kodu Tego oprogramowania, to utrata Tego oprogramowania jest równoznaczna z utratą dotychczasowego dorobku (np. najgorszą formą archiwizowania danych jest relacyjna baza danych i zapytania SQL do niej, sytuacja w jakiej jest większość posiadaczy systemów ERP).
Komputer bez udokumentowanego mechanizmu działania to dla nas wyłącznie “czarna skrzynka”. Wobec tego jak się zabezpieczyć, skoro depozyt kodu to zabezpieczenie fikcyjne? Należy zabezpieczyć:
- nasz dotychczasowy dorobek (stanowiące naszą własność archiwum z dokumentami w uniwersalnym formacie, łatwym do odczytania, np. XML+PDF),
- mechanizm działania (udokumentowany np. w UML).
Poniżej idealna bezpieczna architektura: mamy komputer i mamy archiwum oraz mamy “na boku” udokumentowany mechanizm powstawania (przetwarzania) naszych danych.

Innymi słowy: nie tylko mamy archiwum dokumentów, ale mamy także wiedzę jak one powstawały, i możemy tej wiedzy użyć do zbudowania kolejnego “działającego komputera”, bez względu na to w jakiej technologii zrobimy to kolejnym razem. Poniżej zilustrowano podstawowe zalecane zasady zarzadzania danymi:
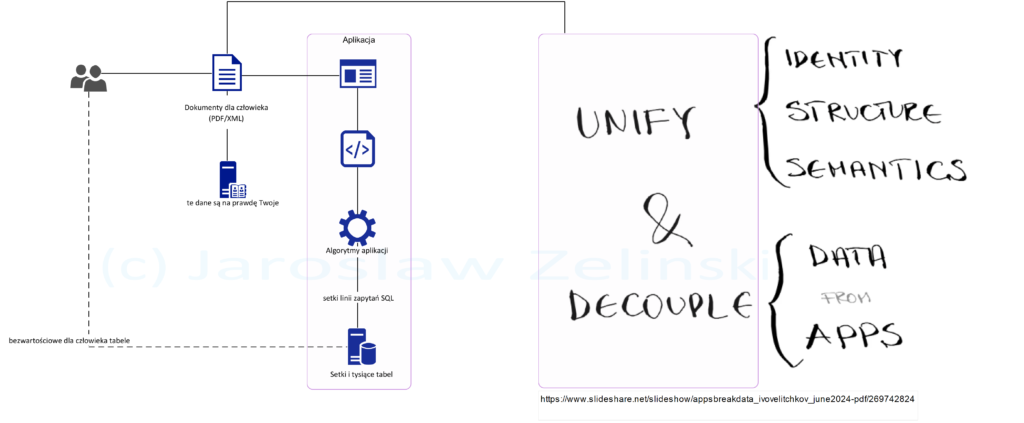
Dodam tu, że ochrona know-how to nic innego jak posiadanie ww. udokumentowanego mechanizmu. Kod źródłowy nie daje takiej ochrony.
Czym jest wiedza o produkcie?
Opis produktu powinien przedstawiać (ujawniać) go na tyle jasno i wyczerpująco, aby znawca mógł go urzeczywistnić. Za „znawcę z danej dziedziny” uważa się przeciętnego praktyka dysponującego przeciętną, ogólnie dostępną wiedzą z danej dziedziny w odpowiednim czasie, który dysponuje typowymi środkami i możliwościami prowadzenia prac. Przyjmuje się, że specjalista taki ma dostęp do stanu techniki; tzn. informacji zawartych w podręcznikach, monografiach, książkach. Zna także informacje zawarte w opisach patentowych i publikacjach naukowych, jeżeli jest to rozwiązanie, które jest na tyle nowe, że stosowne opisy nie są zawarte w książkach. Ponadto, potrafi korzystać ze stanu techniki w działalności zawodowej do rozwiązywania problemów technicznych. Produkt powinien nadawać się do odtworzenia (na podstawie dokumentacji) bez dodatkowej twórczości wynalazczej. Pod pojęciem tym należy rozumieć dodatkową działalność umysłową, eksperymentalną związaną z niepełną informacją techniczną zawartą w opisie produktu, a także konieczność dodatkowych uzupełniających badań naukowych, niezbędnych do wytworzenia produktu według tego opisu. (na podstawie Pyrża, 2006)
Na bazie poprawnie wykonanej dokumentacji technicznej (opis mechanizmu działania, opis produktu) można aplikację odtworzyć wielokrotnie niższym nakładem środków w porównaniu z analizą cudzego kodu źródłowego, którego dalszy rozwój w postaci i technologii w jakiej pierwotnie powstał, nie raz może nie mieć sensu (postęp technologii w IT jest dość szybki).
Dlatego od wielu zalecana architektura systemów ERP to także osobna zintegrowane własne hurtownia danych i archiwum dokumentów jako np. dokumentowa baza danych NoSQL:

Ważna rzecz na koniec tej części:
- jeżeli oprogramowanie jest dedykowane to właścicielem i posiadaczem praw majątkowych do kodu i wszelkiej jego dokumentacji powinien być jego użytkownik,
- jeżeli oprogramowanie jest licencjonowane to użytkownik powinien znać mechanizm jego działania,
- jeżeli ktoś używa oprogramowania, którego dziania nie rozumie, to może to mieć sens tylko w przypadkach gdy użytkownik wymaga wyłącznie efektu i nie musi rozumieć tego jak powstał: np. oprogramowanie OCR czy retusz zdjęć.
Dlatego tak ważne jest posiadanie archiwum “trwałych nośników dokumentów” (Documents na powyższym schemacie):
Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego nośnika, jeżeli tego rodzaju strona internetowa nie spełnia cech trwałego nośnika.
Co radzą prawnicy
Co to jest depozyt kodu źródłowego ?
Depozyt kodu źródłowego (ang. source code escrow) jest jednym z najlepszych środków ochrony przed skutkami upadłości producenta oprogramowania. W praktyce depozyt kodu źródłowego polega na złożeniu przez Licencjodawcę / Deponenta (firmę produkującą oprogramowanie) kodów źródłowych u depozytariusza (tzw agenta depozytu), przy równoczesnym upoważnieniu licencjobiorcy (kupca oprogramowania) do pobrania i dalszego wykorzystania kodów źródłowych w określonych w umowie depozytowej w przypadkach, takich jak np. upadłość, wrogie przejęcie, likwidacja producenta oprogramowania, zaprzestanie rozwoju aplikacji, zaprzestania świadczenia usług serwisowych i wsparcia przez licencjodawcę.
https://axteon.pl/depozyt-kodu/depozyt-kodu-%C5%BAr%C3%B3d%C5%82owego/
Podsumuję to tak:
- jeżeli oprogramowanie jest dedykowane to właścicielem i posiadaczem praw majątkowych do kodu i wszelkiej jego dokumentacji powinien być jego użytkownik,
- jeżeli oprogramowanie jest licencjonowane, to użytkownik powinien znać mechanizm jego działania, co pozwala w dowolnym momencie kupić na rynku analogiczne, lub w skrajnym przypadku zlecić napisanie.
- jeżeli ktoś używa oprogramowania, którego dziania nie rozumie, to może to mieć sens tylko w przypadkach gdy użytkownik wymaga wyłącznie efektu i nie musi rozumieć tego jak powstał: np. oprogramowanie OCR czy retusz zdjęć.
Podczas negocjacji na temat kupna oprogramowania w pewnym momencie rozważny licencjobiorca może zapytać: Co się stanie, jeśli dostawca oprogramowania zakończy swój biznes? Zazwyczaj następuje żądanie dostępu do kodu źródłowego i wszelkich innych krytycznych materiałów używanych do utrzymania oprogramowania.
https://axteon.pl/depozyt-kodu/depozyt-kodu-%C5%BAr%C3%B3d%C5%82owego/
Co do zasady: oprogramowanie się licencjonuje (brak jakichkolwiek praw do niego) lub zleca jego wykonanie (wtedy jest się jego właścicielem, także kodu).
Umowa depozytu kodu źródłowego znana jest w Stanach Zjednoczonych od około 50 lat pod nazwą software escrow. Już wtedy była wykorzystywana do zabezpieczenia oprogramowania tworzonego przez wyspecjalizowane firmy z branży IT. Na początku XXI w. konstrukcja zaczęła upowszechniać się w Europie, ale w Polsce dla wielu przedsiębiorców nadal stanowi całkowicie obce zagadnienie. Po co deponować kod źródłowy i jak prawidłowo skonstruować taką umowę?
https://rpms.pl/depozyt-kodu-zrodlowego-oprogramowania/
50 lat temu, miało to sens bo czasy były takie, że oprogramowanie to były relatywnie małe monolity, kodu było nie wiele, a języków programowania kilka. Obecnie stopień złożoności oprogramowania oraz mnogość technologii powoduje, że kod z zasady nie jest swoją dokumentacją.
Kod źródłowy to nic innego jak zbiór poleceń napisanych w określonym języku programowania, które pozwalają zarządzać zgromadzonymi i wprowadzanymi danymi. Aby kod źródłowy mógł działać, niezbędna jest jego kompilacja, czyli przekształcenie w kod wynikowy, który następnie może zostać zastosowany przez procesor. Efekt takiego działania użytkownik widzi na monitorze komputera. Kod źródłowy zazwyczaj ma postać pliku tekstowego i jako taki może on zostać zapisany na trwałym nośniku, np. płycie CD lub pamięci nieulotnej typu FLASH.
https://rpms.pl/depozyt-kodu-zrodlowego-oprogramowania/
I to jest prawda, jednak problem w tym, że konkretny kod, to jedno z dziesiątek możliwych metod odwzorowania mechanizmu przetwarzania danych (co opisano wcześniej) i niestety bardzo trudne do zrozumienia przez osoby inne niż autor twego kodu.
Każdy dostawca oprogramowania w nieco inny sposób tworzy dokumentację software’u, dlatego warto zadbać o to, aby w umowie były wymienione wszystkie konieczne elementy, które znajdą się u depozytariusza. Co powinno się wśród nich znaleźć?
– aktualizowana karta wersji wraz ze wskazaniem wszystkich wprowadzonych zmian,
https://rpms.pl/depozyt-kodu-zrodlowego-oprogramowania/
– opis struktur katalogów kodów źródłowych wraz ze wskazaniem standardu nazewnictwa plików źródłowych i wynikowych,
dokładny opis procedury kompilacji,
– opis środowiska kompilacyjnego i zdefiniowane biblioteki programistyczne,
– dokumentacja techniczna baz danych wraz ze wskazaniem nazw tabel i relacji między nimi oraz podaniem ewentualnych atrybutów,
– narzędzia do przygotowania wersji instalacyjnej, czyli takiej, która będzie się nadawała do wgrania na twardy dysk oraz do samej instalacji.
W ten sposób licencjobiorca ma gwarancję, że po zwolnieniu kodu będzie dysponował wszystkimi narzędziami, za pomocą których samodzielnie obsłuży otrzymany kod źródłowy.
Niestety nie ma żadnej gwarancji, gdyż narzędzia kompilacji, w tym ich wersje, mogą być niedostępne na rynku, i nadal pozostaje kwestia tego, że nabywca “nie wie jak to działa” bo dla niego kod źródłowy jest niezrozumiały, a zlecenie innemu deweloperowi tworzy konflikt interesu i bardzo duże koszty.
A czym więc jest oprogramowanie?
Jedną z najbardziej szkodliwych działań na rynku jest lansowanie tezy, że kod źródłowy to jakieś wartości intelektualne, i wie o tym każdy kto z takim kodem został sam. Jest to nie prawda: polecam publikacje Urzędów Patentowych na świecie .
Kod źródłowy to co najwyżej “kołka zębate maszyny” . Kod źródłowy, jako wartości intelektualne, jest bezwartościowy bez jego autora, tak samo jak bezwartościowy jest tort bez recepty na jego wykonanie. Wie o tym każdy kto został z kodem źródłowym bez dewelopera, który go napisał.
Oprogramowanie to skrypt konfigurujący komputer zas jako ludzie używamy komputera a nie “kodu źródłowego” . Dlatego w IT raczej należy skupić się na ochronie know-how: chronimy projekt buta a nie buty, chronimy receptury dań a nie to co podamy na stół. W fabryce samochodów chronione know-how to dokumentacja techniczna samochodu, a nie samochody na parkingu.
Jako użytkownik cudzego (licencja) oprogramowania powinniśmy chronić to co z jego pomocą tworzymy. Mając swoje dedykowane oprogramowanie należy chronić opis mechanizmu jego działania, który możemy zaimplementować kiedykolwiek z pomocą dowolnego języka programowania.
Podsumowanie
Więc jak? Użytkownik oprogramowania:
- albo licencjonuje od dostawcy oprogramowanie standardowe i nie kastomizuje go, tu wymaganie kodu źródłowego jest kuriozalne, a sytuację “awaryjną” leczy zakup analogicznego, standardowego oprogramowania od innego producenta (Finanse i księgowość, itp.).
- albo posiada prawa majątkowe do dokumentacji i oprogramowania wykonanego specjalnie dla niego, i firma – deweloper – która to wykonała nie ma nic do gadania.
Każda inna forma to szukanie kłopotów. Więcej o kastomizacji i dlaczego jest ona poważnym błędem: Kastomizacja oprogramowania standardowego, aspekty ekonomiczne: Recenzja i rekomendacje. Samodzielne, ponowne, po kilku latach, uruchomienie “starego” kodu źródłowego graniczy z cudem.
Nie jest też możliwe by jakaś jedna aplikacja obsłużyła cała firmę. Nie ma czegoś takiego jak “jedna wspólna baza danych” jako “jedno źródło prawdy”, bo dane są zawsze kontekstowe. Dlatego system IT to raczej kilka tematycznych źródeł prawdy (dziedzinowe oprogramowanie zintegrowane w jeden system), a nie jedno centralne. Wielkie wdrożenia kastomizowanych (nieudokumentowane kastomizacje) monolitów ERP kończą sią zawsze porażką.
Jak udokumentować oprogramowanie: Analiza Biznesowa i Opis Techniczny Oprogramowania – moja rola w projekcie.
Ciekawostka:
Za trwały nośnik można uznać m.in. dokument papierowy, kartę pamięci, pendrive, wiadomość mailową lub załączony do niej plik, np. w formacie pdf. Samo hiperłącze przekierowujące na stronę internetową nie spełnia wymogów trwałego nośnika, jeżeli tego rodzaju strona internetowa nie spełnia cech trwałego nośnika. (https://uokik.gov.pl/zwrot-i-rekompensata-od-mpay-i-revolut-bank-uab)
P.S.
Przykład. W powyższy sposób opracowałem i udokumentowałem logikę działania systemu Generator Ofert dla Kancelarii Senatu. Jest to oprogramowanie obsługujące dofinansowanie projektów dla polonii na całym świecie: od naboru wniosków, przez ich procesowanie, zatwierdzanie, podpisywanie umów aż do rozliczenia. Aplikacja dwa razy zmieniała firmę, która obsługiwała jej utrzymanie i rozwój, później została przepisana w nowej technologii w toku przejścia z chmury na hosting dedykowany. Dzięki temu, że zastosowano dokumentowy model danych, migracja do nowej wersji odbyła praktycznie bez kosztowo.
Czarny humor na zakończenie
Poniższy mem jest dość popularny w sieci:

Jego parafraza:
Koder: Tylko kod źródłowy jest dokumentacją oprogramowania.
Użytkownik: To oprogramowanie nie działa poprawnie, gdzie jest opis poprawnego (oczekiwanego) działania tego programu?
Koder: Opisem jest ten kod źródłowy….
(autor mema nie znany)

