Zapraszam wszystkich, którzy szukają pomocy, wiedzy oraz wsparcia w swoich projektach informatyzacji. Działam od 1991 roku, mój Blog działa nieprzerwanie od 1998 roku.
Jeżeli nie potrafisz czegoś poprawnie narysować to znaczy że nadal tego nie rozumiesz.
Wprowadzenie Tym razem krótka recenzja pewnej książki z roku 2006, a raczej jej polecenie każdemu projektantowi i architektowi dzisiaj. Na końcu polecam także kolejną nowszą pozycję jako uzupełnienie. Adresatami tej recenzji są głównie analitycy i projektanci, jednak adresuję ten wpis także do developerów, zakładam że dla nich nie jest to "coś nowego", ale być może mają jakieś rady dla projektantów. Warto także podkreślić, że pomiędzy OOP a OOAD jest coraz większa różnica i podział na role: analiza i projektowanie oraz implementacja, a także postępująca separacja tych ról, stają się standardem…
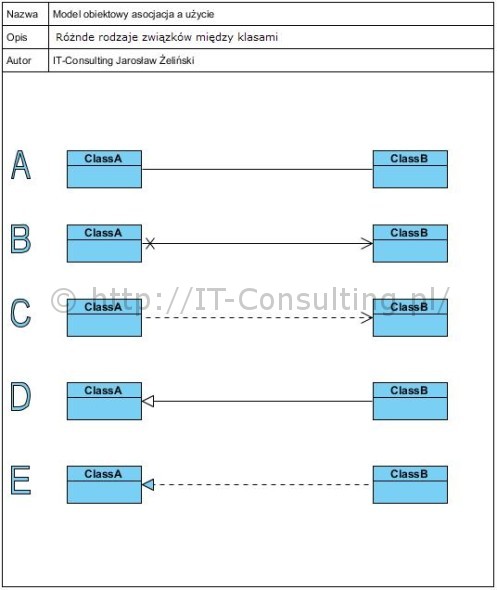
Wprowadzenie Tym razem artykuł na temat typów związków między elementami w modelach systemów. Modele tego typu to hierarchiczna struktura mająca kilka różnych perspektyw, poziomów abstrakcji i poziomów dekompozycji. Do tego dochodzą fizyczne i logiczne powiązania między elementami oraz fakt, że każdy system to określone "materialne" elementy ułożone w hierarchiczną strukturę. Każdy system składa się ze skończonej liczby elementów o skończonej liczbie typów. Na to wszystko nakłada się struktura wymagań na system, oraz konieczność wykazania zgodności projektu systemu z tymi wymaganiami . Bardzo często jestem pytany o to, jak organizować repozytorium…
Wprowadzenie Notacja EPC (Event-driven Process Chain) została opracowana w 1992 roku w ramach projektu badawczo-rozwojowego z udziałem SAP AG na University of Saarland w Niemczech, a jej twórcą jest dr August-Wilhelm Scheer. Stanowi ona kluczowy element koncepcji modelowania SAP R/3 w zakresie inżynierii biznesowej i dostosowania tego systemu do potrzeb klienta, została włączona także do systemu NetWeaver firmy SAP. Ostatni duży projekt z jej użyciem realizowałem w 2008 roku dla polskiego oddziału niemieckiego banku WestLB Bank Polska SA. Później już jedynie okazjonalne wsparcie merytoryczne i audyty, nadal się zdarzają. EPC…
Wprowadzenie Ronald Ross, współautor standardu modelowania reguł biznesowych i biznesowego słownika pojęć napisał niedawno na swoim profilu LinkedIn: "People love stories. Are user stories helpful in engineering business solutions? Absolutely. Are you done with requirements and solution engineering when you?ve worked through a set of user stories? No. Not even close!" ["Ludzie kochają historie. Czy historie użytkowników są pomocne w tworzeniu rozwiązań biznesowych? Zdecydowanie tak. Czy skończyłeś z wymaganiami i inżynierią rozwiązania, gdy już opracowałeś zestaw historyjek użytkownika? Nie. Nawet nie zbliżyłeś się do nich!".] (https://www.linkedin.com/posts/rossronald_people-love-stories-are-user-stories-helpful-activity-6935627008265633793-Bpzb/) Świat od dekad boryka…
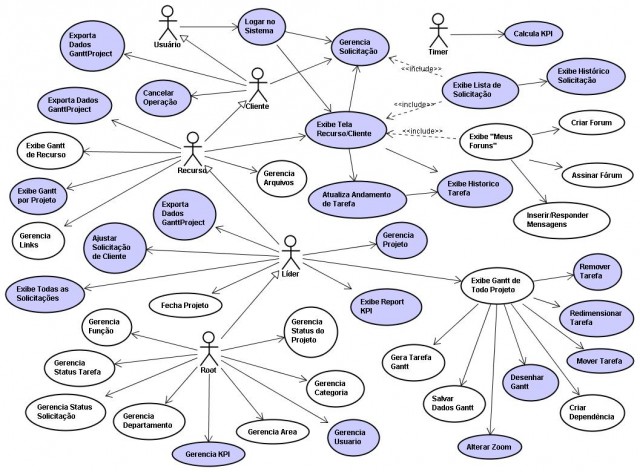
Wprowadzenie Jest to diagram, który na równi z Diagramem Klas, budzi bardzo często ogromne problemy interpretacyjne (patrz: Diagram klas...). Bardzo wielu autorów przypisuje temu diagramowi role, których on nie pełni, a nie raz prezentowane w sieci i literaturze przykłady są niepoprawne. Znakomita większość autorów tych diagramów używa ich jako "zbioru możliwych kliknięć" co jest całkowitym niezrozumieniem celu użycia i idei tego diagramu. Nawet jeżeli ktoś potrzebuje takiej mapy klikania, to są do tego lepszych narzędzia i metody (przykład: Mapa ekranów aplikacji ? podstawa dobrego UX/UI design). Tworzenie niezgodnych z notacją…
Architektura Projekty informatyczne się rozrastają, cała branża ewoluuje. Ostatnie 20 lat doświadczeń pokazało, że owszem sztuką jest stworzyć i wdrożyć oprogramowanie, ale jeszcze większą sztuką jest je konserwować, zmieniać i rozwijać. Wiele firm boryka się z powtarzanymi długotrwałymi i kosztownymi "analizami przedwdrożeniowymi" poprzedzającymi każdy kolejny projekt wdrażania zmian. To skutek braku aktualnej dokumentacji posiadanego systemu. To jak planowanie nowej budowy w mieście nie mając aktualnych planów urbanistycznych tego miasta: każdy nowy projekt to ponowne dokumentowanie stanu obecnego, tylko dlatego, że ktoś nie udokumentował zmian wprowadzonych ostatnim razem (być może poprzednio…
Artykuł ma dwie części. Pierwsza część jest adresowana do kadr zarządczych, cały artykuł (obie części) do osób zajmujących się projektowaniem rozwiązań.
Wstęp
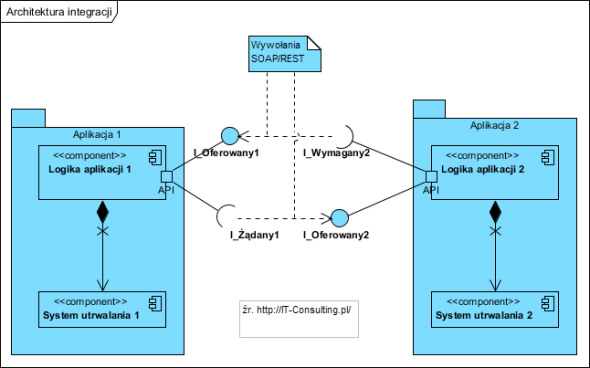
Mamy ogólnoświatową sieć Internet, aplikacje lokalne i w chmurze, aplikacje naszych kontrahentów i aplikacje centralnych urzędów. Wszystkie one współpracują i wymieniają dane, czyli są zintegrowane. Dlatego integracja stała się cechą każdego systemu informatycznego.
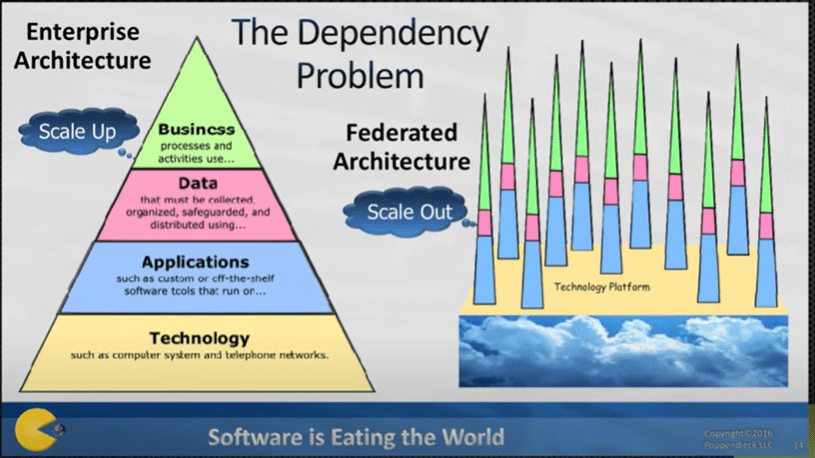
Wyjątkowo na początku (poniżej) umieszczam cały ten ciekawy referat, można bo pominąć i czytać dalej, jednak jeżeli ktoś chce poznać przewidywania z roku 2016 i ma czas, polecam (teraz lub później):
The Future of Software Engineering ? Mary Poppendieck ? GOTO 2016
Obecnie kluczowym pytaniem jest: Jak zintegrować, a nie: Czy zintegrować.
Pogodzenie się z tym, że świat systemó ERP już nigdy nie będzie tak prosty jak w czasach mainframe’ów, czyli jednej centralnej aplikacji, jest nieuniknione.
Czym jest obecnie integracja? To wymiana danych a nie ich współdzielenie: dane z urzędem wymieniamy, dane z kontrahentem wymieniamy, nie współdzielimy żadnych danych z tymi podmiotami, każdy ma swoje własne, bezpieczne bazy danych, i to wszystko ładnie działa! Idea zbudowania wszystkich funkcjonalności jako zintegrowanej aplikacji na jednej współdzielonej bazie danych w czasach obecnych jest utopią. Taką samą jak hipotetyczna centralna baza danych dla wszystkich sklepów internetowych, firm kurierskich i banków, a one są jednak zintegrowane: one wymieniają dane a nie współdzielą!
ERP to (ang.) Enterprise Resource Planning czyli Planowanie Zasobów Przedsiębiorstwa. To system wykorzystywany przez firmy do zarządzania i integrowania ważnych elementów ich działalności. Ale kto powiedział, że to ma być monolit od jednego producenta?
Nadal spotykam pejoratywne określenia “system pointegrowany” jako krytykę budowy systemu ERP z komponentów i integracji jako wymiany danych. Autor tego określenia najprawdopodobniej nadal żyje w świecie mainframe.
Chociaż dostawcy systemów ERP oferują aplikacje dla przedsiębiorstw i twierdzą, że ich zintegrowany system jest najlepszym rozwiązaniem, wszystkie moduły w jednym systemie ERP rzadko kiedy są najlepsze z najlepszych.
Prawo autorskie stanowi naturalny przedmiot zainteresowania każdego, kogo efekty pracy są tym prawem chronione. Czasami prawo to staje się przedmiotem badań, jak w moim przypadku, bo nie tylko to co tworzę, podlega ochronie prawnoautorskiej, ale też stanowi to wartość niematerialną dla beneficjentów mojej pracy: podmiotów będących przedmiotem moich audytów i analiz, przekazywaną im wartością tego co projektuję: projektów rozwiązań.
Moje badania nie dotyczą jednak aktualnego stanu prawnego, dotyczą mechanizmu powstawania i prawnej ochrony wartości intelektualnych.
Prawo autorskie budzi wiele emocji i kontrowersji z wielu powodów. Jednym z nich jest to, że często stawiany jest mu zarzut, że jest nieskuteczne w pewnych obszarach:
Dla filozofa prawa wyjątkowo interesującym przedmiotem badań są prawa autorskie. Wynika to z faktu, iż odkąd pojawił się Internet, dotychczasowe w pełni satysfakcjonujące uregulowania stały się nieskuteczne.
Autorka powyższego napisała ciekawy esej, do którego postaram się odnieść na gruncie systemów informacyjnych i technologii z nimi związanych (wspominany przez autorkę Internet także). Jest to próba wyjaśnienia krytykowanego zjawiska jakim jest łatwość kopiowania, oraz teza i jej obrona, że nie prawo autorskie jest tu źródłem problemu a życzeniowe podejście wielu posiadaczy praw majątkowych, do jego stosowania. W 2012 roku pisałem, że nie można się “obrażać” na postęp:
Prostą, nadal funkcjonującą, barierą blokującą powielanie (tworzenie replik, reprodukcji oryginałów np. rzeźb) dzieł materialnych jest wymagana umiejętność porównywalna do tej, jaką cechuje się autor oryginału. W przypadku dzieł niematerialnych ta bariera nie istnieje, bo do skopiowania najlepszego nawet utworu literackiego czy muzycznego wystarczy np. komputer, nie są potrzebne żadne, poza obsługą komputera, umiejętności.
Produktem modelowania procesów biznesowych są jakieś diagramy, i z tym jesteśmy oswojeni. Od czasu do czasu można usłyszeć o symulacjach procesów, lecz to już jednak znacznie rzadziej. O symulacjach procesów pisze się mniej: Google Scholar (literatura naukowa) pokazuje ok. 5 mln publikacji na temat modelowania procesów biznesowych, na temat ich symulacji 2 mln mniej. Ale już Google (“cały Internet”) odpowiednio: 2,3 mld. i 282 mln. Jak widać w powszechnym obiegu symulacje, jako temat, to trzy rzędy (tysiąckrotnie) mniejsza ilość tekstów! (wyszukiwane były hasła ang. ‘business process modeling’ oraz ‘business process simulation’). Zastanówmy się dlaczego i co można osiągnąć symulacją.
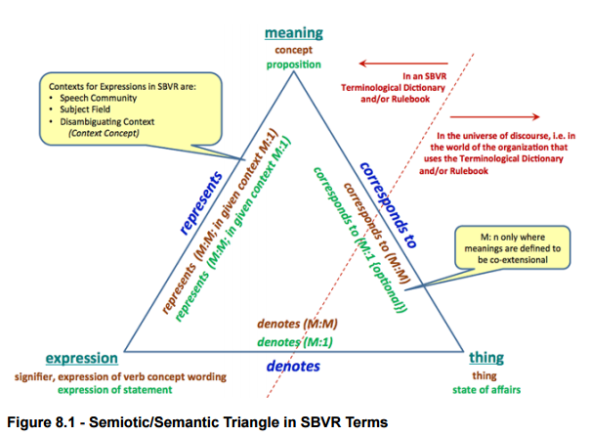
Ronald G. Ross Ronald G. Ross jest autorem lub współautorem wielu opracowań na temat modeli pojęciowych i zarządzania wiedzą . Jest także współzałożycielem Business Rule Solution LLC, oraz współtwórcą specyfikacji i notacji SBVR . Książka Najnowsze z powyższych opracowań to rodzaj podsumowania pewnej części dorobku autora. Modele pojęciowe są często mylone z projektowaniem relacyjnego modelu danych, a bywa gorzej, gdy są utożsamiane z "modelem dziedziny systemu" w projektach dotyczących tworzenia aplikacji określanych jako"obiektowe". Książka traktuje o modelach pojęciowych, i autor definiuje je jako: model pojęciowy: uporządkowany zbiór pojęć i związków…
Practical Event-Driven Microservices Architecture Building Sustainable and Highly Scalable Event-Driven MicroservicesHugo Rocha ma prawie dziesięcioletnie doświadczenie w pracy z wysoce rozproszonymi, sterowanymi zdarzeniami architekturami mikroserwisów. Obecnie jest szefem inżynierii w wiodącej globalnej platformie ecommerce dla produktów luksusowych (Farfetch), świadczącej usługi dla milionów aktywnych użytkowników, wspieranej przez architekturę sterowaną zdarzeniami z setkami mikroserwisów przetwarzających setki zmian na sekundę. Wcześniej pracował dla kilku referencyjnych firm telekomunikacyjnych, które przechodziły od aplikacji monolitycznych do architektur zorientowanych na mikroserwisy. Hugo kierował kilkoma zespołami, które każdego dnia bezpośrednio stykają się z ograniczeniami architektur sterowanych zdarzeniami. Zaprojektował…
This time a short article about an interesting construction. It was described by Rebecca Wirfs-Brock in 1999 (Miller & Wirfs-Brock, 1999) . The idea did not gain much popularity at the time, but now, in the era of patterns based on microservices and micro applications, it has a chance to come back into favour. I've been using it for a long time (see interface-oriented design). The abbreviations HLD and LLD are High-Level Design and Low-Level Design, respectively. These are the levels of abstraction in the PIM model. It is also a description of the design style of an interface-oriented system architecture (interface-oriented architecture).


![Abstraction focuses upon the essential characteristics of some object, relative to the perspective of the viewer. [Abstrakcja skupia się na istotnych cechach jakiegoś obiektu w odniesieniu do perspektywy widza.]](https://it-consulting.pl/wp-content/uploads/2022/05/image-14-590x397.png)