Wprowadzenie
Niedawno napisał do mnie czytelnik pod jednym z artykułów:
Załóżmy, że realizujemy proces biznesowy: zarządzanie kursami walut. W ramach procesu pracownik musi przygotować plik csv zawierający wyłącznie listę słownikową par walut (np. usdpln, eurpln, eurusd). Nazwa pliku to np bieżącą data. Następnie systemX łączy się z API zewnętrznej platformy i pobiera tabele kursów tych par walut (aktualne i historyczne miesiąc wstecz) i wystawia plik xls zawierający dane: nazwa pary walut, data kursu, wartość kursy) Plik ten system X wysyła do szyby ESB. Szyna przesyła ten plik do systemuY. SystemY wykorzystuje te dane do wyznaczenia wewnętrznych kursów walut wg. ustalonego modelu matematycznego. Wynik obliczeń odkładany jest w bazie danych tego systemu. Na końcu procesu jest pracownik, który wykorzystuje te informacje za pośrednictwem SystemuZ. Wybiera parę walut, określa datę i system zwraca mu wewnętrzny kurs wyznaczony przez SystemY. Technicznie odbywa się poprzez odpytanie systemu Y poprzez jego API. Czyli mamy SystemX, SystemY, SystemZ, pracownika, szynę, plik csv, plix xls, 2XAPI no i przepływ danych (najpierw plików, potem poszczególnych atrybutów) . I jak to wszystkim pokazać żeby było czytelne? (źr.: : Model pojęciowy, model danych, model dziedziny systemu)
Prawdę mówiąc, mniej więcej w takiej formie dostaje materiały od moich klientów.. ;). Co możemy zrobić? Pomyślałem, że dobry reprezentatywny przykład pomoże. Popatrzmy…
Metody
Organizacje na początku modelujemy z perspektywy biznesowej abstrahując od tego co nazywamy “systemem informatycznym”. Celem jest zrozumienie tego jak ona funkcjonuje i opisanie (model) jej mechanizmu działania. Na tym etapie musimy oderwać się od używanego od wielu lat oprogramowania i udokumentować procesy biznesowe, mimo tego, że bardzo często używane oprogramowanie coś automatyzuje i pracownicy tego od lat nie widzą. Taki model w metodyce MDA nazywamy Computation Independent Model. Mając opisany i rozumiejąc mechanizm działania organizacji, pozyskujemy wiedzę o tym jakimi narzędziami się ona (jej pracownicy) posługuje i kiedy, sprawdzamy co i kiedy (jeżeli w ogóle) zostało z pomocą tych rozwiązań IT zautomatyzowane. Powstaje model PIM systemu IT (Platform Independent Model). Całość wykorzystuje notacje BPMN oraz UML.
Model biznesowy (CIM)
Na tym etapie modelujemy “co i po” co a nie “jak i czym” a task BPMN (model analityczny, opisowy) to nazwa procedury:
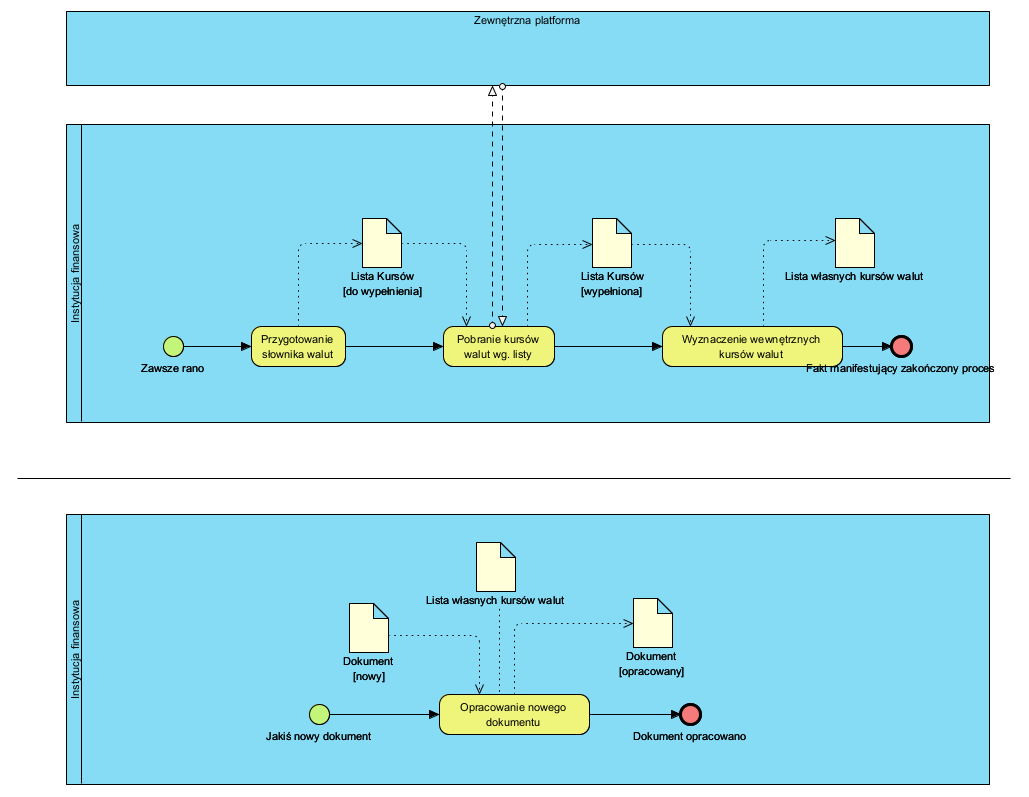
Bardzo częstym błędem, są próby łączenia powyższego w (traktowania jako) jeden proces biznesowy. Drugi częsty błąd to umieszczanie na modelach biznesowych systemów IT. Powyżej “Zewnętrzna platforma” to nie “system IT” a dostawca usługi, alternatywą jest wpisanie tam nazwy podmiotu zarządzającego tą platformą. Detale, zależnie od tego czego dotyczą, umieszczamy na szablonach dokumentów (czyli poza diagramami BPMN) lub w treści procedur uwidocznionych jako ich nazwy (task) na diagramie BPMN.
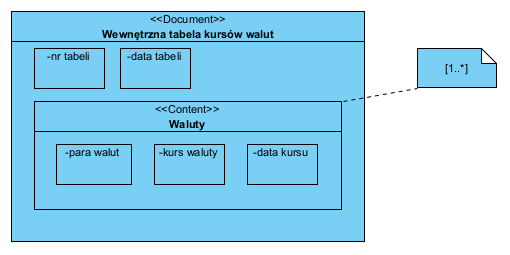
Dokument (szablon, struktura) Lista własnych kursów walut można przedstawić np. tak (tu jako Wewnętrzna tabela kursów walut) :
Model, opis techniczny (PIM)
Może mało podobny do realnego wydruku, ale pozwala zarządzać treścią a taki jest cel na tym etapie. Taki model wykonany w narzędziu CASE, to klasa i jej atrybuty. Może posłużyć jako struktura pliku XML.
Modelowanie to przede wszystkim poziomy abstrakcji. najwyższy to Model kontekstowy:
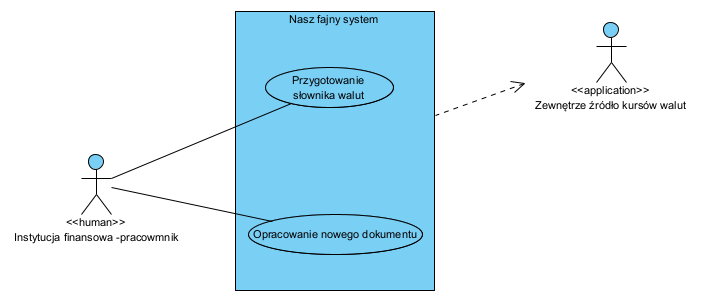
Powyższe to konsekwencja modelu procesów (patrz Transformacja modelu…): przypadek użycia aplikacji (systemu) to usługa jaką ‘system’ świadczy aktorowi. Usługa w UML (przypadek użycia systemu) realizuje oczekiwany przez aktora efekt (tu dokument) a nie “kliknięcie w ekran”.
A co robi nasz “system”?

Tu pokazujemy komponenty składowe systemu rozumianego jako “system IT organizacji”. Granice tego co nazywamy “system” ustalamy my, bo to kontekst projektu. Pod pojęciem “system” może sie kryć konkretna aplikacja lub “całość IT” organizacji, to także kwestia umowy (przyjętej w danym projekcie konwencji).
Jak to działa?
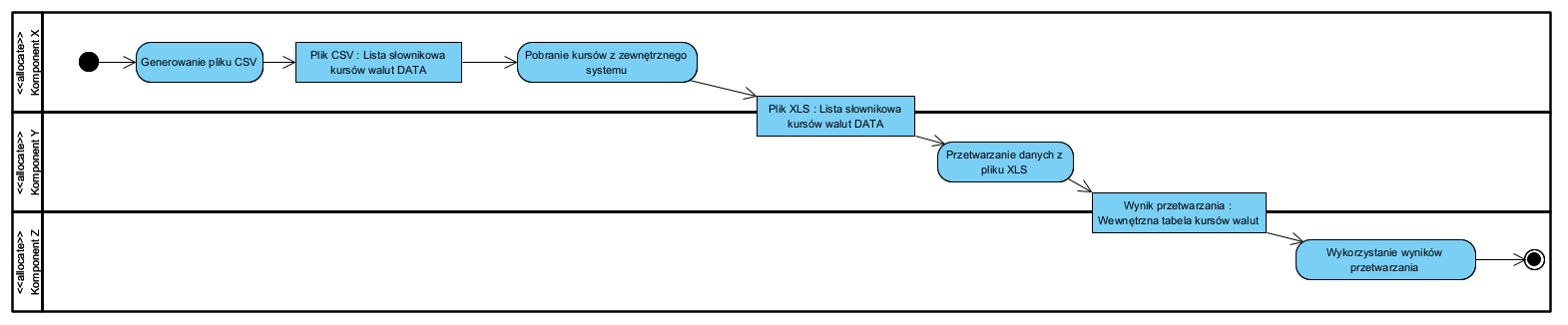
Diagram aktywności. Cały basen to aktywny system, partycje reprezentują jego komponenty. Wewnątrz partycji pokazano zadania realizowane przez poszczególne komponenty i (ewentualnie) dane jakie sobie przekazują. Docelowo zadania można przyporządkować do operacji komponentów reprezentowanych przez partycje. Ten diagram pokazuje w jakiej kolejności są wykonywane zadania a nie jak wywołują się między sobą komponenty. Tutaj celem jest pokazanie samej współpracy komponentów i przepływu danych (obiekty reprezentują dokumenty: nazwane struktury danych). Na rym etapie (z reguły wcześniejszy etap koncepcyjny) pokazujmy tylko przepływ danych.
Jeżeli chcemy pokazać scenariusz integracji robimy to tak:
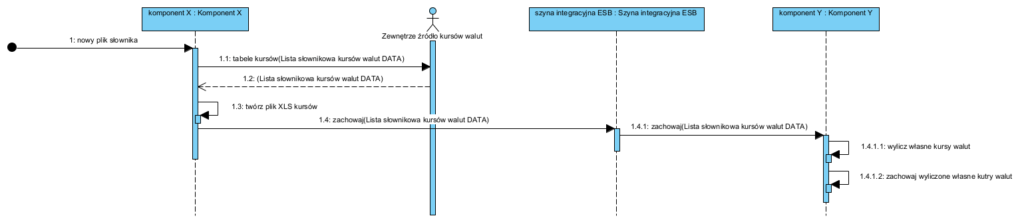
Tak wygląda scenariusz (realizowany raz dziennie) komunikowania się komponentów. Każdorazowo zaś, gdy pracownik tworzy dokument wykorzystujący aktualny wewnętrzny kurs waluty, realizowany jest scenariusz:
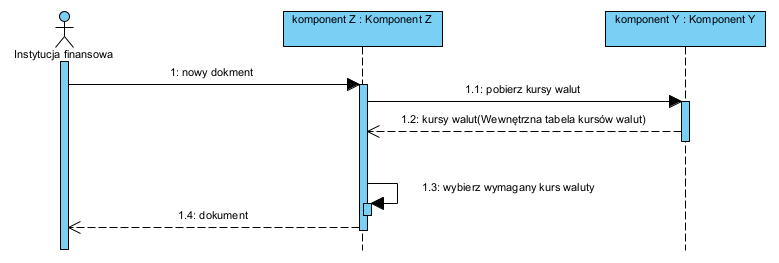
Na diagramach pokazujemy operacje interfejsów wywoływane przez poszczególne komponenty.
Podsumowanie
Jak widać mamy tu kilka prostych diagramów, każdy ma określony jeden kontekst. Czy to jest tytułowe “czytelne pokazanie”? Moim zdaniem, każdy z tych diagramów jest bardzo prosty mimo, że pierwotny opis wygląda na skomplikowany.
Próba pokazanie wszystkiego na “jakimś” jednym diagramie skończy się typowym “spaghetti modelingiem”. Jednak jeżeli podejdziemy do tego tak, że osobno opiszemy to co robią ludzie i osobno to co robią komponenty tego systemu, to będzie właśnie kilka prostych diagramów. Jak dodamy do tego fakt, że robiąc to w narzędziu CASE, automatycznie zyskamy śledzenie spójności i kompletności logiki tego modelu (projektu), uzyskamy efekt w postaci spójnej i kompletnej dokumentacji (jeżeli jest to opis wykonany na bazie audytu) lub projektu (jeżeli jest to opis opracowany przed wdrożeniem).
Podręcznikowa wersja powyższego wygląda jak poniżej:
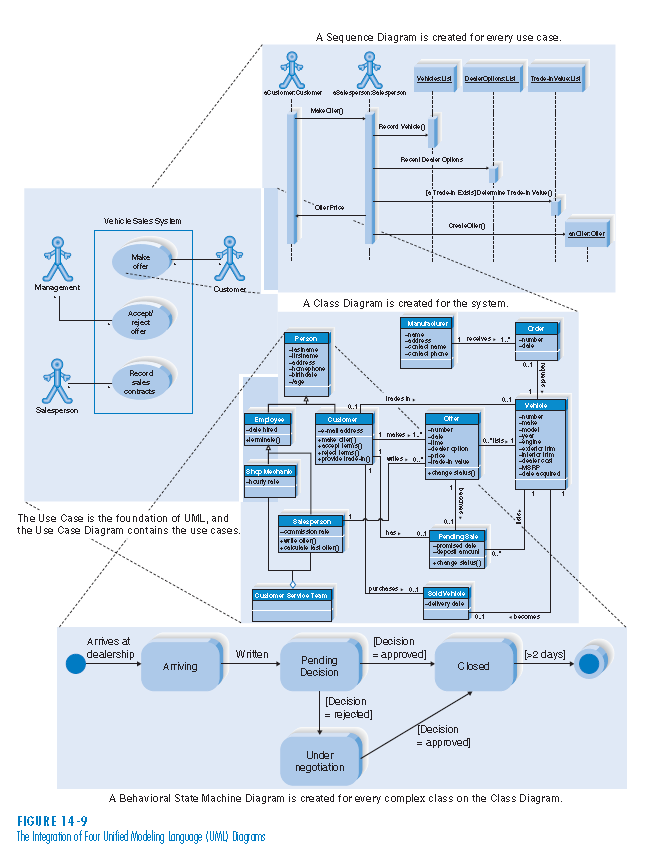
Więcej o powyższym w artykule o wymaganiach.
Uwagi końcowe
Takie modele pomagają wychwytywać miejsca optymalizacji zarówno procesów jak i samej architektury integracji.
Mając takie schematy i zrozumienie architektury pojawia sie pytanie: skoro mamy szynę integracyjną ESB to dlaczego mamy integracje bezpośrednią pomiędzy komponentami Z i Y?
Komponent Y wielokrotnie odpowiada na żądania podawania określonych kursów. Być może API było by prostsze i natężenie komunikacji mniejsze gdyby Komponent Z żądał i dostawał całą tabelę kursów i “wydłubywał z niej” potrzebny mu w danym momencie kurs waluty.
Na modelu procesów biznesowych, można (w razie takiej potrzeby) pokazać, które komponenty wspierają poszczególne aktywności w procesach, lub je automatyzują.




Dziękuję 🙂 nie powiem, kilka razy musiałem przeanalizować ten materiał żeby go zrozumieć (np. z diagramem sekwencji nie miałem nigdy do czynienia) ale koniec końców ułożyło mi się to w całość i faktycznie ma to sens. Może diagramów jest wiele ale i kontekstów jest wiele, kilku kontekstów nawet nie dostrzegałem. Mam jedno pytanie. Napisał Pan, że detale można umieszczać też w treści procedur aktywności uwidocznionych na diagramie BPMN. Czy chodzi o to, że procedury (jeśli są) powinny być dodatkowo pokazane na diagramie BPMN (jeśli tak to w jaki sposób) czy, że szczegóły aktywności, jeśli są istotne, powinny zostać opisane w procedurze (rozumianej jak dokument z treścią) ale nie powinno się ich umieszczać na diagramie BPMN.
W kwestii BPMN: mamy modele wykonywalne i analityczne. Jeżeli powstaje (istnieje) oprogramowanie “typowe” czyli w jakimś języku ktoś napisał aplikację, to tworzymy modele analityczne, podobnie jak to ma miejsce w projektach wdrażania norm ISO, procedur bezpieczeństwa, analizy wymagań na oprogramowanie (model CIM). I tu uwaga: czym innym jest procedura wykonania jakiejś pracy (aktywności) pokazanej na modelu procesów biznesowych (BPMN) a czym innym scenariusz (celowo inne słowo niż procedura) wykonania jakiejś wewnętrznej operacji przez aplikację (w tym ewentualne integracje):
– Proces a procedura
– modele analityczne
Dodałem podręcznikowy diagram pokazujący związki między modelami i ich kontekstami w UML.
Napisał Pan: “..Na modelu procesów biznesowych, można (w razie takiej potrzeby) pokazać, które komponenty wspierają poszczególne aktywności w procesach, lub je automatyzują”. Rozumiem, że należy to pokazać właśnie w taki sposób jak zostało powyżej pokazane tj. jako tor na diagramie?
Niestety nie, partycje w BPMN nie służą do modelowania systemów (to błąd), partycje służą do kategoryzacji aktywności. Modele i notacja BPMN to modele CIM (Computation Independent Model), partycja to nie “system”. Na modelu CIM z użyciem BPMN “można” pokazać, że aktywności są wspierane przez jakieś aplikacje, ale to są cechy tych aktywności a nie elementy notacji BPMN. Robimy to najczęściej np. dodając do nazwy aktywności, np. w nawiasie, nazwę usługi aplikacyjnej lub aplikacji (kwestia przyjętej konwencji). Inna forma to, osobny dokument, macierz, np.: wiersze to nazwy aplikacji lub przypadków użycia, a kolumny to nazwy aktywności na modelach BPMN, na przecięciach ‘ptaszki’ pokazujące która aktywność jest realizowana w jakiej aplikacji. Niektóre narzędzia (Visua-Paradigm) wspierają takie oznaczenia, więcej o tym: Transformacja ….