W toku szkoleń, a także audytów, powstają nie raz spory o interpretacje znaczenia symboli notacji: ich semantyki i syntaktyki (co oznaczają i jak je można łączyć z innymi). Dzisiaj o dość częstym sporze czyli bramki OR (inclusive) i XOR (exclusive) w notacji BPMN oraz o tym, że z 380 stron specyfikacji BPMN, w modelach analitycznych stosujemy tylko niecałe 40 stron rozdziału 7., pozostałe rozdziały służą wyłącznie lepszemu zrozumieniu teorii i modelom wykonywalnym. Czyli dlaczego w analizach stosujemy kilka, a nie kilkadziesiąt symboli notacji BPMN.
Wprowadzenie
Specyfikacje notacji zarządzane przez OMG (Object Management Group) ewoluują, są pisane i rozwijane przez zespoły ludzi, i często odnoszą się wzajemnie do siebie (w szczególności do MOF, obecnie wersja 2.5.1. 2019 r.). Jeżeli dodać do tego fakt, że notacje te nie są aktualizowane jednocześnie, musimy sie pogodzić z tym, że zawsze będą w pewnym zakresie niespójne i między sobą i wewnątrz. Widać to w szczególności w UML po 2015 roku (pojawienie sie wersji 2.5) i w BPMN po 2014 (pojawienie się wersji 2.0.2). Te dwie zmiany są fundamentalne, bo są efektem harmonizacji obu tych notacji ze specyfikacją MDA (Model Driven Architecture), która zakłada, że proces wytwarzania oprogramowania to cztery kluczowe etapy i zarazem modele, powstające w kolejności: (1) Computation Independent Model (CIM), (2) Platform Independent Model (PIM), (3) Platform Specific Model (PSM) oraz (4) implementacja, czyli właściwe kodowanie. Są tą odpowiednio: (1) model biznesowy (problem domain), (2) model rozwiązania (solution domain), (3) model implementacji (software domain), (4) implementacja (implementation domain).

Powyższy diagram pokazuje kolejność tych etapów i produktów każdego z nich (artefaktów). Na szaro oznaczono obszary transformacji, pozostające nadal w sferze akademickich rozważań o możliwości automatyzacji tych operacji. Powyższy proces, wbrew zarzutom wielu autorów, nie jest tak zwanym wodospadowym (waterfall) procesem tworzenia oprogramowania, gdyż opisuje dowolny mały lub duży komponent systemu. Mogą to być np. mikroserwisy, powstające w cyklu nawet tygodniowym. MDA stawia sobie za cel odsunięcie w czasie najkosztowniejszego etapu jakim jest implementacja i testowanie. CIM i PIM robi sie “na papierze” (czyli szybko i tanio, jak ktoś potrafi), implementacja to już konieczność uruchomienia środowiska wykonawczego i kilku dni pracy zespół programistów, w tym testy i poprawianie błędów (które są szybko i tanio usuwane na etapie testowania modeli PIM).
Czy wspomniane na początku drobne niespójności notacji dyskwalifikują te notacje (głównie BPMN i UML)? Absolutnie nie. Po pierwsze są marginalne i nie dotyczą kluczowych cech notacji, po drugie notacje mają określoną hierarchię jako meta-modele, opisaną w specyfikacji MOF, co pozwala samodzielnie rozstrzygać takie problemy, co w tym artykule pokażę.
Najnowsza wersja MOF zawiera krótki komentarz na temat liczby warstw metamodeli (7.3 How Many Meta Layers?). Powszechnie cytowany jest poniższy diagram:

Jest to pokłosie pierwszej specyfikacji MOF z roku 2002 zawierającej taki opis:
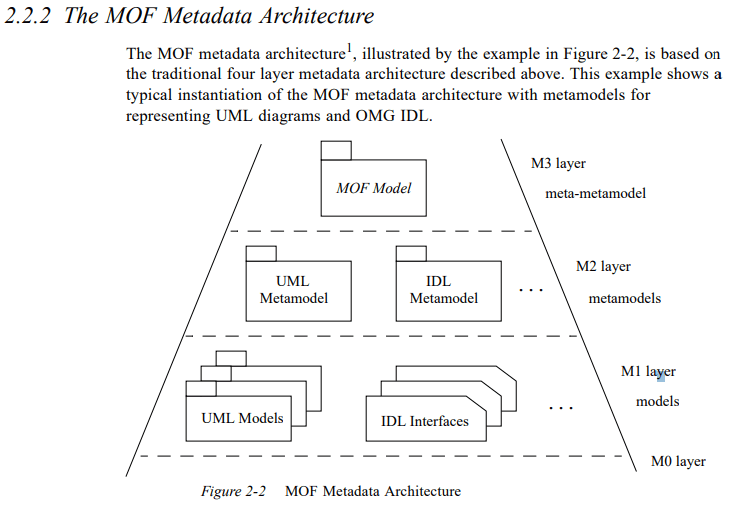
Obecnie (Meta Object Facility, 2.5.1, 2016) czytamy:
Jednym ze źródeł nieporozumień w pakiecie standardów OMG jest postrzegana sztywność “czterowarstwowej architektury metamodelu architektury metamodelu”, o której mowa w różnych specyfikacjach OMG. Należy zauważyć, że kluczowymi pojęciami modelowania są klasyfikator i instancja lub klasa i obiekt oraz możliwość nawigacji od instancji do jej meta-obiektu (jej klasyfikatora). Ta podstawowa koncepcja może być użyta do obsługi dowolnej liczby warstw metamodeli (czasami określanych jako meta-poziomy).
Ostatnie zdanie dotyczy warstwy oznaczane M2 i dotyczy klas abstrakcyjnych i profili. To w tej warstwie (M2) są definiowane między innymi profile wzorców projektowych; np. bloki funkcjonalne wzorców DDD (Domain Driven Design) czy BCE (Boundary, Control, Entity) i wielu frameworków.
Istnienie drobnych niespójności (raczej są to niekonsekwencje) w notacjach (jak widać są aktualizowane w różnym czasie) oznacza, że ich odrębne i dogmatyczne intepretowanie jest bardzo poważnym błędem. Z uwagi na sposób powstawania, każda specyfikacja, pochodząca z OMG, zawiera w początkowych rozdziałach informacje o zgodności z dokumentami nadrzędnymi, co pozwala, na drodze logiki i dedukcji, rozstrzygać tego typu wątpliwości. W specyfikacji BPMN czytamy:
3. Normative References
(źr. BPMN Version 2.0.2).
3.1 General
The following referenced documents are indispensable for the application of this document. For dated references, only the edition cited applies. For undated references, the latest edition of the referenced document (including any amendments) applies.
(Następujące dokumenty powołane są niezbędne do stosowania niniejszego dokumentu. W przypadku powołań datowanych obowiązuje tylko wydanie cytowane. W przypadku powołań niedatowanych obowiązuje ostatnie wydanie dokumentu powołanego (łącznie z poprawkami)).
3.2 Normative
OMG UML
? OMG Unified Modeling Language (OMG UML), Superstructure, V2.1.2 – OMG MOF
? Object Management Group – Meta Object Facility (MOF) Core Specification, V2.0
https://www.omg.org/spec/MOF/2.0 RFC-2119
? Key words for use in RFCs to Indicate Requirement Levels, S. Bradner, IETF RFC 2119, March 1997
http://www.ietf.org/rfc/rfc2119.txt
Innymi słowy interpretacja semantyki i syntaktyki specyfikacji BPMN, MUSI być realizowana na bazie aktualnych specyfikacji MOF i UML. Specyfikacja notacji nie może być intepretowana jako oderwany od pozostałych, dogmatycznie czytany, tekst.
Proces w BPMN
Modele procesów biznesowych w BPMN to tak na prawdę tworzenie metamodeli określonego typu, nazwanych, sekwencji zdarzeń (instancji procesu). Elementy na diagramach BPMN to z zasady klasy a nie obiekty (specyfikacja BPMN zawiera wyłącznie diagramy klas). Innymi słowy zadanie “Wystawienie faktury” na diagramie BPMN, oznacza wszystkie przypadki wystawienia faktury w modelowanej organizacji.
Modele BPMN formalnie umieszczamy w warstwie M2 struktury MOF. Innymi słowy: np. jeden diagram BPMN, jako model przepływu faktur kosztowych (warstwa M2), reprezentuje (opisuje) wszystkie możliwe (dopuszczalne) konkretne przepływy faktur. Hierarchię tę można pokazać tak:
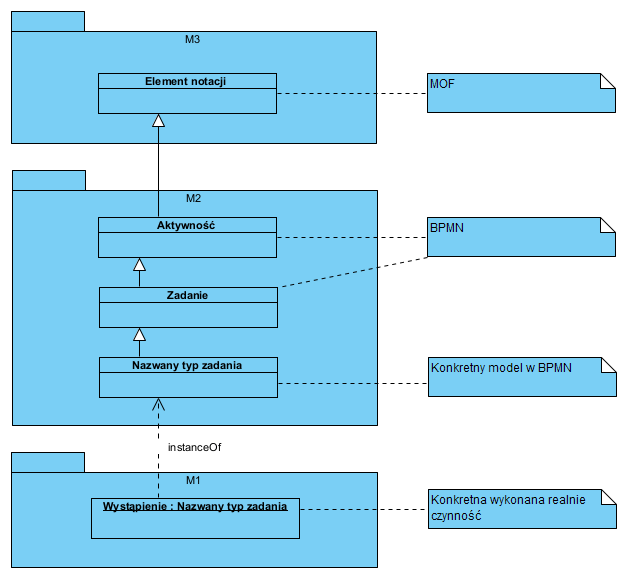
Innymi słowy diagramy BPMN, jako modele procesów biznesowych, to konstrukcje budowane w warstwie M2 MOF. Są to meta-modele faktycznych wystąpień (M1 to abstrakcja, jako diagram byłby to zapis ścieżki przepływu konkretnego dokumentu, świat realny, obserwowany, to niepokazana tu warstwa M0).
Poniżej fragment specyfikacji, BPMN, diagram klas UML definiujący kluczowe elementy semantyki procesu w notacji BPMN:
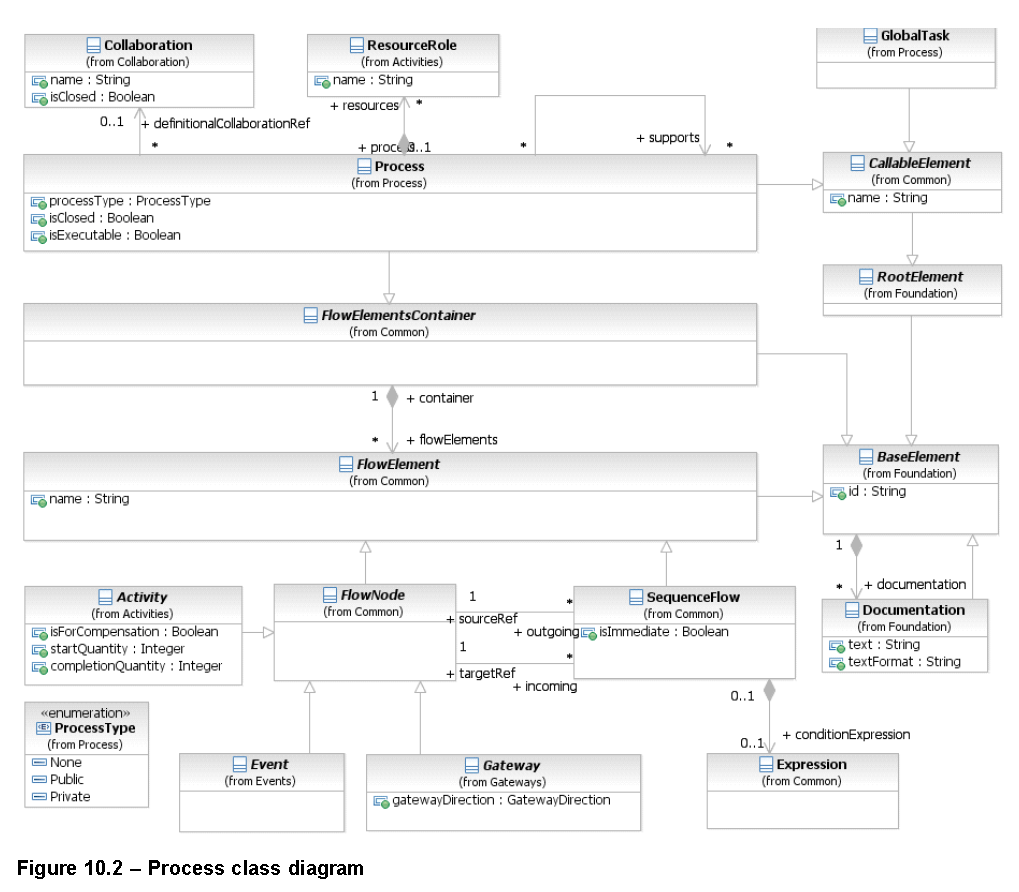
I czytamy, że kluczowe elementy procesu to:
- Proces (jako diagram) jest kontenerem na elementy z jakich się składa jego model,
- Te elementy to połączone ze sobą węzły, którymi są aktywności, bramki i zdarzenia.
To najwyższy poziom abstrakcji w BPMN. W oryginale (rozdz. 10) opisywany jest słownie jako:
Proces opisuje sekwencję lub przepływ działań w organizacji, których celem jest wykonanie pracy [to bardzo ważne, bo chodzi o jej produkt]. W BPMN proces jest przedstawiony jako graf elementów przepływu, które są zbiorem działań, zdarzeń, bramek i przepływu ich sekwencji.
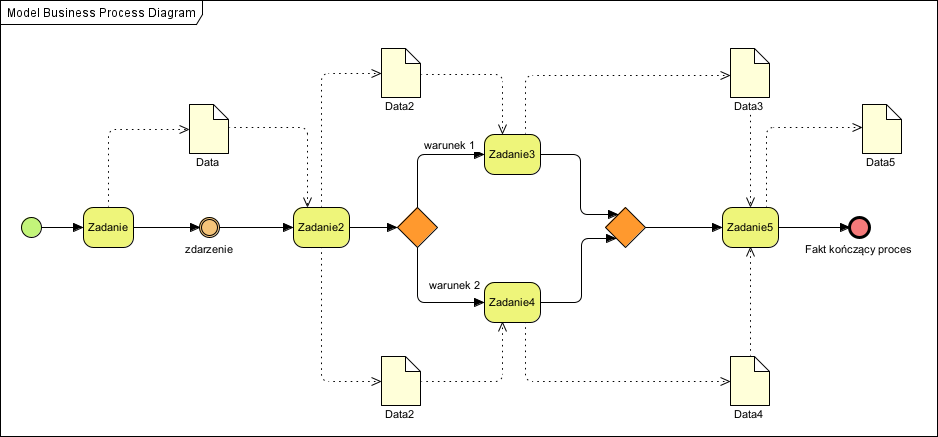
Bramki w procesie
W specyfikacji czytamy (10.6 Gateways):
Bramki mogą definiować wszystkie typy sterowania przepływu sekwencji procesów biznesowych: Decyzje/rozgałęzienia (wyłączne, włączające i złożone), łączenie, rozwidlanie i złączenie. Tak więc, podczas gdy romb był używany tradycyjnie dla decyzji wyłącznych, BPMN rozszerza zachowanie rombów, aby odzwierciedlić każdy rodzaj Sterowania przepływem sekwencji. Każdy typ bramki będzie posiadał wewnętrzny wskaźnik lub marker, aby pokazać typ bramki, która jest używana.
Jednak w rozdziale 7 (tabela 7.1.) podstawowe symbole czytamy:
Bramka jest używana do kontroli rozwidleń i złączeń przepływów sekwencji w procesie […]. W ten sposób określa ona rozgałęzienia, rozwidlenia i złączenie ścieżek.
nieco dalej, (tabela 7.2.) mamy także:
Przepływ warunkowy: Przepływ sekwencji może posiadać warunek (Wyrażenie), który jest analizowany w czasie wykonywania, aby określić, czy przepływ zostanie wykonany. […] Jeśli przepływ warunkowy wychodzi bezpośrednio z krawędzi aktywności, wówczas będzie posiadał miniromb na początku łącznika. Jeśli przepływ warunkowy wychodzi z krawędzi Bramki, wówczas linia nie będzie nie będzie posiadała minirombu.
Poniżej dwie równoważne konstrukcje:

I tu zaczyna się problem dogmatyków, gdyż z powyższego wcale nie wynika, czy bramka jest (powinna być) bramką XOR (exclusive) czy OR (inclusive), bo warunki są na razie abstrakcyjne (np. są nazwami parametrów). Patrząc dogmatycznie na poniższy zapis specyfikacji w rozdz. 10.:

przykład po lewej na diagramie “Alternatywna forma modelowania kontrolowanego przepływu procesu” jest niemożliwy do narysowania, bo to, czy warunki 1 i 2 się wzajemnie wykluczają czy nie, może być skutkiem konkretnego zestawu danych na dokumentach. Innymi słowy, jeżeli forma po prawej jest poprawna zawsze (wyjścia warunkowe), a po lewej miała by wymagać wiedzy o zależności logicznej tych warunków, to albo lewa forma nie ma racji bytu na modelach analitycznych, albo przyjmujemy konwencję, że na modelach analitycznych bramka danych oznacza dowolne rozwidlenie na podstawie danych i jest rysowana bez wewnętrznego oznaczenia, i takie przykłady zawiera także rozdział 7. specyfikacji.
Wyjaśnienie istnienia tego problemu znajdziemy w rozdziale 2.2.1. Czytamy:
Jako alternatywę dla poprawności modelowanych procesów, zdefiniowano trzy podklasy zgodności:
– Opisowa
– Analityczna
– Wykonywalna
Opisowa dotyczy widocznych elementów i atrybutów używanych w modelowaniu wysokopoziomowym. Powinna być wygodna dla analityków, którzy używali narzędzi do tworzenia ogólnych prostych diagramów przepływu BPA.
Analityczna zawiera te same elementy co Opisowa, plus pozostałe elementy notacji. Ta klasa modeli jest oparta na doświadczeniach zebranych podczas szkoleń BPMN oraz analizach wzorców w Department of Defense Architecture Framework i planowanej standaryzacji dla tego frameworka.
Zarówno modele Opisowe jak i Analityczne koncentrują się na widocznych (rysowanych) elementach i minimalnym podzbiorze wspierających atrybutów/elementów.
Klasa Wykonywalnych modeli skupia się na tym, co jest potrzebne do tworzenia detalicznych [implementacja procesów w środowiskach serwerów BPMS] modeli procesów.
Tak więc z uwagi na zapowiedź planowanej standaryzacji modeli analitycznych, dzisiaj musimy sobie radzić sami, i pozostaje przyjąć konwencję: na modelach analitycznych abstrahujemy od tego czy bramka danych jest bramką XOR czy OR, bo jest to na modelach analitycznych bardzo często po prostu nierozstrzygalne. Bez tego założenia bramki te w zasadzie nie powinny być używane na tych modelach, co pokazuje poniższy fragment procesu, a pytanie brzmi: jest to bramka XOR czy OR? W modelach analitycznych – to z zasady modele CIM, niezależne od technologii informacyjnej – bezpodstawne jest stosowanie ikon w rogu symboli aktywności (user, script, manual itp..), bo to znaczniki dla modeli wykonywalnych. Stosowanie ich na medalach analitycznych (Computation Independent) nie ma żadnego uzasadnienia (więcej o modelach analitycznych z przykładami w artykule: Od zapytania do realizacji zamówienia czyli jak to się robi z BPMN).

Można oczywiście rozrysować wszystkie możliwe kombinacje dla tych trzech parametrów, ale to doprowadzi do powstania skomplikowanego diagramu, wymagającego częstej aktualizacji (po każdej zmianie parametrów tych decyzji), diagramu w wielu przypadkach trudnego do interpretacji przez laika (a to oni są często adresatami tych dokumentów).
Co jest podstawą logiczną tej konwencji (jej zgodności z notacją)? W rozdziale 10.6 Gateways, mamy model pojęciowy:

I mamy ciekawostkę: bramki Exclusive i Inclusive mają wspólne zastosowanie: sterowanie przepływem, mogą, ale nie muszą mieć wewnętrznego oznaczenia (conditionExpression 0..1), więc można przyjąć, że mamy bramki: sterujące przepływem, rozwidlające, zdarzeniowe i złożone. Przy obecnym braku uzgodnienia detali dla modeli analitycznych, pozostaje przyjąć, że pusty romb to bramka sterująca danych, bez względu na to czy aktualny zestaw warunków tworzy logikę OR czy XOR, bo jest to po prostu często niemożliwe do stwierdzenia na tym etapie analizy i modelowania. Pamiętajmy także, że bramka (ona jest opcjonalna, jak już wiemy) na diagramie BPMN to manifestacja decyzji podjętych w poprzedzającej ją aktywności, a nie ich podejmowanie. Z moich obserwacji wynika, że taka właśnie konwencja jest najpowszechniej stosowana w literaturze i jest zrozumiała dla odbiorców modeli. Zaryzykuję tezę, że bardziej zrozumiała niż bramki oznaczone dodatkowo [X] lub [O] wewnątrz. Konwencja ta nie łamie zasad notacji (przypominam, że pojęcie tokenu to cecha modeli wykonywalnych).
Podsumowanie
Dogmatyzm w intepretowaniu specyfikacji notacji ma podobne skutki jak dogmatyzm u prawników: często jest szkodliwy. Czy to znaczy, że można łamać zasady notacji? Absolutnie nie. To znaczy, że podobnie jak w teorii prawa normy prawne intepretujemy jako połączone spójnikiem “i”, tak tu zapisy specyfikacji wszystkich notacji OMG intepretujemy łącznie i także łączymy wszystkie spójnikiem “i”. Innymi słowy MOF, UML, BPMN itp. to jedna notacja podzielona na dziedzinowe obszary. Praktycznie każda sformalizowana notacja w OMG (system notacyjny) to profil notacji UML. Dlatego, każda notacja ma tu we wstępie przywołaną zgodność z MOF i UML.
UWAGA! Materiały szkoleniowe i treści egzaminów certyfikacyjnych nie stanowią wiedzy nadrzędnej ani zastępującej oryginalne specyfikacje notacji. Jeżeli jest jakakolwiek niezgodność między treścią tych materiałów a treścią aktualnej specyfikacji danej notacji, stosujemy tę drugą. Żadne z tych materiałów nie stanowią podręcznika analizy czy modelowania, a przykłady tam podawane to wyłącznie przykłady poprawnej konstrukcji diagramów, co nie jest tożsame z dobrą, czy nawet zalecana, praktyką modelowania.


